2025-04-15,由慕尼黑工業大學等機構創建的 EuroCropsML 數據集,這是一個結合了農民報告的作物數據與 Sentinel-2 衛星觀測的時間序列數據集,覆蓋了愛沙尼亞、拉脫維亞和葡萄牙。該數據集為解決遙感應用中作物類型數據空間不平衡問題提供了新的基準,有助于推動少樣本學習和遷移學習算法在真實世界作物分類任務中的應用和評估。
一、研究背景
衛星遙感技術在農業領域發揮著重要作用,如作物類型分類、產量預測等。然而,不同地理區域的作物類型數據分布極不均衡,這種數據空間不平衡問題給準確的作物分類帶來了挑戰。為了克服這一問題,遷移學習和元學習算法應運而生,但它們在真實世界復雜應用中的表現尚待深入評估。
目前遇到困難和挑戰:
1、數據空間不平衡:不同地區作物數據的豐富程度差異巨大,導致在數據匱乏地區難以直接應用基于數據豐富地區訓練的模型。
2、算法泛化能力不足:現有的遷移學習和元學習算法在不同地理區域之間的知識遷移效果不佳,難以適應新地區的作物分類任務。
3、計算資源與性能的權衡:提高模型性能往往需要更多的計算資源和更長的訓練時間,這在實際應用中可能會受到限制。
數據集地址:EuroCropsML|農業數據分析數據集|遙感技術數據集
二、讓我們一起看一下EuroCropsML
EuroCropsML 是一個結合了農民報告的作物數據與 Sentinel-2 衛星觀測的時間序列數據集,專為少樣本作物類型分類任務設計。
該數據集基于 EuroCrops 參考數據,擴展了 Sentinel-2 L1C 反射率數據,覆蓋了愛沙尼亞、拉脫維亞和葡萄牙的農業區域。為了減少數據不平衡問題,對某些頻繁出現的作物類型(如牧草)進行了重采樣。此外,還對數據進行了預處理,包括去除云層干擾和標準化等操作。
數據集包含 706,683 個具有多類標簽的數據點,涉及 176 種不同的作物類型,其中 35 種在三個國家都有分布。每個數據點包含一年內無云的多光譜 Sentinel-2 觀測數據的時間序列,時間步長多達 216 個。
數據集特點:
1、多國覆蓋:包含來自愛沙尼亞、拉脫維亞和葡萄牙的農業數據,具有不同的氣候條件和農業實踐。
2、多類標簽:涵蓋了 176 種不同的作物類型,提供了豐富的分類任務。
3、時間序列數據:每個數據點包含一年內的多光譜 Sentinel-2 觀測數據,能夠反映作物的生長周期。
基準測試:
在基準測試中,MAML 類算法(如 MAML 和 ANIL)在少樣本學習任務中表現最佳,其中 ANIL 在 500-shot 任務中達到了 65.2% 的分類準確率和 0.556 的 Cohen’s Kappa 系數,分別比無預訓練提升了 2.0% 和 2.7%,顯示出顯著的性能提升,但這些算法的訓練時間比傳統方法長了 3-5 倍。
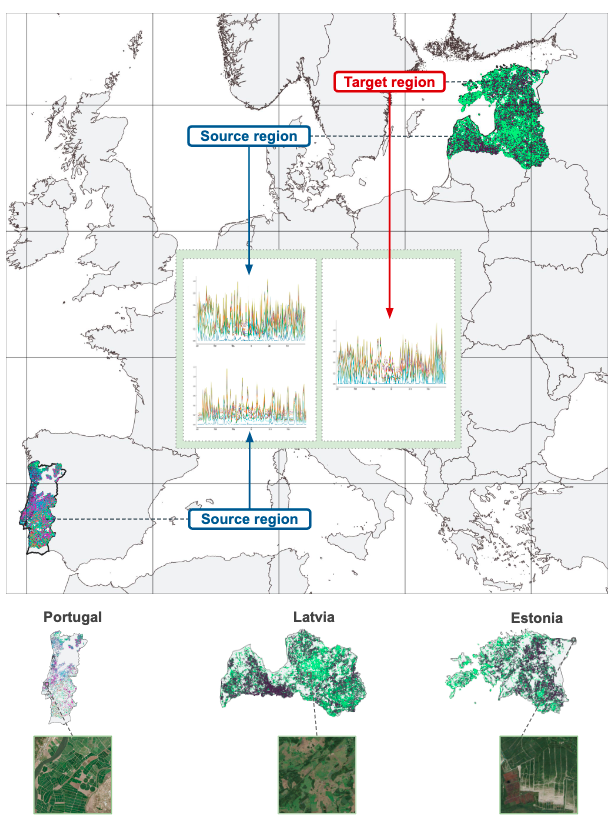
源區域和目標區域(使用 EuroCrops HCAT3 第 3 級(Schneider 等人,2023a,b))的農田可視化。初始訓練在源區域的 Sentinel-2 L1C 農業時間序列上進行,隨后在獨立的目標區域對模型進行微調和評估。
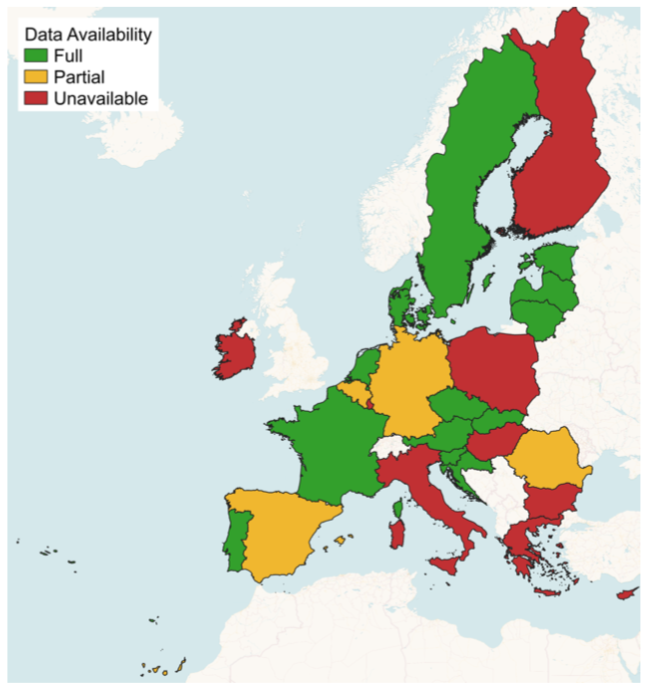
目前,在歐盟27個成員國中,有17個國家的數據在EuroCrops數據集中實現了協調,而有四個國家僅提供了部分數據。數據的可用性指的是EuroCrops數據集的第10版。
根據農業參考數據的可用性對歐盟成員國進行排序。這指的是EuroCrops數據集的第10版
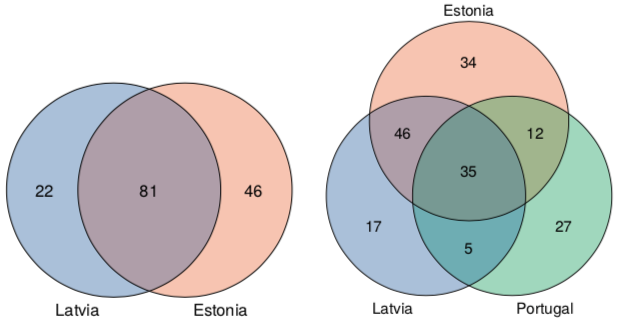
在三個感興趣區域(ROI):愛沙尼亞、拉脫維亞和葡萄牙之間共享和獨特的標注作物類別的數量。
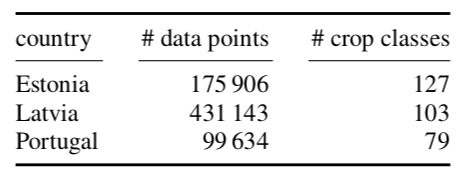
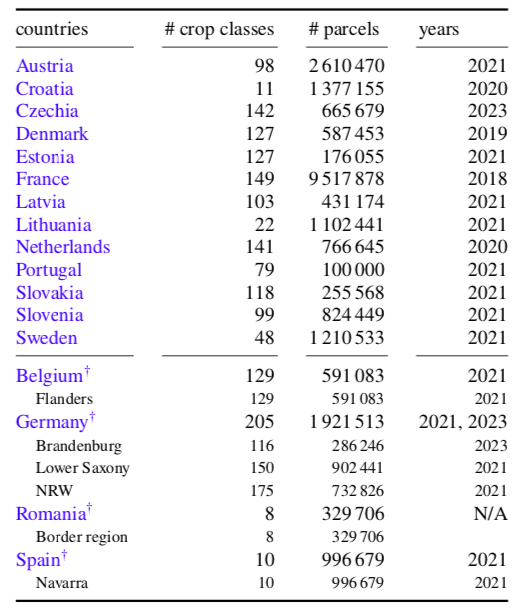
構成EuroCropsML數據集的三個國家的數據點數量和不同的作物類別數量。數據點的數量指的是經過預處理后獨特地塊的數量
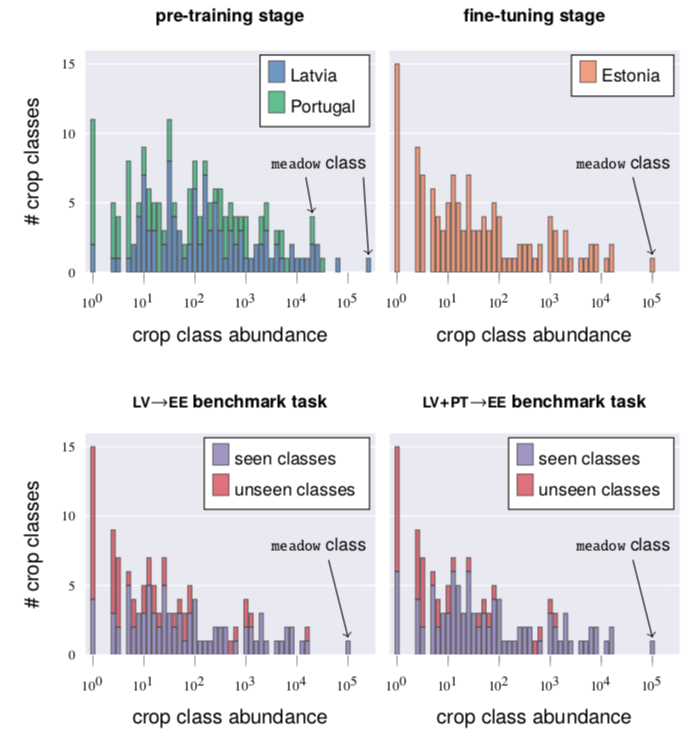
上部直方圖顯示了在預訓練和微調數據集中,不同豐度(地塊數量)的作物類別數量的分布情況。下部直方圖則專注于愛沙尼亞的微調數據,展示了在預訓練階段是否見過的作物類別數量分布,這些數據僅來自拉脫維亞或拉脫維亞和葡萄牙。兩個直方圖均使用對數刻度。
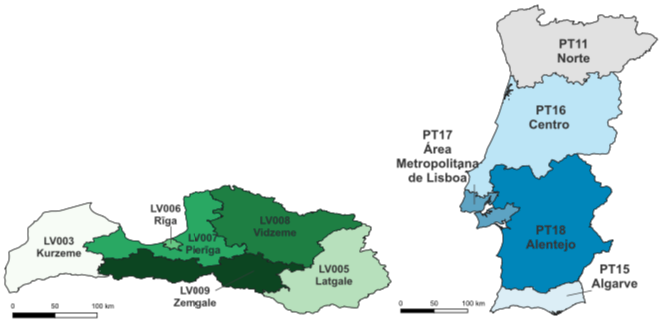
用于采樣元學習任務的拉脫維亞(左)和葡萄牙(右)的NUTS區域
三、展望EuroCropsML應用
案例:作物分類在農業管理中的應用
以前,農民們要想知道地里種的是啥作物,主要靠自己去田里看看,或者請專家來實地考察。這種方法不僅費時費力,還只能覆蓋一小塊地。要是地多了,根本忙不過來。而且,靠人眼識別,難免會出錯,導致分類不準確。比如,有些作物長得差不多,很容易混淆。
另外,雖然衛星圖像也能幫忙,但以前的衛星圖像分析方法需要很多標注好的數據來訓練模型。可問題是,不同地方的數據分布不一樣,有些地方數據多,有些地方數據少,這就導致模型在數據少的地方表現不好,分類精度差。
現在,有了 EuroCropsML 數據集,農場可以這樣操作:
1、數據預處理:用數據集里的衛星圖像和農民報告的作物數據,先對農場的作物進行預訓練。
2、模型訓練:選一個好用的算法,比如 MAML 或 ANIL,在預訓練的基礎上稍微調整一下,就能適應農場的具體情況。
3、實時監測:把訓練好的模型用起來,實時監測作物的生長情況,發現問題及時調整。
4、精準決策:根據分類結果,農民可以更科學地安排種植,選擇合適的作物品種,優化灌溉和施肥計劃。
這樣一來,農場不僅分類更準了,還省了不少事兒,產量也提高了,實現了精準農業。
更多免費的數據集,請打開:遇見數據集
遇見數據集-讓每個數據集都被發現,讓每一次遇見都有價值。遇見數據集,領先的千萬級數據集搜索引擎,實時追蹤全球數據集,助力把握數據要素市場。![]() https://www.selectdataset.com/
https://www.selectdataset.com/








 - 機組組合模型以及 Gurobi 求解)
程編程——(8)多進程的沖突問題)


)


設計與優化)



_51)