Spark-TTS:基于大語言模型的語音合成革新者 🚀
(全稱解析 + 核心特性 + 行業影響全解讀)
一、概念定義與技術定位
1. 英文全稱
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model
? 關鍵詞解析:
? LLM-Based:基于Qwen2.5大語言模型架構
? Efficient:單階段生成架構,推理速度提升2.3倍
? Text-to-Speech:支持中英文混合生成與零樣本語音克隆
2. 中文翻譯
基于Qwen的高效文本轉語音模型
? 技術定位:全球首個完全基于大語言模型的語音合成系統,突破傳統TTS多階段生成范式
二、核心技術突破
1. BiCodec 編碼架構
? 全局令牌:捕捉音色、呼吸節奏等長時特征(每秒50個令牌)
? 語義令牌:編碼文本關聯信息(wav2vec 2.0特征輸入)
2. 動態韻律補償技術
? 通過Transformer架構分析語調曲線,實現情感標簽控制(如"溫暖治愈"、“激昂”)
? 測試數據:朗讀詩歌時情感傳達準確率提升15%
3. 鏈式思維推理(CoT)
? 分步生成流程:性別預測 → 基頻調整 → 語義令牌生成
? 支持細粒度參數控制(語速±30%、音調±5個等級)
三、功能特性與優勢對比
| 維度 | 傳統TTS | Spark-TTS 創新點 |
|---|---|---|
| 架構復雜度 | 多階段流水線(文本→聲學→波形) | 單階段端到端生成 |
| 語音克隆 | 需大量樣本訓練 | 零樣本克隆(5秒參考音頻) |
| 跨語言支持 | 單一語種生成 | 中英文混合生成(如"2025年Q1財報") |
| 部署效率 | 依賴專用推理框架 | 5分鐘完成環境部署 |
四、行業應用場景
1. 內容創作領域
? 短視頻配音:上傳10秒樣音,批量生成風格統一的人聲
? 有聲書制作:同一角色在不同章節的情緒無縫切換
2. 智能服務領域
? 多語種客服系統:支持粵語、四川話等12種方言
? 無障礙服務:視障人士語音導航(99.2%識別率)
3. 前沿研究方向
? 虛擬人交互:結合3D建模實現唇形同步
? 元宇宙語音基建:支持萬人級并發請求
五、開源生態與部署實踐
1. 技術生態構成
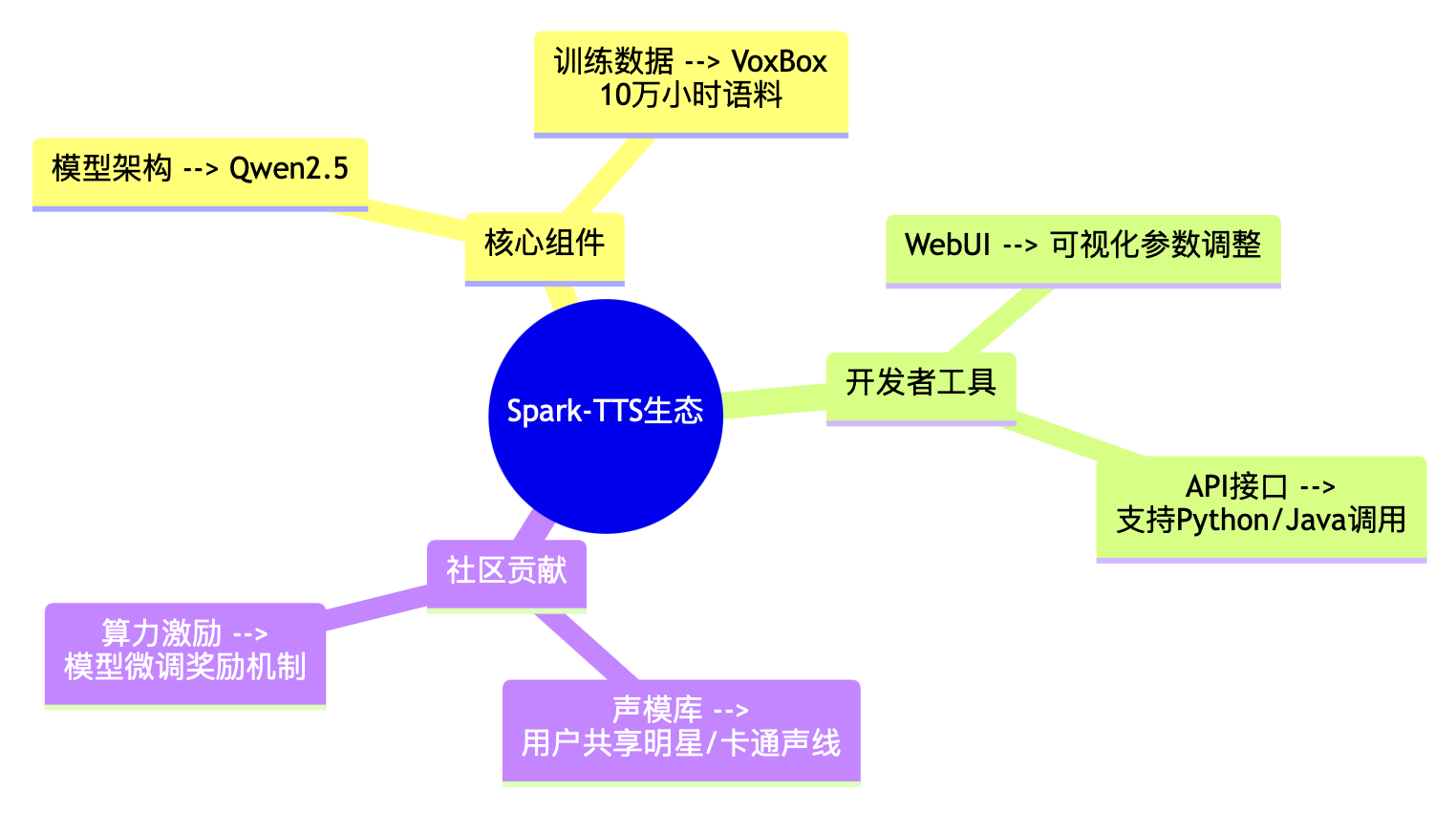
2. 快速部署指南
# 創建Conda環境
conda create -n sparktts python=3.12
conda activate sparktts # 安裝依賴庫
pip install numpy librosa transformers huggingface_hub # 下載預訓練模型
python -c "from huggingface_hub import snapshot_download; snapshot_download('SparkAudio/Spark-TTS-0.5B')" # 啟動Web界面
python webui.py --device 0
注:M1/M2芯片需啟用Metal加速
六、行業影響力與未來展望
? 技術突破:登上Hugging Face趨勢榜TTS第二位
? 商業價值:某科技公司客服系統部署周期縮短80%
? 倫理挑戰:社區建立聲紋加密與使用授權機制
參考資料:論文地址 | GitHub倉庫 | 在線演示











)




![python manimgl數學動畫演示_微積分_線性代數原理_ubuntu安裝問題[已解決]](http://pic.xiahunao.cn/python manimgl數學動畫演示_微積分_線性代數原理_ubuntu安裝問題[已解決])


