語?模型及詞向量相關知識
- ?然語?處理簡介
- ?然語?理解(NLU)
- ?然語??成(NLG)
- 發展趨勢
- 信息檢索技術
- 布爾檢索與詞袋模型
- 基于相關性的檢索 / TF-IDF
- 舉例:
- 語?模型 / Language Model
- 神經?絡語?模型
- Word2Vec訓練?法
- fasttext
?然語?處理簡介
?然語?(NaturalLanguage)其實就是?類語?對?于程序設計語?,?然語?處理(NLP)就是利?計算機對?類語?進?處理。
在NLP領域中,針對?然語?處理核?任務的分類,?直存在著如下兩種劃分:
?然語?理解(Natural Language Understanding,NLU)
?然語??成(Natural Language Generation,NLG)
?然語?理解(NLU)
研究如何讓計算機理解?類語?的語義、語法和語境,將?結構化的?本轉化為結構化的機器可處理的信息。
- 關鍵技術
- 句法分析:解析句?的語法結構(如主謂賓關系)。
- 語義分析:提取句?的深層含義,例如實體識別(NER)、關系抽取、事件抽取等。
- 意圖識別:理解??的真實需求(如對話系統中判斷??是詢問天?還是訂票)。
- 情感分析:判斷?本的情感傾向(積極、消極、中性)
- 上下?處理:結合對話歷史或背景知識消除歧義(如 “蘋果? 在不同語境中指?果或公司)。
- 典型應用
智能客服(意圖識別):解析??問題并進?分類。
搜索引擎(語義分析):理解查詢意圖并返回相關結果。
語?助?(語義分析):將語?指令轉化為操作(如 “打開空調?)。
?然語??成(NLG)
研究如何讓計算機根據結構化數據或意圖?成符合?類語?習慣的?本。
- 關鍵技術
1.模板?成:基于預定義模板填充內容(如?成 “今?天?:晴,溫度 25℃?)。
2.統計?成:利?統計模型(如神經?絡)學習語?模式,?成連貫?本。
3.邏輯到?本轉換:將知識圖譜、數據庫等結構化數據轉化為?然語?(如?成財
務報告)。
4.?格控制:?成符合特定?格(正式 / ?語化、幽默 / 嚴肅)的?本。 - 典型應?:
新聞稿?動?成:根據體育賽事數據撰寫報道。
個性化推薦?案:根據???為?成商品描述。
聊天機器?回復:結合上下??成?然流暢的對話。
發展趨勢
- 預訓練模型的影響:如 GPT4、BERT 等?模型的發展,同時推動了 NLU 和 NLG ?向的進步,?模型通過 “理解 + ?成? 能?實現多輪對話、??本?成等功能。
- 多模態融合:結合圖像、語?等信息提升理解與?成的準確性(如根據圖??成描述)。
- 低資源場景:針對?語種或特定領域(如法律、醫療)的 NLP 需求,開發更?效的模型。
通過 NLU 和 NLG 的結合,計算機正逐步實現與?類?然、流暢的交流,未來將在智能助?、?動化寫作、數據分析等領域發揮更?作?。
信息檢索技術
布爾檢索與詞袋模型
檢索技術的早期階段。涉及的?檔資料井不多,這個時間需要解決的是有?問題。因此,?程?員開發出了?種檢索模型。可?于處理有?問題。
- 假設待檢?件是?個?箱 / ?袋
檢索詞是?袋中的元素 / ?球
各檢索詞之間 地位平等、順序?關、獨?分布
- 提供?些描述檢索詞之間關系的操作符 / 布爾模型
a AND b
a OR b
NOT a
直到互聯?搜索引擎的產?,基于簡單布爾檢索的模型再也?法適應數據增?的規模了。
需要?種讓機器可以對信息的重要性打分的機制
基于相關性的檢索 / TF-IDF
1971
Gerard Salton∕杰拉德 · 索爾頓,康奈爾?學,The SMART Retrieval System—Experiments in Automatic Document Processing(SMART 檢索系統:?動?檔處理實驗)?中?次提到了把查詢關鍵字和?檔都轉換成?向量?,并且給這些向量中的元素賦予不同的值。
Karen Sp?rck Jones / 卡倫 · 瓊斯,A Statistical Interpreation of Term Speificity and Its
Application in Retrieval (從統計的觀點看詞的特殊性表及其在?檔檢索中的應?),第?次詳細闡述了Inverse Document Frequency,IDF的應?。之后在 lndex Term Weighting
對 Term Frequency ,TF 與 IDF 的結合進?了論述。
卡倫是第?位從理論上對TF/IDF進?完整論證的計算機科學家。也被認為是TF與IDF的發明?。
- 詞頻(Term Frequency)
在文檔d中,頻率表示給定詞t的實例數量。因此,我們可以看到當一個詞在文本中出現時,它變得更相關,這是合理的。由于術語的順序不重要,我們可以使用一個向量來描述基于詞袋模型的文本。對于論文中的每個特定術語,都有一個條目,其值是詞頻。
在文檔中出現的術語的權重與該術語的詞頻成正比。

- 延伸:BM25 TF 計算(Bese Match25 Term Frequency)
用于測量特定文檔中詞項的頻率,同時進行文檔長度和詞項飽和度的調整。

- 文檔頻率(Document Frequency)
這測試了文本在整個語料庫集合中的意義,與TF非常相似。唯一的區別在于,在文檔d中,TF是詞項t的頻率計數器,而df是詞項t在文檔集N中的出現次數。換句話說,包含該詞的論文數量即為DF。 - 倒排文檔頻率(Inverse Document Frequency)
主要用于測試詞語的相關性。搜索的主要目標是找到符合需求的適當記錄。由于tf認為所有術語同等重要,因此僅使用詞頻來衡量論文中術語的權重并不充分。

- 計算(Computation)
TF-IDF是確定一個詞對于一系列文本或語料庫的重要性的最佳度量之一。TF-IDF是一個加權系統,根據詞頻(TF)和逆文檔頻率(IDF)為文檔中的每個詞分配權重。具有更高權重得分的詞被視為更重要。

舉例:
數據來源:?瓣讀書top250圖書信息與熱?評論數據集
原始數據格式轉換
#修復后內容存盤文件
fixed = open("douban_comments_fixed.txt","w",encoding="utf-8")
#修復前內容文件
lines = [line for line in open("doubanbook_top250_comments.txt","r",encoding = "utf-8")]
print(len(lines))for i,line in enumerate(lines):#保存標題列if i == 0:fixed.write(line)prev_line = ''#上一行的書名置為空continue#提取書名和評論文本terms = line.split("\t")#當前行的書名 = 上一行的書名if terms[0] == prev_line.split("\t")[0]:#保存上一行的記錄fixed.write(prev_line + '\n')prev_line = line.strip()#保存當前行else:if len(terms) == 6:#新書評論prev_line = line.strip()#保存當前行#保存上一行記錄else:prev_line += line.strip()break
fixed.close()
- 計算TF-IDF并通過余弦相似度給出推薦列表
這里我們引用了兩個模塊,CSV和jieba
Python 的標準庫模塊 csv 提供了處理 CSV 文件的功能,其中 DictReader 類可以將每一行數據解析為字典形式。為了指定自定義的分隔符(如制表符 \t),可以通過傳遞參數 delimiter=‘\t’ 來實現。 - 參數設置
當創建 csv.DictReader 對象時,通過關鍵字參數 delimiter 設置所需的分隔符。對于制表符分隔的數據文件,應將其設為字符串 ‘\t’.
csv.DictReader() 就像一個超級高效的數據整理員,能自動將 CSV 文件轉換成易讀的字典格式。 - 關鍵特點
自動將第一行作為鍵(列名)
每一行變成一個字典
方便直接通過列名訪問數據
重點
TF-IDF傾向于過濾掉常見的詞語,保留重要的詞語。TF-IDF分數越高,表示單詞在一個文檔中出現頻繁(TF高),但在跨多文檔中出現不是很頻繁(IDF高)。
圖書推薦
基于上述描述圖書,進行推薦
import csv
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as npdef load_data(filename):# 圖書評論信息集合book_comments = {} # {書名: “評論1詞 + 評論2詞 + ...”}with open(filename,'r') as f:reader = csv.DictReader(f,delimiter='\t') # 識別格式文本中標題列for item in reader:book = item['book']comment = item['body']comment_words = jieba.lcut(comment)if book == '': continue # 跳過空書名# 圖書評論集合收集book_comments[book] = book_comments.get(book,[])book_comments[book].extend(comment_words)return book_commentsif __name__ == '__main__':# 加載停用詞列表stop_words = [line.strip() for line in open("stopwords.txt", "r", encoding="utf-8")]# 加載圖書評論信息book_comments = load_data("douban_comments_fixed.txt")print(len(book_comments))# 提取書名和評論文本book_names = []book_comms = []for book, comments in book_comments.items():book_names.append(book)book_comms.append(comments)# 構建TF-IDF特征矩陣vectorizer = TfidfVectorizer(stop_words=stop_words)tfidf_matrix = vectorizer.fit_transform([' '.join(comms) for comms in book_comms])# 計算圖書之間的余弦相似度similarity_matrix = cosine_similarity(tfidf_matrix)# 輸入要推薦的圖書名稱book_list = list(book_comments.keys())print(book_list)book_name = input("請輸入圖書名稱:")book_idx = book_names.index(book_name) # 獲取圖書索引# 獲取與輸入圖書最相似的圖書recommend_book_index = np.argsort(-similarity_matrix[book_idx])[1:11]# 輸出推薦的圖書for idx in recommend_book_index:print(f"《{book_names[idx]}》 \t 相似度:{similarity_matrix[book_idx][idx]:.4f}")print()
-
常見參數
TfidfVectorizer具有多種參數,可以根據需求進行配置:stop_words: 可以選擇去除停用詞,如 `stop_words='english'` 來移除英語的常見停用詞。max_features: 限制詞匯表的最大特征數,例如 `max_features=10` 只保留出現頻率最高的 10 個詞。ngram_range: 設置 n-gram 范圍,如 `(1, 2)` 表示提取單詞和雙詞特征。smooth_idf: 設置為 `True` 以平滑 IDF 值,避免分母為零的情況。sublinear_tf: 設置為 `True`,采用對數縮放而不是原始的詞頻。 -
應用場景
TfidfVectorizer常用于以下場景:文本分類: 將文本數據轉換為結構化格式,以便輸入到機器學習模型中。信息檢索: 在搜索引擎中,根據用戶查詢和文檔 TF-IDF 值進行排序。關鍵詞提取: 通過高 TF-IDF 值的單詞來提取文本中的關鍵詞。
語?模型 / Language Model
我們在?本識別的案例中(使? DenseNet CTC Loss 的中?印刷體識別),已經遇到了需要進?步改進的問題。
需要引?新的機制對結果再次進?打分。
語?模型就是為了解決類似這樣的問題?提出的。簡單地說,語?模型就是?來計算?個句
?的概率的模型,即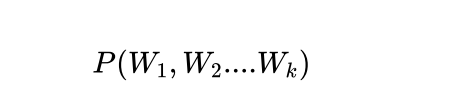
利?語?模型,可以確定哪個詞序列的可能性更?,或者給定若?個詞,可以預測下?個最
可能出現的詞。
神經?絡語?模型

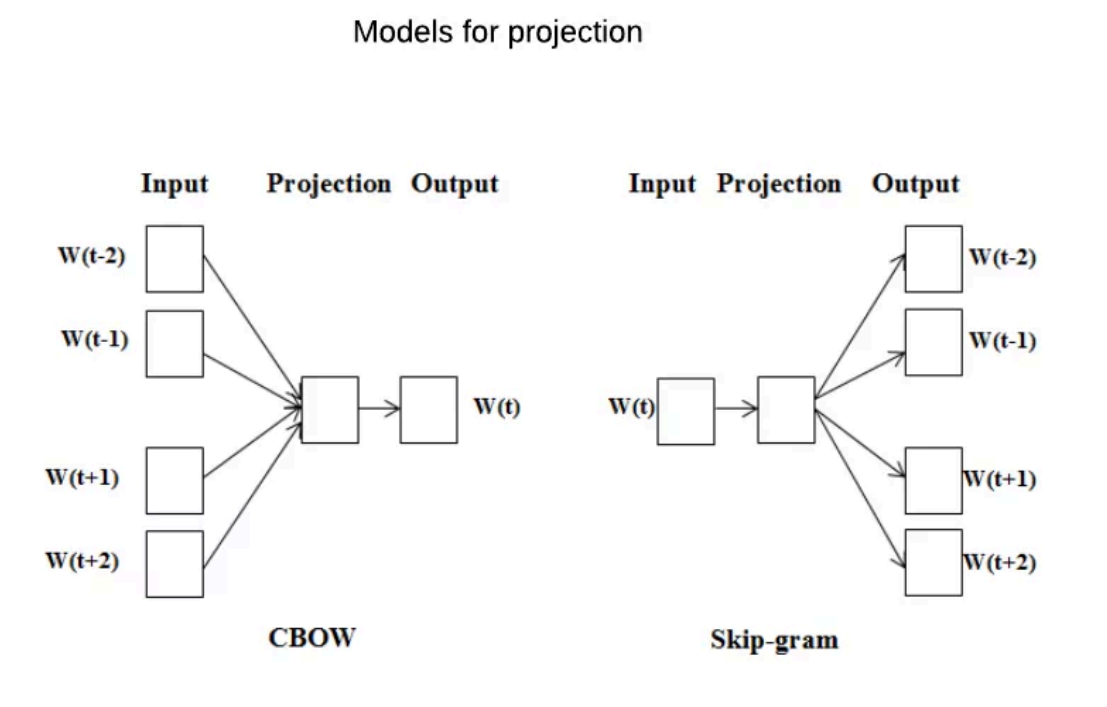
Word2Vec訓練?法
- CBOW(通過附近詞預測中?詞)
- Skip-gram(通過中?詞預測附近的詞):


fasttext
模型的結構類似于CBOW(連續詞袋模型)。模型由輸?層,隱藏層,輸出層組成,輸出層的結果是?個特定的?標。
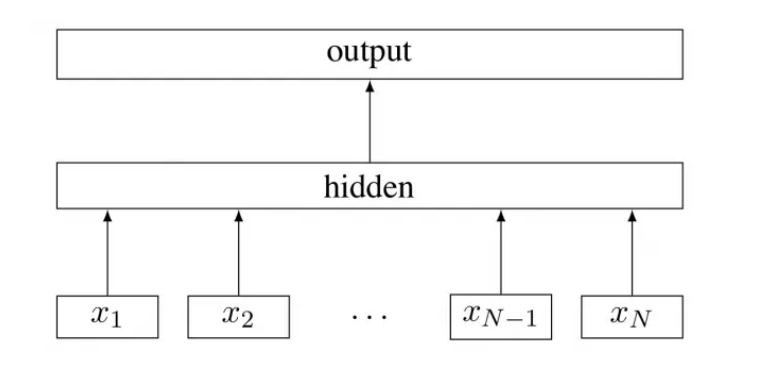
這兩個任務的是同時完成的,更具體點描述就是:在訓練?本分類模型的同時,也訓練了對
應的詞向量。?且FastText的訓練速度?word2vec更快。







)




![python manimgl數學動畫演示_微積分_線性代數原理_ubuntu安裝問題[已解決]](http://pic.xiahunao.cn/python manimgl數學動畫演示_微積分_線性代數原理_ubuntu安裝問題[已解決])




)


