目錄
- 摘要
- Abstract
- 用于檢索-增強大語言模型的查詢與重寫
- 研究背景
- 方法論
- 基于凍結LLM的重寫方案
- 基于可訓練重寫器的方案
- 重寫器預熱訓練(Rewriter Warm-up)
- 強化學習(Reinforcement Learning)
- 創新性
- 實驗結果
- 局限性
- 總結
摘要
這篇論文提出了一種名為"Rewrite-Retrieve-Read"的新型檢索增強框架,旨在改進大型語言模型(LLMs)在知識密集型任務中的表現。傳統方法采用"檢索-讀取"的兩步流程,而本文創新性地在檢索前增加了查詢重寫步驟,形成"重寫-檢索-讀取"的三步流程。核心思想是通過優化檢索查詢本身來彌合輸入文本與所需知識之間的差距,而非像以往研究那樣專注于調整檢索器或讀取器。工作流程分為三個關鍵階段:首先利用LLM或可訓練的小型語言模型(稱為"重寫器")對原始查詢進行重寫;然后使用網絡搜索引擎檢索相關文檔;最后將重寫后的查詢和檢索到的文檔一起輸入凍結的LLM讀取器生成最終答案。為進一步優化流程,作者提出了一種可訓練方案,采用T5-large作為重寫器,通過強化學習根據LLM讀取器的反饋進行訓練。實驗在開放域問答(HotpotQA、AmbigNQ、PopQA)和多項選擇問答(MMLU)任務上進行,使用ChatGPT和Vicuna-13B作為讀取器,結果顯示查詢重寫能持續提升性能,驗證了該框架的有效性和可擴展性。
Abstract
This paper introduces a new retrieval-enhanced framework called “Rewrite-Retrieve-Read,” aimed at improving the performance of large language models (LLMs) in knowledge-intensive tasks. Traditional methods use a two-step “retrieve-read” process, but this paper innovatively adds a query rewriting step before retrieval, forming a three-step “rewrite-retrieve-read” process. The core idea is to bridge the gap between the input text and the required knowledge by optimizing the retrieval query itself, rather than focusing on adjusting the retriever or reader as previous studies have done. The workflow consists of three key stages: first, using an LLM or a trainable small language model (called the “rewriter”) to rewrite the original query; then using a web search engine to retrieve relevant documents; and finally feeding the rewritten query and retrieved documents into a frozen LLM reader to generate the final answer. To further optimize the process, the authors propose a trainable approach, using T5-large as the rewriter and training it through reinforcement learning based on feedback from the LLM reader. Experiments were conducted on open-domain question answering (HotpotQA, AmbigNQ, PopQA) and multiple-choice question answering (MMLU) tasks, using ChatGPT and Vicuna-13B as readers. The results show that query rewriting consistently improves performance, validating the effectiveness and scalability of the framework.
用于檢索-增強大語言模型的查詢與重寫
Title: Query Rewriting for Retrieval-Augmented Large Language Models
Author: Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, Nan Duan
Source: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Arxiv: https://arxiv.org/abs/2305.14283
研究背景
大型語言模型雖然在自然語言處理方面展現出驚人能力,但仍面臨幻覺和時間錯位等問題,這主要源于其對大規模高質量語料庫的依賴而缺乏對現實世界的直接感知。檢索增強方法通過結合外部知識(非參數知識)和內部知識(參數知識)來緩解這些問題,已成為提高LLM事實性的標準解決方案。傳統的"檢索-讀取"框架中,檢索器首先搜索與問題相關的文檔,然后LLM接收問題和文檔并預測答案。
然而,現有方法存在明顯局限。大多數LLM只能通過推理API訪問,在流程中充當黑盒凍結讀取器的角色,這使得需要完全訪問模型參數的早期檢索增強方法不再可行。近期研究多集中于LLM導向的適配,如訓練密集檢索模型以適應凍結的語言模型,或設計檢索器與讀取器之間的交互方式。但這些方法都忽視了查詢本身的適配問題——檢索查詢要么直接來自數據集,要么由黑盒生成決定,始終固定不變,導致輸入文本與真正需要查詢的知識之間存在不可避免的差距。
黑盒API的限制
現在很多強大的LLM(如ChatGPT)只提供"輸入-輸出"的API接口,研究者無法直接調整模型內部參數。這導致早期那些需要修改LLM參數的檢索增強方法(比如讓LLM在訓練時學習如何利用檢索結果)無法繼續使用——因為現在LLM對我們來說是個"黑盒子",只能調用不能修改。
對于現有解決方案的局限性,研究者們最近主要嘗試兩種替代方案:
訓練專用檢索器:專門訓練一個檢索模型,讓它學會為特定LLM提供最合適的外部文檔
優化交互方式:設計更聰明的提示詞(prompt)讓LLM更好地使用檢索結果
但現有方法都忽略了一個根本問題:檢索查詢本身的質量。
目前要么:直接使用原始問題作為檢索詞(比如把"量子糾纏是什么?"直接扔給搜索引擎)或者讓黑盒LLM自己決定檢索詞(但無法優化這個過程)
這會導致"你說的話"和"系統真正需要查的內容"之間存在偏差。就像你想問"如何預防感冒",但直接搜索這句話可能不如搜索"增強免疫力 維生素C 臨床研究"來得有效。
舉個具體例子:
假設問題是:“《星際穿越》中那個后來成為科學家的女孩最后怎樣了?”直接檢索可能效果差,因為包含太多電影細節。
理想的重寫可能是:“星際穿越 Murph角色結局 NASA科學家”
但現有系統缺乏主動優化查詢的這個環節。
這種"問題表達"與"實際需要查找的知識"之間的不匹配,就是作者指出的"不可避免的差距"。而本文的創新點正是通過增加"查詢重寫"步驟來填補這個空白。
這一研究空白正是本文工作的出發點。作者觀察到,現有檢索增強方法過分關注檢索器或讀取器的調整,而忽略了查詢優化這一關鍵環節。特別是在處理復雜查詢(如多跳問題)時,直接使用原始問題作為檢索查詢往往效果不佳,因為這些問題可能包含冗余信息或缺乏關鍵檢索詞。此外,隨著LLM規模不斷擴大,如何高效地將小型可訓練模塊與黑盒LLM集成也成為一個重要研究問題。
方法論
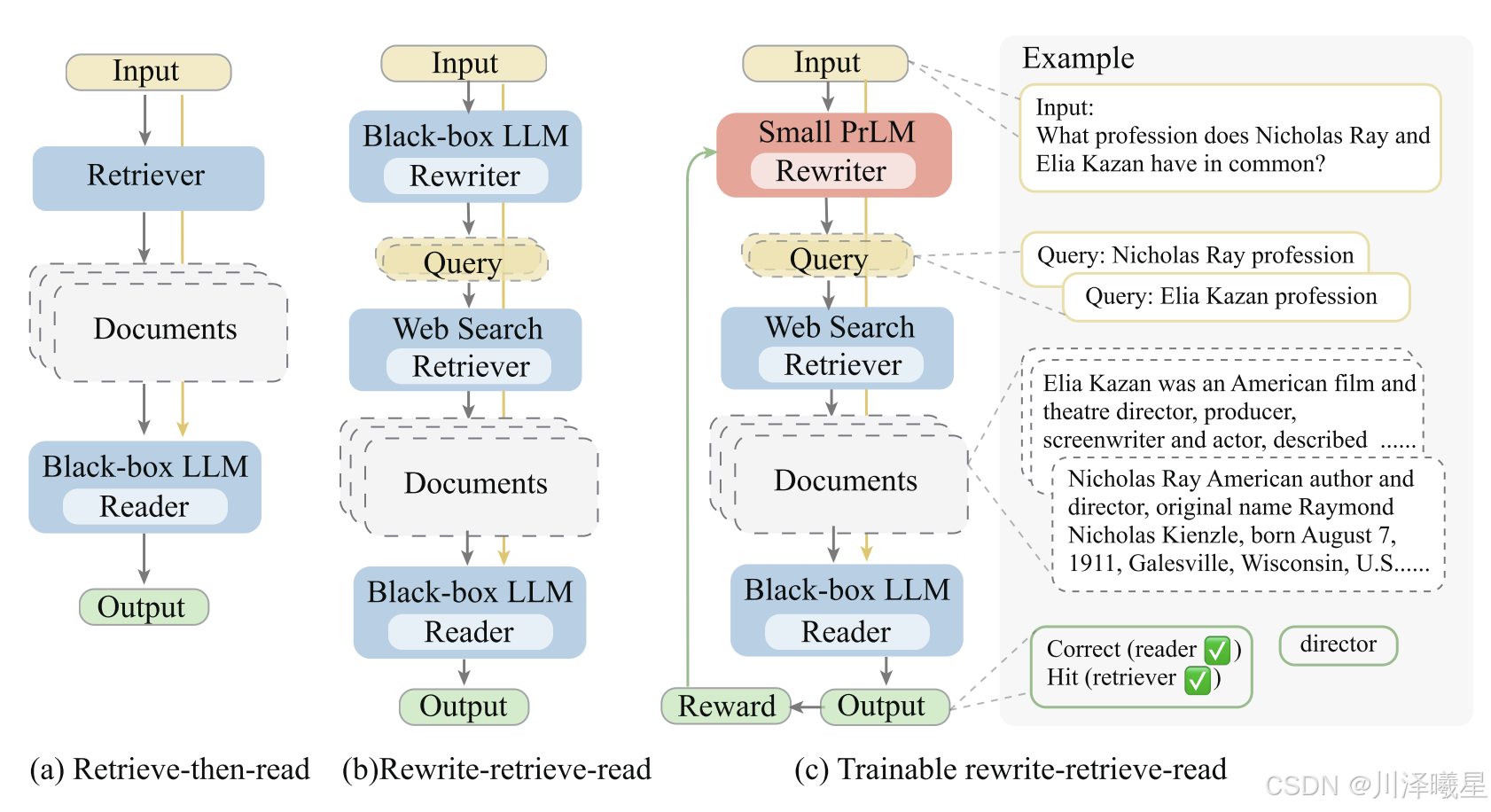
上圖直觀對比了傳統的 retrieve-then-read 方法和本文提出的 rewrite-retrieve-read 框架,并展示了可訓練重寫器的方案。
(a)標準 Retrieve-Then-Read 流程
流程步驟:
輸入(Input):原始問題或文本(如 “What is the capital of France?”)。
檢索(Retrieve):直接使用原始輸入作為查詢,從外部知識庫(如維基百科)或搜索引擎(如Bing)檢索相關文檔。
讀取(Read):將檢索到的文檔 + 原始問題一起輸入LLM(如ChatGPT),生成最終答案(如 “Paris”)。 核心問題:
查詢未優化:直接使用原始輸入檢索,可能效果不佳(例如,復雜問題、模糊表述或包含冗余信息)。
(b) LLM作為凍結重寫器的 Rewrite-Retrieve-Read
流程步驟:
輸入(Input):原始問題。
重寫(Rewrite):使用一個凍結的LLM(如ChatGPT)對原始問題重寫,生成更適合檢索的查詢。
檢索(Retrieve):用重寫后的查詢檢索文檔。
讀取(Read):將檢索結果 + 原始問題輸入LLM生成答案。
改進點: 查詢適配性增強,重寫后的查詢更精準,檢索效果更好,直接利用現成LLM的重寫能力。
局限性: 依賴LLM的提示工程(prompt design),重寫質量不穩定,并且黑盒LLM無法針對性優化。
(c)可訓練重寫器的 Rewrite-Retrieve-Read
流程步驟:
輸入(Input):原始問題。
重寫(Rewrite):使用一個可訓練的小型LM(如T5)作為重寫器,生成優化查詢。
訓練方法:
預熱訓練(Warm-up):用LLM生成的偽數據(如正確重寫樣本)監督訓練。
強化學習(RL):以LLM的答案質量作為獎勵,進一步優化重寫器(PPO算法)。
檢索(Retrieve):用訓練后的重寫器生成查詢并檢索。
讀取(Read):LLM生成最終答案。
改進點: 通過強化學習,使重寫器適配特定任務和LLM;小型重寫器比直接調用LLM更輕量。
關鍵設計: 獎勵函數(Reward)基于LLM輸出的答案質量(如EM、F1分數)和檢索命中率; KL散度正則化防止重寫器偏離初始語言模型太遠。
本文提出的"重寫-檢索-讀取"框架包含三個核心組成部分:查詢重寫、檢索和讀取。在技術實現上,作者探索了兩種主要方案:基于凍結LLM的重寫方案和基于可訓練重寫器的方案。
基于凍結LLM的重寫方案
基于凍結LLM的重寫方案采用少量示例提示(few-shot prompting)的方式,引導LLM對原始查詢進行重寫。具體而言,提示模板包含指令、示范和輸入三部分,指令簡明扼要,示范則來自訓練集中的1-3個隨機示例,主要用于說明任務特定的輸出格式。這種方法無需額外訓練,直接利用LLM的推理能力生成更適合檢索的查詢。例如,對于開放域問答任務,提示LLM逐步思考并生成所需知識的搜索引擎查詢;對于多項選擇任務,則提示生成能更好回答給定問題的網頁搜索查詢。
基于可訓練重寫器的方案
更具創新性的是可訓練重寫器方案。作者采用T5-large(770M參數)作為基礎模型,通過兩階段過程進行訓練:預熱訓練和強化學習。
重寫器預熱訓練(Rewriter Warm-up)
在預熱階段,首先構建偽數據集——使用LLM重寫訓練集中的原始問題,并篩選那些能使LLM讀取器做出正確預測的樣本作為訓練數據。重寫器通過標準對數似然目標進行監督訓練,使其初步掌握查詢重寫的基本模式。
目標:讓重寫器初步學會生成合理的查詢。
-
偽數據生成:
- 用LLM(如ChatGPT)重寫訓練集中的原始問題 x x x,生成候選查詢 x ~ \tilde{x} x~。
- 篩選能使LLM讀者輸出正確答案的樣本,構成預熱數據集:
D T r a i n = { ( x , x ~ ) ∣ y ^ = y } D_{Train} = \{(x, \tilde{x}) \mid \hat{y} = y\} DTrain?={(x,x~)∣y^?=y}
-
訓練目標(最大似然估計):
L w a r m = ? ∑ t log ? p θ ( x ~ t ∣ x ~ < t , x ) \mathcal{L}_{warm} = -\sum_{t} \log p_{\theta}(\tilde{x}_t \mid \tilde{x}_{<t}, x) Lwarm?=?t∑?logpθ?(x~t?∣x~<t?,x)- x ~ t \tilde{x}_t x~t?:查詢的第 t t t個token
- x ~ < t \tilde{x}_{<t} x~<t?:已生成的前 t ? 1 t-1 t?1個token
- θ \theta θ:重寫器參數
每一項 log ? p θ ( x ~ t ∣ x ~ < t , x ) \log p_{\theta}(\tilde{x}_t \mid \tilde{x}_{<t}, x) logpθ?(x~t?∣x~<t?,x) 表示在給定原始問題 x x x 和已生成部分 x ~ < t \tilde{x}_{<t} x~<t? 的條件下,模型對下一個正確token x ~ t \tilde{x}_t x~t? 的預測概率。最小化NLL等價于讓模型對真實token分配更高概率。
查詢重寫器模塊:
class QueryRewriter:def __init__(self, model_name="t5-large"):self.model = T5ForConditionalGeneration.from_pretrained(model_name)self.tokenizer = T5Tokenizer.from_pretrained(model_name)def warm_up_train(self, dataset):# dataset: List[{"original": str, "rewritten": str}]optimizer = torch.optim.Adam(self.model.parameters(), lr=3e-5)for batch in dataloader:inputs = self.tokenizer(batch["original"], return_tensors="pt",padding=True)labels = self.tokenizer(batch["rewritten"], return_tensors="pt",padding=True).input_idsoutputs = self.model(input_ids=inputs.input_ids,attention_mask=inputs.attention_mask,labels=labels)loss = outputs.lossloss.backward()optimizer.step()def rewrite(self, query):inputs = self.tokenizer(query, return_tensors="pt")outputs = self.model.generate(**inputs)return self.tokenizer.decode(outputs[0], skip_special_tokens=True)
強化學習(Reinforcement Learning)
強化學習階段則采用近端策略優化(PPO)算法進一步調整重寫器。將重寫器優化問題建模為馬爾可夫決策過程,其中狀態空間由詞匯表和序列長度限定,動作空間等同于詞匯表,轉移概率由策略網絡(即重寫器模型)決定。獎勵函數基于LLM讀取器的預測質量設計,包含精確匹配(EM)、F1分數和命中指示器等指標,同時加入KL散度正則化防止模型偏離初始策略太遠。價值網絡從策略網絡初始化,采用廣義優勢估計(GAE)計算優勢函數。通過這種設計,重寫器能夠學習生成那些能引導檢索器找到更有用文檔、進而幫助LLM讀取器做出更準確預測的查詢。
目標:通過LLM讀者的反饋進一步優化重寫器。
-
馬爾可夫決策過程(MDP)建模:
- 狀態 s t s_t st?:當前生成的部分查詢 [ x , x ~ ^ < t ] [x, \hat{\tilde{x}}_{<t}] [x,x~^<t?]
- 動作 a t a_t at?:選擇下一個token x ~ ^ t \hat{\tilde{x}}_t x~^t?
- 策略 π θ \pi_{\theta} πθ?:重寫器模型 G θ G_{\theta} Gθ?
- 獎勵 R R R:基于LLM讀者的答案質量
-
獎勵函數設計:
R ( s t , a t ) = R l m ( x ~ ^ , y ) ? β KL ( π θ ∥ π 0 ) R(s_t, a_t) = R_{lm}(\hat{\tilde{x}}, y) - \beta \text{KL}(\pi_{\theta} \| \pi_{0}) R(st?,at?)=Rlm?(x~^,y)?βKL(πθ?∥π0?)- R l m R_{lm} Rlm?:LLM讀者的表現(如EM/F1分數)
- KL \text{KL} KL項:防止重寫器偏離初始策略 π 0 \pi_{0} π0?(預熱后的模型)
- β \beta β:平衡系數(動態調整)
-
策略優化(PPO算法):
- 優化目標:
max ? θ E x ~ ^ ~ p θ ( ? ∣ x ) [ R ( x , x ~ ^ ) ] \max_{\theta} \mathbb{E}_{\hat{\tilde{x}} \sim p_{\theta}(\cdot|x)}[R(x, \hat{\tilde{x}})] θmax?Ex~^~pθ?(?∣x)?[R(x,x~^)] - 具體損失函數:
L θ = ? 1 ∣ S ∣ T ∑ τ ∈ S ∑ t = 0 T min ? ( k t , θ A θ ′ , clip ( k t , θ , 1 ? ? , 1 + ? ) A θ ′ ) \mathcal{L}_{\theta} = -\frac{1}{|\mathcal{S}|T} \sum_{\tau \in \mathcal{S}} \sum_{t=0}^{T} \min(k_{t,\theta} A^{\theta'}, \text{clip}(k_{t,\theta}, 1-\epsilon,1+\epsilon) A^{\theta'}) Lθ?=?∣S∣T1?τ∈S∑?t=0∑T?min(kt,θ?Aθ′,clip(kt,θ?,1??,1+?)Aθ′)
k t , θ = p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) k_{t,\theta} = \frac{p_{\theta}(a_t \mid s_t)}{p_{\theta'}(a_t \mid s_t)} kt,θ?=pθ′?(at?∣st?)pθ?(at?∣st?)?- A θ ′ A^{\theta'} Aθ′:優勢函數(GAE估計)
- θ ′ \theta' θ′:舊策略參數(采樣時固定)
- clip \text{clip} clip:防止策略更新過大
- 優化目標:
-
價值函數訓練:
L ? = 1 ∣ S ∣ T ∑ τ ∈ S ∑ t = 0 T ( V ? ( s t ) ? R t ) 2 \mathcal{L}_{\phi} = \frac{1}{|\mathcal{S}|T} \sum_{\tau \in \mathcal{S}} \sum_{t=0}^{T} (V_{\phi}(s_t) - R_t)^2 L??=∣S∣T1?τ∈S∑?t=0∑T?(V??(st?)?Rt?)2- V ? V_{\phi} V??:價值網絡(從策略網絡初始化)
- R t R_t Rt?:累計獎勵
-
總損失函數:
L p p o = L θ + λ v L ? \mathcal{L}_{ppo} = \mathcal{L}_{\theta} + \lambda_v \mathcal{L}_{\phi} Lppo?=Lθ?+λv?L??- λ v \lambda_v λv?:價值損失權重
核心創新點:
- 兩階段訓練:預熱(模仿學習)→ RL(精細優化)
- KL正則化:避免重寫器生成不合理查詢
- 輕量化設計:小型重寫器(T5-large)適配黑盒LLM
class RLTraining:def __init__(self, rewriter, llm_reader):self.rewriter = rewriterself.llm_reader = llm_reader # Black-box LLM (e.g. ChatGPT API)ppo_config = PPOConfig(batch_size=16,learning_rate=2e-6,kl_divergence_coeff=0.2)self.ppo_trainer = PPOTrainer(model=self.rewriter.model,config=ppo_config)def compute_reward(self, queries, answers, gold_answers):# 實現論文中的獎勵函數 em_reward = exact_match(answers, gold_answers)f1_reward = f1_score(answers, gold_answers)hit_reward = 1 if answer_in_retrieved_docs() else -1return em_reward + 1.0*f1_reward + 1.0*hit_rewarddef train_step(self, queries, gold_answers):# 生成重寫查詢rewritten_queries = [self.rewriter.rewrite(q) for q in queries]# 檢索文檔 retrieved_docs = bing_search(rewritten_queries)# LLM生成答案llm_inputs = [f"{doc} {q}" for doc,q in zip(retrieved_docs, queries)]answers = chatgpt_api(llm_inputs)# 計算獎勵rewards = self.compute_reward(rewritten_queries, answers, gold_answers)# PPO更新self.ppo_trainer.step(queries, rewritten_queries, rewards)
在檢索環節,作者使用Bing搜索引擎作為檢索器,避免了構建和維護搜索索引的開銷,并能訪問最新知識。檢索采用兩種方式:一是拼接搜索引擎返回的相關片段;二是獲取網頁URL并解析全部文本,然后使用BM25算法保留與查詢相關性較高的部分以減少文檔長度。讀取環節則采用凍結的LLM(如ChatGPT或Vicuna-13B)進行閱讀理解,同樣使用少量示例提示的方式進行預測。
創新性
本文的核心創新點在于首次提出了從查詢重寫角度改進檢索增強LLM的框架,具有多重理論和方法創新價值。
最顯著的貢獻是突破了傳統"檢索-讀取"范式的局限,開創性地增加了查詢重寫環節,形成了"重寫-檢索-讀取"的新范式。這一創新源于對檢索過程中"查詢-知識"差距的深刻洞察——原始輸入往往不是最優的檢索查詢,特別是在處理復雜、模糊或專業性強的任務時。通過引入重寫環節,系統能夠主動調整查詢形式,更精準地表達信息需求,從而顯著提升后續檢索和讀取的效果。
在技術層面,作者提出了一個精巧的可訓練方案,將小型語言模型作為重寫器與黑盒LLM讀取器協同工作。這一設計既保持了LLM的強大能力,又通過小型可訓練模塊實現了流程優化,計算效率高且實用性強。特別是采用強化學習將重寫器與LLM讀取器的表現直接關聯,創造性地解決了黑盒模型難以端到端訓練的挑戰。這種"小模型引導大模型"的思路為整合可訓練模塊與商業LLM API提供了新范式。
實驗設計上也體現了創新性。作者不僅比較了傳統檢索與查詢重寫的效果,還深入分析了不同配置下的性能差異,包括使用不同檢索方法(片段vs BM25)、不同讀取器(ChatGPT vs Vicuna)等。特別有價值的是對重寫查詢的案例分析,直觀展示了查詢優化如何影響檢索結果和最終答案質量。例如,在多跳問題中,好的重寫能夠聚焦關鍵實體和關系;在模糊問題中,重寫可以添加明確的約束條件;在專業性問題中,重寫可以突出術語和背景。
此外,使用網絡搜索引擎作為檢索器也是一個務實而創新的選擇。相比專業構建的知識庫,這種方法知識覆蓋面廣、實時性強,能夠緩解LLM的時間錯位問題。作者也坦誠討論了這一選擇的利弊,為后續研究提供了寶貴經驗。
實驗結果
論文在開放域問答和多項選擇問答兩大類任務上進行了全面實驗驗證,涵蓋了多種難度和類型的問題。
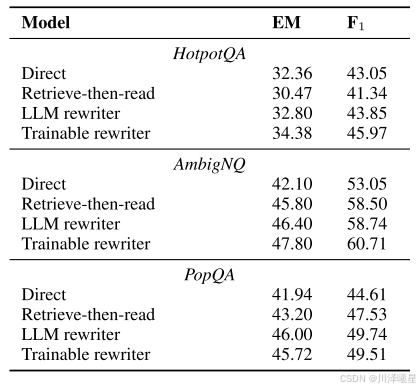
在開放域問答任務中,HotpotQA包含需要多跳推理的復雜問題,AmbigNQ提供自然問題的消歧版本,PopQA則包含更多長尾分布知識。實驗結果顯示,查詢重寫在所有數據集上均帶來性能提升。特別值得注意的是,在HotpotQA上標準檢索反而損害了讀取器性能,說明復雜問題直接作為查詢會引入噪聲;而增加重寫步驟后性能顯著提高,證明重寫能有效優化多跳問題的檢索效果。在AmbigNQ和PopQA上,標準檢索已有所幫助,而查詢重寫能進一步提升性能,其中LLM重寫器表現最佳,訓練后的T5重寫器次之但優于標準檢索。
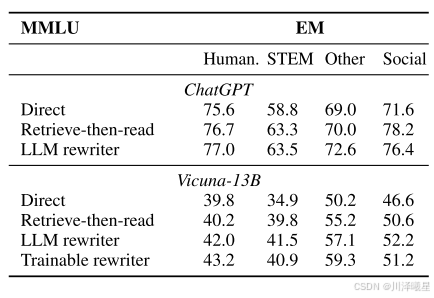
多項選擇問答任務使用MMLU數據集,涵蓋人文、STEM、社會科學和其他四大類考試題目。實驗發現,使用ChatGPT作為讀取器時,查詢重寫在大多數類別上提高了分數(社會科學除外);使用Vicuna作為讀取器時,查詢重寫在所有類別上都獲得了更大提升。這表明更強大的讀取器擁有更多參數記憶,更需要通過優化檢索來補充外部知識。
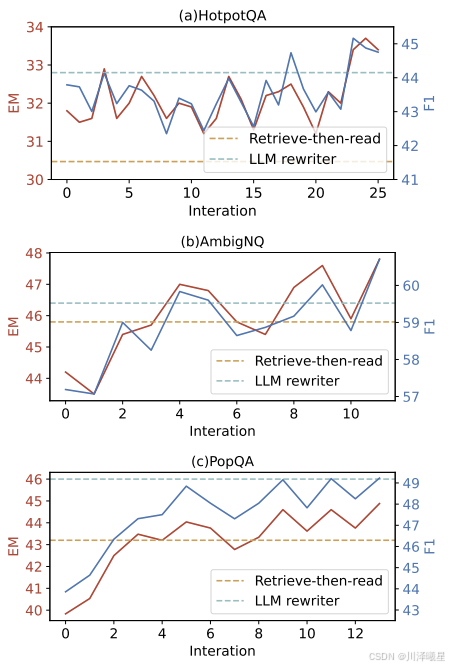
作者還對訓練過程和檢索結果進行了深入分析。強化學習曲線顯示,隨著訓練迭代,所有數據集的指標總體呈上升趨勢,說明RL階段能夠彌補預熱訓練的不足。檢索分析則表明,查詢重寫顯著提高了檢索命中率(AmbigNQ上從76.4%提升到82.2%),且檢索效果的改善幅度大于讀取器的提升幅度,這與相關研究發現一致。
案例研究生動展示了查詢重寫如何改變檢索結果和預測性能。一個好的重寫能夠:(1)重組問題結構,將關鍵信息前置;(2)消除歧義,避免錯誤解讀;(3)簡化復雜背景,突出核心概念。例如,在多跳問題中,好的重寫會聚焦關鍵人物關系;在模糊問題中,重寫可以修正時間表述;在專業問題中,重寫會強調術語和背景。
局限性
盡管取得了顯著成果,作者也坦誠指出了工作的幾點局限性。
首先是通用性與專用性之間的權衡問題。增加訓練過程雖然提高了特定任務性能,但相比少量示例提示的直接遷移能力有所下降。這意味著該方法在需要快速適應新任務的場景中可能不如純提示方法靈活。
其次,與新興的"LLM智能體"研究方向相比,本文框架采用單輪檢索策略,而智能體方法通常需要多次調用LLM進行多輪檢索和交互。雖然單輪設計效率更高,但在處理極其復雜的問題時可能不如多輪方法全面。作者明確表示其動機是改進單輪檢索-讀取框架,而非探索更復雜的交互模式。
第三,使用網絡搜索引擎作為檢索器雖然便利,但也帶來一些挑戰。商業API需要訂閱,且網絡知識難以控制,可能返回不一致、冗余甚至有害內容,影響LLM讀取器。相比之下,基于專業篩選知識庫的神經密集檢索器可能獲得更可控的檢索結果。
此外,還有一些潛在限制未在文中明確討論但值得思考。例如,查詢重寫質量高度依賴預熱階段生成的偽數據質量;強化學習訓練過程計算成本較高;不同領域和任務可能需要設計特定的獎勵函數;框架對搜索引擎API的依賴可能影響可復現性等。
總結
《Query Rewriting for Retrieval-Augmented Large Language Models》這篇論文提出了一種創新且實用的檢索增強框架,通過引入查詢重寫步驟顯著提升了大型語言模型在知識密集型任務中的表現。其核心價值在于突破了傳統方法僅關注檢索器或讀取器優化的局限,開創性地從查詢適配角度解決問題,為檢索增強LLM研究提供了新視角。方法論上,論文的亮點在于巧妙結合了凍結LLM的強大能力和小型可訓練模塊的靈活性,特別是通過強化學習將重寫器與黑盒LLM的反饋相連接,為解決類似集成問題提供了范例。實驗設計全面,結果分析深入,不僅驗證了框架的有效性,還揭示了不同配置下的性能特點,為后續研究提供了豐富參考。從更廣的視角看,這項工作反映了LLM研究的一個重要趨勢:如何在保持商業LLM黑盒特性的同時,通過可訓練模塊和外部工具擴展其能力邊界。查詢重寫的思想不僅適用于檢索增強場景,也可推廣到其他工具使用場景,如代碼解釋器、專業模型調用等,具有廣泛的應用潛力。當然,如同作者指出的,該方法仍有改進空間,特別是在平衡通用性與專用性、處理復雜多輪交互、提高檢索結果可控性等方面。未來研究可以探索更智能的多輪重寫策略、結合專業知識庫的混合檢索方式,以及更高效的訓練算法等方向。總的來說,這篇論文在檢索增強語言模型領域做出了實質性貢獻,提出的"重寫-檢索-讀取"框架和可訓練方案既有理論創新又具實用價值,為提升LLM的事實性和可靠性提供了有效工具,對相關研究和應用都具有重要啟發意義。
)






-Nodejs開發入門)

 三十二、(TGRS 2024) MDAF 多尺度雙表示對齊過濾器)
 == hash(-2)?)




)

R語言實現)

