目錄
📌?核心特性
📌 運行原理
(1)全腳本執行
(2)差異更新
📌 緩存機制
?為什么使用緩存?
使用@st.cache_data的優化方案
緩存適用場景
使用st.session_state的優化方案
📌總結
Streamlit 是一個開源的 Python 庫,專為快速構建數據科學和機器學習 Web 應用而設計。它無需前端開發經驗,通過簡單 API 即可創建交互式界面,適合原型開發和數據展示
Streamlit官方地址:Streamlit ? A faster way to build and share data apps
📌?核心特性
- 極簡代碼:用純 Python 實現界面交互
- 實時預覽:保存代碼后自動刷新頁面
- 豐富組件:支持圖表、表格、滑塊、文件上傳等
- 無縫集成:兼容 Pandas、Matplotlib、PyTorch 等主流庫
安裝Streamlit
pip3 install streamlit先通過一個簡單的Hello World案例來了解Streamlit
import streamlit as st# 顯示標題
st.title("Hello World,I'm echola")# 顯示文本
st.write("這是一個由Streamlit搭建的Web平臺")
運行:
streamlit run hello.py結果:
 ?是不是很強悍,三行代碼搞定一個Web應用
?是不是很強悍,三行代碼搞定一個Web應用
📌 運行原理
Streamlit 的運行邏輯圍繞腳本的線性執行和響應式更新展開,其核心設計是讓開發者以極簡的方式構建交互式應用。以下是關鍵邏輯分步解析:
1、啟動Web服務器
- ?Streamlit 啟動一個本地 Web 服務器,默認監聽 8501 端口
- 打開瀏覽器并導航到 http://localhost:8501,展示應用界面
2、解析和執行腳本:
- Streamlit 解析 hello.py 文件,生成抽象語法樹(AST)
- 動態執行腳本中的代碼,按照順序執行每個 Streamlit 組件(如 st.title 和 st.write)
3、組件渲染
- 每個 Streamlit 組件(如 st.title 和 st.write)會被注冊到當前頁面的狀態中
- 頁面會根據組件的順序和內容進行渲染
4、實時更新:
- 基于Websocket通信:瀏覽器與服務器保持長連接,腳本輸出的文本、圖表等實時推送至前端
- 增量更新機制:Streamlit只能對比前后兩次執行的輸出差異,僅向瀏覽器發送差異部分,也就是只更新變化的部分(而非刷新整個頁面),Streamlit 會自動重新運行政整個腳本(而非局部更新)并更新頁面,確保了開發過程中的高效性和實時性
上述增量更新可能會有一點矛盾,簡而言之就是,「全腳本執行 + 差異更新」的設計,讓 Streamlit 在開發便捷性(無需手動管理更新)和運行效率(局部渲染)之間取得了完美平衡
(1)全腳本執行
??:也要避免全局作用域的冗余計算(需用緩存優化)
下來使用一個簡單的案例,來模擬Streamlit加載全腳本的耗時過程
import time
import streamlit as st# 全腳本執行部分:以下代碼每次交互都會運行
st.title("TimeOut Example") # ? 標題會重復渲染,但 Streamlit 會優化為"增量更新"# 局部增量執行:以下代碼僅在按鈕點擊時觸發
if st.button("Click me"):processing_bar = st.progress(0) # 每次點擊時新建進度條with st.spinner("Loading..."):for percent_complete in range(100):time.sleep(0.05)processing_bar.progress(percent_complete + 1)st.success("Loading completed!")
?當用戶點擊按鈕時,觸發 if 條件判斷,顯示加載提示框 "Loading..."。開始模擬耗時操作,通過循環和 time.sleep 模擬耗時。每次循環中,更新進度條的值,進度條從0%逐漸增加到100%
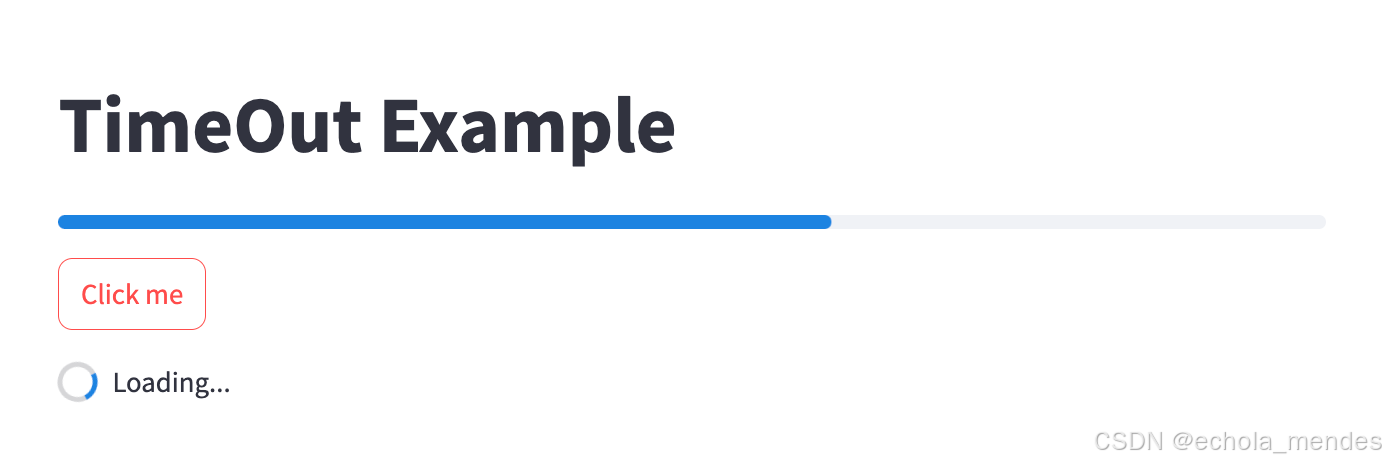
直至耗時完成5s后,隱藏加載提示框,顯示成功消息框”Loading completed“

再次點擊【Click me】,?重復上述效果圖
可以從上述效果中看出,無論是頁面首次加載、按鈕點擊,還是其他組件交互(如下拉框選擇),Streamlit都會從頭到尾重新執行整個腳本
雖然腳本會全量執行,但Streamlit內部通過智能的組件狀態管理和緩存機制,只更頁面中發生變化的部分(如按鈕觸發的進度條),而不是刷新整個頁面
接下來會使用緩存機制進行優化?
(2)差異更新
?可以高效渲染(減少網絡傳輸數據量和瀏覽器渲染開銷)和無縫體驗(用戶輸入狀態,如:文本框焦點、滾動條位置,不會因為局部更新而丟失)
??:也要關注復雜UI的組件鍵(Key)的穩定性
📌 緩存機制
?為什么使用緩存?
🔴 問題:每次點擊click按鈕時,代碼會從執行整個耗時操作(for循環+time.sleep),即使操作結果不變
🥀 緩存的作用:將耗時操作的結果緩存起來,后續重復調用時直接讀取緩存,避免重復計算
解決重復計算問題:通過裝飾器@st.cache_data(緩存數據)或@st.cache_resource(緩存資源如模型、數據庫連接),避免腳本執行導致的重復計算
@st.cache_data
def heavy_computation():# 此函數僅在輸入參數或代碼變更時重新執行return result使用@st.cache_data的優化方案
那優化一下上面提到的問題
import time
import streamlit as stst.title("Optimize Example")# 緩存耗時操作的結束(假設操作是無參數)
@st.cache_data
def expensive_operation():# 模擬耗時操作(例如:數據計算)result = []for _ in range(100):time.sleep(0.05) # 假設這是實際的計算步驟result.append(_) # 模擬中間結果return resultif st.button("Click me"):processing_bar = st.progress(0) # 每次點擊時新建進度條with st.spinner("Loading..."):# 獲取數據(首次點擊執行耗時操作,后續點擊直接讀緩存)data = expensive_operation()for percent_complete in range(len(data)):processing_bar.progress(percent_complete + 1)st.success("Loading completed!")
首次點擊【Click me】,會出現

大概5s后,執行完成
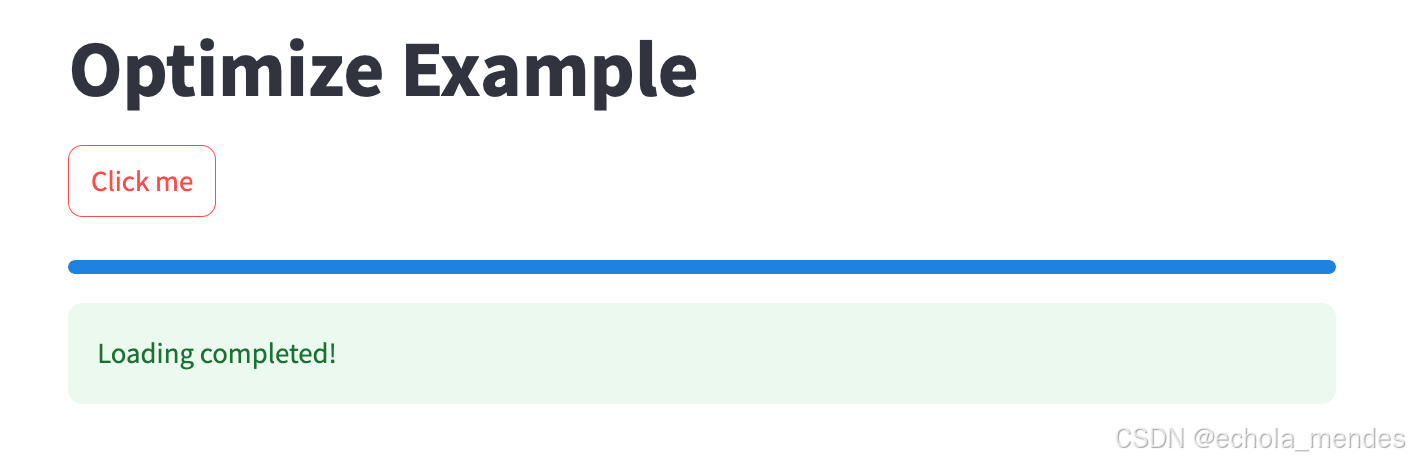 ?重復點擊【Click me】?,不會重復加載進度條,由于直接讀取緩存結果,無需重復計算,數據已緩存,進度條會快速更新到100%
?重復點擊【Click me】?,不會重復加載進度條,由于直接讀取緩存結果,無需重復計算,數據已緩存,進度條會快速更新到100%
通過 @st.cache_data 裝飾器緩存耗時操作的結果,避免每次點擊按鈕時都重新執行耗時操作
不是所有耗時操作都必須使用緩存
緩存適用場景
- 需要緩存的場景:
- 耗時操作的結果是?靜態的(例如讀取文件、初始化模型、復雜計算)。
- 操作結果?不依賴外部變量或用戶輸入。
- 不適用緩存場景:
- 操作結果?依賴動態參數(例如用戶輸入的變量),此時需通過函數參數觸發緩存更新。
- 操作需要?實時更新(例如每次點擊都需重新計算)
如果耗時操作?依賴參數,可以通過函數參數控制緩存版本:
@st.cache_data
def expensive_operation(param1, param2):# 根據參數執行不同計算results = []for _ in range(100):time.sleep(0.05)results.append(param1 + param2 + _)return results# 在按鈕點擊時傳入參數
data = expensive_operation(10, 20) # 參數不同會生成不同緩存可以看出:
- 緩存機制:通過?
@st.cache_data?緩存靜態計算結果,減少重復執行。 - 進度條優化:將耗時操作與進度條更新分離,首次加載緩存后,后續交互可快速完成
那上述代碼就沒有什么問題了嗎?
??接下來分析原代碼存在的弊端:
- 進度條重復創建:每次點擊按鈕都會新建processing_bar,導致多次點擊時進度條堆疊
- 無法阻止重復提交:在耗時操作執行期間,用戶仍可多次點擊按鈕,導致邏輯混亂
- 狀態丟失:進度完成后的狀態(如success提示)無法持久化
使用st.session_state的優化方案
1、保存進度條實例
if "processing_bar" not in st.session_state:st.session_state.processing_bar = None # 初始化進度條容器if st.button("Click me"):# 僅在第一次點擊時創建進度條if not st.session_state.processing_bar:st.session_state.processing_bar = st.progress(0)# 后續操作復用已有進度條with st.spinner("Loading..."):data = expensive_operation()for i in range(len(data)):st.session_state.processing_bar.progress(i + 1)# 完成后清空引用st.session_state.processing_bar = Nonest.success("Done!")2. 防止重復提交
if "is_processing" not in st.session_state:st.session_state.is_processing = False # 狀態鎖if st.button("Click me") and not st.session_state.is_processing:st.session_state.is_processing = True # 鎖定try:# 執行耗時操作...finally:st.session_state.is_processing = False # 釋放3. 持久化完成狀態
if "load_complete" not in st.session_state:st.session_state.load_complete = Falseif st.button("Click me"):# 執行操作...st.session_state.load_complete = Trueif st.session_state.load_complete:st.success("數據已加載完成!")st.balloons() # 顯示動畫效果?完整優化代碼
import time
import streamlit as stst.title("Optimized Example")# 初始化會話狀態
if "processing_bar" not in st.session_state:st.session_state.processing_bar = None
if "is_processing" not in st.session_state:st.session_state.is_processing = False
if "load_complete" not in st.session_state:st.session_state.load_complete = False@st.cache_data
def expensive_operation():result = []for _ in range(100):time.sleep(0.05)result.append(_)return resultif st.button("Click me") and not st.session_state.is_processing:st.session_state.is_processing = Truetry:# 創建或復用進度條if not st.session_state.processing_bar:st.session_state.processing_bar = st.progress(0)with st.spinner("Loading..."):data = expensive_operation()for i in range(len(data)):st.session_state.processing_bar.progress(i + 1)st.session_state.load_complete = Truefinally:st.session_state.is_processing = Falsest.session_state.processing_bar = None # 重置進度條if st.session_state.load_complete:st.success("操作成功!")st.balloons()關鍵作用總結
| 會話狀態項 | 功能說明 |
|---|---|
processing_bar | 保持進度條對象引用,防止重復創建 |
is_processing | 實現類似互斥鎖,防止重復提交 |
load_complete | 持久化完成狀態,實現跨腳本執行記憶 |
通過?st.session_state?實現了:
- 狀態持久化:在 Streamlit 的全腳本重執行機制中保持關鍵狀態
- 資源管理:避免 DOM 元素重復創建
- 交互安全:防止用戶誤操作導致的邏輯沖突
?這種模式特別適合需要保持復雜交互狀態的場景(如多步驟表單、長任務處理)
📌總結
通過?緩存機制?減少重復計算,結合?st.session_state?管理會話狀態,Streamlit 可以高效處理復雜交互場景,同時保持代碼簡潔和用戶體驗流暢。這種優化策略尤其適合需要頻繁交互、狀態保持或耗時操作的 Web 應用開發?








)










