RNN、LSTM、GRU匯總
- 0、論文匯總
- 1.RNN論文
- 2、LSTM論文
- 3、GRU
- 4、其他匯總
- 1、發展史
- 2、配置和架構
- 1.配置
- 2.架構
- 3、基本結構
- 1.神經元
- 2.RNN
- 1. **RNN和前饋網絡區別:**
- 2. 計算公式:
- 3. **梯度消失:**
- 4. **RNN類型**:(查看發展史)
- 5. **網絡區別**
- 3.LSTM
- 1、RNN中梯度問題
- 2、LSTM結構
- 3、LSTM梯度緩解
- 一、LSTM 反向傳播求導核心推導
- 1. **定義反向傳播變量**
- 2. **輸出門 o t o_t ot? 的梯度**
- 3. **細胞狀態 c t c_t ct? 的梯度**
- 4. **遺忘門 f t f_t ft?、輸入門 i t i_t it?、候選細胞 c ~ t \tilde{c}_t c~t? 的梯度**
- 5. **向過去時刻傳遞梯度**
- 二、梯度消失的緩解:LSTM 結構設計核心
- 三、梯度爆炸的緩解:訓練階段的外部策略
- 四、總結
- 4.GRU
0、論文匯總
1.RNN論文
傳統RNN經典結構:Elman Network、Jordan Network、Bidirectional RNN
Jordan RNN于1986年提出:《SERIAL ORDER: A PARALLEL DISTRmUTED PROCESSING APPROACH》
Elman RNN于1990年提出:《Finding Structure in Time》
《LSTM原始論文:Long Short-Term Memory》
2、LSTM論文
論文原文
地址01:https://arxiv.org/pdf/1506.04214.pdf
地址02:https://www.bioinf.jku.at/publications/older/2604.pdf
《舊:Convolutional LSTM Network: A Machine Learning
Approach for Precipitation Nowcasting》
《LSTM原始論文:Long Short-Term Memory》
3、GRU
《GRU原始論文:Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》
門控循環單元 (Gate Recurrent Unit, GRU) 于 2014 年提出,原論文為《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》。
4、其他匯總
維基百科RNN總結(發展史):https://en.wikipedia.org/wiki/Recurrent_neural_network
傳統RNN經典結構:Elman Network、Jordan Network、Bidirectional RNN
Jordan RNN于1986年提出:《SERIAL ORDER: A PARALLEL DISTRmUTED PROCESSING APPROACH》
Elman RNN于1990年提出:《Finding Structure in Time》
《LSTM原始論文:Long Short-Term Memory》
《GRU原始論文:Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》
門控循環單元 (Gate Recurrent Unit, GRU) 于 2014 年提出,原論文為《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》。
博客鏈接:https://blog.csdn.net/u013250861/article/details/125922368
時間系列相關:https://zhuanlan.zhihu.com/p/637171880
論文名:Recurrent Neural Network Regularization(正則化)
論文地址:https://arxiv.org/abs/1409.2329v5
循環神經網絡(Recurrent Neural Network,RNN)
適用于處理序列數據,如文本、語音等。它在隱藏層中引入了循環連接,使得神經元能夠記住過去的信息。其中,長短期記憶網絡(Long Short-Term Memory,LSTM)和門控循環單元(Gate Recurrent Unit,GRU)是 RNN 的改進版本,能夠更好地處理長序列中的長期依賴關系。
公式:https://zhuanlan.zhihu.com/p/149869659
1、發展史
https://en.wikipedia.org/wiki/Recurrent_neural_network
現代 RNN 網絡主要基于兩種架構:LSTM 和 BRNN。[ 32 ]
在 20 世紀 80 年代神經網絡復興之際,循環網絡再次受到研究。它們有時被稱為“迭代網絡”。[ 33 ]兩個早期有影響力的作品是Jordan 網絡(1986 年)和Elman 網絡(1990 年),它們將 RNN 應用于認知心理學研究。1993 年,一個神經歷史壓縮系統解決了一項“非常深度學習”任務,該任務需要RNN 中隨時間展開的1000 多個后續層。 [ 34 ]
長短期記憶(LSTM) 網絡由Hochreiter和Schmidhuber于 1995 年發明,并在多個應用領域創下了準確率記錄。[ 35 ] [ 36 ]它成為 RNN 架構的默認選擇。
雙向循環神經網絡(BRNN) 使用兩個以相反方向處理相同輸入的 RNN。[ 37 ]這兩者通常結合在一起,形成雙向 LSTM 架構。
2006 年左右,雙向 LSTM 開始徹底改變語音識別,在某些語音應用方面表現優于傳統模型。[ 38 ] [ 39 ]它們還改進了大詞匯量語音識別[ 3 ] [ 4 ]和文本到語音合成[ 40 ],并用于Google 語音搜索和Android 設備上的聽寫。[ 41 ]它們打破了機器翻譯[ 42 ] 、語言建模[ 43 ]和多語言處理方面的記錄。 [ 44 ]此外,LSTM 與卷積神經網絡(CNN)相結合,改進了自動圖像字幕制作。[ 45 ]
編碼器-解碼器序列傳導的概念是在 2010 年代初發展起來的。最常被引用為 seq2seq 的創始人的論文是 2014 年的兩篇論文。[ 46 ] [ 47 ] seq2seq架構采用兩個 RNN(通常是 LSTM),一個“編碼器”和一個“解碼器”,用于序列傳導,例如機器翻譯。它們成為機器翻譯領域的最先進技術,并在注意力機制和Transformers的發展中發揮了重要作用。
RNN類型**:
RNN–>LATM—>BPTT—>GUR–>RNN LM—>word2vec–>seq2seq–>BERT–>transformer–>GPT
反向傳播(BP)和基于時間的反向傳播算法BPTT
BPTT(back-propagation through time)算法是常用的訓練RNN的方法,其實本質還是BP算法,只不過RNN處理時間序列數據,所以要基于時間反向傳播,故叫隨時間反向傳播。BPTT的中心思想和BP算法相同,沿著需要優化的參數的負梯度方向不斷尋找更優的點直至收斂。綜上所述,BPTT算法本質還是BP算法,BP算法本質還是梯度下降法,那么求各個參數的梯度便成了此算法的核心。
RNN發展歷史
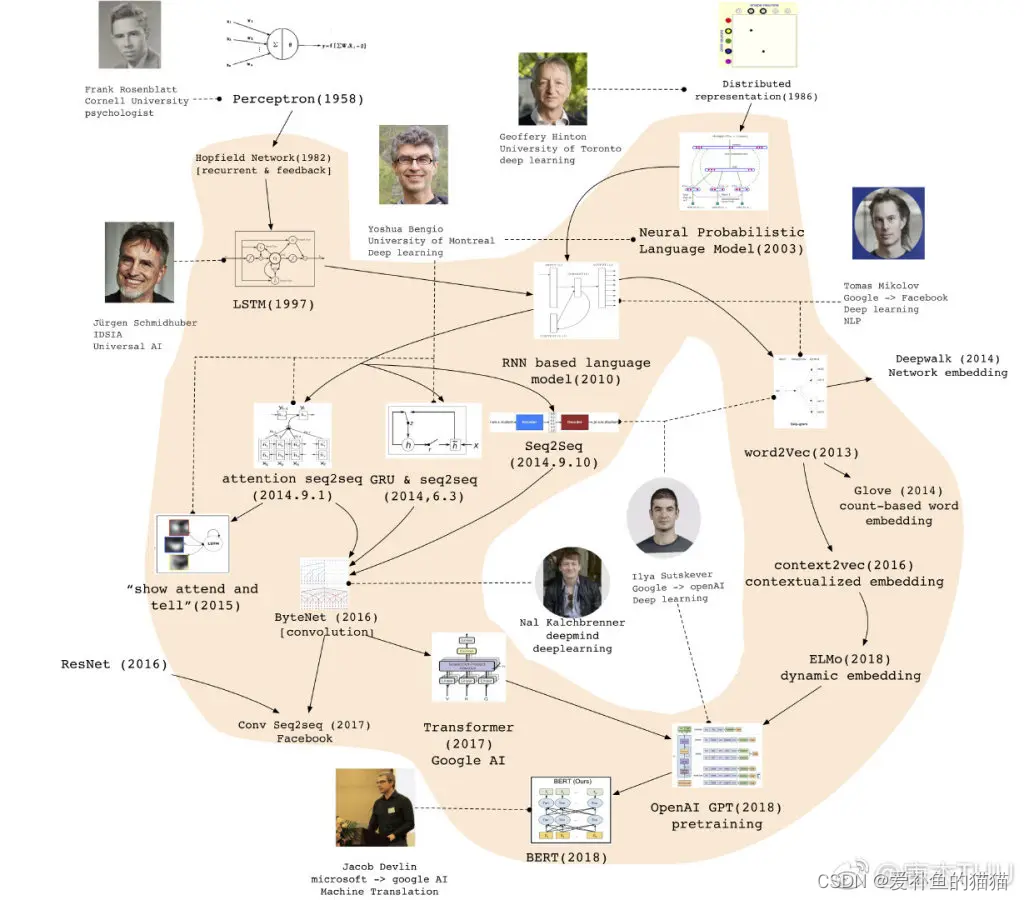
RNN的常見算法分類:
參考連接:https://zhuanlan.zhihu.com/p/148172079
1)、完全遞歸網絡(Fully recurrent network)
2)、Hopfield網絡(Hopfield network)
3)、Elman networks and Jordannetworks
4)、回聲狀態網絡(Echo state network)
5)、長短記憶網絡(Long short term memery network)
6)、雙向網絡(Bi-directional RNN)
7)、持續型網絡(Continuous-time RNN)
8)、分層RNN(Hierarchical RNN)
9)、復發性多層感知器(Recurrent multilayer perceptron)
10)、二階遞歸神經網絡(Second Order Recurrent Neural Network)
11)、波拉克的連續的級聯網絡(Pollack’s sequential cascaded networks)
2、配置和架構
https://en.wikipedia.org/wiki/Recurrent_neural_network
基于 RNN 的模型可以分為兩部分:配置和架構。多個 RNN 可以組合成一個數據流,數據流本身就是配置。每個 RNN 本身可以具有任何架構,包括 LSTM、GRU 等。
1.配置
Standard 標準、Stacked RNN 堆疊 RNN、Bidirectional 雙向、Encoder-decoder 編碼器-解碼器、PixelRNN


2.架構
-
Fully recurrent 完全循環
完全遞歸神經網絡 (FRNN) 將所有神經元的輸出連接到所有神經元的輸入。換句話說,它是一個完全連接的網絡 。這是最通用的神經網絡拓撲,因為所有其他拓撲都可以通過將某些連接權重設置為零來表示,以模擬這些神經元之間缺少連接的情況。 -
Hopfield 霍普菲爾德
Hopfield 網絡是一個 RNN,其中跨層的所有連接大小相等。它需要固定的輸入,因此不是通用的 RNN,因為它不處理 pattern 序列。但是,它保證它將收斂。如果連接是使用 Hebbian 學習進行訓練的,那么 Hopfield 網絡可以作為強大的內容可尋址內存運行,抵抗連接更改。 -
Elman 網絡和 Jordan 網絡
Elman網絡是一個三層網絡(圖中水平排列為x、 y 和 z ),并增加了一組上下文單元(圖中為u )。中間層(隱藏層)以 1 的權重固定連接到這些上下文單元。[ 51 ]在每個時間步,輸入都會前饋,并應用學習規則。固定的反向連接保存了上下文單元中隱藏單元先前值的副本(因為它們在應用學習規則之前通過連接傳播)。因此,網絡可以維持某種狀態,使其能夠執行標準多層感知器無法完成的序列預測等任務。
Jordan網絡與 Elman 網絡類似。上下文單元由輸出層而非隱藏層提供。Jordan 網絡中的上下文單元也稱為狀態層。它們與自身具有循環連接。 [ 51 ]

-
Long short-term memory 長短期記憶
長短期記憶(LSTM) 是最廣泛使用的 RNN 架構。它旨在解決消失梯度問題。LSTM 通常由稱為“遺忘門”的循環門增強。[ 54 ] LSTM 可防止反向傳播的錯誤消失或爆炸。[ 55 ]相反,錯誤可以通過空間中展開的無限數量的虛擬層向后流動。也就是說,LSTM 可以學習需要記憶數千甚至數百萬個離散時間步驟前發生的事件的任務。可以發展針對特定問題的 LSTM 類拓撲。[ 56 ]即使在重要事件之間有較長的延遲,LSTM 也能正常工作,并且可以處理混合了低頻和高頻分量的信號。
許多應用都使用 LSTM 堆棧,[ 57 ]因此被稱為“深度 LSTM”。與基于隱馬爾可夫模型(HMM) 和類似概念的先前模型不同,LSTM 可以學習識別上下文相關的語言。 [ 58 ] -
Gated recurrent unit 門控循環單元
門控循環單元(GRU) 于 2014 年推出,旨在簡化 LSTM。它們以完整形式和幾個進一步簡化的變體使用。[ 59 ] [ 60 ]由于沒有輸出門,它們的參數比 LSTM 少。[ 61 ]它們在復音音樂建模和語音信號建模方面的表現與長短期記憶相似。[ 62 ] LSTM 和 GRU 之間似乎沒有特別的性能差異。[ 62 ] [ 63 ] -
Bidirectional associative memory雙向關聯存儲器
由 Bart Kosko 提出,[64] 雙向關聯記憶 (BAM) 網絡是 Hopfield 網絡的一種變體,它將關聯數據存儲為向量。雙向性來自通過矩陣傳遞信息及其轉置 。通常,雙極編碼優于關聯對的二進制編碼。最近,使用馬爾可夫步進的隨機 BAM 模型得到了優化,以提高網絡穩定性和與實際應用的相關性。[65]BAM 網絡有兩層,其中任何一層都可以作為輸入驅動,以調用關聯并在另一層上生成輸出。[66]
常見變體與改進
-
LSTM(長短期記憶網絡):
引入輸入門、遺忘門和輸出門,通過門控機制選擇性保留或遺忘信息,有效緩解梯度消失問題12。 -
GRU(門控循環單元):
簡化 LSTM 結構,合并部分門控單元,減少參數量的同時保持性能4。 -
雙向 RNN(BiRNN):
同時考慮序列的前向和后向信息,適用于需要上下文理解的場景(如命名實體識別)
3、基本結構
1.神經元
https://mp.weixin.qq.com/s/MIL14-IKjJ_mF66S3brNrg


2.RNN
1. RNN和前饋網絡區別:
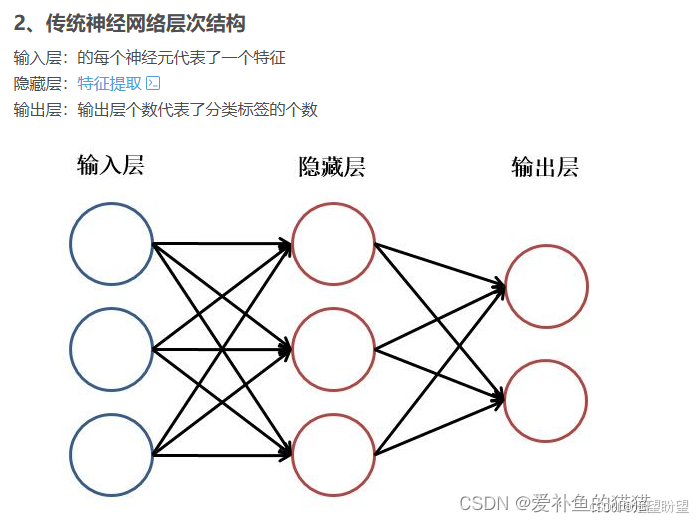
循環神經網絡是一種對序列數據有較強的處理能力的網絡, 這些序列型的數據具有時序上的關聯性的,既某一時刻網絡的輸出除了與當前時刻的輸入相關之外,還與之前某一時刻或某幾個時刻的輸出相關。傳統神經網絡(包括CNN),輸入和輸出都是互相獨立的,前饋神經網絡并不能處理好這種關聯性,因為它沒有記憶能力,所以前面時刻的輸出不能傳遞到后面的時刻。
循環神經網絡,是指在全連接神經網絡的基礎上增加了前后時序上的關系,RNN包括三個部分:輸入層、隱藏層和輸出層。相對于前饋神經網絡,RNN可以接收上一個時間點的隱藏狀態。(在傳統的神經網絡模型中,是從輸入層到隱含層再到輸出層(三個層),層與層之間是全連接的(上下層之間),每層之間的節點是無連接的(同層之間)。)
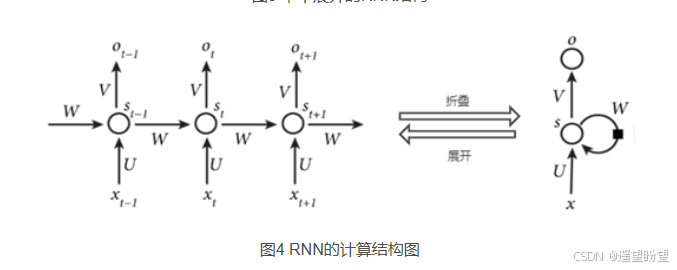
圖中 x、s、o (或x、h、y)分別代表 RNN 神經元的輸入、隱藏狀態、輸出。
U、W、V 是對向量 x、s、o(或x、h、y) 進行線性變換的矩陣。
計算 St 時激活函數通常采用 tanh,計算輸出 Ot 時激活函數通常是 softmax (分類)。

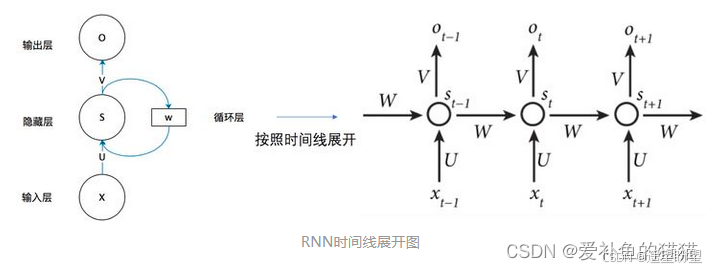
參考:
https://blog.csdn.net/kevinjin2011/article/details/125069293
https://blog.csdn.net/weixin_44986037/article/details/128923058
https://blog.csdn.net/weixin_44986037/article/details/128954608
2. 計算公式:
https://zhuanlan.zhihu.com/p/149869659
h2的計算和h1類似。要注意的是,在計算時,每一步使用的參數U、W、b都是一樣的,也就是說每個步驟的參數都是共享的,這是RNN的重要特點,一定要牢記。

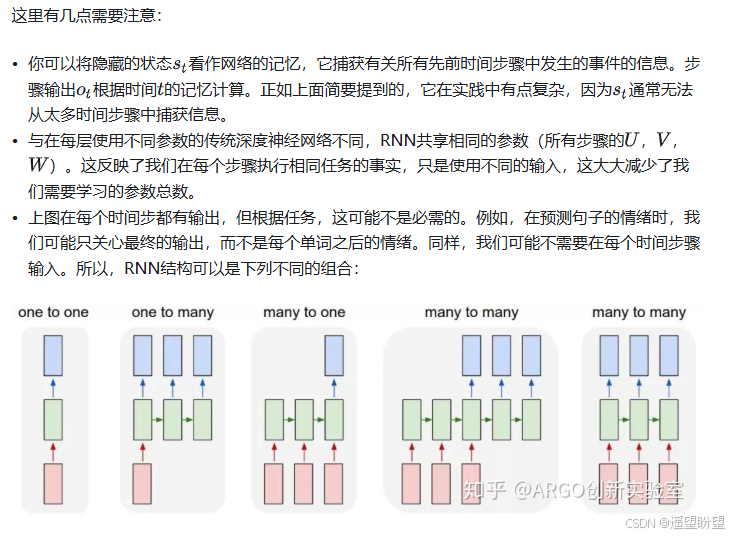 RNN分為一對一、一對多、多對一、多對多,其中多對多分為兩種。
RNN分為一對一、一對多、多對一、多對多,其中多對多分為兩種。
1.單個神經網絡,即一對一。2.單一輸入轉為序列輸出,即一對多。這類RNN可以處理圖片,然后輸出圖片的描述信息。3.序列輸入轉為單個輸出,即多對一。多用在電影評價分析。4.編碼解碼(Seq2Seq)結構。seq2seq的應用的范圍非常廣泛,語言翻譯,文本摘要,閱讀理解,對話生成等。5.輸入輸出等長序列。這類限制比較大,常見的應用有作詩機器人。
層次可分為:單層RNN、多層RNN、雙向RNN
3. 梯度消失:
循環神經網絡在進行反向傳播時也面臨梯度消失或者梯度爆炸問題,這種問題表現在時間軸上。如果輸入序列的長度很長,人們很難進行有效的參數更新。通常來說梯度爆炸更容易處理一些。梯度爆炸時我們可以設置一個梯度閾值,當梯度超過這個閾值的時候可以直接截取。
有三種方法應對梯度消失問題:
(1)合理的初始化權重值。初始化權重,使每個神經元盡可能不要取極大或極小值,以躲開梯度消失的區域。
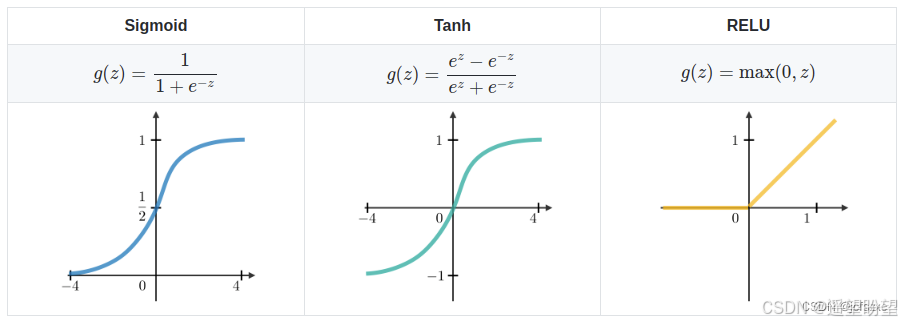
(2) 使用 ReLu 代替 sigmoid 和 tanh 作為激活函數。
(3) 使用其他結構的RNNs,比如長短時記憶網(LSTM)和 門控循環單元 (GRU),這是最流行的做法。
4. RNN類型:(查看發展史)
RNN–>LATM—>BPTT—>GUR–>RNN LM—>word2vec–>seq2seq–>BERT–>transformer–>GPT
反向傳播(BP)和基于時間的反向傳播算法BPTT
BPTT(back-propagation through time)算法是常用的訓練RNN的方法,其實本質還是BP算法,只不過RNN處理時間序列數據,所以要基于時間反向傳播,故叫隨時間反向傳播。BPTT的中心思想和BP算法相同,沿著需要優化的參數的負梯度方向不斷尋找更優的點直至收斂。綜上所述,BPTT算法本質還是BP算法,BP算法本質還是梯度下降法,那么求各個參數的梯度便成了此算法的核心。
5. 網絡區別
RNN(循環神經網絡,Recurrent Neural Network)和前饋神經網絡(Feedforward Neural Network,也稱為多層感知機,MLP)是兩種常見的神經網絡結構,它們在結構和應用場景上有顯著的區別。以下是它們的主要區別:
-
前饋網絡:
- 是一種最基礎的神經網絡結構,數據從輸入層流向隱藏層,再流向輸出層,沒有反饋或循環。
- 每個神經元只接收前一層的輸入,不與同一層或后面的層交互。
- 結構是靜態的,沒有記憶功能。
-
RNN:
- 引入了循環結構,允許信息在神經元之間循環傳遞。
- 隱藏層的狀態會傳遞到下一個時間步,因此 RNN 具有“記憶”功能,可以處理序列數據。
- 結構是動態的,適合處理時間序列或序列數據。
3.LSTM
參考:
https://zhuanlan.zhihu.com/p/149869659
https://www.jianshu.com/p/247a72812aff
https://www.jianshu.com/p/0cf7436c33ae
https://blog.csdn.net/mary19831/article/details/129570030
LSTM 緩解梯度消失、梯度爆炸,RNN 中出現梯度消失的原因主要是梯度函數中包含一個連乘項
1、RNN中梯度問題
反向傳播(求導)連乘項就是導致 RNN 出現梯度消失與梯度爆炸的罪魁禍首



對上面的部分解釋:


由于預測的誤差是沿著神經網絡的每一層反向傳播的,因此當雅克比矩陣的最大特征值大于1時,隨著離輸出越來越遠,每層的梯度大小會呈指數增長,導致梯度爆炸;反之,若雅克比矩陣的最大特征值小于1,梯度的大小會呈指數縮小,產生梯度消失。對于普通的前饋網絡來說,梯度消失意味著無法通過加深網絡層次來改善神經網絡的預測效果,因為無論如何加深網絡,只有靠近輸出的若干層才真正起到學習的作用。這使得循環神經網絡模型很難學習到輸入序列中的長距離依賴關系。
參考:
https://zhuanlan.zhihu.com/p/149869659
https://www.jianshu.com/p/247a72812aff
https://www.jianshu.com/p/0cf7436c33ae
2、LSTM結構
-
LSTM結構
LSTM 緩解梯度消失、梯度爆炸,RNN 中出現梯度消失的原因主要是梯度函數中包含一個連乘項
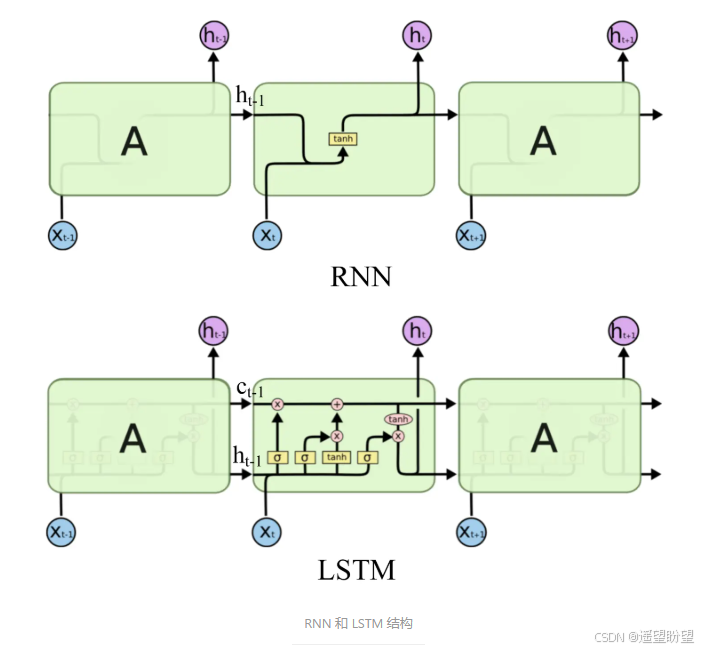
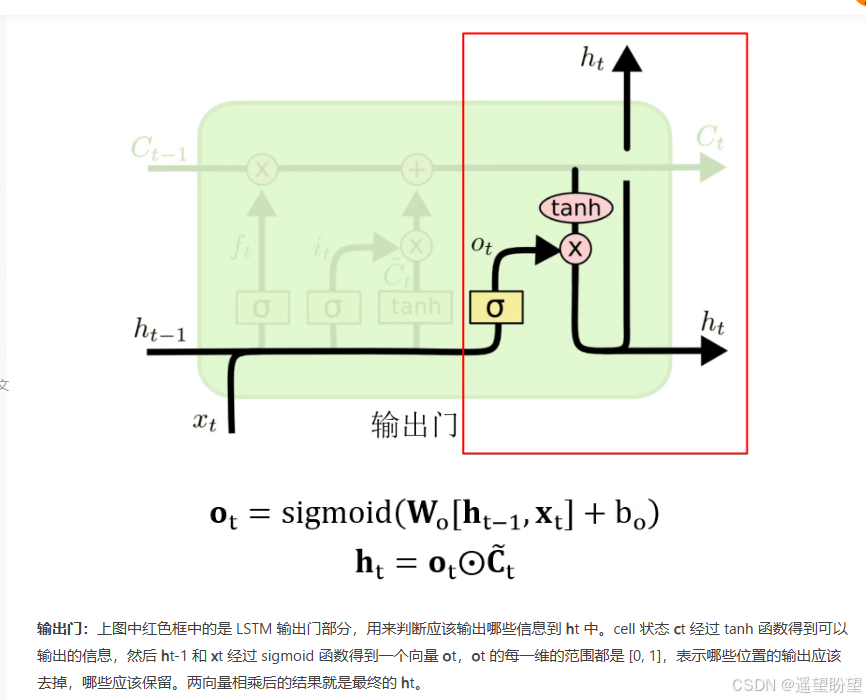
LSTM(長短時記憶網絡)是一種常用于處理序列數據的深度學習模型,與傳統的 RNN(循環神經網絡)相比,LSTM引入了三個門( 輸入門、遺忘門、輸出門,如下圖所示)和一個 細胞狀態(cell state),這些機制使得LSTM能夠更好地處理序列中的長期依賴關系。注意:小蝌蚪形狀表示的是sigmoid激活函數
而 LSTM 的神經元在此基礎上還輸入了一個 cell 狀態 ct-1, cell 狀態 c 和 RNN 中的隱藏狀態 h 相似,都保存了歷史的信息,從 ct-2 ~ ct-1 ~ ct。在 LSTM 中 c 與 RNN 中的 h 扮演的角色很像,都是保存歷史狀態信息,而在 LSTM 中的 h 更多地是保存上一時刻的輸出信息。
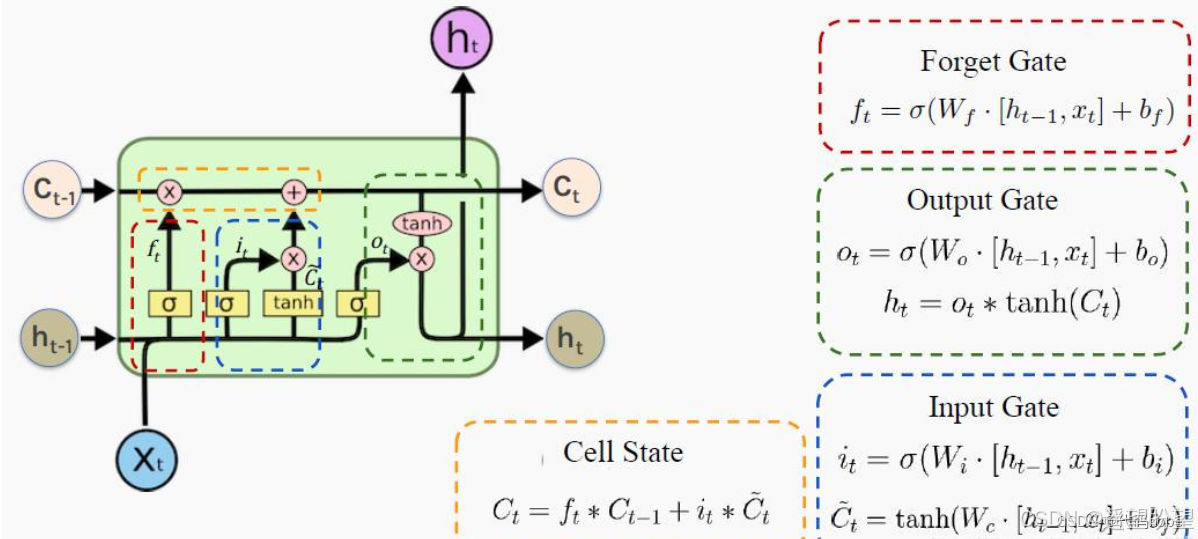
-
遺忘門:
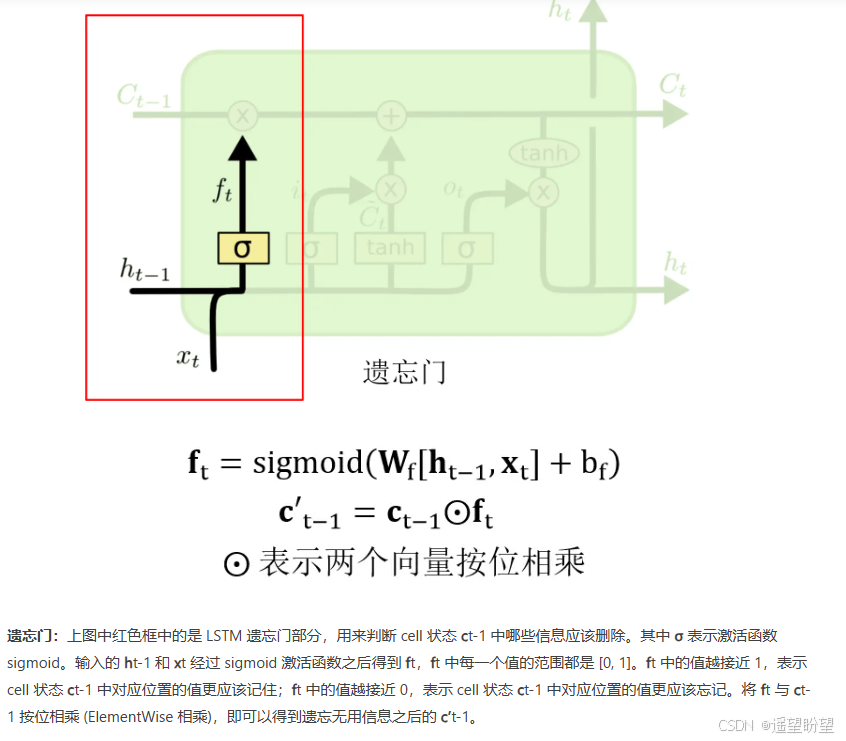
-
輸入門
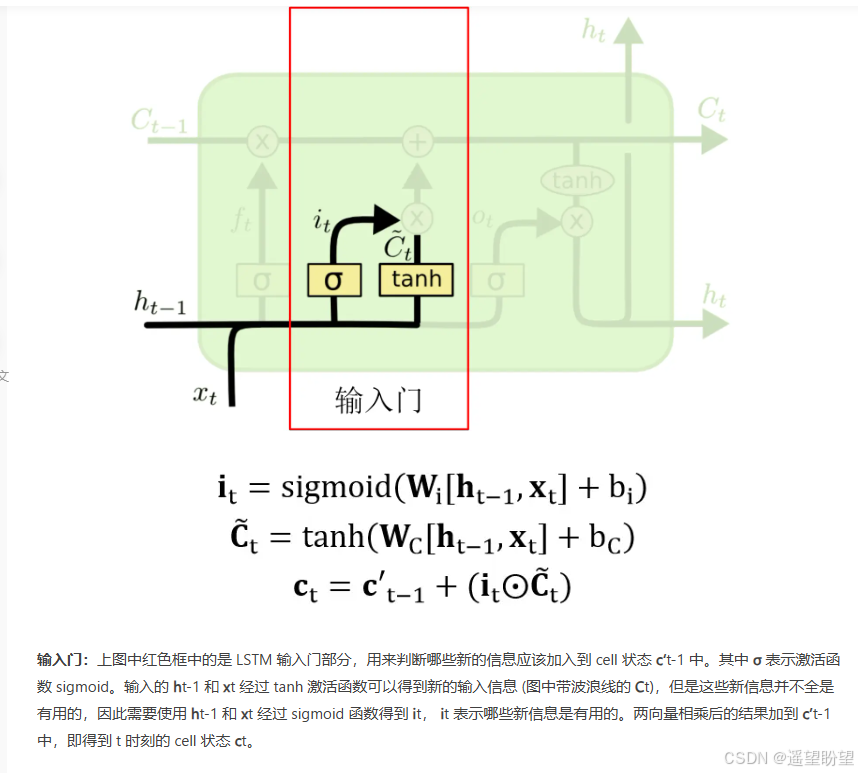
-
輸出門
3、LSTM梯度緩解
梯度爆炸和梯度消失緩解



一、LSTM 反向傳播求導核心推導
LSTM 的梯度反向傳播需計算損失函數對各參數(權重 W , U W, U W,U、偏置 b b b)和隱藏狀態的梯度,核心是細胞狀態 c t c_t ct? 和門控信號的梯度傳遞。以下為關鍵推導步驟(符號定義同正向傳播, σ \sigma σ 為 sigmoid,導數 σ ′ = σ ( 1 ? σ ) \sigma' = \sigma(1-\sigma) σ′=σ(1?σ); tanh ? ′ = 1 ? tanh ? 2 \tanh' = 1-\tanh^2 tanh′=1?tanh2):
1. 定義反向傳播變量
設 δ t = ? L ? h t \delta_t = \frac{\partial L}{\partial h_t} δt?=?ht??L?(當前時刻隱藏狀態對損失的梯度),需推導 δ t \delta_t δt? 對 h t ? 1 h_{t-1} ht?1?、 c t ? 1 c_{t-1} ct?1? 及各層參數的梯度。
2. 輸出門 o t o_t ot? 的梯度
? L ? o t = δ t ⊙ tanh ? ( c t ) (鏈式法則: h t = o t ⊙ tanh ? ( c t ) ) \frac{\partial L}{\partial o_t} = \delta_t \odot \tanh(c_t) \quad \text{(鏈式法則:$h_t = o_t \odot \tanh(c_t)$)} ?ot??L?=δt?⊙tanh(ct?)(鏈式法則:ht?=ot?⊙tanh(ct?))
對輸出門權重 W o , U o W_o, U_o Wo?,Uo? 的梯度:
? L ? W o = ? L ? o t ⊙ o t ⊙ ( 1 ? o t ) ⊙ x t T , ? L ? U o = ? L ? o t ⊙ o t ⊙ ( 1 ? o t ) ⊙ h t ? 1 T \frac{\partial L}{\partial W_o} = \frac{\partial L}{\partial o_t} \odot o_t \odot (1-o_t) \odot x_t^T, \quad \frac{\partial L}{\partial U_o} = \frac{\partial L}{\partial o_t} \odot o_t \odot (1-o_t) \odot h_{t-1}^T ?Wo??L?=?ot??L?⊙ot?⊙(1?ot?)⊙xtT?,?Uo??L?=?ot??L?⊙ot?⊙(1?ot?)⊙ht?1T?
3. 細胞狀態 c t c_t ct? 的梯度
? L ? c t = δ t ⊙ o t ⊙ ( 1 ? tanh ? 2 ( c t ) ) + ? L ? c t + 1 ⊙ f t + 1 (當前時刻隱藏狀態?+?下一時刻細胞狀態的貢獻) \frac{\partial L}{\partial c_t} = \delta_t \odot o_t \odot (1 - \tanh^2(c_t)) + \frac{\partial L}{\partial c_{t+1}} \odot f_{t+1} \quad \text{(當前時刻隱藏狀態 + 下一時刻細胞狀態的貢獻)} ?ct??L?=δt?⊙ot?⊙(1?tanh2(ct?))+?ct+1??L?⊙ft+1?(當前時刻隱藏狀態?+?下一時刻細胞狀態的貢獻)
4. 遺忘門 f t f_t ft?、輸入門 i t i_t it?、候選細胞 c ~ t \tilde{c}_t c~t? 的梯度
- 遺忘門(控制歷史信息保留):
? L ? f t = ? L ? c t ⊙ c t ? 1 ⊙ f t ⊙ ( 1 ? f t ) \frac{\partial L}{\partial f_t} = \frac{\partial L}{\partial c_t} \odot c_{t-1} \odot f_t \odot (1-f_t) ?ft??L?=?ct??L?⊙ct?1?⊙ft?⊙(1?ft?) - 輸入門(控制新信息注入):
? L ? i t = ? L ? c t ⊙ c ~ t ⊙ i t ⊙ ( 1 ? i t ) \frac{\partial L}{\partial i_t} = \frac{\partial L}{\partial c_t} \odot \tilde{c}_t \odot i_t \odot (1-i_t) ?it??L?=?ct??L?⊙c~t?⊙it?⊙(1?it?) - 候選細胞狀態(非線性變換):
? L ? c ~ t = ? L ? c t ⊙ i t ⊙ ( 1 ? c ~ t 2 ) \frac{\partial L}{\partial \tilde{c}_t} = \frac{\partial L}{\partial c_t} \odot i_t \odot (1 - \tilde{c}_t^2) ?c~t??L?=?ct??L?⊙it?⊙(1?c~t2?)
5. 向過去時刻傳遞梯度
- 隱藏狀態梯度:
δ t ? 1 = ( W i T ? L ? i t + W f T ? L ? f t + W o T ? L ? o t + W c T ? L ? c ~ t ) ⊙ σ ′ ( h t ? 1 ) \delta_{t-1} = \left( W_i^T \frac{\partial L}{\partial i_t} + W_f^T \frac{\partial L}{\partial f_t} + W_o^T \frac{\partial L}{\partial o_t} + W_c^T \frac{\partial L}{\partial \tilde{c}_t} \right) \odot \sigma'(h_{t-1}) δt?1?=(WiT??it??L?+WfT??ft??L?+WoT??ot??L?+WcT??c~t??L?)⊙σ′(ht?1?)
(各門將梯度傳遞回前一時刻隱藏狀態, σ ′ \sigma' σ′ 為 sigmoid 導數,控制衰減) - 細胞狀態梯度:
? L ? c t ? 1 = ? L ? c t ⊙ f t \frac{\partial L}{\partial c_{t-1}} = \frac{\partial L}{\partial c_t} \odot f_t ?ct?1??L?=?ct??L?⊙ft?
(核心路徑:若 f t ≈ 1 f_t \approx 1 ft?≈1,梯度近乎無損傳遞,緩解消失)
二、梯度消失的緩解:LSTM 結構設計核心
傳統 RNN 梯度消失的本質是:反向傳播時,梯度需經過多層激活函數(sigmoid/tanh 導數 < 1),導致 ∏ 導數 ≈ 0 \prod \text{導數} \approx 0 ∏導數≈0(指數衰減)。
LSTM 通過門控機制重構梯度傳遞路徑,核心策略:
-
遺忘門主導的恒等映射
- 若 f t = 1 f_t = 1 ft?=1(完全保留歷史細胞狀態),則 c t = c t ? 1 + i t ⊙ c ~ t c_t = c_{t-1} + i_t \odot \tilde{c}_t ct?=ct?1?+it?⊙c~t?,此時 ? c t ? c t ? 1 = f t = 1 \frac{\partial c_t}{\partial c_{t-1}} = f_t = 1 ?ct?1??ct??=ft?=1,梯度傳遞為 恒等映射(無衰減)。
- 實際中,遺忘門通過學習動態調整 f t f_t ft?(接近 1 時保留歷史信息,接近 0 時遺忘),避免梯度因激活函數導數衰減而消失。
-
分離非線性變換與梯度路徑
- 輸入門 i t i_t it? 和候選細胞 c ~ t \tilde{c}_t c~t? 的非線性操作(sigmoid/tanh)僅影響新信息注入,而歷史信息傳遞( c t ? 1 → c t c_{t-1} \to c_t ct?1?→ct?)由線性操作(乘以 f t f_t ft?)主導,繞過了激活函數導數的衰減問題。
-
梯度的多路徑傳播
- 梯度可通過 c t → c t ? 1 c_t \to c_{t-1} ct?→ct?1?(主要路徑,線性)和 h t → h t ? 1 h_t \to h_{t-1} ht?→ht?1?(次要路徑,非線性)傳遞,前者的穩定性確保長距離依賴的梯度有效保留。
三、梯度爆炸的緩解:訓練階段的外部策略
LSTM 未從結構上解決梯度爆炸(權重矩陣乘積的行列式可能過大),需依賴以下訓練技巧:
- 梯度裁剪(Gradient Clipping)
- 原理:直接限制梯度范數,避免數值溢出。
- 操作:設定閾值 C C C,若梯度范數 ∥ ? ∥ > C \|\nabla\| > C ∥?∥>C,則將其縮放為:
? = C ? ? ∥ ? ∥ \nabla = \frac{C \cdot \nabla}{\|\nabla\|} ?=∥?∥C??? - 優勢:簡單有效,不依賴模型結構,廣泛應用于 RNN/LSTM 訓練。
- 合理的權重初始化
- 正交初始化:確保權重矩陣正交(特征值為 1),避免奇異值過大導致的梯度放大。
- Xavier/Glorot 初始化:根據輸入輸出維度動態調整初始范圍,使激活值和梯度的方差在層間保持穩定。
- 優勢:從初始條件抑制權重矩陣的極端值,降低爆炸風險。
- 正則化與 Dropout
- L2 正則化:在損失函數中添加 λ ∥ W ∥ 2 \lambda\|W\|^2 λ∥W∥2,懲罰權重過大,迫使參數保持較小值。
- 門控層 Dropout:對輸入門、遺忘門、輸出門的輸入施加 Dropout(而非細胞狀態),避免破壞梯度主路徑,同時增加模型魯棒性。
- 自適應優化器
- 使用 RMSprop、Adam 等優化器,通過動態調整學習率(如 Adam 的二階矩估計),緩解梯度爆炸的影響。需注意超參數(如 β 2 \beta_2 β2?)的設置,避免過度衰減梯度。
四、總結
- LSTM 緩解梯度消失的本質:通過遺忘門控制的細胞狀態線性傳遞(恒等映射),將傳統 RNN 的“指數衰減路徑”轉化為“穩定路徑”,確保長距離梯度有效傳播。
- 梯度爆炸的解決:依賴訓練技巧(梯度裁剪、權重初始化等),而非結構本身,因 LSTM 無法阻止權重矩陣因參數更新導致的行列式爆炸。
- 核心價值:LSTM 的門控機制(尤其是細胞狀態的線性路徑)是解決梯度消失的關鍵,而梯度爆炸需結合外部策略共同優化,二者結合使 LSTM 在長序列任務中表現優異。
參考:https://www.jianshu.com/p/247a72812aff
4.GRU
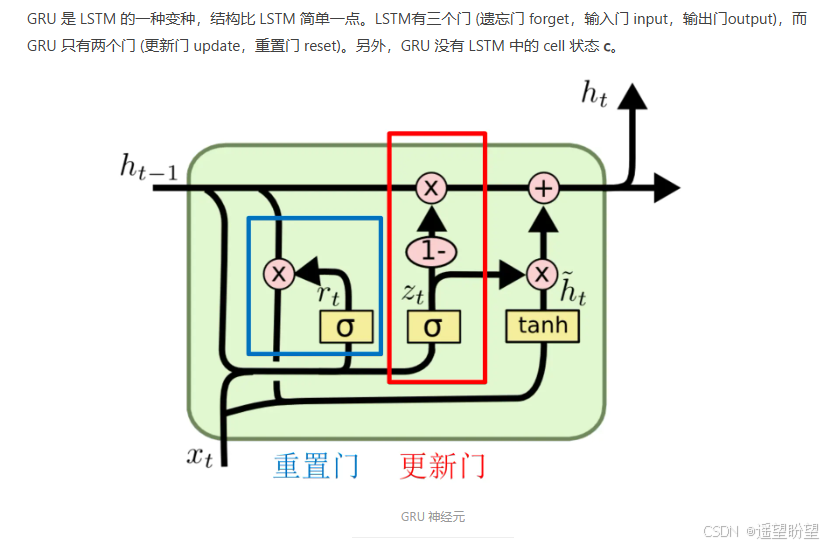

參考:
https://www.jianshu.com/p/0cf7436c33ae

——ListBox控件詳解)


)


 codepipeline-build-deploy-github-manual)











