
- 論文:Yiran Qin 1 , 2 ^{1,2} 1,2, Ao Sun 2 ^{2} 2, Yuze Hong 2 ^{2} 2, Benyou Wang 2 ^{2} 2, Ruimao Zhang 1 ^{1} 1
- 單位: 1 ^{1} 1中山大學, 2 ^{2} 2香港中文大學深圳校區
- 論文標題:NavigateDiff: Visual Predictors are Zero-Shot Navigation Assistants
- 論文鏈接:https://arxiv.org/pdf/2502.13894
- 項目主頁:https://21styouth.github.io/NavigateDiff/
主要貢獻
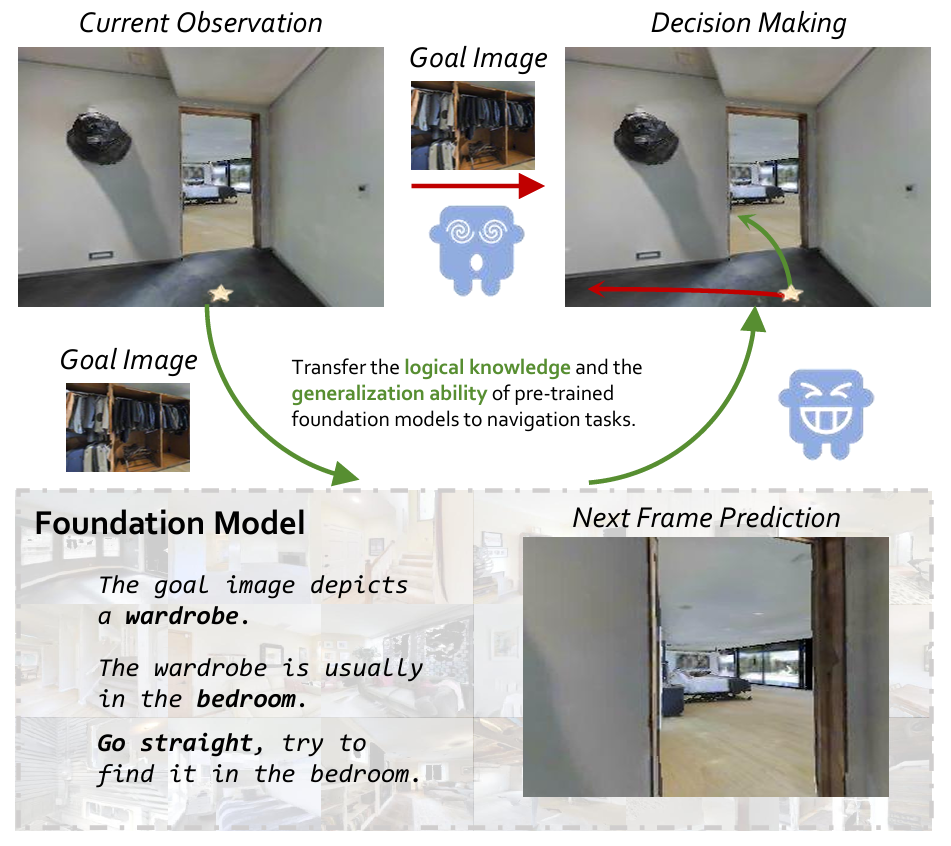
- 提出了新的導航框架NavigateDiff,通過將高層次任務推理與低層次機器人控制分離,增強了導航的泛化能力。
- 引入了視覺預測器,結合多模態語言模型和擴散模型,用于生成未來的場景圖像,以輔助機器人決策。
- 設計了混合融合策略網絡,通過整合當前觀察、未來預測和目標圖像,優化機器人的導航動作。
- 通過模擬和現實環境的廣泛實驗,驗證了該方法在零樣本導航中的有效性和魯棒性,展示了其在不同環境中的適應性。
研究背景
研究問題
論文主要解決的問題是家庭機器人在導航不熟悉環境時面臨的挑戰,特別是如何在不進行大量地圖繪制和探索的情況下,實現零樣本導航。
研究難點
該問題的研究難點包括:
- 現有強化學習方法依賴于大量的地圖繪制和探索,導致時間消耗大且效率低下;
- 現有數據集無法覆蓋機器人可能遇到的所有環境和場景,缺乏廣泛的邏輯知識。
相關工作
- 基于視覺的導航:
- 討論了經典的SLAM方法和基于學習的方法在機器人視覺導航中的應用。
- 這些方法包括端到端學習技術、記憶增強的強化學習、單目相機設置下的導航改進,以及模塊化的導航和語義映射任務。
- 擴散模型用于圖像生成:
- 介紹了文本到圖像的擴散模型如何改進指令驅動的圖像生成方法。
- 這些模型在圖像編輯和動態導航任務中的應用被討論,強調了在導航任務中生成符合物理規則的未來圖像的挑戰。
- 預訓練基礎模型用于具身任務:
- 探討了大模型(LLMs)和擴散模型在導航等具身任務中的應用。
- 這些模型通過其信息處理和生成能力,用于導航任務中的先驗知識推理、路徑規劃和目標識別等。
研究方法
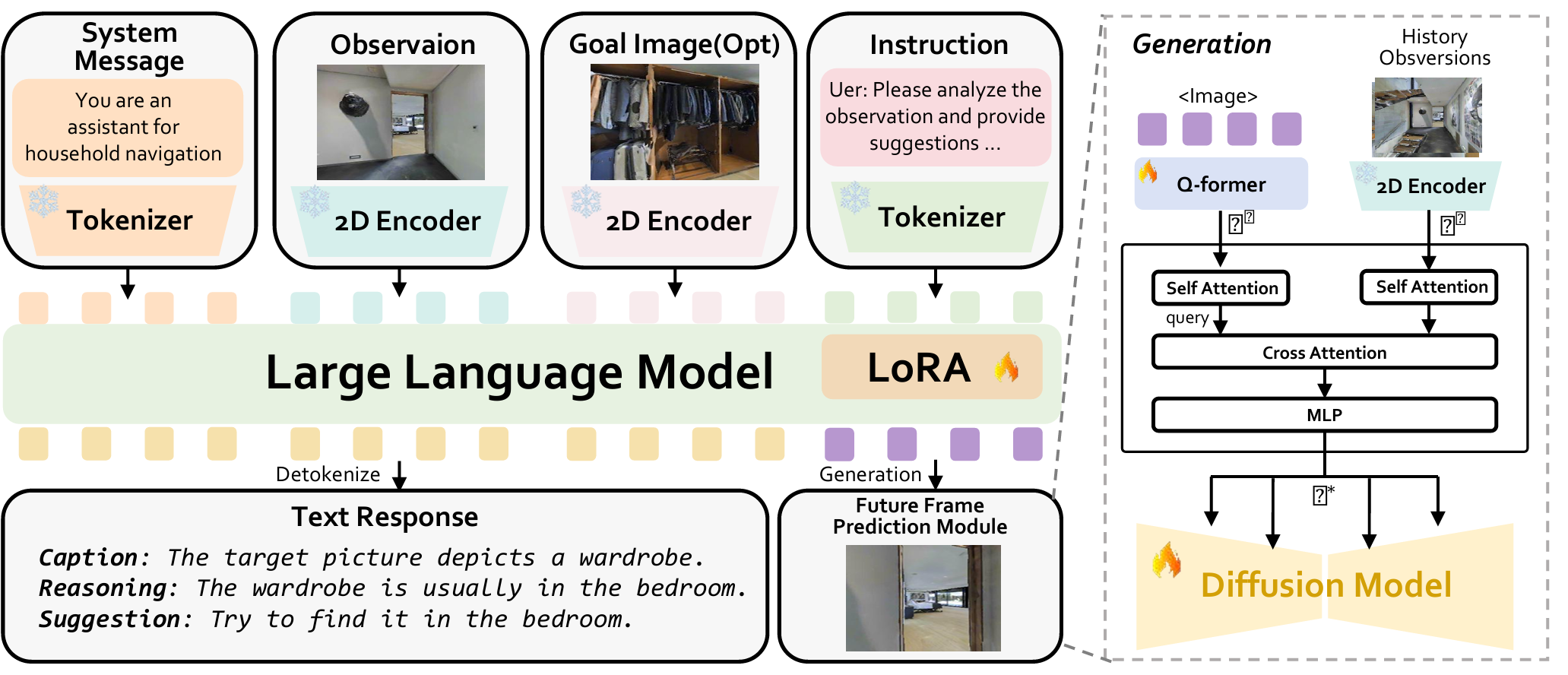
論文提出了NavigateDiff導航框架,旨在通過視覺預測器將高層次的任務推理與低層次的機器人控制分離,從而實現可泛化的導航。
形式化描述
- 為了生成未來幀的訓練數據,論文使用模擬器內置的“最短路徑跟隨”算法來獲取每個任務的標準化路線,并生成相應的視頻。
- 在現實世界中,論文記錄了人類遠程控制導航機器人完成圖像導航任務的視角視頻。
- 從收集的視頻中,隨機選擇起始幀,并根據預定義的預測間隔生成對應的未來幀。同時記錄相關的導航任務信息,形成訓練元組 ( x t , x t + k , x h , y , x g ) (x_{t}, x_{t+k}, x_{h}, y, x_{g}) (xt?,xt+k?,xh?,y,xg?),其中:
- x t x_{t} xt? 是當前觀察圖像,
- x t + k x_{t+k} xt+k? 是需要預測的未來幀圖像,
- x h x_{h} xh? 是歷史幀,
- y y y 是任務的文本指令,
- x g x_{g} xg? 是導航任務的最終目標圖像。
預測器
- 預測器結合了多模態大模型(MLLM)和未來幀預測模型,能夠處理當前觀察、目標圖像和指令,并生成預測的未來圖像。
- 多模態大模型:輸入當前觀察 x t x_{t} xt?、目標圖像 x g x_{g} xg? 和文本指令 y y y,生成特殊圖像標記 ,然后傳遞給未來幀預測模型。
- 未來幀預測模型:將特殊圖像標記轉換為語義相關的表示 f N f^{N} fN,并將其與從2D編碼器提取的特征 f H f^{H} fH 融合。融合特征 f ? f^{*} f? 用于條件化編輯型擴散模型生成未來圖像:
f ? = H ( Q ( h < image > ) , E v ( x h ) ) f^{*} = H(Q(h_{<\text{image}>}), E_{v}(x_{h})) f?=H(Q(h<image>?),Ev?(xh?))
其中, Q Q Q 表示Q-Former, E v E_{v} Ev? 是二維編碼器, H H H 是融合塊,包含兩個自注意力塊、一個交叉注意力塊和一個MLP層。 - 訓練目標是通過最小化噪聲與去噪結果之間的差異來優化預測器:
L predictor = E E ( x t + k ) , E ( x t ) , ? ~ N ( 0 , 1 ) , s [ ∥ ? ? ? δ ( s , [ z s , E ( x t ) ] + f ? ) ∥ 2 2 ] \mathcal{L}_{\text{predictor}} = E_{\mathcal{E}(x_{t+k}), \mathcal{E}(x_{t}), \epsilon \sim \mathcal{N}(0,1), s} [\|\epsilon - \epsilon_{\delta}(s, [z_{s}, \mathcal{E}(x_{t})] + f^{*})\|_{2}^{2}] Lpredictor?=EE(xt+k?),E(xt?),?~N(0,1),s?[∥???δ?(s,[zs?,E(xt?)]+f?)∥22?]
其中, ? \epsilon ? 表示未縮放的噪聲, s s s 表示采樣步長, z s z_{s} zs? 是步驟 s s s 的潛在噪聲, E ( x t ) \mathcal{E}(x_{t}) E(xt?) 對應于當前觀察的條件。
融合導航策略

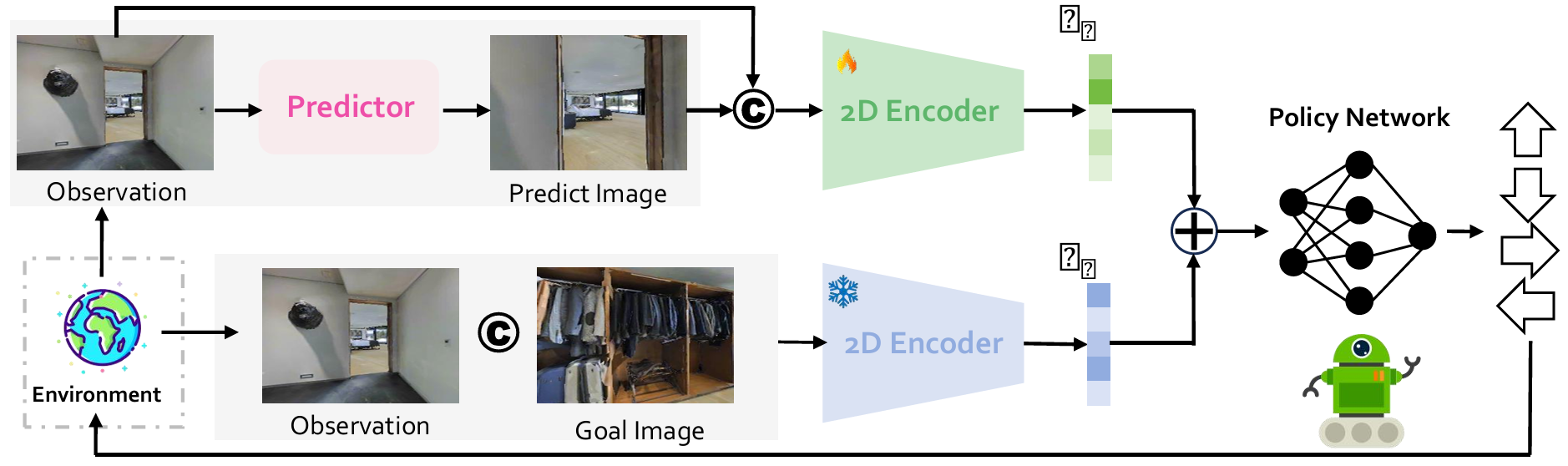
- 盡管預測器提供了視覺模態內的未來狀態規劃,但仍需要訓練一個低層次控制器來選擇適當的導航動作。
- 圖像融合策略:在訓練階段,將當前觀察 x t x_{t} xt? 與未來幀 x t + k x_{t+k} xt+k? 和目標圖像 x g x_{g} xg? 拼接并通過可訓練的二維編碼器進行處理,以獲得融合表示。使用強化學習(如PPO)訓練導航策略:
s t = π ( [ f p , f o , a t ? 1 ] ∣ h t ? 1 ) s_{t} = \pi([\,f_{p}, f_{o}, a_{t-1}\,] | h_{t-1}) st?=π([fp?,fo?,at?1?]∣ht?1?)
其中, s t s_{t} st? 表示智能體當前狀態的嵌入, h t ? 1 h_{t-1} ht?1? 表示策略 π \pi π 中來自前一步的循環層的隱藏狀態。 - 測試階段:使用訓練好的預測器和融合導航策略在新環境中進行導航。生成未來幀后,執行融合導航策略以生成具體的動作序列。
- 融合策略設計: 提出了混合融合方法,比較了其與早期融合和晚期融合的性能。混合融合方法在像素級建立語義關聯,并在時間維度上分離局部和全局信息,從而實現更好的性能。
實驗
預測器
- 數據集:使用GIBSON數據集中的視頻序列進行訓練,設置預測間隔 k = 5 k=5 k=5。
- 訓練過程:首先使用InstructPix2Pix預訓練擴散模型的權重,然后在導航環境中進行端到端的優化。
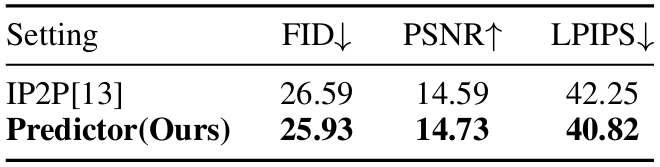
- 評估:使用三種圖像級指標(Frechet Inception Distance, Peak Signal-to-Noise Ratio, Learned Perceptual Image Patch Similarity)評估預測器的生成能力。結果顯示,預測器在所有指標上均優于基線模型。

模擬實驗
- 數據集:在Habitat模擬器中使用GIBSON數據集進行訓練,采用72個訓練場景和14個測試場景。
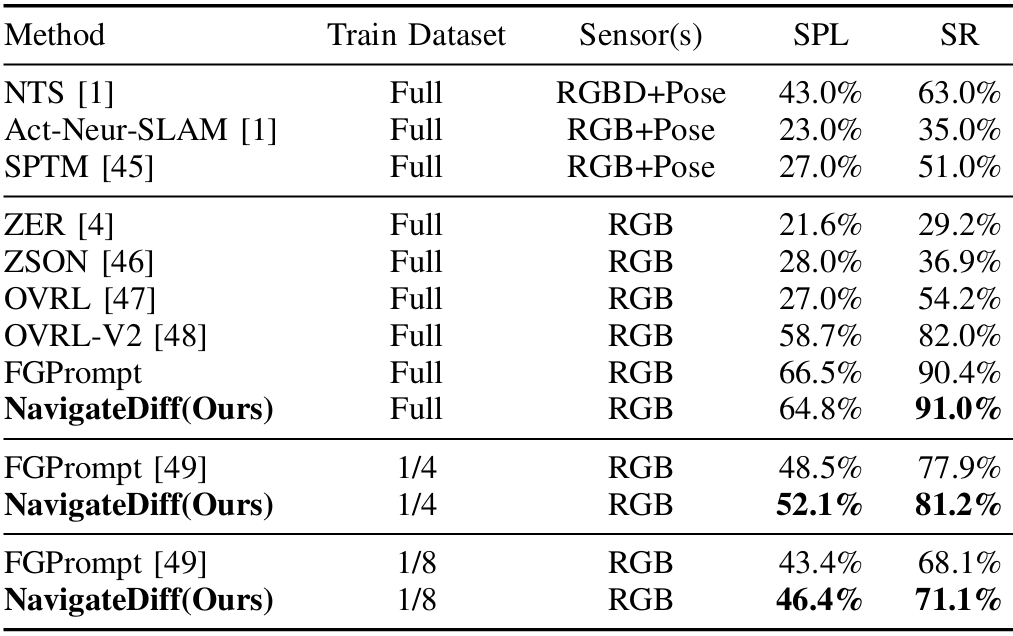
- 設置:訓練500M步,遵循FGPrompt的規則。報告了多個數據集上的結果,以便與現有工作直接比較。
-
結果:
- 在GIBSON數據集上,NavigateDiff在Success Rate (SR) 和 Success weighted by Path Length (SPL) 上表現優異。
- 在MP3D數據集上進行跨域評估,NavigateDiff在較小的訓練數據集上表現出色,超越了全數據集上的現有方法。
-
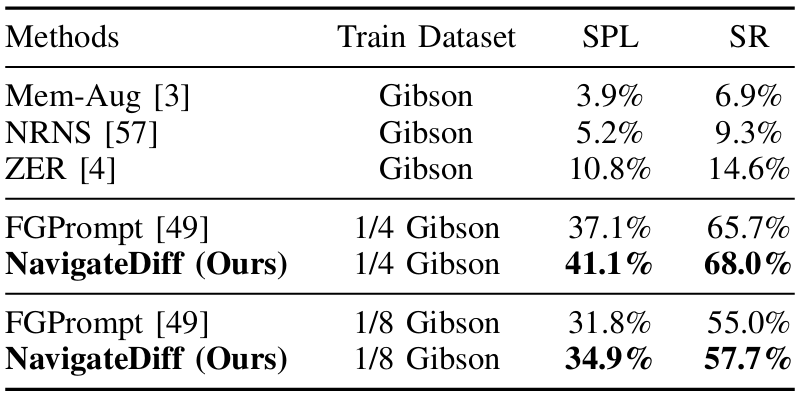
跨任務評估:
- 數據集:在GIBSON環境中訓練的模型直接轉移到MP3D環境中進行評估。
- 結果:NavigateDiff在MP3D數據集上實現了68.0%的SR和41.1%的SPL,優于其他方法。
真實世界實驗
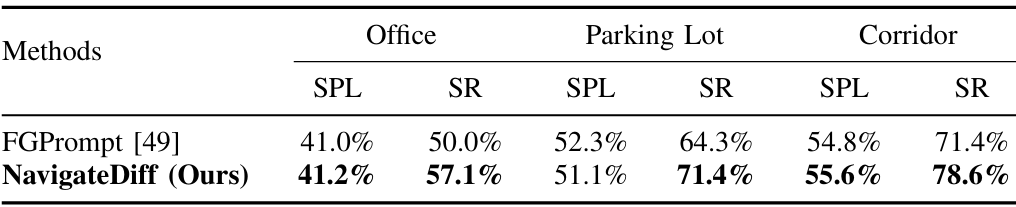
- 設置:在辦公室、停車場和走廊三種室內環境中進行測試,每種環境代表不同的布局、照明和障礙物挑戰。
- 結果:在所有三種真實世界場景中,NavigateDiff在成功率和SPL上均超過基線模型,展示了其在不同環境中的魯棒性。
融合策略設計
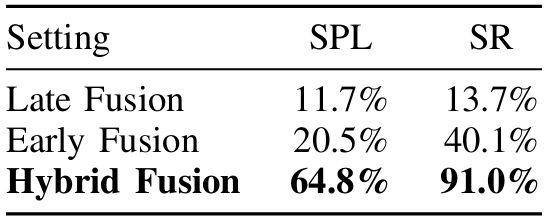
- 評估:在不同的融合策略(早期融合、晚期融合和混合融合)上進行評估。
- 結果:混合融合策略在GIBSON ImageNav任務中實現了91.0%的SR和64.8%的SPL,顯著優于其他融合策略。
總結
- 論文提出了NavigateDiff,一種新的導航框架,通過視覺預測器和混合融合策略,實現了在新環境中的零樣本導航。
- NavigateDiff方法在模擬和真實世界環境中均表現出強大的魯棒性和適應性,顯著提高了導航性能和效率。






)





)






)
