中國科學院自動化研究所智能感知與計算研究中心攜手華為等領軍企業,共同推出面向產業應用的視覺目標檢測全流程解決方案——GAIA智能檢測平臺。該研究成果已獲CVPR 2021會議收錄(論文鏈接:
論文地址:https://arxiv.org/pdf/2106.11346.pdf
開源框架:https://github.com/GAIA-vision
GAIA誕生的時代背景
在深度學習技術與海量數據雙重驅動的浪潮下,雖然目標檢測算法在COCO、OpenImages等基準測試集上屢創佳績,但產業落地卻面臨"模型適配難"的顯著痛點。現有的學術模型往往針對標準數據集優化,面對工業場景復雜多變的需求時顯得水土不服。企業開發者常需投入大量資源進行數據清洗、模型調優和部署適配,這種重復造輪子的模式嚴重阻礙了AI技術的產業化進程。
針對產業應用中的四大核心挑戰:
- 數據治理困境:從原始數據采集到可用數據集構建,需經歷清洗、標注、對齊等多環節,流程冗長且成本高昂
- 模型優化壁壘:超參數調優依賴專家經驗,算力資源不足導致訓練周期漫長
- 資源復用難題:相似需求場景下,不同團隊重復開發造成資源浪費
- 定制部署鴻溝:跨硬件平臺的模型適配需人工干預,難以保證性能與效率的平衡
GAIA平臺創新性地構建了"一站式"解決方案,用戶只需在配置文件中定義檢測類別,通過簡單命令行交互,系統即可自動完成數據篩選、模型訓練、參數優化到部署適配的全流程(如圖1所示)。該平臺支持從移動端到服務器端的無縫部署,真正實現了"開箱即用"的產業級檢測能力。
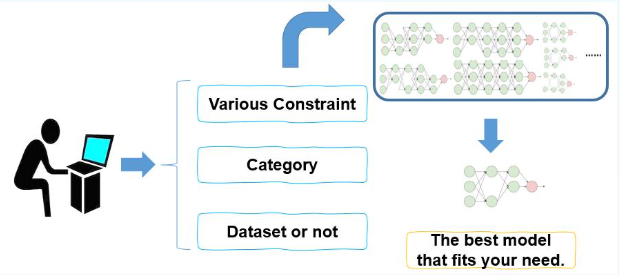
GAIA技術架構深度解析
作為新一代智能檢測平臺,GAIA由四大核心模塊構成(如圖2技術框架所示):
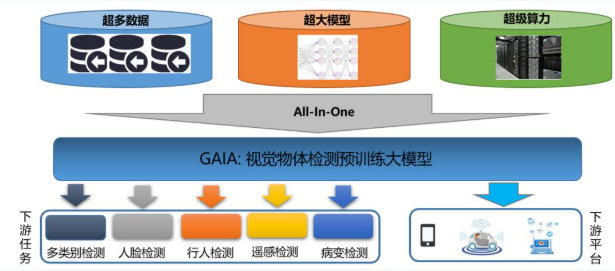
1. 多源數據集融合引擎
突破傳統單數據集訓練的局限,GAIA整合COCO、Object365、OpenImages等15+主流數據集,構建超大規模訓練池。針對視覺數據中普遍存在的標簽歧義問題(如"earth"與"ground"的語義重疊),創新性地引入語義相似度建模技術,通過閾值過濾實現跨數據集標簽體系的統一,為模型泛化能力奠定堅實基礎。
2. 神經架構搜索驅動的全模型訓練
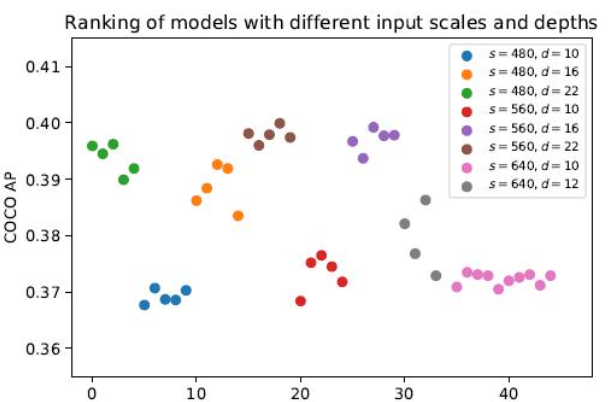
區別于BERT等通用預訓練模型,GAIA將神經架構搜索(NAS)與大規模預訓練有機結合。在采樣空間設計上,系統分析了網絡深度、輸入分辨率、通道寬度三大維度對性能的影響(如圖3性能分析所示),基于經典網絡結構設置錨點,采用三維子網采樣策略,在保持性能的前提下顯著提升訓練效率。生成的預訓練模型庫覆蓋從16ms到53ms的多梯度時延需求,滿足不同硬件平臺的部署要求。
3. 小樣本數據增強模塊
針對產業數據中常見的少樣本問題,GAIA開發了智能數據選擇策略。當本地標注數據不足時,系統自動在上游數據池中檢索語義最近鄰類別,通過特征向量相似度排序,篩選出與目標域差異最小的樣本子集(如圖5數據選擇示意圖)。實驗表明,即使在僅提供10張標注樣本的極端情況下,該策略仍能保證模型性能的顯著提升。

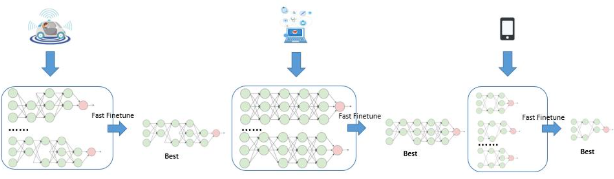
4. 硬件感知模型適配層
平臺預置了覆蓋主流硬件的算力-精度對照表(如圖6模型結構選擇),用戶只需輸入目標設備的計算資源約束,系統即可從預訓練模型庫中匹配最優子網。對于高級用戶,還支持自定義約束條件接口,實現更精細化的模型定制。在COCO數據集測試中,GAIA-det可輸出時延16-53ms、AP指標38.2-46.2的系列模型,充分滿足產業應用的多樣化需求。
性能驗證與產業價值
在VOC、Object365等15個公開數據集的對比實驗中(如圖7性能對比),GAIA模型展現出顯著優勢:
- 在保持學術基線性能的基礎上,通過TSAS架構選擇策略可獲得額外2.5%的精度提升
- 在OpenImages等長尾數據集上,憑借多源數據融合技術實現8.8%的顯著增益
- 在小樣本場景下,智能數據選擇策略帶來0.8-2.3%的性能增益
未來發展方向
作為持續進化的智能檢測生態,GAIA將不斷拓展技術邊界:
- 數據維度:定期吸收最新開源數據集,通過持續預訓練保持模型先進性
- 模型庫擴展:即將推出GAIA-seg(語義分割)和GAIA-ssl(自監督學習)模塊
- 硬件適配:深化與芯片廠商合作,建立更細粒度的硬件特性畫像
- 社區共建:誠邀學術界與產業界伙伴加入,共同構建檢測模型預訓練-微調的協作生態
GAIA的愿景是打造計算機視覺領域的"預訓練模型集市",讓開發者像選購商品一樣便捷地獲取定制檢測方案。
以上如有理解錯誤,請指正。











)
)






)