隨著大語言模型(LLM)在自然語言處理各領域取得突破性進展,越來越多開發者和企業開始關注模型的微調方式。然而,全參數微調不僅成本高昂、資源要求極高,還容易引發過擬合與知識遺忘等問題。為此,LoRA、QLoRA、PEFT 等輕量級微調技術迅速崛起,成為大模型落地實踐的熱門選擇。
本文將全面梳理這些技術,從原理剖析到工程實戰,逐步構建一套適用于大模型適配的完整知識體系,幫助讀者以更低的資源代價、更快的速度掌握大模型微調的核心能力。
目錄
第一部分:大模型微調背景與挑戰
🧠 為什么需要微調?
📉 全參數微調的困境
🔍 微調的典型應用場景
🧭 微調的新思路:輕量化微調登場
第二部分:LoRA原理與實現全剖析
1. LoRA 背后的核心思想:低秩矩陣近似
?編輯2. 數學原理簡單解釋(易懂版)
3. LoRA 訓練的具體實現機制
插入位置:哪些層插 LoRA?
參數配置含義
4. 使用 HuggingFace + PEFT 實現 LoRA 微調
5. LoRA 的實際效果如何?
第三部分:QLoRA:輕量內存占用的黑科技
1. QLoRA 的核心創新點
2. 量化技術詳解:什么是 NF4?
3. HuggingFace 生態下的 QLoRA 實現
? 安裝環境
? 載入4bit模型 + 配置QLoRA參數
? 啟動訓練(可配合 Trainer 或 SFTTrainer)
4. 性能與顯存對比實測
第四部分:PEFT 框架全家桶解析
1. PEFT 支持的微調方法一覽
2. PEFT 架構與核心概念
3. 使用 PEFT 快速實現多種微調
4. PEFT 與 Checkpoint 存儲機制
第五部分:實戰案例:微調大模型對話助手
1. 項目目標與模型選擇
2. 數據集準備
3. 配置訓練流程(以 QLoRA + PEFT 為例)
4. 微調效果驗證與評估
第一部分:大模型微調背景與挑戰
在大語言模型(LLM, Large Language Models)迅速發展的浪潮下,越來越多的企業和開發者希望將預訓練模型應用到特定領域,如法律、醫療、金融、客服等垂直場景。然而,盡管開源大模型如 LLaMA、Baichuan、ChatGLM 已經具備強大的通用語言能力,但“原地使用”往往無法滿足實際業務中的專業需求和語境差異,這就引出了微調(Fine-tuning)的重要性。
🧠 為什么需要微調?
預訓練語言模型是基于海量通用語料構建的,雖然具備強大的上下文理解能力,但在面對特定任務時,它往往表現得“知其然不知其所以然”:
-
例如,金融領域的問題“什么是量化寬松政策?”如果用未微調的LLM回答,可能泛泛而談,而缺乏專業術語和精準表達。
-
醫療問答中,常見的模型輸出有誤診、回答模糊等風險,顯然不能直接投入使用。
-
電商客服中,常規大模型容易出現語氣不一致、品牌信息錯誤等現象。
因此,通過微調使模型對特定數據、任務、語氣風格進行定向強化,是大模型落地的重要一環。
📉 全參數微調的困境
最直觀的微調方式就是“全參數微調(Full Fine-tuning)”,即對整個模型的所有權重進行再訓練。但這也帶來了以下致命問題:
| 問題 | 描述 |
|---|---|
| 顯存消耗極大 | 微調一個 65B 參數模型,顯存需求往往高達數百GB,普通A100也吃不消 |
| 成本高昂 | 全參數更新意味著參數量 × 訓練步數 × 精度,云資源開銷極高 |
| 更新慢 | 大模型訓練速度慢,Checkpoint 體積龐大,調參周期長 |
| 參數冗余 | 實際上許多下游任務只需要調整小部分權重,更新全部參數效率極低 |
| 不易遷移 | 多任務微調時容易“遺忘”原有能力(catastrophic forgetting) |
尤其對于個人開發者或中小企業而言,全參數微調幾乎是不可承受之重。
🔍 微調的典型應用場景
以下是一些典型的大模型微調應用案例,幫助讀者理解這項技術的實際價值:
-
行業定制:基于財報數據微調模型,讓它回答財務分析類問題
-
風格遷移:將原模型訓練為具有特定語氣風格的客服機器人(如京東、小米語氣)
-
指令強化:通過指令微調(Instruction tuning)讓模型學會“聽話”:按照固定格式答復、按步驟思考
-
多輪對話:加入對話歷史上下文信息,提升多輪問答的連貫性與上下文理解
這些場景有一個共同點:**只需“稍加調整”,就能大幅提升模型在特定任務下的表現。**這也促使我們思考——有沒有可能做到“只調一小部分參數,就能獲得很好的效果”?
🧭 微調的新思路:輕量化微調登場
針對上述問題,研究者提出了各種輕量化微調方案:
-
Adapter Tuning:在網絡中插入額外模塊,僅訓練這部分參數;
-
Prompt Tuning / Prefix Tuning:凍結模型,僅訓練“提示詞前綴”;
-
LoRA(Low-Rank Adaptation):使用矩陣分解方法,僅訓練插入的小矩陣;
-
QLoRA:結合量化壓縮與LoRA,顯存優化進一步升級;
-
PEFT(Parameter-Efficient Fine-Tuning):將上述方法統一成一個通用框架。
這些方法顯著降低了計算資源消耗,同時還支持更靈活的多任務、增量更新,成為當前微調主流解決方案。
第二部分:LoRA原理與實現全剖析
在資源有限的現實情況下,想要“微調”一個大語言模型就像試圖用一輛小車拖動一架飛機,幾乎不可能。然而,自從LoRA(Low-Rank Adaptation of Large Language Models)被提出以來,輕量化微調不再是奢望。
1. LoRA 背后的核心思想:低秩矩陣近似
微調的本質,是更新神經網絡中的權重矩陣,比如 Transformer 中的 Attention 權重 W∈Rd×dW \in \mathbb{R}^{d \times d}W∈Rd×d。全參數微調會更新所有權重,而 LoRA 的做法是:
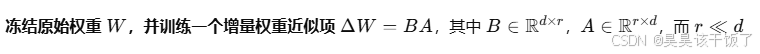 2. 數學原理簡單解釋(易懂版)
2. 數學原理簡單解釋(易懂版)
LoRA 的思想可以這樣直觀理解:
-
原始模型中有一個線性層:
y = W @ x -
使用 LoRA 之后,變成:
y = W @ x + B @ (A @ x)
最終,模型學的是一個“差值”,不會破壞預訓練知識,又能精準適配新任務。
3. LoRA 訓練的具體實現機制
插入位置:哪些層插 LoRA?
在 Transformer 架構中,最常用的插入位置是:
-
Attention中的 Query (Q) 和 Value (V) 子層
-
有時也包括 FFN中的第一層
參數配置含義
| 參數 | 含義 | 常用取值 |
r | 低秩矩陣的秩 | 4 / 8 / 16 |
lora_alpha | 縮放系數(相當于學習率倍率) | 16 / 32 |
lora_dropout | Dropout比率 | 0.05 / 0.1 |
target_modules | 作用模塊(如q_proj、v_proj) | 依模型結構而定 |
4. 使用 HuggingFace + PEFT 實現 LoRA 微調
pip install transformers accelerate peft datasetsfrom transformers import AutoModelForCausalLM, AutoTokenizer
from peft import get_peft_model, LoraConfig, TaskTypemodel = AutoModelForCausalLM.from_pretrained("bigscience/bloomz-560m")
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloomz-560m")lora_config = LoraConfig(r=8,lora_alpha=32,target_modules=["query_key_value"],lora_dropout=0.05,bias="none",task_type=TaskType.CAUSAL_LM
)model = get_peft_model(model, lora_config)from transformers import TrainingArguments, Trainertraining_args = TrainingArguments(per_device_train_batch_size=4,num_train_epochs=3,learning_rate=1e-4,fp16=True,logging_steps=10,output_dir="./lora_model"
)trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,
)
trainer.train()5. LoRA 的實際效果如何?
| 模型規模 | 全參數微調準確率 | LoRA微調準確率 | 參數數量對比 |
| 350M | 89.2% | 88.8% | ↓ 99.5% |
| 1.3B | 91.5% | 91.2% | ↓ 99.2% |
| 6.7B | 93.4% | 93.1% | ↓ 99.0% |
第三部分:QLoRA:輕量內存占用的黑科技
雖然 LoRA 極大降低了大模型微調的參數規模,但在面對數十億乃至百億參數模型時,顯存占用依然是橫亙在開發者面前的一座“大山”。QLoRA(Quantized Low-Rank Adapter)正是在這種背景下提出的,它結合了4-bit量化技術和 LoRA 的優點,大幅降低了訓練時的內存占用,同時保留了性能表現。
1. QLoRA 的核心創新點
QLoRA 并不是一個全新的架構,而是一種 訓練優化技術組合方案,主要包含三大技術:
| 技術名稱 | 功能作用 |
|---|---|
| NF4 量化(4-bit NormalFloat) | 將權重壓縮為 4bit,保留更多信息,降低內存 |
| Double Quantization | 進一步壓縮優化器狀態和梯度存儲 |
| LoRA 插入 | 僅訓練可調節的低秩權重,提高訓練效率 |
通過這三者組合,QLoRA 實現了在單張 A100 顯卡上訓練 65B 參數模型的可能性。
2. 量化技術詳解:什么是 NF4?
QLoRA 使用的是一種新的量化格式:NF4 (NormalFloat 4-bit),它不是普通的 int4,而是更接近浮點分布,能夠更好保留權重信息。
| 對比項 | int4 | NF4 |
| 精度 | 較低 | 較高 |
| 表達能力 | 有限 | 接近 fp16 |
| 用途 | 推理為主 | 訓練可用 |
NF4 是一種對稱的、以正態分布為核心的編碼方式,在保持低位寬的同時最大限度保留了參數分布的特征,適合用作權重矩陣的存儲格式。
3. HuggingFace 生態下的 QLoRA 實現
目前,QLoRA 的訓練流程已經由 HuggingFace 完整支持,依賴的核心庫包括:
-
transformers -
bitsandbytes -
peft -
accelerate
以下是一個最小可運行的QLoRA訓練樣例:
? 安裝環境
pip install transformers datasets peft bitsandbytes accelerate? 載入4bit模型 + 配置QLoRA參數
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import get_peft_model, LoraConfig, TaskTypemodel = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf",device_map="auto",load_in_4bit=True,quantization_config={"bnb_4bit_use_double_quant": True,"bnb_4bit_quant_type": "nf4","bnb_4bit_compute_dtype": "float16"}
)lora_config = LoraConfig(r=8,lora_alpha=32,lora_dropout=0.05,bias="none",task_type=TaskType.CAUSAL_LM
)model = get_peft_model(model, lora_config)? 啟動訓練(可配合 Trainer 或 SFTTrainer)
from transformers import TrainingArguments, Trainertraining_args = TrainingArguments(per_device_train_batch_size=4,gradient_accumulation_steps=8,warmup_steps=100,max_steps=1000,learning_rate=2e-4,fp16=True,logging_steps=10,output_dir="./qlora_model"
)trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,
)
trainer.train()4. 性能與顯存對比實測
| 模型規模 | LoRA 顯存占用 | QLoRA 顯存占用 | 精度變化 |
| 7B | ~24 GB | ~12 GB | 下降 <0.5% |
| 13B | ~45 GB | ~22 GB | 下降 <1.0% |
| 65B | 無法訓練 | ~46 GB | 下降 <1.5% |
QLoRA 在多項任務上(SQuAD、MT-Bench等)表現與全精度微調接近,遠優于 Prompt Tuning 等方式。
第四部分:PEFT 框架全家桶解析
隨著 LoRA 和 QLoRA 等方法在大模型微調中的流行,如何高效管理這些參數高效微調策略、統一調用接口、提高工程復用性,成為了另一個重要問題。為此,HuggingFace 推出了 PEFT(Parameter-Efficient Fine-Tuning)庫,作為輕量微調方法的集成平臺。
PEFT 讓用戶可以使用統一接口快速切換不同微調技術(如 LoRA、Prefix Tuning、Prompt Tuning、IA3、AdaLoRA 等),極大提升了實驗效率和工程可維護性。
1. PEFT 支持的微調方法一覽
| 微調方法 | 簡介 | 適用場景 |
|---|---|---|
| LoRA | 插入低秩矩陣,凍結原始權重 | 通用,推薦默認首選 |
| QLoRA | 結合LoRA+量化,節省顯存 | 資源受限場景 |
| Prefix Tuning | 學習一段固定前綴 | 小樣本、指令類任務 |
| Prompt Tuning | 學習提示詞向量(embedding) | GPT類任務、嵌入控制 |
| IA3 | 對激活層縮放調節 | 精度保留較好 |
| AdaLoRA | 動態調整秩r,提升訓練效率 | 精調期/實驗期使用 |
2. PEFT 架構與核心概念
PEFT 底層結構主要由以下幾個模塊組成:
-
PeftModel: 封裝了帶 Adapter 的模型; -
PeftConfig: 存儲 LoRA/Prefix 等參數配置; -
get_peft_model(): 用于將預訓練模型轉換為可微調結構; -
prepare_model_for_kbit_training(): 結合QLoRA時使用,用于凍結層設置和準備量化訓練。
3. 使用 PEFT 快速實現多種微調
以 LoRA 為例,代碼如下(適用于任意 HuggingFace 支持的模型結構):
from peft import get_peft_model, LoraConfig, TaskTypelora_config = LoraConfig(r=8,lora_alpha=32,lora_dropout=0.1,bias="none",task_type=TaskType.CAUSAL_LM,target_modules=["q_proj", "v_proj"]
)
model = get_peft_model(model, lora_config)若要切換為 Prefix Tuning,只需更換 Config 類型:
from peft import PrefixTuningConfigprefix_config = PrefixTuningConfig(num_virtual_tokens=20,task_type=TaskType.SEQ_2_SEQ_LM
)
model = get_peft_model(model, prefix_config)這就是 PEFT 的最大優勢:統一接口 + 模塊復用 + 插拔靈活。
4. PEFT 與 Checkpoint 存儲機制
PEFT 默認支持保存/加載的模型包括:
-
Adapter 權重(極小,僅幾MB)
-
配置文件(yaml/json)
-
可與原始模型動態合并推理
示例:保存 Adapter
model.save_pretrained("./adapter")加載時:
from peft import PeftModel
model = PeftModel.from_pretrained(base_model, "./adapter")如果需要部署完整模型,也支持使用 merge_and_unload() 合并參數:
model = model.merge_and_unload()
model.save_pretrained("./full")第五部分:實戰案例:微調大模型對話助手
本節將以一個典型應用場景為例,走完整個大模型微調流程:從模型選擇、數據準備,到訓練配置、效果驗證,并提供全套代碼與提示,助力快速落地。
1. 項目目標與模型選擇
目標:基于開源 LLaMA 或 ChatGLM 模型,構建一個中文對話助手,支持通用問答、情緒對話、命令執行等能力。
推薦模型:
-
meta-llama/Llama-2-7b-hf(英文、指令微調強) -
THUDM/chatglm2-6b(中文原生支持,部署友好)
依照資源選擇:
-
單A100:推薦 QLoRA + ChatGLM
-
多卡:可考慮 LLaMA2 + LoRA + Flash Attention 加速
2. 數據集準備
選用數據集:
-
Belle Group: 中文對話數據(含多輪、命令類) -
ShareGPT: 結構化英文對話數據(需清洗) -
OpenOrca,UltraChat: 高質量指令問答對話數據
若需自定義數據結構,可轉為如下格式:
{"instruction": "請幫我寫一段祝福語","input": "場景:公司年會","output": "祝公司年會圓滿成功,大家闔家歡樂!"
}格式要求:instruction-based 格式適配 SFT(Supervised Fine-Tuning)流程。
3. 配置訓練流程(以 QLoRA + PEFT 為例)
from peft import LoraConfig, get_peft_model, TaskType
from transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained("THUDM/chatglm2-6b",device_map="auto",load_in_4bit=True,trust_remote_code=True
)lora_config = LoraConfig(r=8,lora_alpha=32,lora_dropout=0.05,task_type=TaskType.CAUSAL_LM,bias="none"
)
model = get_peft_model(model, lora_config)使用 SFTTrainer 配合訓練配置:
from trl import SFTTrainertraining_args = TrainingArguments(output_dir="qlora-chatglm2",per_device_train_batch_size=4,gradient_accumulation_steps=4,learning_rate=2e-4,num_train_epochs=3,save_strategy="epoch",fp16=True,
)trainer = SFTTrainer(model=model,args=training_args,train_dataset=train_dataset,dataset_text_field="text",
)
trainer.train()4. 微調效果驗證與評估
可使用以下方式評估微調效果:
-
自定義 Prompt 測試
-
BLEU / ROUGE 指標評估生成質量
-
引入 MT-Bench 中文版進行結構化問答打分
示例 Prompt:
### Instruction:
請推薦三種適合情侶周末出游的地方### Response:
1. 鼓浪嶼:文藝、浪漫,適合拍照;2. 千島湖:自然風光宜人;3. 烏鎮:古鎮風情濃郁。微調后模型應表現出明顯風格變化、指令理解增強、情感表達更自然。
通過輕量化微調,可以用極低的成本,讓大模型真正適配特定任務與場景,不再止步于調用,而是深入參與模型能力構建。希望本文內容能為大家的后續深入研究與落地實踐提供參考與助力,也歡迎大家在實踐中不斷優化微調流程,推動大模型技術真正走進業務一線。





)


)


C++版——day8)




)


