????????一般情況下,爬蟲會使用云服務器來運行,這樣可以保證爬蟲24h不間斷運行。但是如何把爬蟲放到云服務器上面去呢?有人說用FTP,有人說用Git,有人說用Docker。但是它們都有很多問題。
????????FTP:使用FTP來上傳代碼,不僅非常不方便,而且經常出現把方向搞反,導致本地最新的代碼被服務器代碼覆蓋的問題。
????????Git:好處是可以進行版本管理,不會出現代碼丟失的問題。但操作步驟多,需要先在本地提交,然后登錄服務器,再從服務器上面把代碼下載下來。如果有很多服務器的話,每個服務器都登錄并下載一遍代碼是非常浪費時間的事情。
????????Docker:好處是可以做到所有服務器都有相同的環境,部署非常方便。但需要對Linux有比較深入的了解,對新人不友好,上手難度比較大。
????????為了簡化新人的上手難度,本次將會使用Scrapy官方開發的爬蟲部署、運行、管理工具:Scrapyd。
一、Scrapyd介紹與使用
1. Scrapyd的介紹
????????Scrapyd是Scrapy官方開發的,用來部署、運行和管理Scrapy爬蟲的工具。使用Scrapyd,可以實現一鍵部署Scrapy爬蟲,訪問一個網址就啟動/停止爬蟲。Scrapyd自帶一個簡陋網頁,可以通過瀏覽器看到爬蟲當前運行狀態或者查閱爬蟲Log。Scrapyd提供了官方API,從而可以通過二次開發實現更多更加復雜的功能。
????????Scrapyd可以同時管理多個Scrapy工程里面的多個爬蟲的多個版本。如果在多個云服務器上安裝Scrapyd,可以通過Python寫一個小程序,來實現批量部署爬蟲、批量啟動爬蟲和批量停止爬蟲。
2. 安裝Scrapyd
????????安裝Scrapyd就像安裝普通的Python第三方庫一樣容易,直接使用pip安裝即可:
pip install scrapyd
????????由于Scrapyd所依賴的其他第三方庫在安裝Scrapy的時候都已經安裝過了,所以安裝Scrapyd會非常快。
????????Scrapyd需要安裝到云服務器上,如果讀者沒有云服務器,或者想在本地測試,那么可以在本地也安裝一個。
????????接下來需要安裝scrapyd-client,這是用來上傳Scrapy爬蟲的工具,也是Python的一個第三方庫,使用pip安裝即可:
pip install scrapyd-client????????這個工具只需要安裝到本地計算機上,不需要安裝到云服務器上。
3. 啟動Scrapyd
????????接下來需要在云服務器上啟動Scrapyd。在默認情況下,Scrapyd不能從外網訪問,為了讓它能夠被外網訪問,需要創建一個配置文件。
????????對于Mac OS和Linux系統,在/etc下創建文件夾scrapyd,進入scrapyd,創建scrapyd.conf文件。對于Windows系統,在C盤創建scrapyd文件夾,在文件夾中創建scrapyd.conf文件,文件內容如下:

????????除了bind_address這一項外,其他都可以保持默認。bind_address這一項的值設定為當前這臺云服務器的外網IP地址。
????????配置文件放好以后,在終端或者CMD中輸入scrapyd并按Enter鍵,這樣Scrapyd就啟動了。此時打開瀏覽器,輸入“http://云服務器IP地址:6800”格式的地址就可以打開Scrapyd自帶的簡陋網頁。
4. 部署爬蟲
????????Scrapyd啟動以后,就可以開始部署爬蟲了。打開任意一個Scrapy的工程文件,可以看到在工程的根目錄中,Scrapy已經自動創建了一個scrapy.cfg文件,打開這個文件,其內容如圖所示。
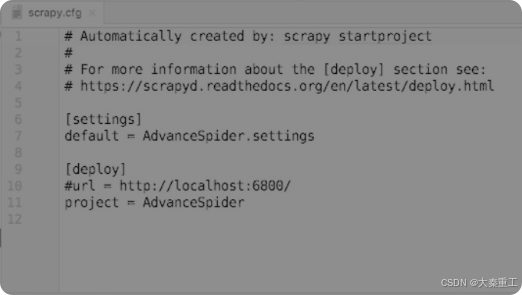
????????現在需要把第10行的注釋符號去掉,并將IP地址改為Scrapyd所在云服務器的IP地址。
最后,使用終端或者CMD進入這個Scrapy工程的根目錄,執行下面這一行命令部署爬蟲:
scrapyd-deploy????????命令執行完成后,爬蟲代碼就已經在服務器上面了;如果服務器上面的Python版本和本地開發環境的Python版本不一致,那么部署的時候需要注意代碼是否使用了服務器的Python不支持的語法;最好的辦法是使用本地和服務器一樣的版本開發環境(推薦使用 Conda)。需要記住,Scrapyd只是一個管理Scrapy爬蟲的工具而已,只有能夠正常運行的爬蟲放到Scrapyd上面,才能夠正常工作。
5.啟動/停止爬蟲
????????在上傳了爬蟲以后,就可以啟動爬蟲了。對于Mac OS和Linux系統,啟動和停止爬蟲非常簡單。要啟動爬蟲,需要在終端輸入下面這一行格式的代碼:
? ? curl http://云服務器IP地址:6800/schedule.json-d project=爬蟲工程名-d spider=爬蟲名????????執行完成命令以后,打開Scrapyd的網頁,進入Jobs頁面,可以看到爬蟲正在運行。單擊右側的Log鏈接,可以看到當前爬蟲的Log。需要注意的是,這里顯示的Log只能是在爬蟲里面使用logging模塊輸出的內容,而不會顯示print函數打印出來的內容。
如果爬蟲的運行時間太長,希望提前結束爬蟲,那么可以使用下面格式的命令來實現:
x
? ? curl http://云服務器IP地址:6800/schedule.json-d project=爬蟲工程名-d spider=爬蟲名????????運行以后,相當于對爬蟲按下了Ctrl+C組合鍵的效果。如果爬蟲本身已經運行結束了,那么執行命令以后的返回內容中,?“prevstate”這一項的值就為null,如果運行命令的時候爬蟲還在運行,那么這一項的值就為“running”?。對于Windows系統,啟動和停止爬蟲稍微麻煩一點,這是由于Windows的CMD功能較弱,沒有像Mac OS和Linux的終端一樣擁有curl這個發起網絡請求的自帶工具。但既然是發起網絡請求,那么只需要借助Python和requests就可以完成。先來看看啟動爬蟲的命令:
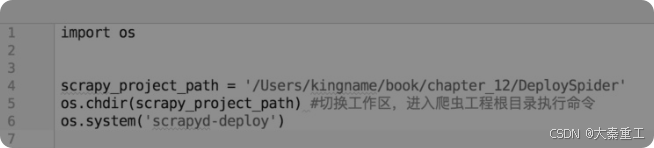
? ? curl http://192.168.31.210:6800/schedule.json -d project=DeploySpider -d spider=Example????????顯而易見,其中的“http://192.168.31.210:6800/schedule.json”是一個網址,后面的-d中的d對應的是英文data數據的首字母,project=DeploySpider和spider=Example又剛好是Key、Value的形式,這和Python的字典有點像。而requests的POST方法剛好有一個參數也是data,它的值正好也是一個字典,所以使用requests的POST方法就可以實現啟動爬蟲。由于部署爬蟲的時候直接執行scrapyd-deploy命令,所以如何使用Python來自動化部署爬蟲呢?其實也非常容易。在Python里面使用os這個自帶模塊就可以執行系統命令,如圖:
????????使用Python與requests的好處不僅在于可以幫助Windows實現控制爬蟲,還可以用來實現批量部署、批量控制爬蟲。假設有一百臺云服務器,只要每一臺上面都安裝了Scrapyd,那么使用Python來批量部署并啟動爬蟲所需要的時間不超過1min。這里給出一個批量部署并啟動爬蟲的例子,首先在爬蟲的根目錄下創建一個scrapy_template.cfg文件,其內容如圖所示。
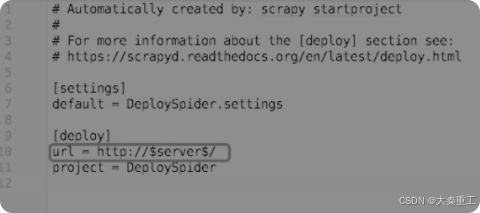
????????scrapy_template.cfg與scrapy.cfg的唯一不同之處就在于url這一項,其中的IP地址和端口變成了$server$。接下來編寫批量部署和運行爬蟲的腳本,如圖所示。
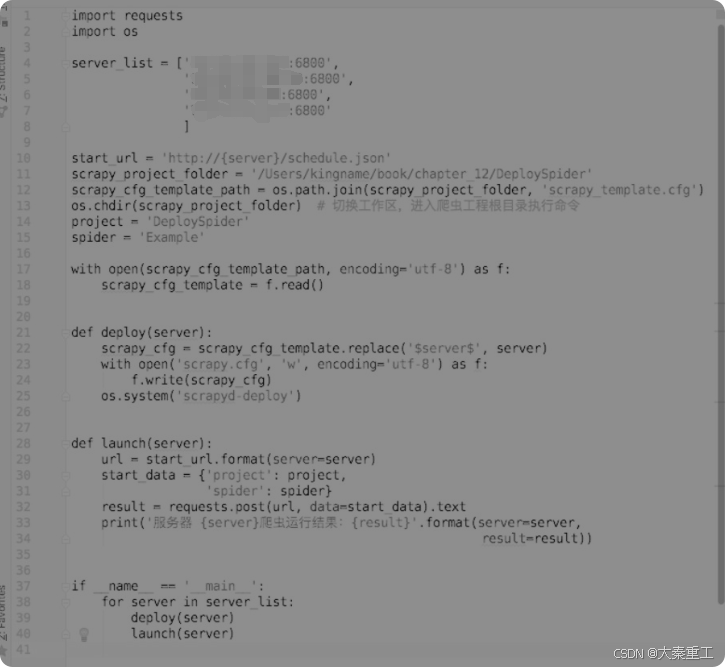
????????這個腳本的作用是逐一修改scrapy.cfg里面的IP地址和端口,每次修改完成以后就部署并運行爬蟲。運行完成以后再使用下一個服務器的IP地址修改scrapy.cfg,再部署再運行,直到把爬蟲部署到所有的服務器上并運行。
二、權限管理
????????在整個使用Scrapyd的過程中,只要知道IP地址和端口就可以操作爬蟲。如果IP地址和端口被別人知道了,那豈不是別人也可以隨意控制你的爬蟲?確實是這樣的,因為Scrapyd沒有權限管理系統。任何人只要知道了IP地址和端口就可以控制爬蟲。為了彌補Scrapyd沒有權限管理系統這一短板,就需要借助其他方式來對網絡請求進行管控。帶權限管理的反向代理就是一種解決辦法。能實現反向代理的程序很多,本次以Nginx為例來進行說明。
1. Nginx的介紹
????????Nginx讀作Engine X,是一個輕量級的高性能網絡服務器、負載均衡器和反向代理。為了解決Scrapyd的問題,需要用Nginx做反向代理。所謂“反向代理”?,是相對于“正向代理”而言的。前面章節所用到的代理是正向代理。正向代理幫助請求者(爬蟲)隱藏身份,爬蟲通過代理訪問服務器,服務器只能看到代理IP,看不到爬蟲;反向代理幫助服務器隱藏身份。用戶只知道服務器返回的內容,但不知道也不需要知道這個內容是在哪里生成的。使用Nginx反向代理到Scrapyd以后,Scrapyd本身只需要開通內網訪問即可。用戶訪問Nginx, Nginx再訪問Scrapyd,然后Scrapyd把結果返回給Nginx, Nginx再把結果返回給用戶。這樣只要在Nginx上設置登錄密碼,就可以間接實現Scrapyd的訪問管控了,如圖所示。

????????這個過程就好比是家里的保險箱沒有鎖,如果把保險箱放在大庭廣眾之下,誰都可以去里面拿錢。但是現在把保險箱放在房間里,房間門有鎖,那么即使保險箱沒有鎖也沒關系,只有手里有房間門鑰匙的人才能拿到保險箱里面的錢。Scrapyd就相當于這里的“保險箱”?,云服務器就相當于這里的“房間”, Nginx就相當于“房間門”?,而登錄賬號和密碼就相當于房間門的“鑰匙”?。為了完成這個目標,需要先安裝Nginx。由于這里涉及爬蟲的部署和服務器的配置,因此僅以Linux的Ubuntu為例。一般不建議Windows做爬蟲服務器,也不建議購買很多臺蘋果計算機(因為太貴了)來搭建爬蟲服務器。
2.Nginx的安裝
????????在Ubuntu中安裝Nginx非常簡單,使用一行命令即可完成:
? ? sudo apt-get install nginx????????安裝好以后,需要考慮以下兩個問題。(1)服務器是否有其他的程序占用了80端口。(2)服務器是否有防火墻。對于第1個問題,如果有其他程序占用了80端口,那么Nginx就無法啟動。因為Nginx會默認打開80端口,展示一個安裝成功的頁面。當其他程序占用了80端口,Nginx就會因為拿不到80端口而報錯。要解決這個問題,其辦法有兩個,關閉占用80端口的程序,或者把Nginx默認開啟的端口改為其他端口。如果云服務器為國內的服務器,建議修改Nginx的默認啟動端口,無論是否有其他程序占用了80端口。這是因為國內服務器架設網站是需要進行備案的,而80端口一般是給網站用的。如果沒有備案就開啟了80端口,有可能導致云服務器被運營商停機。
????????比如,講監聽端口從80修改為81;然后使用下列命令重啟Nginx
? ? sudo systemctl restart nginx? ? ? ?重啟Nginx可以在1~2s內完成。完成以后,使用瀏覽器訪問格式為“服務器IP:81”的地址,如果出現圖所示的頁面,表示服務器沒有防火墻,Nginx架設成功。
????????如果瀏覽器提示網頁無法訪問,那么就可能是服務器有防火墻,因此需要讓防火墻對81端口的數據放行。不同的云服務器提供商,其防火墻是不一樣的。例如Vultr,它沒有默認的防火墻,Nginx運行以后就能用;國內的阿里云,CentOS系統服務器自帶的防火墻為firewalld; Ubuntu系統自帶的防火墻是Iptables;亞馬遜的AWS,需要在網頁后臺開放端口;而UCloud,服務器自帶防火墻的同時,網頁控制臺上還有對端口的限制。因此,要開放一個端口,最好先看一下云服務器提供商使用的是什么樣的防火墻策略,并搜索提供商的文檔。如果云服務器提供商沒有相關的文檔,可以問 AI ,比如:Deepseek 。
????????開放了端口以后,就可以開始配置環境了。
3.配置反向代理
????????首先打開/etc/scrapyd/scrapyd.conf,把bind_address這一項重新改為127.0.0.1,并把http_port這一項改為6801,如圖所示。
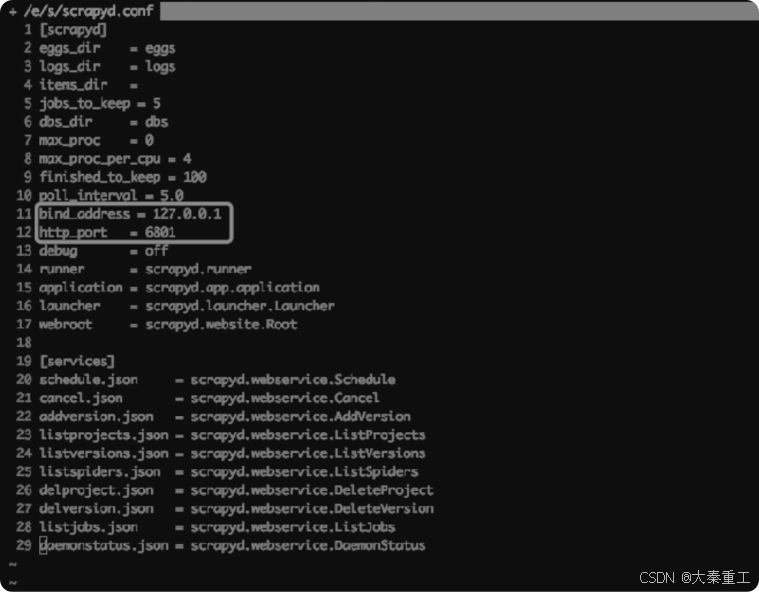
????????這樣修改以后,如果再重新啟動Scrapyd,只能在服務器上向127.0.0.1:6801發送請求操作Scrapyd,服務器之外是沒有辦法連上Scrapyd的。接下來配置Nginx,在/etc/nginx/sites-available文件夾下創建一個scrapyd.conf,其內容為:
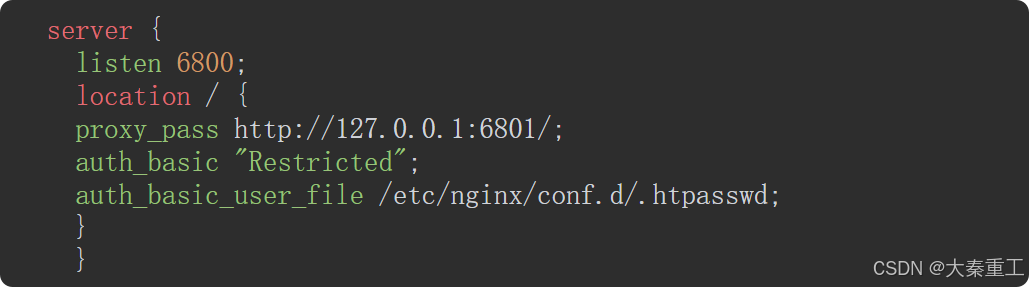
????????這個配置的意思是說,使用basic auth權限管理方法,對于通過授權的用戶,將它對6800端口的請求轉到服務器本地的6801端口。需要注意配置里面的記錄授權文件的路徑這一項:

????????在后面會將授權信息的記錄文件放在/etc/nginx/conf.d/.htpasswd這個文件中。寫好這個配置以后,保存。接下來,執行下面的命令,在/etc/nginx/sites-enabled文件夾下創建一個軟連接:

????????軟連接創建好以后,需要生成賬號和密碼的配置文件。
????????首先安裝apache2-utils軟件包:

????????安裝完成apache2-utils以后,cd進入/etc/nginx/conf.d文件夾,并執行命令為用戶kingname生成密碼文件:

????????屏幕會提示輸入密碼,與Linux的其他密碼輸入機制一樣,在輸入密碼的時候屏幕上不會出現*號,所以不用擔心,輸入完成密碼按Enter鍵即可。
????????上面的命令會在/etc/nginx/conf.d文件夾下生成一個.htpasswd的隱藏文件。有了這個文件,Nginx就能進行權限驗證了。接下來重啟Nginx:

????????重啟完成以后,啟動Scrapyd,再在瀏覽器上訪問格式為“http://服務器IP:6800”的網址,可以看到圖所示的頁面。
????????在這里輸入使用htpasswd生成的賬號和密碼,就可以成功登錄Scrapyd。
4.配置Scrapy工程
????????由于為Scrapyd添加了權限管控,涉及的部署爬蟲、啟動/停止爬蟲的地方都要做一些小修改。首先是部署爬蟲,為了讓scrapyd-deploy能成功地輸入密碼,需要修改爬蟲根目錄的scrapy.cfg文件,添加username和password兩項,其中username對應賬號,password對應密碼,如圖所示。
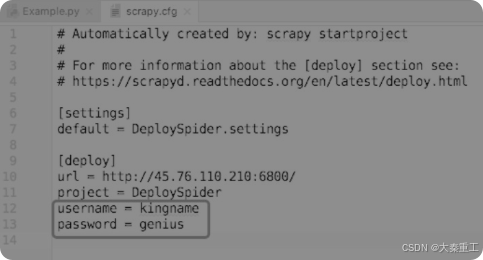
????????配置好scrapy.cfg以后,部署爬蟲的命令不變,還是進入這個Scrapy工程的根目錄,執行以下代碼即可:
? ? scrapyd-deploy????????使用curl啟動/關閉爬蟲,只需要在命令上加上賬號參數即可。賬號參數為“-u用戶名:密碼”?。所以,啟動爬蟲的命令為:
? ? curl http://192.168.31.210:6800/schedule.json-d project=工程名-d spider=爬蟲名 -u kingname:genius????????停止爬蟲的命令為:
? ? curl http://192.168.31.210:6800/cancel.json-d project=工程名-d job=爬蟲JOBID-u kingname:genius????????如果使用Python與requests編寫腳本來控制爬蟲,那么賬號信息可以作為POST方法的一個參數,參數名為auth,值為一個元組,元組第0項為賬號,第1項為密碼:
? ? result = requests.post(start_url, data=start_data, auth=('kingname', 'genius')).textresult = requests.post(end_url, data=end_data, auth=('kingname', 'genius')).text三、分布式架構介紹
????????之前講到了把目標放到Redis里面,然后讓多個爬蟲從Redis中讀取目標再爬取的架構,這其實就是一種主—從式的分布式架構。使用Scrapy,配合scrapy_redis,再加上Redis,也就實現了一個所謂的分布式爬蟲。實際上,這種分布式爬蟲的核心概念就是一個中心結點,也叫Master。它上面跑著一個Redis,所有的待爬網站的網址都在里面。其他云服務器上面的爬蟲(Slave)就從這個共同的Redis中讀取待爬網址。只要能訪問這個Master服務器,并讀取Redis,那么其他服務器使用什么系統什么提供商都沒有關系。例如,使用Ubuntu作為爬蟲的Master,用來做任務的派分。使用樹莓派、Windows 10 PC和Mac來作為分布式爬蟲的Slave,用來爬取網站,并將結果保存到Mac上面運行的MongoDB中。
????????其中,作為Master的Ubuntu服務器僅需要安裝Redis即可,它的作用僅僅是作為一個待爬網址的臨時中轉,所以甚至不需要安裝Python。在Mac、樹莓派和Windows PC中,需要安裝好Scrapy,并通過Scrapyd管理爬蟲。由于爬蟲會一直監控Master的Redis,所以在Redis沒有數據的時候爬蟲處于待命狀態。當目標被放進了Redis以后,爬蟲就能開始運行了。由于Redis是一個單線程的數據庫,因此不會出現多個爬蟲拿到同一個網址的情況。
????????嚴格來講,Master只需要能運行Redis并且能被其他爬蟲訪問即可。但是如果能擁有一個公網IP則更好。這樣可以從世界上任何一個能訪問互聯網的地方訪問Master。但如果實在沒有云服務器,也并不是說一定得花錢買一個,如果自己有很多臺計算機,完全可以用一臺計算機來作為Master,其他計算機來做Slave。Master也可以同時是Slave。Scrapy和Redis是安裝在同一臺計算機中的。這臺計算機既是Master又是Slave。Master一定要能夠被其他所有的Slave訪問。所以,如果所有計算機不在同一個局域網,那么就需要想辦法弄到一臺具有公網IP的計算機或者云服務器。在中國,大部分情況下,電信運營商分配到的IP是內網IP。在這種情況下,即使知道了IP地址,也沒有辦法從外面連進來。在局域網里面,因為局域網共用一個出口,局域網內的所有共用同一個公網IP。對網站來說,這個IP地址訪問頻率太高了,肯定不是人在訪問,從而被網站封鎖的可能性增大。而使用分布式爬蟲,不僅僅是為了提高訪問抓取速度,更重要的是降低每一個IP的訪問頻率,使網站誤認為這是人在訪問。所以,如果所有的爬蟲確實都在同一個局域網共用一個出口的話,建議為每個爬蟲加上代理。在實際生產環境中,最理想的情況是每一個Slave的公網IP都不一樣,這樣才能做到既能快速抓取,又能減小被反爬蟲機制封鎖的機會。
四、爬蟲開發中的法律與道德問題
????????全國人民代表大會常務委員會在2016年11月7日通過了《中華人民共和國網絡安全法》,2017年6月1日正式實施。爬蟲從過去游走在法律邊緣的灰色產業,變得有法可循。在開發爬蟲的過程中,一定要注意一些細節,否則容易在不知不覺中觸碰道德甚至是法律的底線。
1. 數據采集的法律問題
????????如果爬蟲爬取的是商業網站,并且目標網站使用了反爬蟲機制,那么強行突破反爬蟲機制可能構成非法侵入計算機系統罪、非法獲取計算機信息系統數據罪。如果目標網站有反爬蟲聲明,那么對方在被爬蟲爬取以后,可以根據服務器日志或者各種記錄來起訴使用爬蟲的公司。這里有幾點需要注意。
????????(1)目標網站有反爬蟲聲明。
????????(2)目標網站能在服務器中找到證據(包括但不限于日志、IP)。
????????(3)目標網站進行起訴。如果目標網站本身就是提供公眾查詢服務的網站,那么使用爬蟲是合法合規的。但是盡量不要爬取域名包含.gov的網站。
2. 數據的使用
????????公開的數據并不一定被允許用于第三方盈利目的。例如某網站可以供所有人訪問,但是如果一個開發把這個網站的數據爬取下來,然后用于盈利,那么可能會面臨法律風險。成熟的大數據公司在爬取并使用一個網站的數據時,一般都需要專業的律師對目標網站進行審核,看是否有禁止爬取或者禁止商業用途的相關規定。
3. 注冊及登錄可能導致的法律問題
????????自己能查看的數據,不一定被允許擅自拿給第三方查看。例如登錄很多網站以后,用戶可以看到“用戶自己”的數據。如果開發把自己的數據爬取下來用于盈利,那么可能面臨法律風險。因此,如果能在不登錄的情況下爬取數據,那么爬蟲就絕不應該登錄。這一方面是避免反爬蟲機制,另一方面也是減小法律風險。如果必須登錄,那么需要查看網站的注冊協議和條款,檢查是否有禁止將用戶自己后臺數據公開的相關條文。
4. 數據存儲
????????根據《個人信息和重要數據出境安全評估辦法(征求意見稿)?》第九條的規定,包含或超過50萬人的個人信息,或者包含國家關鍵信息的數據,如果要轉移到境外,必須經過主管或者監管部門組織安全評估。
5. 內幕交易
????????如果開發通過爬蟲抓取某公司網站的公開數據,分析以后發現這個公司業績非常好,于是買入該公司股票并賺了一筆錢。這是合法的。如果開發通過爬蟲抓取某公司網站的公開數據,分析以后發現這個公司業績非常好。于是將數據或者分析結果出售給某基金公司,從而獲得銷售收入。這也是合法的。如果開發通過爬蟲抓取某公司網站的公開數據,分析以后發現這個公司業績非常好,于是首先把數據或者分析結果出售給某基金公司,然后自己再買被爬公司的股票。此時,該開發涉嫌內幕交易,屬于嚴重違法行為。之所以出售數據給基金公司以后,開發就不能在基金公司購買股票之前再購買被爬公司股票,這是由于“基金公司將要購買哪一只股票”屬于內幕消息,使用內幕消息購買股票將嚴重損壞市場公平,因此已被定義為非法行為。而開發自身是沒有辦法證明自己買被爬公司的股票是基于對自己數據的信心,而不是基于知道了某基金公司將要購買該公司股票這一內幕消息的。在金融領域,有一個詞叫作“老鼠倉”?,與上述情況較為類似。
五、道德協議
????????在爬蟲開發過程中,除了法律限制以外,還有一些需要遵守的道德規范。雖然違反也不會面臨法律風險,但是遵守才能讓爬蟲細水長流。
????????robots.txt協議robots.txt是一個存放在網站根目錄下的ASCII編碼的文本文件。爬蟲在爬網站之前,需要首先訪問并獲取這個robots.txt文件的內容,這個文件里面的內容會告訴爬蟲哪些數據是可以爬取的,哪些數據是不可以爬取的。要查看一個網站的robots.txt,只需要訪問“網站域名/robots.txt”?,例如知乎的robots.txt地址為https://www.zhihu.com/robots.txt,訪問后的結果如圖所示。
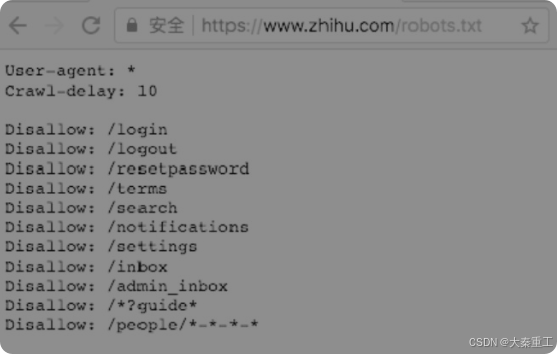
????????這個robots.txt文件表示,對于任何爬蟲,允許爬取除了以Disallow開頭的網址以外的其他網址,并且爬取的時間間隔為10s。Disallow在英文中的意思是“不允許”?,因此列在這個頁面上的網址是不允許爬取的,沒有列在這里的網址都是可以爬取的。在Scrapy工程的settings.py文件中,有一個配置項為“ROBOTSTXT_OBEY”?,如果設置為True,那么Scrapy就會自動跳過網站不允許爬取的內容。robots.txt并不是一種規范,它只是一種約定,所以即使不遵守也不會受到懲罰。但是從道德上講,建議遵守。
????????新手開發在開發爬蟲時,往往不限制爬蟲的請求頻率。這種做法一方面很容易導致爬蟲被網站屏蔽,另一方面也會給網站造成一定的負擔。如果很多爬蟲同時對一個網站全速爬取,那么其實就是對網站進行了DDOS(Distributed Denial-of-Service,分布式拒絕服務)攻擊。小型網站是無法承受這樣的攻擊的,輕者服務器崩潰,重者耗盡服務器流量。而一旦服務器流量被耗盡,網站在一個月內都無法訪問了。
????????開源是一件好事,但不要隨便公開爬蟲的源代碼。因為別有用心的人可能會拿到被公開的爬蟲代碼而對網站進行攻擊或者惡意抓取數據。網站的反爬蟲技術也是一種知識產權,而破解了反爬蟲機制再開源爬蟲代碼,其實就相當于把目標網站的反爬蟲技術泄漏了。這可能會導致一些不必要的麻煩。
????????在爬蟲開發和數據采集的過程中,閱讀網站的協議可以有效發現并規避潛在的法律風險。爬蟲在爬取網站的時候控制頻率,善待網站,才能讓爬蟲運行得更長久。
?--------------------------------------
沒有自由的秩序和沒有秩序的自由,同樣具有破壞性。

)


)


C++版——day8)




)



-clickhouse與hdfs)



被稱為 擴展運算符(Spread Operator) 或 剩余運算符(Rest Operator))