2022年全國職業院校技能大賽 高職組 “大數據技術與應用” 賽項賽卷(1卷)任務書
- 背景描述:
- 模塊A:大數據平臺搭建(容器環境)(15分)
- 任務一:Hadoop 完全分布式安裝配置
- 任務二:Spark on Yarn安裝配置
- 任務三:Flink on Yarn安裝配置
- 模塊B:離線數據處理(25分)
- 任務一:數據抽取
- 任務二:數據清洗
- 任務三:指標計算
- 模塊C:數據挖掘(10分)
- 任務一:特征工程
- 任務二:推薦系統
- 任務一:實時數據采集
- 任務二:使用Flink處理Kafka中的數據
- 模塊E:數據可視化(15分)
- 任務一:用柱狀圖展示消費額最高的國家
- 任務二:用餅狀圖展示各地區消費能力
- 任務三:用折線圖展示總消費額變化
- 任務四:用條形圖展示平均消費額最高的國家
- 任務五:用折柱混合圖展示地區平均消費額和國家平均消費額
- 需要培訓私信博主,資源環境也可以(包拿獎)!!
背景描述:
大數據時代背景下,電商經營模式發生很大改變。在傳統運營模式中,缺乏數據積累,人們在做出一些決策行為過程中,更多是憑借個人經驗和直覺,發展路徑比較自我封閉。而大數據時代,為人們提供一種全新的思路,通過大量的數據分析得出的結果將更加現實和準確。商家可以對客戶的消費行為信息數據進行收集和整理,比如消費者購買產品的花費、選擇產品的渠道、偏好產品的類型、產品回購周期、購買產品的目的、消費者家庭背景、工作和生活環境、個人消費觀和價值觀等。通過數據追蹤,知道顧客從哪兒來,是看了某網站投放的廣告還是通過朋友推薦鏈接,是新訪客還是老用戶,喜歡瀏覽什么產品,購物車有無商品,是否清空,還有每一筆交易記錄,精準鎖定一定年齡、收入、對產品有興趣的顧客,對顧客進行分組、標簽化,通過不同標簽組合運用,獲得不同目標群體,以此開展精準推送。
因數據驅動的零售新時代已經到來,沒有大數據,我們無法為消費者提供這些體驗,為完成電商的大數據分析工作,你所在的小組將應用大數據技術,以Scala作為整個項目的基礎開發語言,基于大數據平臺綜合利用Hudi、Spark、Flink、Vue.js等技術,對數據進行處理、分析及可視化呈現,你們作為該小組的技術人員,請按照下面任務完成本次工作。
模塊A:大數據平臺搭建(容器環境)(15分)
環境說明:
服務端登錄地址詳見各模塊服務端說明。
補充說明:宿主機可通過Asbru工具或SSH客戶端進行SSH訪問;
相關軟件安裝包在宿主機的/opt目錄下,請選擇對應的安裝包進行安裝,用不到的可忽略;
所有模塊中應用命令必須采用絕對路徑;
從本地倉庫中拉取鏡像,并啟動3個容器進入Master節點的方式為
docker exec –it master /bin/bash
進入Slave1節點的方式為
docker exec –it slave1 /bin/bash
進入Slave2節點的方式為
docker exec –it slave2 /bin/bash
同時將/opt目錄下的所有安裝包移動到3個容器節點中。
任務一:Hadoop 完全分布式安裝配置
本環節需要使用root用戶完成相關配置,安裝Hadoop需要配置前置環境。命令中要求使用絕對路徑,具體要求如下:
1、將Master節點JDK安裝包解壓并移動到/usr/java路徑(若路徑不存在,則需新建),將命令復制并粘貼至對應報告中;
2、修改/root/profile文件,設置JDK環境變量,配置完畢后在Master節點分別執行“java”和“javac”命令,將命令行執行結果分別截圖并粘貼至對應報告中;
3、請完成host相關配置,將三個節點分別命名為master、slave1、slave2,并做免密登錄,使用絕對路徑從Master節點復制JDK解壓后的安裝文件到Slave1、Slave2節點,并配置相關環境變量,將全部復制命令復制并粘貼至對應報告中;
4、在Master節點將Hadoop解壓到/opt目錄下,并將解壓包分發至Slave1、Slave2節點中,配置好相關環境,初始化Hadoop環境namenode,將初始化命令及初始化結果復制粘貼至對應報告中;
5、啟動Hadoop集群,查看Master節點jps進程,將查看結果復制粘貼至對應報告中。
任務二:Spark on Yarn安裝配置
本環節需要使用root用戶完成相關配置,已安裝Hadoop及需要配置前置環境,具體要求如下:
1、將scala包解壓到/usr/路徑,配置環境變量使其生效,將完整命令復制粘貼至對應報告中(若已安裝,則可跳過);
2、配置/root/profile文件,設置Spark環境變量,并使環境變量生效將環境變量配置內容復制粘貼至對應報告中;
3、完成on yarn相關配置,使用spark on yarn 的模式提交$SPARK_HOME/examples/jars/spark-examples_2.11-2.1.1.jar 運行的主類為org.apache.spark.examples.SparkPi,將運行結果粘貼至對應報告中。
任務三:Flink on Yarn安裝配置
本環節需要使用root用戶完成相關配置,已安裝Hadoop及需要配置前置環境,具體要求如下:
1、將Flink包解壓到路徑/opt目錄下,將完整命令復制粘貼至對應報告中;
2、修改/root/profile文件,設置Flink環境變量,并使環境變量生效將環境變量配置內容復制粘貼至對應報告中;
3、開啟Hadoop集群,在yarn上以per job模式(即Job分離模式,不采用Session模式)運行 $FLINK_HOME/examples/batch/WordCount.jar,將運行結果最后10行復制粘貼至對應報告中。
示例 :
flink run -m yarn-cluster -p 2 -yjm 2G -ytm 2G $FLINK_HOME/examples/batch/WordCount.jar
模塊B:離線數據處理(25分)
環境說明:
服務端登錄地址詳見各模塊服務端說明。
補充說明:各主機可通過Asbru工具或SSH客戶端進行SSH訪問;
Master節點MySQL數據庫用戶名/密碼:root/123456(已配置遠程連接);
Hive的元數據啟動命令為:
nohup hive --service metastore &
Hive的配置文件位于/opt/apache-hive-2.3.4-bin/conf/
Spark任務在Yarn上用Client運行,方便觀察日志。
任務一:數據抽取
編寫Scala工程代碼,將MySQL的shtd_store庫中表CUSTOMER、NATION、PART、PARTSUPP、REGION、SUPPLIER的數據全量抽取到Hive的ods庫中對應表customer,nation,part,partsupp,region,supplier中,將表ORDERS、LINEITEM的數據增量抽取到Hive的ods庫中對應表ORDERS,LINEITEM中。
1、抽取shtd_store庫中CUSTOMER的全量數據進入Hive的ods庫中表customer。字段排序、類型不變,同時添加靜態分區,分區字段類型為String,且值為當前比賽日的前一天日期(分區字段格式為yyyyMMdd)。并在hive cli執行show partitions ods.customer命令,將結果截圖復制粘貼至對應報告中;
2、抽取shtd_store庫中NATION的全量數據進入Hive的ods庫中表nation。字段排序、類型不變,同時添加靜態分區,分區字段類型為String,且值為當前比賽日的前一天日期(分區字段格式為yyyyMMdd)。并在hive cli執行show partitions ods.nation命令,將結果截圖復制粘貼至對應報告中;
3、抽取shtd_store庫中PART的全量數據進入Hive的ods庫中表part。字段排序、類型不變,同時添加靜態分區,分區字段類型為String,且值為當前比賽日的前一天日期(分區字段格式為yyyyMMdd)。并在hive cli執行show partitions ods.part命令,將結果截圖復制粘貼至對應報告中;
4、抽取shtd_store庫中PARTSUPP的全量數據進入Hive的ods庫中表partsupp。字段排序、類型不變,同時添加靜態分區,分區字段類型為String,且值為當前比賽日的前一天日期(分區字段格式為yyyyMMdd)。并在hive cli執行show partitions ods.partsupp命令,將結果截圖復制粘貼至對應報告中;
5、抽取shtd_store庫中REGION的全量數據進入Hive的ods庫中表region,字段排序、類型不變,同時添加靜態分區,分區字段類型為String,且值為當前比賽日的前一天日期(分區字段格式為yyyyMMdd)。并在hive cli執行show partitions ods.region命令,將結果截圖復制粘貼至對應報告中;
6、抽取shtd_store庫中SUPPLIER的全量數據進入Hive的ods庫中表supplier,字段排序、類型不變,同時添加靜態分區,分區字段類型為String,且值為當前比賽日的前一天日期(分區字段格式為yyyyMMdd)。并在hive cli執行show partitions ods.supplier命令,將結果截圖復制粘貼至對應報告中;
7、抽取shtd_store庫中ORDERS的增量數據進入Hive的ods庫中表orders,要求只取某年某月某日及之后的數據(包括某年某月某日),根據ORDERS表中ORDERKEY作為增量字段(提示:對比MySQL和Hive中的表的ORDERKEY大小),只將新增的數據抽入,字段類型不變,同時添加動態分區,分區字段類型為String,且值為ORDERDATE字段的內容(ORDERDATE的格式為yyyy-MM-dd,分區字段格式為yyyyMMdd),。并在hive cli執行select count(distinct(dealdate)) from ods.orders命令,將結果截圖復制粘貼至對應報告中;
8、抽取shtd_store庫中LINEITEM的增量數據進入Hive的ods庫中表lineitem,根據LINEITEM表中orderkey作為增量字段,只將新增的數據抽入,字段類型不變,同時添加靜態分區,分區字段類型為String,且值為當前比賽日的前一天日期(分區字段格式為yyyyMMdd)。并在hive cli執行show partitions ods.lineitem命令,將結果截圖復制粘貼至對應報告中。
任務二:數據清洗
編寫Scala工程代碼,將ods庫中相應表數據全量抽取到Hive的dwd庫中對應表中。表中有涉及到timestamp類型的,均要求按照yyyy-MM-dd HH:mm:ss,不記錄毫秒數,若原數據中只有年月日,則在時分秒的位置添加00:00:00,添加之后使其符合yyyy-MM-dd HH:mm:ss。
1、將ods庫中customer表數據抽取到dwd庫中dim_customer的分區表,分區字段為etldate且值與ods庫的相對應表該值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填寫“user1”,dwd_insert_time、dwd_modify_time均填寫操作時間,并進行數據類型轉換。在hive cli中按照cust_key順序排序,查詢dim_customer前1條數據,將結果內容復制粘貼至對應報告中;
2、將ods庫中part表數據抽取到dwd庫中dim_part的分區表,分區字段為etldate且值與ods庫的相對應表該值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填寫“user1”,dwd_insert_time、dwd_modify_time均填寫操作時間,并進行數據類型轉換。在hive cli中按照part_key順序排序,查詢dim_part前1條數據,將結果內容復制粘貼至對應報告中;
3、將ods庫中nation表數據抽取到dwd庫中dim_nation的分區表,分區字段為etldate且值與ods庫的相對應表該值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填寫“user1”,dwd_insert_time、dwd_modify_time均填寫操作時間,并進行數據類型轉換。在hive cli中按照nation_key順序排序,查詢dim_nation前1條數據,將結果內容復制粘貼至對應報告中;
4、將ods庫中region表數據抽取到dwd庫中dim_region的分區表,分區字段為etldate且值與ods庫的相對應表該值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中 dwd_insert_user、dwd_modify_user均填寫“user1”,dwd_insert_time、dwd_modify_time均填寫操作時間,并進行數據類型轉換。在hive cli中按照region_key順序排序,查詢dim_region表前1條數據,將結果內容復制粘貼至對應報告中;
5、將ods庫中orders表數據抽取到dwd庫中fact_orders的分區表,分區字段為etldate且值與ods庫的相對應表該值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填寫“user1”,dwd_insert_time、dwd_modify_time均填寫操作時間,并進行數據類型轉換。在執行hive cli執行select count(distinct(dealdate)) from dwd.fact_orders命令,將結果內容復制粘貼至對應報告中;
6、待任務5完成以后,需刪除ods.orders中的分區,僅保留最近的三個分區。并在hive cli執行show partitions ods.orders命令,將結果截圖粘貼至對應報告中;
7、將ods庫中lineitem表數據抽取到dwd庫中fact_lineitem的分區表,分區字段為etldate且值與ods庫的相對應表該值相等,抽取的條件為根據orderkey和partkey進行去重,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填寫“user1”,dwd_insert_time、dwd_modify_time均填寫操作時間,并進行數據類型轉換。在hive cli執行show partitions dwd.fact_lineitem命令,將結果截圖粘貼至對應報告中。
任務三:指標計算
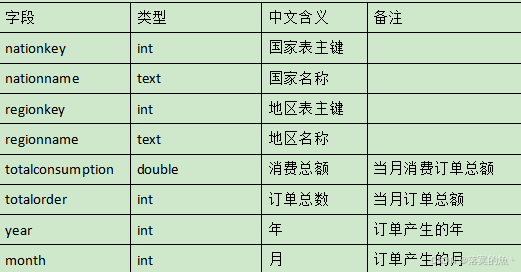
1、編寫Scala工程代碼,根據dwd層表統計每個地區、每個國家、每個月下單的數量和下單的總金額,存入MySQL數據庫shtd_store的nationeverymonth表(表結構如下)中,然后在Linux的MySQL命令行中根據訂單總數、消費總額、國家表主鍵三列均逆序排序的方式,查詢出前5條,將SQL語句與執行結果截圖粘貼至對應報告中;
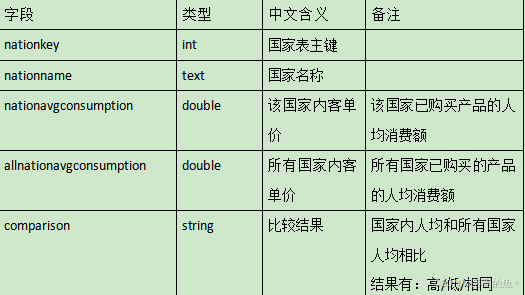
2、請根據dwd層表計算出某年每個國家的平均消費額和所有國家平均消費額相比較結果(“高/低/相同”),存入MySQL數據庫shtd_store的nationavgcmp表(表結構如下)中,然后在Linux的MySQL命令行中根據訂單總數、消費總額、國家表主鍵三列均逆序排序的方式,查詢出前5條,將SQL語句與執行結果截圖粘貼至對應報告中;
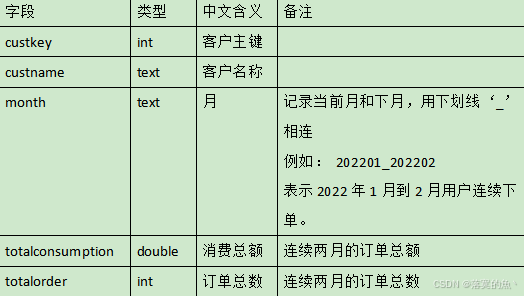
3、編寫Scala工程代碼,根據dwd層表統計連續兩個月下單并且下單金額保持增長的用戶,訂單發生時間限制為大于等于某年,存入MySQL數據庫shtd_store的usercontinueorder表(表結構如下)中。然后在Linux的MySQL命令行中根據訂單總數、消費總額、客戶主鍵三列均逆序排序的方式,查詢出前5條,將SQL語句與執行結果截圖粘貼至對應報告中。
模塊C:數據挖掘(10分)
環境說明:
服務端登錄地址詳見各模塊服務端說明。
補充說明:各主機可通過Asbru工具或SSH客戶端進行SSH訪問;
Master節點MySQL數據庫用戶名/密碼:root/123456(已配置遠程連接);
Hive的元數據啟動命令為:
nohup hive --service metastore &
Hive的配置文件位于/opt/apache-hive-2.3.4-bin/conf/
Spark任務在Yarn上用Client運行,方便觀察日志。
該模塊均使用Scala編寫,利用Spark相關庫完成。
任務一:特征工程
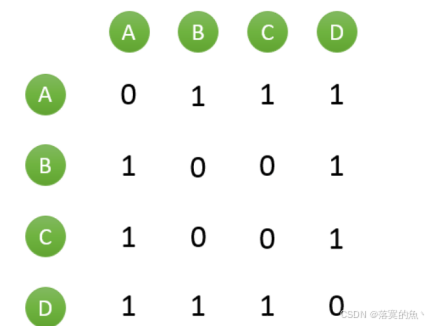
1、根據dwd庫中fact_orders表,將其轉換為以下類型矩陣:其中A表示用戶A,B表示用戶B,矩陣中的【0,1】值為1表示A用戶與B用戶之間購買了1個相同的零件,0表示A用戶與B用戶之間沒有購買過相同的零件。將矩陣保存為txt文件格式并存儲在HDFS上,使用命令查看文件前2行,將執行結果截圖粘貼至對應報告中;
2、對dwd庫中dim_part獲取partkey 、mfgr、brand、size、retailprice五個字段并進行數據預處理,再進行歸一化并保存至dwd.fact_part_machine_data中,對制造商與品牌字段進行one-hot編碼處理(將制造商與品牌的值轉換成列名添加至表尾部,若該零部件屬于該品牌則置為1,否則置為0),并按照partkey,size進行順序排序,然后在Hive cli中執行命令desc dwd.fact_part_machine_data 中查詢出結果,將SQL語句與執行結果截圖粘貼至對應報告中。
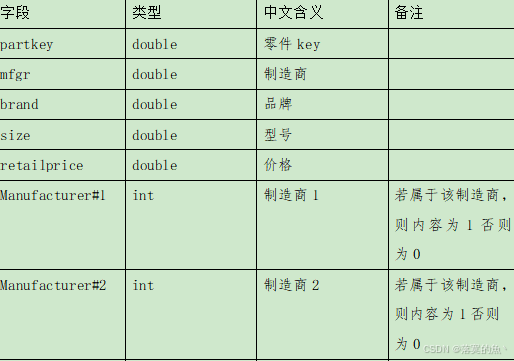
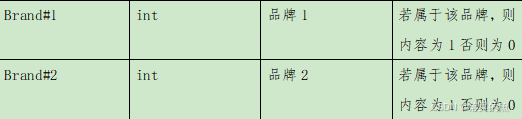
任務二:推薦系統
1、根據任務一的結果,獲取與該用戶相似度(矩陣內的值最高)最高的前10個用戶,并結合hive中dwd層的fact_orders表、fact_lineitem表、fact_part_machine_data表,獲取到這10位用戶已購買過的零部件,并剔除該用戶已購買的零部件,并通過計算用戶已購買產品與該數據集中余弦相似度累加,輸出前5零部件key作為推薦使用。將輸出結果保存至MySQL的part_machine表中。然后在Linux的MySQL命令行中查詢出前5條數據,將SQL語句與執行結果截圖粘貼至對應報告中。
模塊D:數據采集與實時計算(20分)
環境說明:
服務端登錄地址詳見各模塊服務端說明。
補充說明:各主機可通過Asbru工具或SSH客戶端進行SSH訪問;
請先檢查ZooKeeper、Kafka、Redis端口看是否已啟動,若未啟動則各啟動命令如下:
ZK啟動(netstat -ntlp查看2181端口是否打開)
/usr/zk/zookeeper-3.4.6/bin/zkServer.sh start
Redis啟動(netstat -ntlp查看6379端口是否打開)
/usr/redis/bin/redis-server /usr/redis/bin/redis.conf
Kafka啟動(netstat -ntlp查看9092端口是否打開)
/opt/kafka/kafka_2.11-2.0.0/bin/kafka-server-start.sh -daemon
(空格連接下行)/opt/kafka/kafka_2.11-2.0.0/config/server.propertiesFlink
任務在Yarn上用per job模式(即Job分離模式,不采用Session模式),方便Yarn回收資源。
任務一:實時數據采集
1、在Master節點使用Flume采集實時數據生成器26001端口的socket數據,將數據存入到Kafka的Topic中(topic名稱為order,分區數為4),將Flume的配置截圖粘貼至對應報告中;
2、Flume接收數據注入kafka 的同時,將數據備份到HDFS目錄/user/test/flumebackup下,將備份結果截圖粘貼至對應報告中。
任務二:使用Flink處理Kafka中的數據
編寫Scala工程代碼,使用Flink消費Kafka中Topic為order的數據并進行相應的數據統計計算。
1、使用Flink消費Kafka中的數據,統計個人實時訂單總額,將key設置成totalprice存入Redis中(再使用hash數據格式,key存放為用戶id,value存放為該用戶消費總額),使用redis cli以get key方式獲取totalprice值,將結果截圖粘貼至對應報告中,需兩次截圖,第一次截圖和第二次截圖間隔一分鐘以上,第一次截圖放前面,第二次放后面。
2、在任務1進行的同時需監控若發現ORDERSTATUS字段為F,將數據存入MySQL表alarmdata中(可考慮側邊流的實現),然后在Linux的MySQL命令行中根據ORDERKEY逆序排序,查詢出前5條,將SQL語句與執行結果截圖粘貼至對應報告中;
3、使用Flink消費kafka中的數據,統計每分鐘下單的數量,將key設置成totalorder存入redis中。使用redis cli以get key方式獲取totalorder值,將結果粘貼至對應報告中,需兩次截圖,第一次截圖(應該在job啟動2分鐘數據穩定后再截圖)和第二次截圖時間間隔應達一分鐘以上,第一次截圖放前面,第二次放后面。(注:流數據中,時間未精確到時分秒,建議StreamTimeCharacteristic設置成ProcessingTime(默認)或IngestionTime。)
模塊E:數據可視化(15分)
環境說明:
數據接口地址及接口描述詳見各模塊服務端說明。
任務一:用柱狀圖展示消費額最高的國家
編寫Vue工程代碼,根據接口,用柱狀圖展示某年某月消費額最高的5個國家,同時將用于圖表展示的數據結構在瀏覽器的console中進行打印輸出,將圖表可視化結果和瀏覽器console打印結果分別截圖并粘貼至對應報告中。
任務二:用餅狀圖展示各地區消費能力
編寫Vue工程代碼,根據接口,用餅狀圖展示某年第一季度各地區的消費總額占比,同時將用于圖表展示的數據結構在瀏覽器的console中進行打印輸出,將圖表可視化結果和瀏覽器console打印結果分別截圖并粘貼至對應報告中。
任務三:用折線圖展示總消費額變化
編寫Vue工程代碼,根據接口,用折線圖展示某年上半年商城總消費額的變化情況,同時將用于圖表展示的數據結構在瀏覽器的console中進行打印輸出,將圖表可視化結果和瀏覽器console打印結果分別截圖并粘貼至對應報告中。
任務四:用條形圖展示平均消費額最高的國家
編寫Vue工程代碼,根據接口,用條形圖展示某年平均消費額最高的5個國家,同時將用于圖表展示的數據結構在瀏覽器的console中進行打印輸出,將圖表可視化結果和瀏覽器console打印結果分別截圖并粘貼至對應報告中。
任務五:用折柱混合圖展示地區平均消費額和國家平均消費額
編寫Vue工程代碼,根據接口,用折柱混合圖展示某年地區平均消費額和國家平均消費額的對比情況,柱狀圖展示平均消費額最高的5個國家,折線圖展示每個國家所在的地區的平均消費額變化,同時將用于圖表展示的數據結構在瀏覽器的console中進行打印輸出,將圖表可視化結果和瀏覽器console打印結果分別截圖并粘貼至對應報告中。
需要培訓私信博主,資源環境也可以(包拿獎)!!





解析一)









)

(詳解))



時自動輸出COCO指標(AP):2025最新配置與代碼詳解 (小白友好 + B站視頻))

