前言
由于計算機無法認識到文字內容,因此在訓練模型時需要將文字映射到計算機能夠識別的編碼內容。
映射的流程如下:
- 首先將文字內容按照詞表映射到成唯一的數字ID。比如“我愛中國”,將“中”映射為1,將“國”映射到2。
- 再將文字映射到的數字ID映射成向量。比如“中”映射成了ID=1,再將1映射成某個向量,比如[0,0,0,0,0,1]。
# 構建數據集:詞匯表、訓練集、驗證集、測試集vocab, train_data, dev_data, test_data = build_dataset(config, args.word)# 構建數據迭代器,用于批量加載數據train_iter = build_iterator(train_data, config)dev_iter = build_iterator(dev_data, config)test_iter = build_iterator(test_data, config)?這篇文章的目的就是搞懂上面的代碼如何實現,即如何構建文字數據集和迭代器。
源碼
# coding: UTF-8
# coding: UTF-8
# 導入必要的庫
import os # 操作系統接口,用于文件路徑處理
import torch # PyTorch深度學習框架
import numpy as np # 數值計算庫
import pickle as pkl # 對象序列化/反序列化,用于保存詞匯表
from tqdm import tqdm # 進度條顯示
import time
from datetime import timedelta# 全局常量定義
MAX_VOCAB_SIZE = 10000 # 詞匯表最大容量限制
UNK, PAD = '<UNK>', '<PAD>' # 特殊標記:未知詞(UNK)和填充符(PAD)def build_vocab(file_path, tokenizer, max_size, min_freq):"""構建詞匯表字典Args:file_path: 訓練集文件路徑tokenizer: 分詞函數(按詞或字符分割)max_size: 最大詞匯表大小min_freq: 詞的最小出現頻次閾值Returns:vocab_dic: 詞到索引的映射字典,包含UNK和PAD"""vocab_dic = {}# 遍歷訓練集文件的每一行with open(file_path, 'r', encoding='UTF-8') as f:for line in tqdm(f): # 使用tqdm顯示進度條lin = line.strip()if not lin:continue # 跳過空行content = lin.split('\t') # 分割文本和標簽,取文本內容# 分詞并統計詞頻for word in tokenizer(content):vocab_dic[word] = vocab_dic.get(word, 0) + 1# 篩選詞頻≥min_freq的詞,按詞頻降序排列,取前max_size個vocab_list = sorted([item for item in vocab_dic.items() if item >= min_freq],key=lambda x: x, reverse=True)[:max_size]# 生成詞到索引的映射字典vocab_dic = {word_count: idx for idx, word_count in enumerate(vocab_list)}# 添加未知詞和填充符的索引(排在最后兩位)vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})return vocab_dicdef build_dataset(config, use_word):"""構建數據集Args:config: 配置對象,包含文件路徑等參數use_word: 分詞方式,True表示按詞分割,False按字符分割Returns:vocab: 詞匯表字典train/dev/test: 處理后的數據集"""# 定義分詞器if use_word:tokenizer = lambda x: x.split(' ') # 按空格分割(詞級別)else:tokenizer = lambda x: [y for y in x] # 按字符分割# 加載或創建詞匯表if os.path.exists(config.vocab_path):vocab = pkl.load(open(config.vocab_path, 'rb')) # 從文件加載else:vocab = build_vocab(config.train_path, tokenizer, MAX_VOCAB_SIZE, min_freq=1)pkl.dump(vocab, open(config.vocab_path, 'wb')) # 保存詞匯表print(f"Vocab size: {len(vocab)}")# -----------------------n-gram哈希函數定義-----------------------def biGramHash(sequence, t, buckets):"""計算第t個位置的bigram哈希值公式: (前一個詞的哈希值 * 質數) % 桶大小說明:如果t-1越界,用0代替(相當于用PAD的哈希值)"""t1 = sequence[t - 1] if t - 1 >= 0 else 0return (t1 * 14918087) % buckets # 14918087是一個大質數def triGramHash(sequence, t, buckets):"""計算第t個位置的trigram哈希值公式: (前兩個詞的哈希值組合 * 質數) % 桶大小說明:如果t-1或t-2越界,用0代替"""t1 = sequence[t - 1] if t - 1 >= 0 else 0t2 = sequence[t - 2] if t - 2 >= 0 else 0return (t2 * 14918087 * 18408749 + t1 * 14918087) % buckets # 雙質數減少沖突# -------------------------------------------------------------def load_dataset(path, pad_size=32):"""加載并處理單個數據集文件Args:path: 數據集文件路徑pad_size: 填充/截斷后的固定長度Returns:contents: 處理后的數據列表,元素為(詞索引, 標簽, 長度, bigram, trigram)"""contents = []with open(path, 'r', encoding='UTF-8') as f:for line in tqdm(f): # 顯示進度條lin = line.strip()if not lin:continuecontent, label = lin.split('\t') # 分割文本和標簽# 分詞并處理長度token = tokenizer(content)seq_len = len(token)# 填充或截斷至固定長度pad_sizeif pad_size:if len(token) < pad_size:# 注意:這里用vocab.get(PAD)可能存在錯誤,PAD應為詞匯表中已存在的鍵token.extend([vocab.get(PAD)] * (pad_size - len(token))) # 填充else:token = token[:pad_size] # 截斷seq_len = pad_size # 更新實際長度為pad_size# 將詞轉換為索引,未知詞用UNK的索引words_line = []for word in token:words_line.append(vocab.get(word, vocab.get(UNK))) # 雙重保險取UNK索引# 生成n-gram特征(FastText模型需要)buckets = config.n_gram_vocab # 從配置獲取哈希桶數量bigram = []trigram = []for i in range(pad_size):# 為每個位置生成bigram和trigram的哈希值bigram.append(biGramHash(words_line, i, buckets))trigram.append(triGramHash(words_line, i, buckets))# 添加處理后的數據:詞索引、標簽、長度、bigram、trigramcontents.append((words_line, int(label), seq_len, bigram, trigram))return contents # 返回結構:[([...], 0, 32, [...], [...]), ...]# 加載并處理所有數據集train = load_dataset(config.train_path, config.pad_size)dev = load_dataset(config.dev_path, config.pad_size)test = load_dataset(config.test_path, config.pad_size)return vocab, train, dev, testclass DatasetIterater(object):"""數據集迭代器,用于按批次生成數據"""def __init__(self, batches, batch_size, device):"""Args:batches: 處理后的數據集,格式為[(words_line, label, seq_len, bigram, trigram), ...]batch_size: 每個批次的樣本數device: 數據存放設備(cpu或cuda)"""self.batch_size = batch_sizeself.batches = batchesself.n_batches = len(batches) // batch_size # 完整批次數self.residue = False # 是否包含不完整的剩余批次# 如果總樣本數不能被batch_size整除,設置residue標志if len(batches) % self.n_batches != 0:self.residue = Trueself.index = 0 # 當前批次索引self.device = device # 設備類型def _to_tensor(self, datas):"""將原始數據轉換為Tensor格式"""# 注釋掉的代碼為按序列長度排序的邏輯(可用于動態padding優化)# xx = [xxx for xxx in datas] # 獲取所有樣本的原始長度# indexx = np.argsort(xx)[::-1] # 按長度降序排列的索引# datas = np.array(datas)[indexx] # 重新排列數據# 構造各特征張量(LongTensor用于整型數據)x = torch.LongTensor([_ for _ in datas]).to(self.device) # 詞索引序列y = torch.LongTensor([_ for _ in datas]).to(self.device) # 標簽bigram = torch.LongTensor([_ for _ in datas]).to(self.device) # bigram特征trigram = torch.LongTensor([_ for _ in datas]).to(self.device) # trigram特征# 實際長度(考慮padding前的原始長度,但不超過pad_size)seq_len = torch.LongTensor([_ for _ in datas]).to(self.device)return (x, seq_len, bigram, trigram), y # 返回特征元組和標簽def __next__(self):"""生成下一個批次數據"""# 處理剩余的不完整批次(當總樣本數不是batch_size整數倍時)if self.residue and self.index == self.n_batches:batches = self.batches[self.index * self.batch_size: len(self.batches)]self.index += 1batches = self._to_tensor(batches)return batches# 所有批次處理完成后重置索引并拋出停止迭代異常elif self.index >= self.n_batches:self.index = 0raise StopIteration# 正常批次處理else:batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size]self.index += 1batches = self._to_tensor(batches)return batchesdef __iter__(self):"""返回迭代器自身"""return selfdef __len__(self):"""返回總批次數(包含剩余批次)"""return self.n_batches + 1 if self.residue else self.n_batchesdef build_iterator(dataset, config):"""構建數據集迭代器Args:dataset: 處理后的數據集config: 配置對象,需包含batch_size和device屬性Returns:DatasetIterater實例"""iter = DatasetIterater(dataset, config.batch_size, config.device)return iterdef get_time_dif(start_time):"""計算時間間隔Args:start_time: 開始時間戳Returns:timedelta: 格式化的時間差(秒級精度)示例:>>> start = time.time()>>> # 執行操作...>>> print(get_time_dif(start)) # 輸出: 0:00:12"""end_time = time.time()time_dif = end_time - start_timereturn timedelta(seconds=int(round(time_dif)))if __name__ == "__main__":"""預訓練詞向量提取(示例用法)"""# 文件路徑配置vocab_dir = "./THUCNews/data/vocab.pkl" # 詞匯表路徑pretrain_dir = "./THUCNews/data/sgns.sogou.char" # 預訓練向量路徑filename_trimmed_dir = "./THUCNews/data/vocab.embedding.sougou" # 輸出路徑emb_dim = 300 # 詞向量維度# 加載詞匯表(詞到id的映射字典)word_to_id = pkl.load(open(vocab_dir, 'rb'))# 初始化隨機詞向量矩陣(詞匯表大小 x 維度)embeddings = np.random.rand(len(word_to_id), emb_dim)# 加載預訓練詞向量with open(pretrain_dir, "r", encoding='UTF-8') as f:for i, line in enumerate(f.readlines()):# 跳過首行標題(如果存在)# if i == 0: continuelin = line.strip().split(" ")word = lin # 詞vector = lin[1:301] # 對應向量# 如果當前詞在詞匯表中,更新其向量if word in word_to_id:idx = word_to_id[word]emb = [float(x) for x in vector] # 轉換為浮點數列表embeddings[idx] = np.asarray(emb, dtype='float32') # 更新矩陣# 保存壓縮后的詞向量矩陣(npz格式)np.savez_compressed(filename_trimmed_dir, embeddings=embeddings)
數據集構建
def build_dataset(config, use_word):"""構建數據集Args:config: 配置對象,包含文件路徑等參數use_word: 分詞方式,True表示按詞分割,False按字符分割Returns:vocab: 詞匯表字典train/dev/test: 處理后的數據集"""# 定義分詞器if use_word:tokenizer = lambda x: x.split(' ') # 按空格分割(詞級別)else:tokenizer = lambda x: [y for y in x] # 按字符分割# 加載或創建詞匯表if os.path.exists(config.vocab_path):vocab = pkl.load(open(config.vocab_path, 'rb')) # 從文件加載else:vocab = build_vocab(config.train_path, tokenizer, MAX_VOCAB_SIZE, min_freq=1)pkl.dump(vocab, open(config.vocab_path, 'wb')) # 保存詞匯表print(f"Vocab size: {len(vocab)}")# -----------------------n-gram哈希函數定義-----------------------def biGramHash(sequence, t, buckets):"""計算第t個位置的bigram哈希值公式: (前一個詞的哈希值 * 質數) % 桶大小說明:如果t-1越界,用0代替(相當于用PAD的哈希值)"""t1 = sequence[t - 1] if t - 1 >= 0 else 0return (t1 * 14918087) % buckets # 14918087是一個大質數def triGramHash(sequence, t, buckets):"""計算第t個位置的trigram哈希值公式: (前兩個詞的哈希值組合 * 質數) % 桶大小說明:如果t-1或t-2越界,用0代替"""t1 = sequence[t - 1] if t - 1 >= 0 else 0t2 = sequence[t - 2] if t - 2 >= 0 else 0return (t2 * 14918087 * 18408749 + t1 * 14918087) % buckets # 雙質數減少沖突# -------------------------------------------------------------def load_dataset(path, pad_size=32):"""加載并處理單個數據集文件Args:path: 數據集文件路徑pad_size: 填充/截斷后的固定長度Returns:contents: 處理后的數據列表,元素為(詞索引, 標簽, 長度, bigram, trigram)"""contents = []with open(path, 'r', encoding='UTF-8') as f:for line in tqdm(f): # 顯示進度條lin = line.strip()if not lin:continuecontent, label = lin.split('\t') # 分割文本和標簽# 分詞并處理長度token = tokenizer(content)seq_len = len(token)# 填充或截斷至固定長度pad_sizeif pad_size:if len(token) < pad_size:# 注意:這里用vocab.get(PAD)可能存在錯誤,PAD應為詞匯表中已存在的鍵token.extend([vocab.get(PAD)] * (pad_size - len(token))) # 填充else:token = token[:pad_size] # 截斷seq_len = pad_size # 更新實際長度為pad_size# 將詞轉換為索引,未知詞用UNK的索引words_line = []for word in token:words_line.append(vocab.get(word, vocab.get(UNK))) # 雙重保險取UNK索引# 生成n-gram特征(FastText模型需要)buckets = config.n_gram_vocab # 從配置獲取哈希桶數量bigram = []trigram = []for i in range(pad_size):# 為每個位置生成bigram和trigram的哈希值bigram.append(biGramHash(words_line, i, buckets))trigram.append(triGramHash(words_line, i, buckets))# 添加處理后的數據:詞索引、標簽、長度、bigram、trigramcontents.append((words_line, int(label), seq_len, bigram, trigram))return contents # 返回結構:[([...], 0, 32, [...], [...]), ...]# 加載并處理所有數據集train = load_dataset(config.train_path, config.pad_size)dev = load_dataset(config.dev_path, config.pad_size)test = load_dataset(config.test_path, config.pad_size)return vocab, train, dev, test字/詞分割
if use_word:tokenizer = lambda x: x.split(' ') # 按空格分割(詞級別)else:tokenizer = lambda x: [y for y in x] # 按字符分割首先定義分詞器,如果是按照單詞分割,就按照空格做分割;如果是按照字分割,就按照字符做分割。代碼里的lambda表達式可以換成常規的寫法:
if use_word:def tokenizer(x):return x.split(' ') # 按空格分割成詞列表
else:def tokenizer(x):return [y for y in x] # 拆分成字符列表
?加載/創建詞匯表
接下來我們需要得到一個詞匯表,它的作用就是把文字轉換成數字ID。這里可以加載現成的,也可以自己生成一個詞匯表。
# 加載或創建詞匯表if os.path.exists(config.vocab_path):vocab = pkl.load(open(config.vocab_path, 'rb')) # 從文件加載else:vocab = build_vocab(config.train_path, tokenizer, MAX_VOCAB_SIZE, min_freq=1)pkl.dump(vocab, open(config.vocab_path, 'wb')) # 保存詞匯表print(f"Vocab size: {len(vocab)}")構建詞匯表的第一步是計算各個文字出現的頻次。
vocab_dic[word] = vocab_dic.get(word, 0) + 1
我們遍歷每一行文本內容,將每一句文本的回車符去掉,并按照之前設計好的分詞器進行分割。

遍歷之后可以得到一個字典,字典里面記錄的是每個字出現的次數。
 ?
?
這行代碼的作用是從詞匯字典中篩選出符合最小詞頻要求的單詞,并按詞頻從高到低排序,最后截取前 max_size個單詞形成最終的詞匯列表。
vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] >= min_freq], key=lambda x: x[1], reverse=True)[:max_size]-
vocab_dic.items()?
獲取字典中的鍵值對列表,格式為[(單詞1, 詞頻1), (單詞2, 詞頻2), ...]。
示例輸入:{'apple':5, 'banana':3, 'cherry':7} → [('apple',5), ('banana',3), ('cherry',7)] -
?列表推導式篩選
if _ >= min_freq?
過濾出詞頻≥min_freq 的單詞,_表示元組的第二個元素(詞頻)。如果min_freq=4, 篩選后:[('apple',5), ('cherry',7)](banana因詞頻3被剔除) -
?按詞頻降序排序
sorted(..., key=lambda x: x, reverse=True)?key=lambda x: x:指定按元組的第二個元素(詞頻)排序。reverse=True:降序排列(從高到低)。
排序后:[('cherry',7), ('apple',5)]
-
?截取前
max_size個元素[:max_size]?
保留排序后的前max_size個高頻詞。
若max_size=1:
→ 結果:[('cherry',7)] -
?最終輸出
vocab_list?
得到處理后的詞匯列表,格式為[(單詞, 詞頻), ...],按詞頻降序排列且長度≤max_size。
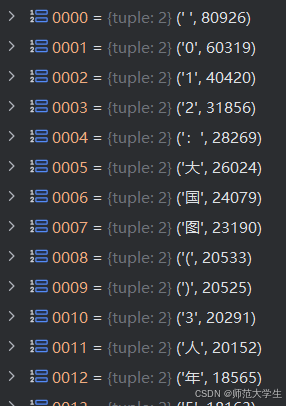
?
得到上圖所示的文字頻次表后,再做一步處理。下面這行代碼的?核心作用?是將排序后的詞匯列表轉換為 {字: 索引} 的字典映射。
vocab_dic = {word_count[0]: idx for idx, word_count in enumerate(vocab_list)}這行代碼我看著也頭大,可以拆解成下面這種寫法:
vocab_dic = {}
for idx, word_count in enumerate(vocab_list):word = word_count # word_count 是 (單詞, 詞頻) 元組,取第一個元素即單詞vocab_dic[word] = idx
上面的代碼看起來就清晰多了,先是將原先的數組轉換為元組,這樣每個字都被賦予了一個數字ID,再將{字:數字ID}的形式存到哈希表里,如下圖所示:
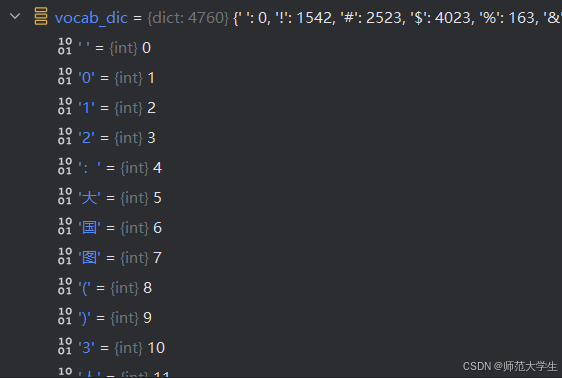
?
# 添加未知詞和填充符的索引(排在最后兩位)vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})最后再把未知詞和填充符號添加到字典的末尾就好了。
數據集處理
with open(path, 'r', encoding='UTF-8') as f:for line in tqdm(f): # 顯示進度條lin = line.strip()if not lin:continuecontent, label = lin.split('\t') # 分割文本和標簽# 分詞并處理長度token = tokenizer(content)seq_len = len(token)# 填充或截斷至固定長度pad_sizeif pad_size:if len(token) < pad_size:# 注意:這里用vocab.get(PAD)可能存在錯誤,PAD應為詞匯表中已存在的鍵token.extend([vocab.get(PAD)] * (pad_size - len(token))) # 填充else:token = token[:pad_size] # 截斷seq_len = pad_size # 更新實際長度為pad_size# 將詞轉換為索引,未知詞用UNK的索引words_line = []for word in token:words_line.append(vocab.get(word, vocab.get(UNK))) # 雙重保險取UNK索引# 生成n-gram特征(FastText模型需要)buckets = config.n_gram_vocab # 從配置獲取哈希桶數量bigram = []trigram = []for i in range(pad_size):# 為每個位置生成bigram和trigram的哈希值bigram.append(biGramHash(words_line, i, buckets))trigram.append(triGramHash(words_line, i, buckets))# 添加處理后的數據:詞索引、標簽、長度、bigram、trigramcontents.append((words_line, int(label), seq_len, bigram, trigram))在訓練的時候我們要保證每條語句的長度是一致的,所以要設置一個固定長度pad_size。小于這個長度就在句子后面增加PAD符號,大于這個長度就做后向截斷。
# 生成n-gram特征(FastText模型需要)buckets = config.n_gram_vocab # 從配置獲取哈希桶數量bigram = []trigram = []for i in range(pad_size):# 為每個位置生成bigram和trigram的哈希值bigram.append(biGramHash(words_line, i, buckets))trigram.append(triGramHash(words_line, i, buckets))這段代碼通過生成 ?Bigram(二元組)? 和 ?Trigram(三元組)? 的哈希特征,為深度學習模型提供?局部詞序信息?,增強模型對短語和上下文關系的捕捉能力,尤其在處理短文本時效果顯著。
- Bigram?:相鄰兩個詞的組合(如"深度學習" → "深度"-"學習")
- ?Trigram?:相鄰三個詞的組合(如"自然語言處理" → "自然"-"語言"-"處理")
在實際的實現里我們做了哈希映射,原因是直接存儲所有可能的N-Gram會導致?特征維度爆炸?。哈希映射的原理是將任意長度的N-Gram映射到固定范圍的桶,做維度壓縮。
def biGramHash(sequence, t, buckets):"""計算第t個位置的bigram哈希值公式: (前一個詞的哈希值 * 質數) % 桶大小說明:如果t-1越界,用0代替(相當于用PAD的哈希值)"""t1 = sequence[t - 1] if t - 1 >= 0 else 0return (t1 * 14918087) % buckets # 14918087是一個大質數def triGramHash(sequence, t, buckets):"""計算第t個位置的trigram哈希值公式: (前兩個詞的哈希值組合 * 質數) % 桶大小說明:如果t-1或t-2越界,用0代替"""t1 = sequence[t - 1] if t - 1 >= 0 else 0t2 = sequence[t - 2] if t - 2 >= 0 else 0return (t2 * 14918087 * 18408749 + t1 * 14918087) % buckets # 雙質數減少沖突使用?大質數組合相乘?的設計,主要目的是通過?數學特性降低哈希沖突率?,同時保證計算效率。
質數的特點是只能被1和自身整除,在乘法運算中不同質數組合能生成唯一性更高的中間值;另外,使用兩個間距大的千萬級大質數,能夠避免相鄰詞索引的小幅變化導致哈希值相似。比如:
詞t-2=100, 詞t-1=101 → 100*18,408,749 + 101*14,918,087 ≈ 3.3e9
詞t-2=101, 詞t-1=100 → 101*18,408,749 + 100*14,918,087 ≈ 3.4e9




指南)

案例教程:最新抖音視頻文案提取方法替代方案,音頻視頻提取文案插件制作,手把手教學,完全免費教程)



)

![[ctfshow web入門] web6](http://pic.xiahunao.cn/[ctfshow web入門] web6)


快速進入深度學習pytorch環境)


