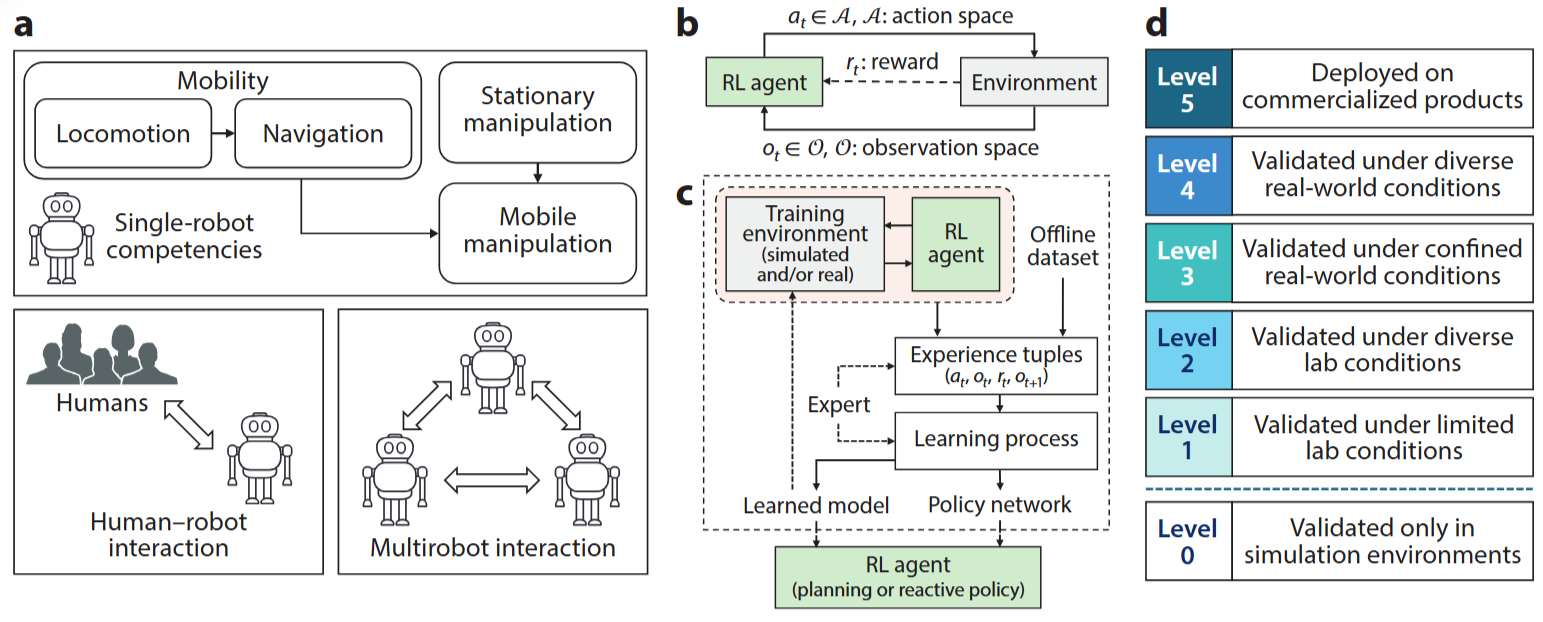
a. 機器人能力
1 單機器人能力(Single-robot competencies)
- 運動能力(Mobility)
- 行走(Locomotion)
- 導航(Navigation)
- 操作能力(Manipulation)
- 靜態操作(Stationary manipulation)
- 移動操作(Mobile manipulation_MoMa):將運動與操作結合
2 人機交互(Human–robot interaction):機器人與人類實時協作、交流
3 多機器人交互(Multirobot interaction):多個機器人之間的協同
b. 問題建模(Problem Formulation)
- 強化學習基本模型的要素:
- 狀態空間
- 動作空間
- 獎勵函數
- 智能體與環境的交互過程
c. 解決策略(Solution Approach)
- 訓練方式:
- 在線訓練(環境實時交互)
- 離線數據集(offline dataset)
- 專家演示(expert demonstration)
- 學習過程:
- 經驗元組
- 學習模型 / 策略網絡(learned model / policy network)
- 推理方式:
- 規劃式策略(planning policy)
- 反應式策略(reactive policy)
d. 現實世界成熟度(Level of Real-World Success)
| 等級 | 描述 |
|----------|----------------------------------|
| Level 5 | 已部署于商業化產品 |
| Level 4 | 在多種真實條件下驗證 |
| Level 3 | 在受限真實條件下驗證 |
| Level 2 | 在多樣化實驗室環境下驗證 |
| Level 1 | 在受限實驗室環境下驗證 |
| Level 0 | 僅在仿真環境中驗證 |
Problem Formulation
即如何為所研究的機器人能力構建最優控制策略的數學框架。在機器人任務中,強化學習問題通常被建模為:
- 部分可觀馬爾可夫決策過程(POMDP):用于單智能體強化學習(single-agent RL);
- 去中心化部分可觀馬爾可夫過程(Dec-POMDP):用于多智能體強化學習(Multiagent RL, MARL)任務。
a) 動作空間(Action Space)
動作空間定義了智能體的輸出控制信號類型。可細分為三類:
- 低層動作(Low-level actions):如關節空間命令或電機控制信號;
- 中層動作(Mid-level actions):如任務空間中的位移或姿態目標;
- 高層動作(High-level actions):如帶有時間延展性的任務序列命令或子程序調用(subroutines)。
b) 觀測空間(Observation Space)
觀測空間描述了智能體對環境狀態的感知方式,主要包括:
- 高維觀測(High-dimensional observations):如圖像、激光雷達點云等原始傳感器輸入;
- 低維狀態向量(Low-dimensional state estimates):如通過估計器或先驗模型獲得的簡化狀態表示。
c) 獎勵函數(Reward Function)
獎勵信號是強化學習的核心驅動因素。根據其反饋密度,可以分為:
- 稀疏獎勵(Sparse reward):只有在完成特定目標后才給出獎勵;
- 密集獎勵(Dense reward):在任務過程中持續給出反饋,以鼓勵或懲罰某些行為傾向。
Solution Approach
a) 模擬方式(Simulator Usage)
- Zero-shot sim-to-real transfer:完全基于模擬訓練,直接遷移至真實環境,無需真實數據微調;
- Few-shot sim-to-real transfer:模擬訓練為主,輔以少量真實環境微調;
- 無模擬器學習(learning directly offline or in the real world):完全在真實世界或離線數據集上進行訓練,未使用模擬器。
b) 基于模型學習(Model Learning)
分析是否使用機器人交互數據對系統的**動力學模型(transition dynamics)**進行建模,分為:
- Model-based RL:學習顯式模型,用于預測狀態轉移;
- Model-free RL:不使用或隱式使用環境模型;
- 部分建模(Partial modeling):僅對部分系統或任務階段建模。
c) 專家示范使用(Expert Usage)
是否引入專家策略(expert policy)或專家數據(如人類演示、oracle 策略)以加速學習過程。方法包括:
- 行為克隆(Behavior Cloning)
- 模仿學習(Imitation Learning)
- 獎勵塑形(Reward Shaping)等
d) 策略優化方式(Policy Optimization)
- 規劃方法(Planning-based):如模型預測控制(MPC)等;
- 離線RL(Offline RL)
- 異策略RL(Off-policy RL):如 DDPG、TD3、SAC;
- 同策略RL(On-policy RL):如 PPO、TRPO。
e) 策略 / 模型表示方式(Policy/Model Representation)
- 多層感知器(Multilayer Perceptrons, MLP)
- 卷積神經網絡(Convolutional Neural Networks, CNN)
- 循環神經網絡(Recurrent Neural Networks, RNN)
- 圖神經網絡、Transformer等新型架構
圖源:Deep Reinforcement Learning for Robotics: A Survey of Real-World Successes,Chen Tang1
案例教程:最新抖音視頻文案提取方法替代方案,音頻視頻提取文案插件制作,手把手教學,完全免費教程)



)

![[ctfshow web入門] web6](http://pic.xiahunao.cn/[ctfshow web入門] web6)


快速進入深度學習pytorch環境)









