一、先說FIFO
隊列是常見的一種數據結構,簡單看來就是一段數據緩存區,可以存儲一定量的數據,先存進來的數據會被先取出,First In Fist Out,就是FIFO。
FIFO主要用于緩沖速度不匹配的通信。
例如生產者(數據產生者)可能在短時間內生成大量數據,導致消費者(數據使用方)無法立即處理完,那么就需要用到隊列。生產者可以突然生成大量數據存到隊列中,然后就去休息,消費者再有條不紊地將數據一條條取出解析。

再具體點的例子,通信接口驅動接收到通信數據時,需要將其存入隊列,然后馬上再回去接收或等待新數據,相關的通信解析程序只需要從隊列中取數據即可。如果驅動每次接收到數據都要等待解析,則有可能導致新數據沒能及時接收而丟失。
除了緩沖速度不匹配的通信外,FIFO也是“多生產者-單消費者”場景的一種解決方案。
二、內核的kfifo 特別的地方
????????kfifo是linux內核的對隊列功能的實現。在內核中,它被稱為無鎖環形隊列。
所謂無鎖,就是當只有一個生產者和只有一個消費者時,操作fifo不需要加鎖。這是因為kfifo出隊和入隊時,不會改動到相同的變量。
例如,如果讓我們自己實現一個fifo,大家容易想到使用一個count來記錄fifo中的數據量,入隊一個則加一個,出隊一個則減一個:
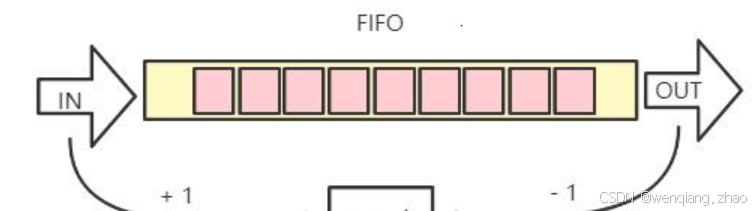
這種情況肯定是需要對count加鎖的。那kfifo是怎么做的呢?
kfifo使用了in和out兩個變量分別作為入隊和出隊的索引:
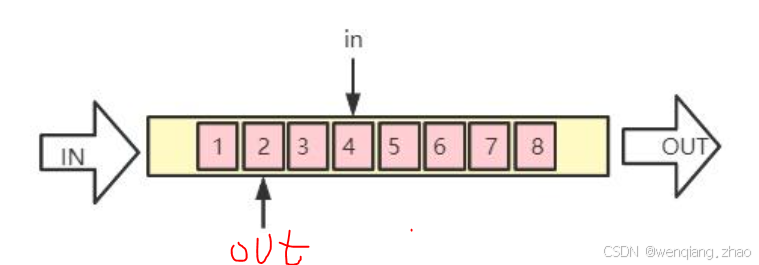
- 入隊n個數據時,in變量就+n
- 出隊k個數據時,out變量就+k
- out不允許大于in(out等于in時表示fifo為空)
- in不允許比out大超過fifo空間(比如上圖,in最多比out多8,此時表示fifo已滿)
如果in和out大于fifo空間了,比如上圖中的8,會減去8后重新開始嗎?
不,這兩個索引會一直往前加,不輕易回頭,為出入隊操作省下了幾個指令周期。
那入隊和出隊的數據從哪里開始存儲/讀取呢,我們第一時間會想到,把 in/out 用“%”對fifo大小取余就行了,是吧?
不,取余這種耗費資源的運算,內核開發者怎會輕易采用呢,kfifo的辦法是,把 in/out 與上fifo->mask。這個mask等于fifo的空間大小減一(其要求fifo的空間必須是2的次方大小)。這個“與”操作可比取余操作快得多了。
由此,kfifo就實現了“無鎖”“環形”隊列。
了解了上述原理,我們就能意識到,這個無鎖只是針對“單生產者-單消費者”而言的。“多生產者”時,則需要對入隊操作進行加鎖;同樣的,“多消費者”時需要對出隊操作進行加鎖。
特別的地方:它使用并行無鎖編程技術,即當它用于只有一個入隊線程和一個出隊線程的場情時,兩個線程可以并發操作,而不需要任何加鎖行為,就可以保證kfifo的線程安全
三、kfifo的實現
struct kfifo {unsigned char *buffer; /* the buffer holding the data */unsigned int size; /* the size of the allocated buffer */unsigned int in; /* data is added at offset (in % size) */unsigned int out; /* data is extracted from off. (out % size) */spinlock_t *lock; /* protects concurrent modifications */
};
這是kfifo的數據結構,kfifo主要提供了兩個操作,__kfifo_put(入隊操作)和__kfifo_get(出隊操作)。 它的各個數據成員如下:
buffer: 用于存放數據的緩存
size: buffer空間的大小,在初化時,將它向上擴展成2的冪
lock: 如果使用不能保證任何時間最多只有一個讀線程和寫線程,需要使用該lock實施同步。
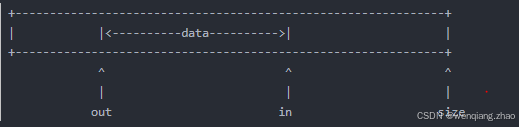
in, out: 和buffer一起構成一個循環隊列。 in指向buffer中隊頭,而且out指向buffer中的隊尾,它的結構如示圖如下:
3.2 kfifo 的功能
- 只支持一個讀者和一個讀者并發操作
- 無阻塞的讀寫操作,如果空間不夠,則返回實際訪問空間
kfifo_alloc 分配kfifo內存和初始化工作:
struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, spinlock_t *lock)
{unsigned char *buffer;struct kfifo *ret;/** round up to the next power of 2, since our 'let the indices* wrap' tachnique works only in this case.*/if (size & (size - 1)) {BUG_ON(size > 0x80000000);size = roundup_pow_of_two(size);}buffer = kmalloc(size, gfp_mask);if (!buffer)return ERR_PTR(-ENOMEM);ret = kfifo_init(buffer, size, gfp_mask, lock);if (IS_ERR(ret))kfree(buffer);return ret;
}
1.判斷一個數是不是2的次冪 :
kfifo要保證其緩存空間的大小為2的次冪,如果不是則向上取整為2的次冪。其對于2的次冪的判斷方式也是很巧妙的。如果一個整數n是2的次冪,則二進制模式必然是1000…,而n-1的二進制模式則是0111…,也就是說n和n-1的每個二進制位都不相同,例如:8(1000)和7(0111);n不是2的次冪,則n和n-1的二進制必然有相同的位都為1的情況,例如:7(0111)和6(0110)。這樣就可以根據 n & (n-1)的結果來判斷整數n是不是2的次冪,實現如下:
static inline bool is_power_of_2(uint32_t n)
{return (n != 0 && ((n & (n - 1)) == 0));
}2.將數字向上取整為2的次冪 :
如果設定的緩沖區大小不是2的次冪,則向上取整為2的次冪,例如:設定為5,則向上取為8。上面提到整數n是2的次冪,則其二進制模式為100…,故如果正數k不是n的次冪,只需找到其最高的有效位1所在的位置(從1開始計數)pos,然后1 << pos即可將k向上取整為2的次冪。實現如下:
static inline uint32_t roundup_power_of_2(uint32_t a)
{if (a == 0)return 0;uint32_t position = 0;for (int i = a; i != 0; i >>= 1)position++;return static_cast<uint32_t>(1 << position);
}
fifo->in & (fifo->size - 1) 再比如這種寫法取模,獲取已用的大小。這樣用邏輯與的方式相較于加減法更有效率
3.3?_kfifo_put與__kfifo_get詳解
__kfifo_put是入隊操作,它先將數據放入buffer里面,最后才修改in參數;
__kfifo_get是出隊操作,它先將數據從buffer中移走,最后才修改out。
unsigned int __kfifo_put(struct kfifo *fifo,unsigned char *buffer, unsigned int len)
{unsigned int l;len = min(len, fifo->size - fifo->in + fifo->out);/** Ensure that we sample the fifo->out index -before- we* start putting bytes into the kfifo.*/smp_mb();/* first put the data starting from fifo->in to buffer end */l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);/* then put the rest (if any) at the beginning of the buffer */memcpy(fifo->buffer, buffer + l, len - l);/** Ensure that we add the bytes to the kfifo -before-* we update the fifo->in index.*/smp_wmb();fifo->in += len;return len;
}
6行,環形緩沖區的剩余容量為fifo->size - fifo->in + fifo->out,讓寫入的長度取len和剩余容量中較小的,避免寫越界;
13行,加內存屏障,保證在開始放入數據之前,fifo->out取到正確的值(另一個CPU可能正在改寫out值)
16行,前面講到fifo->size已經2的次冪圓整,而且kfifo->in % kfifo->size 可以轉化為 kfifo->in & (kfifo->size – 1),所以fifo->size - (fifo->in & (fifo->size - 1)) 即位 fifo->in 到 buffer末尾所剩余的長度,l取len和剩余長度的最小值,即為需要拷貝l 字節到fifo->buffer + fifo->in的位置上。
17行,拷貝l 字節到fifo->buffer + fifo->in的位置上,如果l = len,則已拷貝完成,第20行len – l 為0,將不執行,如果l = fifo->size - (fifo->in & (fifo->size - 1)) ,則第20行還需要把剩下的 len – l 長度拷貝到buffer的頭部。
27行,加寫內存屏障,保證in 加之前,memcpy的字節已經全部寫入buffer,如果不加內存屏障,可能數據還沒寫完,另一個CPU就來讀數據,讀到的緩沖區內的數據不完全,因為讀數據是通過 in – out 來判斷的。
29行,注意這里 只是用了 fifo->in += len而未取模,這就是kfifo的設計精妙之處,這里用到了unsigned int的溢出性質,當in 持續增加到溢出時又會被置為0,這樣就節省了每次in向前增加都要取模的性能,錙銖必較,精益求精,讓人不得不佩服。
unsigned int __kfifo_get(struct kfifo *fifo,unsigned char *buffer, unsigned int len)
{unsigned int l;len = min(len, fifo->in - fifo->out);/** Ensure that we sample the fifo->in index -before- we* start removing bytes from the kfifo.*/smp_rmb();/* first get the data from fifo->out until the end of the buffer */l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);/* then get the rest (if any) from the beginning of the buffer */memcpy(buffer + l, fifo->buffer, len - l);/** Ensure that we remove the bytes from the kfifo -before-* we update the fifo->out index.*/smp_mb();fifo->out += len;return len;
}
6行,可去讀的長度為fifo->in – fifo->out,讓讀的長度取len和剩余容量中較小的,避免讀越界;
13行,加讀內存屏障,保證在開始取數據之前,fifo->in取到正確的值(另一個CPU可能正在改寫in值)
16行,前面講到fifo->size已經2的次冪圓整,而且kfifo->out % kfifo->size 可以轉化為 kfifo->out & (kfifo->size – 1),所以fifo->size - (fifo->out & (fifo->size - 1)) 即位 fifo->out 到 buffer末尾所剩余的長度,l取len和剩余長度的最小值,即為從fifo->buffer + fifo->in到末尾所要去讀的長度。
17行,從fifo->buffer + fifo->out的位置開始讀取l長度,如果l = len,則已讀取完成,第20行len – l 為0,將不執行,如果l =fifo->size - (fifo->out & (fifo->size - 1)) ,則第20行還需從buffer頭部讀取 len – l 長。
27行,加內存屏障,保證在修改out前,已經從buffer中取走了數據,如果不加屏障,可能先執行了增加out的操作,數據還沒取完,令一個CPU可能已經往buffer寫數據,將數據破壞,因為寫數據是通過fifo->size - (fifo->in & (fifo->size - 1))來判斷的 。
29行,注意這里 只是用了 fifo->out += len 也未取模,同樣unsigned int的溢出性質,當out 持續增加到溢出時又會被置為0,如果in先溢出,出現 in < out 的情況,那么 in – out 為負數(又將溢出),in – out 的值還是為buffer中數據的長度。
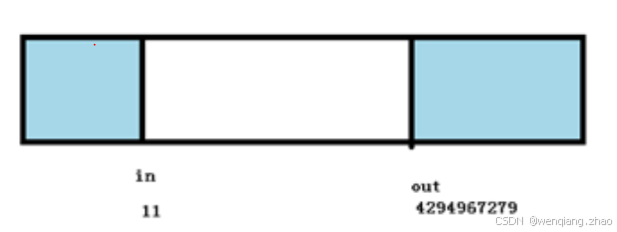
圖解一下 in 先溢出的情況,size = 64, 寫入前 in = 4294967291, out = 4294967279 ,數據 in – out = 12;
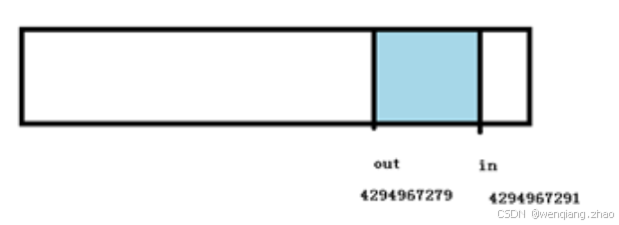
寫入 數據16個字節,則 in + 16 = 4294967307,溢出為 11,此時 in – out = –4294967268,溢出為28,數據長度仍然正確,由此可見,在這種特殊情況下,這種計算仍然正確,是不是讓人嘆為觀止,妙不可言?
3.4?kfifo_get和kfifo_put無鎖并發操作
計算機科學家已經證明,當只有一個讀經程和一個寫線程并發操作時,不需要任何額外的鎖,就可以確保是線程安全的,也即kfifo使用了無鎖編程技術,以提高kernel的并發。
為了避免讀者看到寫者預計寫入,但實際沒有寫入數據的空間,寫者必須保證以下的寫入順序:
1.往[kfifo->in, kfifo->in + len]空間寫入數據
2.更新kfifo->in指針為 kfifo->in + len
在操作1完成時,讀者是還沒有看到寫入的信息的,因為kfifo->in沒有變化,認為讀者還沒有開始寫操作,只有更新kfifo->in之后,讀者才能看到。
那么如何保證1必須在2之前完成,秘密就是使用內存屏障:smp_mb(),smp_rmb(), smp_wmb(),來保證對方觀察到的內存操作順序。
3.5 優點
kfifo優點:
實現單消費者和單生產者的無鎖并發訪問。多消費者和多生產者的時候還是需要加鎖的。
使用與運算in & (size-1)代替模運算
在更新in或者out的值時不做模運算,而是讓其自動溢出。這應該是kfifo實現最牛叉的地方了,利用溢出后的值參與運算,并且能夠保證結果的正確。溢出運算保證了以下幾點:
in - out為緩沖區中的數據長度
size - in + out 為緩沖區中空閑空間
in == out時緩沖區為空
size == (in - out)時緩沖區滿了
讀完kfifo代碼,令我想起那首詩“眾里尋他千百度,默然回首,那人正在燈火闌珊處”。不知你是否和我一樣,總想追求簡潔,高質量和可讀性的代碼,當用盡各種方法,江郞才盡之時,才發現Linux kernel里面的代碼就是我們尋找和學習的對象。
?




)









)
)



預覽的vue組件庫)