系列文章目錄
終章 1:Attention的結構
終章 2:帶Attention的seq2seq的實現
終章 3:Attention的評價
終章 4:關于Attention的其他話題
終章 5:Attention的應用
目錄
系列文章目錄
前言
Attention的結構
一.seq2seq存在的問題
二.編碼器的改進
三.編碼器的改進1
四.編碼器的改進2
五.編碼器的改進3
前言
上一章我們使用RNN生成了文本,又通過連接兩個RNN,將一個時序數據轉換為了另一個時序數據。我們將這個網絡稱為seq2seq,并用它成功求解了簡單的加法問題。之后,我們對這個seq2seq進行了幾處改進,幾乎解決了這個簡單的加法問題。 本章我們將進一步探索seq2seq的可能性(以及RNN的可能性)。這里,Attention這一強大而優美的技術將登場。Attention毫無疑問是近年來深度學習領域最重要的技術之一。本章的目標是在代碼層面理解Attention的結構,然后將其應用于實際問題,體驗它的奇妙效果。
Attention的結構
如上一章所述,seq2seq是一個非常強大的框架,應用面很廣。這里我們將介紹進一步強化seq2seq的注意力機制(attention mechanism,簡稱 Attention)。基于Attention 機制,seq2seq 可以像我們人類一樣,將“注意力”集中在必要的信息上。此外,使用Attention可以解決當前seq2seq 面臨的問題。 本節我們將首先指出當前seq2seq存在的問題,然后一邊說明Attention 的結構,一邊對其進行實現(transformer中的核心就是注意力機制Attention,不過是多頭注意力機制)
一.seq2seq存在的問題
seq2seq 中使用編碼器對時序數據進行編碼,然后將編碼信息傳遞給解碼器。此時,編碼器的輸出是固定長度的向量。實際上,這個“固定長度” 存在很大問題。因為固定長度的向量意味著,無論輸入語句的長度如何(無論多長),都會被轉換為長度相同的向量。以上一章的翻譯為例,如下圖所示,不管輸入的文本如何,都需要將其塞入一個固定長度的向量中。
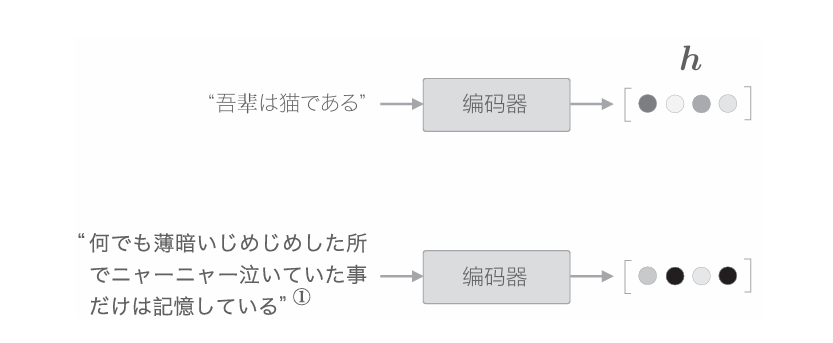
無論多長的文本,當前的編碼器都會將其轉換為固定長度的向量。就像 把一大堆西裝塞入衣柜里一樣,編碼器強行把信息塞入固定長度的向量中。 但是,這樣做早晚會遇到瓶頸。就像最終西服會從衣柜中掉出來一樣,有用的信息也會從向量中溢出。
現在我們就來改進seq2seq。首先改進編碼器,然后再改進解碼器。
二.編碼器的改進
到目前為止,我們都只將LSTM層的最后的隱藏狀態傳遞給解碼器, 但是編碼器的輸出的長度應該根據輸入文本的長度相應地改變。這是編碼器 的一個可以改進的地方。具體而言,如下圖所示,使用各個時刻的LSTM 層的隱藏狀態。
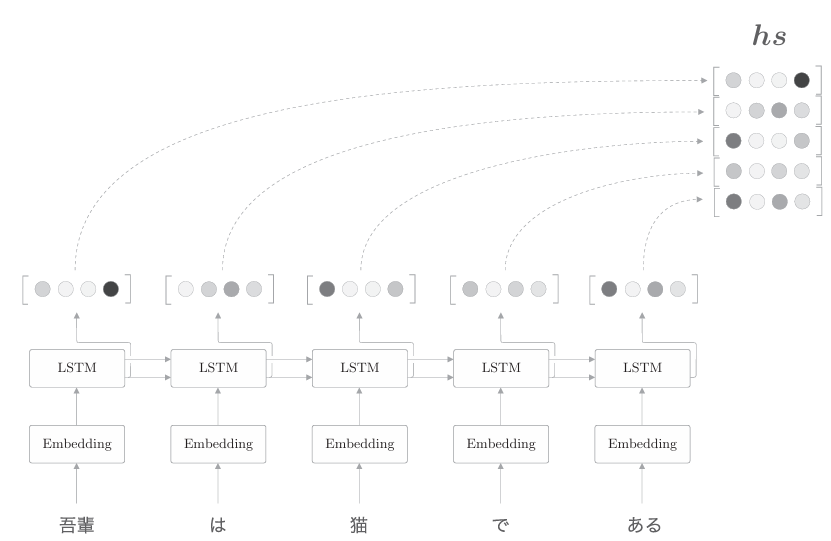
如上圖所示,使用各個時刻(各個單詞)的隱藏狀態向量,可以獲得和輸入的單詞數相同數量的向量。在上圖的例子中,輸入了5個單詞,此時編碼器輸出5個向量。這樣一來,編碼器就擺脫了“一個固定長度的向量”的制約
上圖中我們需要關注LSTM層的隱藏狀態的“內容”。此時,各個時刻的LSTM層的隱藏狀態都充滿了什么信息呢?有一點可以確定的是,各個時刻的隱藏狀態中包含了大量當前時刻的輸入單詞的信息。就上圖的例子來說,輸入“貓”時的LSTM層的輸出(隱藏狀態)受此時輸入的單詞“貓”的影響最大。因此,可以認為這個隱藏狀態向量蘊含許多“貓的成分”。按照這樣的理解,如下圖所示,編碼器輸出的hs矩陣就可以視為各個單詞對應的向量集合

以上就是對編碼器的改進。這里我們所做的改進只是將編碼器的全部時刻的隱藏狀態取出來而已。通過這個小改動,編碼器可以根據輸入語句的長度,成比例地編碼信息。那么,解碼器又將如何處理這個編碼器的輸出呢? 接下來,我們對解碼器進行改進。因為解碼器的改進有許多值得討論的地方,所以我們分3部分進行。
三.編碼器的改進1
編碼器整體輸出各個單詞對應的LSTM層的隱藏狀態向量hs。然后, 這個hs被傳遞給解碼器,以進行時間序列的轉換
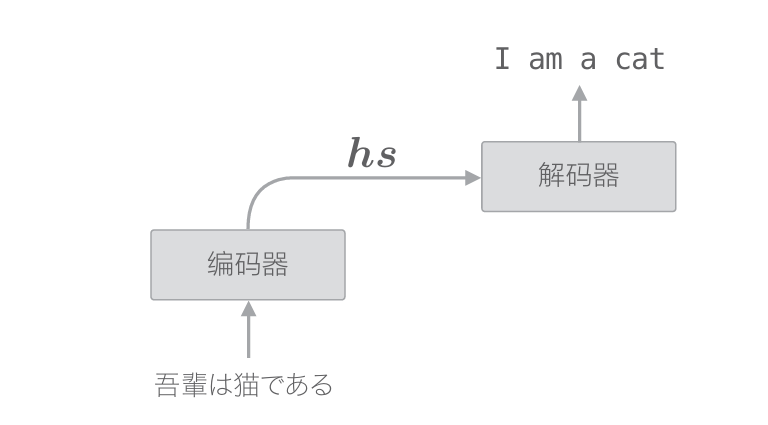
順便說一下,在上一章的最簡單的seq2seq中,僅將編碼器最后的隱藏狀態向量傳遞給了解碼器。嚴格來說,這是將編碼器的LSTM層的“最后” 的隱藏狀態放入了解碼器的LSTM層的“最初”的隱藏狀態。用圖來表示的話,解碼器的層結構如下圖所示
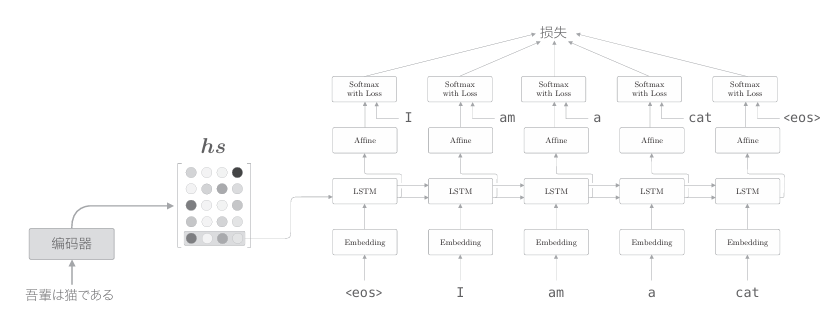
如上圖所示,上一章的解碼器只用了編碼器的LSTM層的最后的隱藏狀態。如果使用hs,則只提取最后一行,再將其傳遞給解碼器。下面我 們改進解碼器,以便能夠使用全部hs。 我們在進行翻譯時,大腦做了什么呢?比如,在將“吾輩は貓である” 這句話翻譯為英文時,肯定要用到諸如“吾輩=I”“ 貓 =cat”這樣的知識。 也就是說,可以認為我們是專注于某個單詞(或者單詞集合),隨時對這個 單詞進行轉換的。那么,我們可以在seq2seq中重現同樣的事情嗎?確切地說,我們可以讓seq2seq學習“輸入和輸出中哪些單詞與哪些單詞有關”這樣的對應關系嗎?
從現在開始,我們的目標是找出與“翻譯目標詞”有對應關系的“翻譯 源詞”的信息,然后利用這個信息進行翻譯。也就是說,我們的目標是僅關 注必要的信息,并根據該信息進行時序轉換。這個機制稱為Attention,是本章的主題。
在介紹Attention的細節之前,這里我們先給出它的整體框架。我們要實現的網絡的層結構如下圖所示。
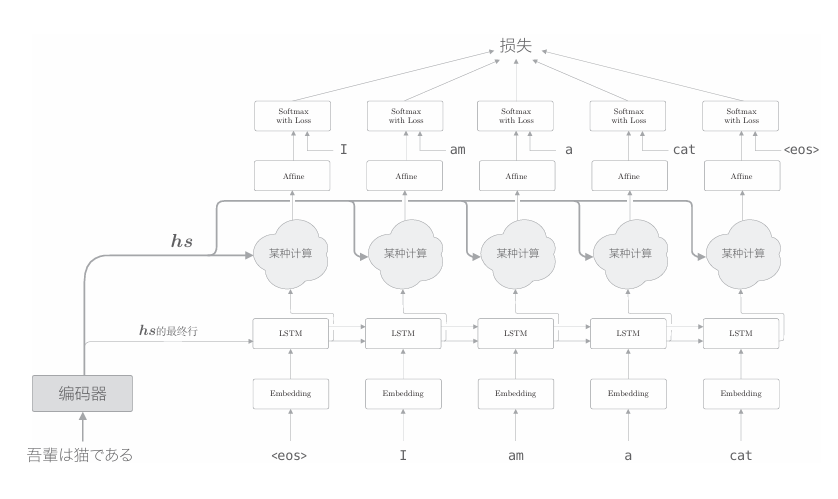
如上圖所示,我們新增一個進行“某種計算”的層。這個“某種計算”接收(解碼器)各個時刻的LSTM層的隱藏狀態和編碼器的hs。然后, 從中選出必要的信息,并輸出到Affine層。與之前一樣,編碼器的最后的隱藏狀態向量傳遞給解碼器最初的LSTM層。 上圖的網絡所做的工作是提取單詞對齊信息。具體來說,就是從hs 中選出與各個時刻解碼器輸出的單詞有對應關系的單詞向量。比如,當上圖的解碼器輸出“I”時,從hs中選出“吾輩”的對應向量。也就是說, 我們希望通過“某種計算”來實現這種選擇操作。不過這里有個問題,就是選擇(從多個事物中選取若干個)這個操作是無法進行微分的。
可否將“選擇”這一操作換成可微分的運算呢?實際上,解決這個問題的思路很簡單(但是,就像哥倫布蛋一樣,第一個想到是很難的)。這個思路就是,與其“單選”,不如“全選”。如下圖所示,我們另行計算表示各個單詞重要度(貢獻值)的權重。
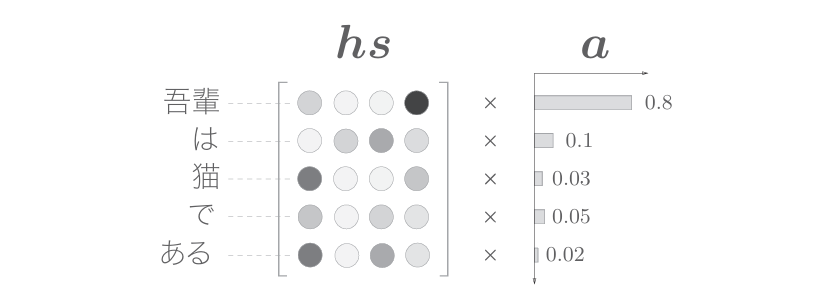
如下圖所示,這里使用了表示各個單詞重要度的權重(記為a)。此時,a像概率分布一樣,各元素是0.0~1.0的標量,總和是1。然后,計算這個表示各個單詞重要度的權重和單詞向量hs的加權和,可以獲得目標向量。這一系列計算如下圖所示

如上圖所示,計算單詞向量的加權和,這里將結果稱為上下文向量, 并用符號c表示。順便說一下,如果我們仔細觀察,就可以發現“吾輩”對應的權重為0.8。這意味著上下文向量c中含有很多“吾輩”向量的成分, 可以說這個加權和計算基本代替了“選擇”向量的操作。假設“吾輩”對應 的權重是1,其他單詞對應的權重是0,那么這就相當于“選擇”了“吾輩” 向量。
下面,我們從代碼的角度來看一下目前為止的內容。這里隨意地生成編碼器的輸出hs和各個單詞的權重a,并給出求它們的加權和的實現,代碼如下所示,請注意多維數組的形狀
import numpy as np
T, H = 5, 4
hs = np.random.randn(T, H)
a = np.array([0.8, 0.1, 0.03, 0.05, 0.02])ar = a.reshape(5, 1).repeat(4, axis=1)
print(ar.shape)
# (5, 4)t = hs * ar
print(t.shape)
# (5, 4)c = np.sum(t, axis=0)
print(c.shape)
# (4, )
設時序數據的長度T=5,隱藏狀態向量的元素個數H=4,這里給出了加權和的計算過程。我們先關注代碼ar = a.reshape(5, 1).repeat(4, axis=1)。 如下圖所示,這行代碼將a轉化為ar。
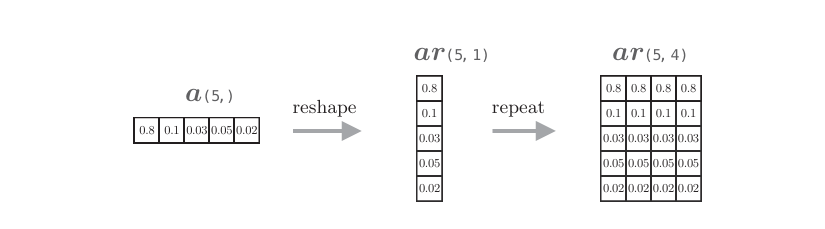
如上圖所示,我們要做的是復制形狀為(5,)的a,創建(5,4)的數組。 因此,通過a.reshape(5, 1) 將a的形狀從(5,)轉化為(5,1)。然后,在第1 個軸方向上(axis=0)重復這個變形后的數組4次,生成形狀為(5,4)的數組。
此外,這里也可以不使用repeat()方法,而使用NumPy的廣播功能。 此時,令ar = a.reshape(5, 1),然后計算hs * ar。如下圖所示,ar會自動擴展以匹配hs的形狀。
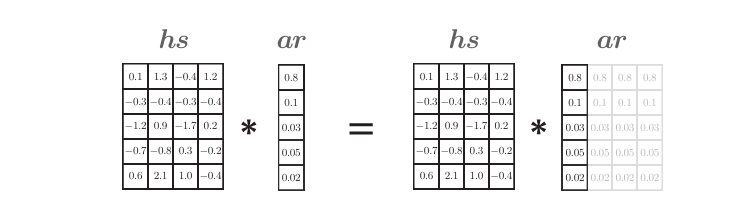
為了提高執行效率,這里應該使用NumPy的廣播,而不是repeat()方 法。但是,在這種情況下,需要注意的是,在許多我們看不見的地方多維數組的元素被復制了。這相當于計算圖中的Repeat節點。 因此,在反向傳播時,需要執行Repeat節點的反向傳播。 如上圖所示,先計算對應元素的乘積,然后通過c = np.sum(hs*ar, axis=0) 求和。這里,通過參數axis可以指定在哪個軸方向(維度)上求和。 如果我們注意一下數組的形狀,axis的使用方法就會很清楚。比如,當x的形狀為(X, Y, Z)時,np.sum(x, axis=1) 的輸出(和)的形狀為(X, Z)。這里的重點是,求和會使一個軸“消失”。在上面的例子中,hs*ar的形狀為 (5,4),通過消除第0個軸,獲得了形狀為(4,)的矩陣(向量)。
下面進行批處理版的加權和的實現,具體如下所示
N, T, H = 10, 5, 4
hs = np.random.randn(N, T, H)
a = np.random.randn(N, T)
ar = a.reshape(N, T, 1).repeat(H, axis=2)
# ar = a.reshape(N, T, 1) # 廣播機制t = hs * ar
print(t.shape)
# (10, 5, 4)c = np.sum(t, axis=1)print(c.shape)
# (10, 4)這里的批處理與之前的實現幾乎一樣。只要注意數組的形狀,應該很快就能確定repeat()和sum()需要指定的維度(軸)。作為總結,我們把加權 和的計算用計算圖表示出來

如上圖所示,這里使用Repeat節點復制a。之后,通過“×”節點 計算對應元素的乘積,通過Sum節點求和。現在考慮這個計算圖的反向傳播。其實,所需要的知識都已經齊備。這里重述一下要點:“Repeat的反向傳播是Sum”“ Sum的反向傳播是Repeat”。只要注意到張量的形狀,就不難知道應該對哪個軸進行Sum,對哪個軸進行Repeat。
現在我們將上圖的計算圖實現為層,這里稱之為Weight Sum層, 其實現如下所示
class WeightSum:def __init__(self):self.params, self.grads = [], []self.cache = Nonedef forward(self, hs, a):N, T, H = hs.shapear = a.reshape(N, T, 1).repeat(H, axis=2)t = hs * arc = np.sum(t, axis=1)self.cache = (hs, ar)return cdef backward(self, dc):hs, ar = self.cacheN, T, H = hs.shapedt = dc.reshape(N, 1, H).repeat(T, axis=1)dar = dt * hsdhs = dt * arda = np.sum(dar, axis=2)return dhs, da
以上就是計算上下文向量的Weight Sum層的實現。因為這個層沒有要學習的參數,所以根據代碼規范,此處為self.params = []。其他應該沒有特別難的地方,我們繼續往下看。
四.編碼器的改進2
有了表示各個單詞重要度的權重a,就可以通過加權和獲得上下文向量。那么,怎么求這個a呢?當然不需要我們手動指定,我們只需要做好讓 模型從數據中自動學習它的準備工作。 下面我們來看一下各個單詞的權重a的求解方法。首先,從編碼器的處理開始到解碼器第一個LSTM層輸出隱藏狀態向量的處理為止的流程如下圖所示
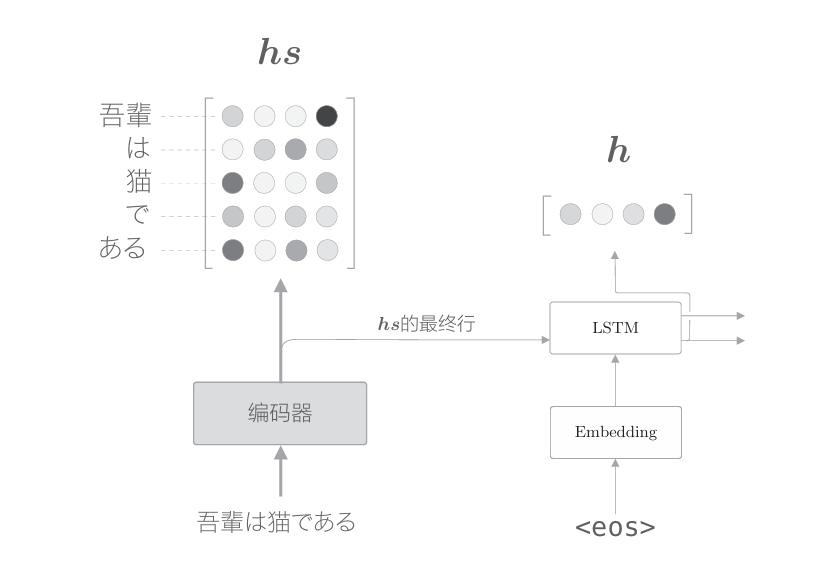
在上圖中,用h表示解碼器的LSTM層的隱藏狀態向量。此時,我們的目標是用數值表示這個h在多大程度上和hs的各個單詞向量“相似”。 有幾種方法可以做到這一點,這里我們使用最簡單的向量內積。順便說一下,向量a=(a1,a2,···,an)和向量b =(b1,b2,···,bn)的內積為:
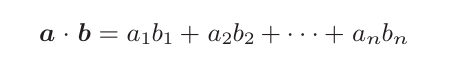
上式的含義是兩個向量在多大程度上指向同一方向,因此使用內積作為兩個向量的“相似度”是非常自然的選擇。
下面用圖表示基于內積計算向量間相似度的處理流程
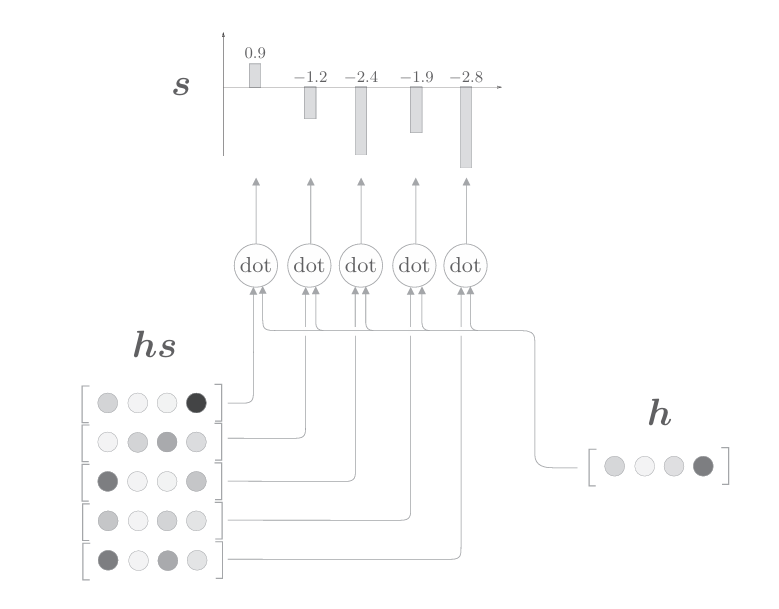
如上圖所示,這里通過向量內積算出h和hs的各個單詞向量之間的相似度,并將其結果表示為s。不過,這個s是正規化之前的值,也稱為得分。接下來,使用老一套的Softmax函數對s進行正規化(下圖)
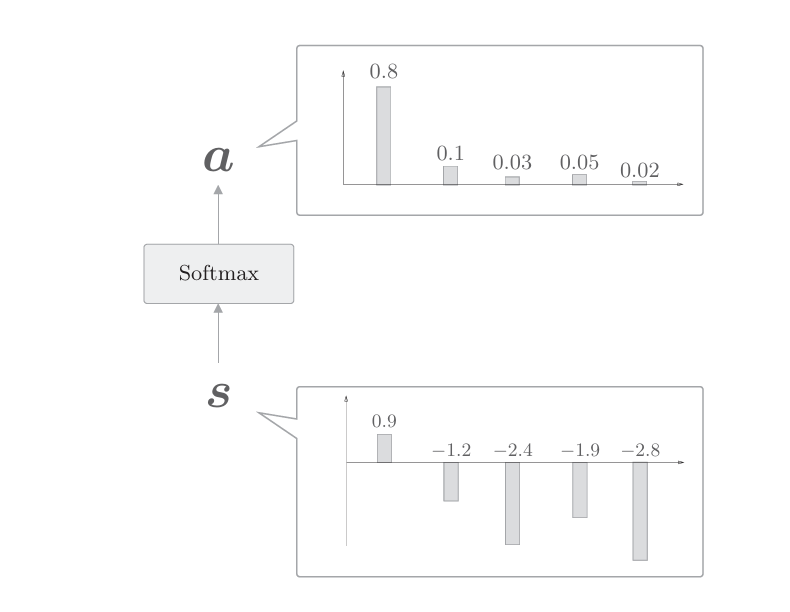
使用Softmax函數之后,輸出的a的各個元素的值在0.0~1.0,總和為1,這樣就求得了表示各個單詞權重的a。現在我們從代碼角度來看一下這些處理。
from common.layers import Softmax
import numpy as npN, T, H = 10, 5, 4
hs = np.random.randn(N, T, H)
h = np.random.randn(N, H)
hr = h.reshape(N, 1, H).repeat(T, axis=1)t = hs * hrprint(t.shape)
# (10, 5, 4)s = np.sum(t, axis=2)
print(s.shape)
# (10, 5)softmax = Softmax()
a = softmax.forward(s)
print(a.shape)
# (10, 5)以上就是進行批處理的代碼。如前所述,此處我們通過reshape()和 repeat() 方法生成形狀合適的hr。在使用NumPy的廣播的情況下,不需要 repeat()。此時的計算圖如下圖所示。
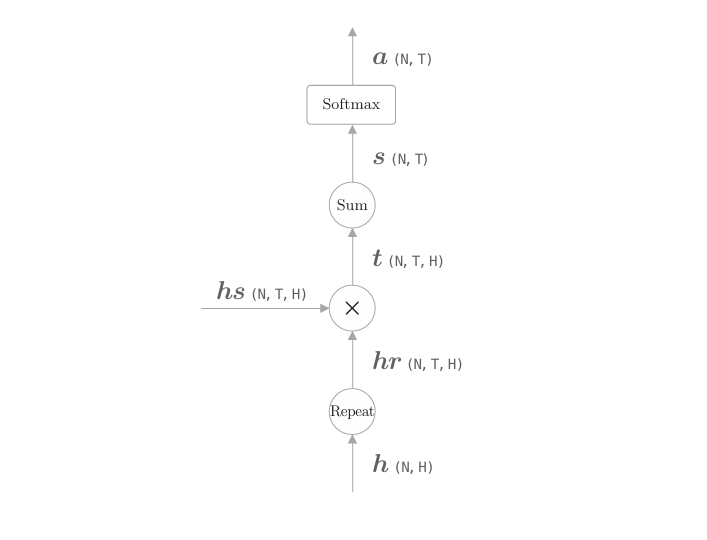
如上圖所示,這里的計算圖由Repeat節點、表示對應元素的乘積的 “×”節點、Sum節點和Softmax層構成。我們將這個計算圖表示的處理實現為AttentionWeight 類
class AttentionWeight:def __init__(self):self.params, self.grads = [], []self.softmax = Softmax()self.cache = Nonedef forward(self, hs, h):N, T, H = hs.shapehr = h.reshape(N, 1, H).repeat(T, axis=1)t = hs * hrs = np.sum(t, axis=2)a = self.softmax.forward(s)self.cache = (hs, hr)return adef backward(self, da):hs, hr = self.cacheN, T, H = hs.shapeds = self.softmax.backward(da)dt = ds.reshape(N, T, 1).repeat(H, axis=2)dhs = dt * hrdhr = dt * hsdh = np.sum(dhr, axis=1)return dhs, dh
類似于之前的Weight Sum層,這個實現有Repeat和Sum運算。只要注意到這兩個運算的反向傳播,其他應該就沒有特別難的地方。下面,我 們進行解碼器的最后一個改進。
五.編碼器的改進3
在此之前,我們分兩節介紹了解碼器的改進方案。上面分別實現了Weight Sum層和Attention Weight層。現在,我們將這兩層組合起來,結果如下圖所示。
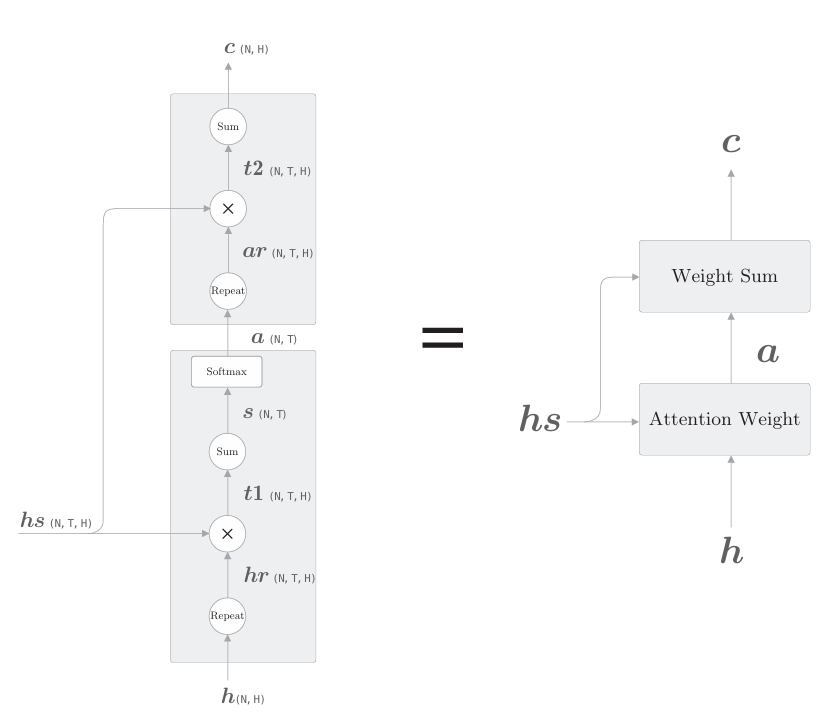
上圖顯示了用于獲取上下文向量c的計算圖的全貌。我們已經分為 Weight Sum 層和Attention Weight 層進行了實現。重申一下,這里進行的計算是:Attention Weight 層關注編碼器輸出的各個單詞向量hs,并計算各個單詞的權重a;然后,Weight Sum層計算a和hs的加權和,并輸出上下文向量c。我們將進行這一系列計算的層稱為Attention層(如下圖)
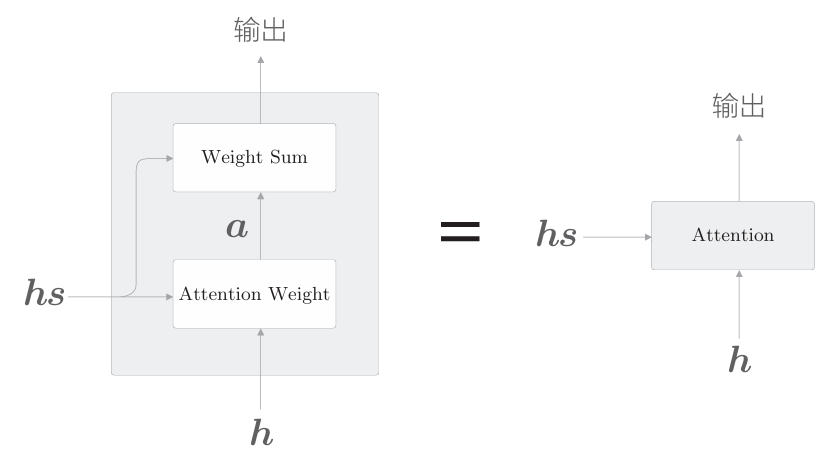
以上就是Attention技術的核心內容。關注編碼器傳遞的信息hs中的重要元素,基于它算出上下文向量,再傳遞給上一層(這里,Affine層在上 一層等待)。下面給出Attention層的實現
class Attention:def __init__(self):self.params, self.grads = [], []self.attention_weight_layer = AttentionWeight()self.weight_sum_layer = WeightSum()self.attention_weight = Nonedef forward(self, hs, h):a = self.attention_weight_layer.forward(hs, h)out = self.weight_sum_layer.forward(hs, a)self.attention_weight = areturn outdef backward(self, dout):dhs0, da = self.weight_sum_layer.backward(dout)dhs1, dh = self.attention_weight_layer.backward(da)dhs = dhs0 + dhs1return dhs, dh以上是Weight Sum層和Attention Weight層的正向傳播和反向傳播。 為了以后可以訪問各個單詞的權重,這里設定成員變量attention_weight, 如此就完成了Attention層的實現。我們將這個Attention層放在LSTM層 和Affine 層的中間,如下圖
如上圖所示,編碼器的輸出hs被輸入到各個時刻的Attention層。 另外,這里將LSTM層的隱藏狀態向量輸入Affine層。根據上一章的解碼器的改進,可以說這個擴展非常自然。如下圖所示,我們將Attention信息“添加”到了上一章的解碼器上。

如上圖所示,我們向上一章的解碼器“添加”基于Attention層的上下文向量信息。因此,除了將原先的LSTM層的隱藏狀態向量傳給 Affine 層之外,追加輸入Attention層的上下文向量。
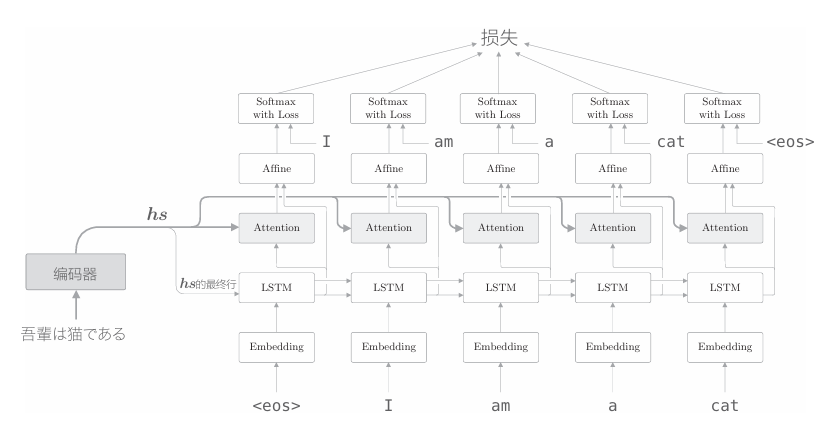
最后,我們將在上上個圖的時序方向上擴展的多個Attention層整體實現為Time Attention 層,如下圖所示。
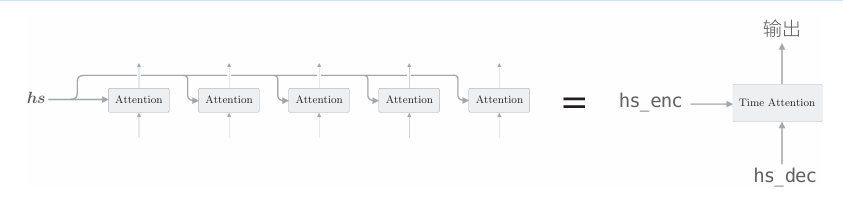
由上圖可知,Time Attention 層只是組合了多個Attention層,其實現如下所示
class TimeAttention:def __init__(self):self.params, self.grads = [], []self.layers = Noneself.attention_weights = Nonedef forward(self, hs_enc, hs_dec):N, T, H = hs_dec.shapeout = np.empty_like(hs_dec)self.layers = []self.attention_weights = []for t in range(T):layer = Attention()out[:, t, :] = layer.forward(hs_enc, hs_dec[:,t,:])self.layers.append(layer)self.attention_weights.append(layer.attention_weight)return outdef backward(self, dout):N, T, H = dout.shapedhs_enc = 0dhs_dec = np.empty_like(dout)for t in range(T):layer = self.layers[t]dhs, dh = layer.backward(dout[:, t, :])dhs_enc += dhsdhs_dec[:,t,:] = dhreturn dhs_enc, dhs_dec這里僅創建必要數量的Attention層(代碼中為T個),各自進行正向 傳播和反向傳播。另外,attention_weights列表中保存了各個Attention層 對各個單詞的權重。
以上,我們介紹了Attention的結構及其實現。下一節我們使用Attention來實現seq2seq,并嘗試挑戰一個真實問題,以確認Attention的效果。










服務器)








