原文鏈接:https://tecdat.cn/?p=41308
在數據科學的領域中,我們常常會遇到需要處理復雜關系的數據。在眾多的數據分析方法中,樣條擬合是一種非常有效的處理數據非線性關系的手段。本專題合集圍繞如何使用PyMC軟件,對櫻花花期數據進行樣條擬合分析展開了一系列深入的探討(點擊文末“閱讀原文”獲取完整代碼、數據、文檔)。
本專題合集涵蓋了從數據的獲取、清洗,到模型的構建、擬合,再到模型結果的分析和新數據預測等多個關鍵環節。數據方面,我們使用了記錄每年櫻花樹開花天數(“一年中的天數”即doy)和年份(year)的櫻花花期數據。在數據處理時,為了方便,我們剔除了缺失開花天數數據的年份(但一般來說,這并不是處理缺失數據的好方法)。
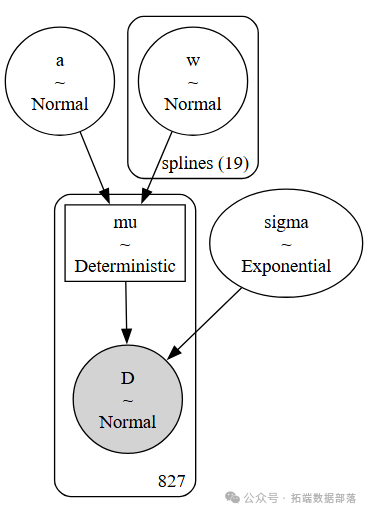
在模型構建部分,我們構建了一個基于正態分布的模型來描述櫻花花期天數的變化。模型中,開花天數D被建模為均值為μ、標準差為σ的正態分布,而均值μ又是由截距a和由基函數B與模型參數w的乘積組成的線性模型。
在模型擬合完成后,我們對模型的后驗抽樣結果進行了詳細分析,包括參數估計、模型預測等方面。最后,我們還探討了如何使用該模型對新數據進行預測,盡管樣條擬合方法在處理超出原始數據范圍的數據時存在一定的局限性。
本文代碼數據已分享在交流社群,閱讀原文進群和500+行業人士共同交流和成長。希望本專題合集的內容能夠為數據科學領域的從業者和愛好者提供有價值的參考,幫助大家更好地理解和應用樣條擬合方法,解決實際數據分析中的問題。
數據準備
AI提示詞:使用Python語言,通過pandas庫讀取存儲櫻花花期數據的CSV文件,若文件不存在則從指定位置讀取,然后對數據進行缺失值處理并查看數據基本描述信息
from?pathlb iport?Path
import?padas?as?pd
trycherry\_blossom\_ata = pd.read_csv(Pth(".",?"data"cm.csv"), sep=";")經過缺失值處理后,數據集中包含了827個年份的櫻花開花天數信息。從數據的可視化散點圖中可以看出,雖然每年的開花天數存在很大的變化,但隨著時間的推移,開花天數呈現出一定的非線性趨勢。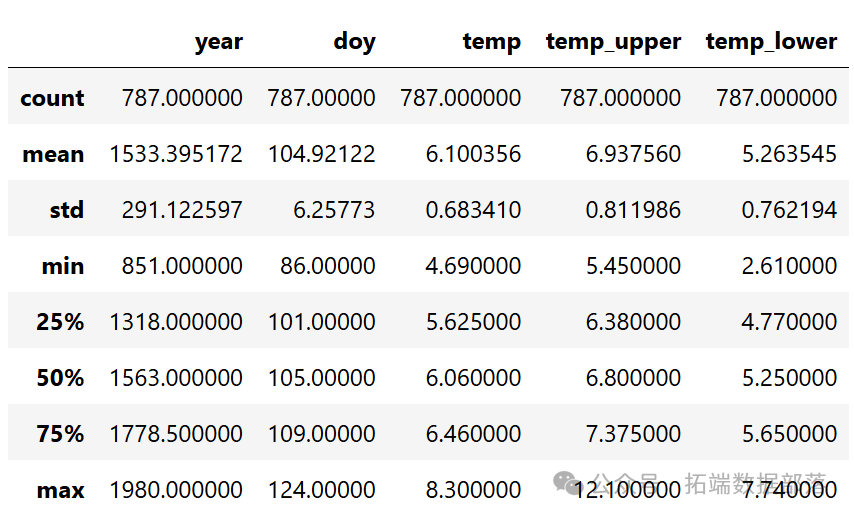
print(cherry\_blossom\_data.head(n=10))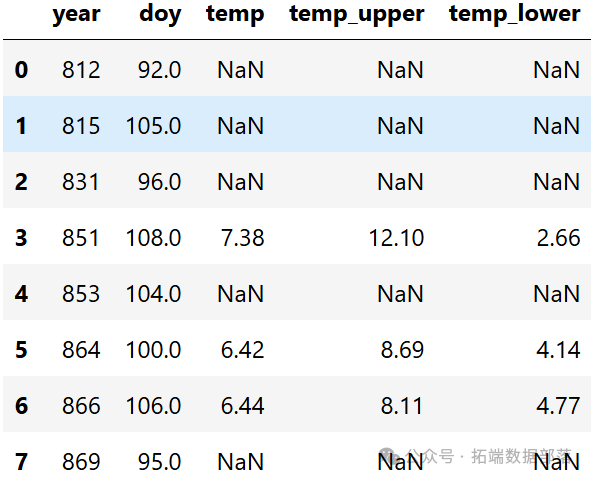
模型構建
AI提示詞:使用PyMC庫構建一個基于正態分布的模型,定義模型的參數,包括截距a、參數w、標準差sigma等,并確定它們的先驗分布
COORDS = {"splines": np.arange(B.shape\[1\])}
with?pm.Model在這個模型中,我們使用了15個節點將年份數據分成了16個部分,并使用patsy庫創建了三次樣條基矩陣B。
B = dmatrix(下面是樣條基的繪圖,顯示了樣條每一段的“域”。每條曲線的高度表示相應的模型協變量(每個樣條區域一個)對該區域模型推斷的影響程度。重疊區域表示節點,顯示了從一個區域到下一個區域的平滑過渡是如何形成的。
color = plt.cm.magma(np.linspace(0,?0.80,?len(spline\_df.spline\_i.unique())))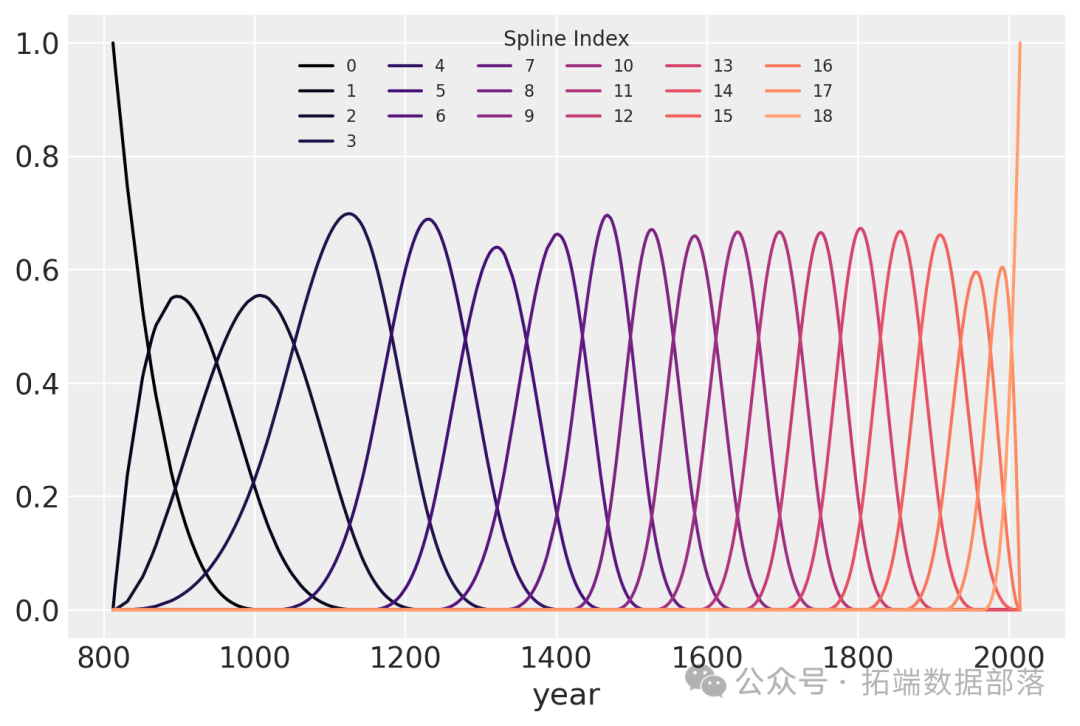
點擊標題查閱往期內容

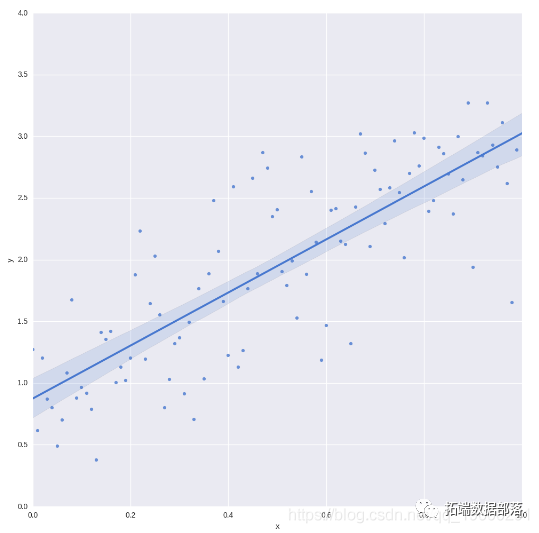
Python用PyMC3實現貝葉斯線性回歸模型

左右滑動查看更多
01
02
03
04

模型擬合
AI提示詞:使用PyMC庫對構建好的模型進行抽樣,獲取先驗預測值、后驗預測值,設置抽樣的相關參數如抽樣次數、調優次數、鏈的數量等
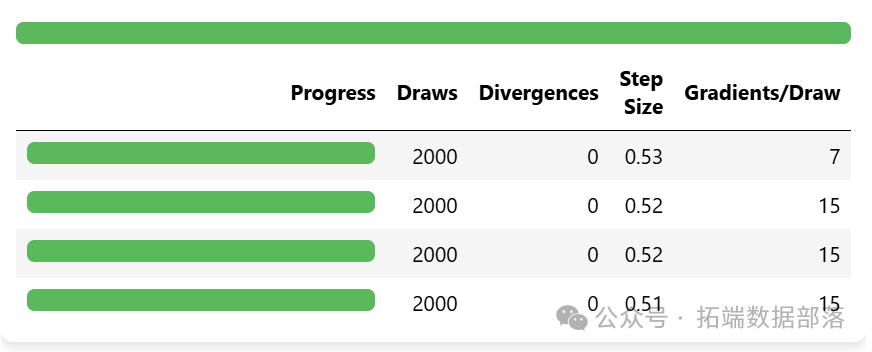
idata = pm.sample\_prior\_predictive()通過模型擬合,我們可以得到模型參數的后驗分布,并對模型的收斂性進行檢查。
print("Sampling: \[D\]")模型分析
AI提示詞:使用arviz庫對模型后驗抽樣結果idata進行分析,計算模型參數a、w、sigma的摘要信息,包括均值、標準差、有效樣本大小等
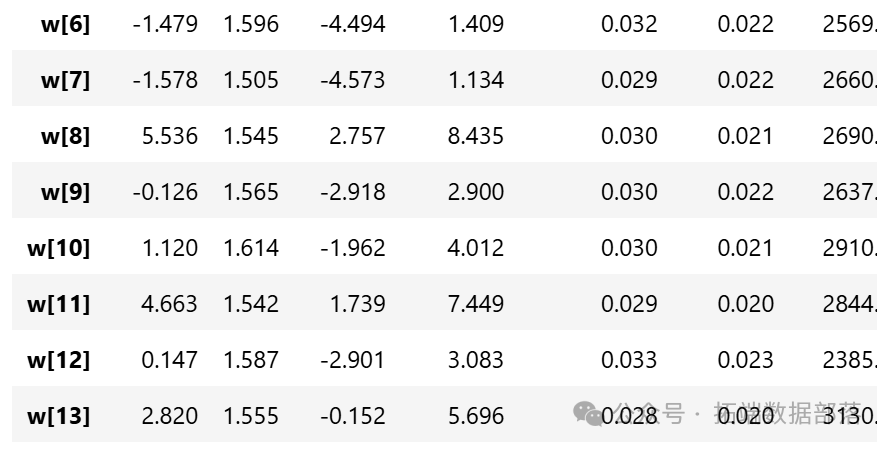
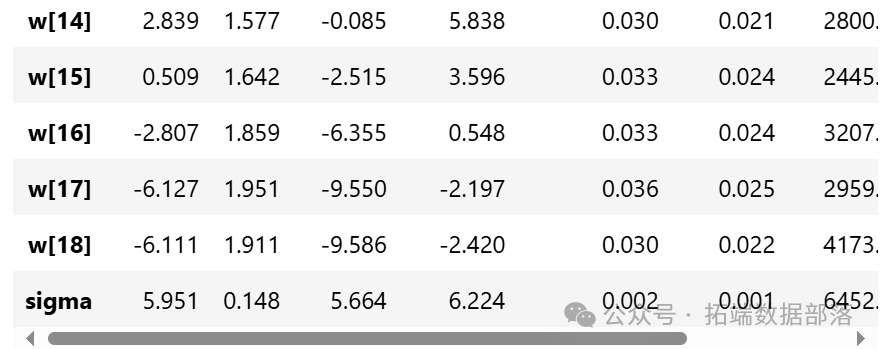
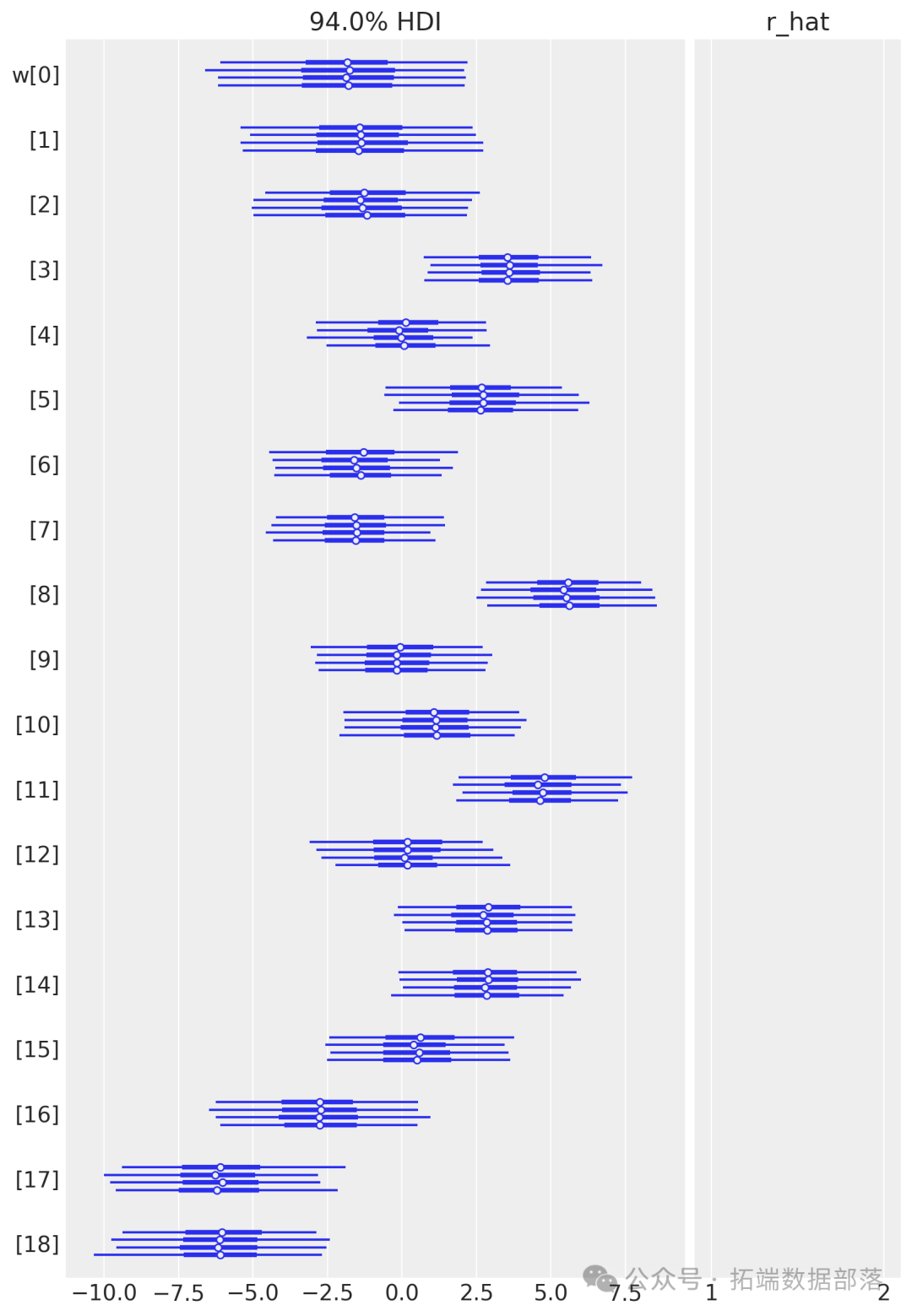
從參數估計的結果來看,截距a和標準差σ的后驗分布比較窄,而參數w的后驗分布較寬。這可能是因為估計a和σ時使用了所有的數據點,而估計每個w值時只使用了部分數據。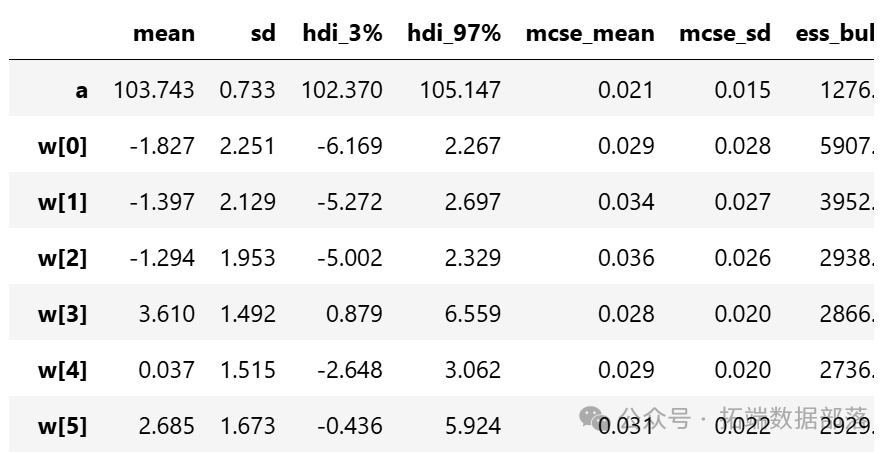
AI提示詞:使用arviz庫繪制模型參數a、w、sigma的跡圖,觀察參數的收斂情況和分布特征
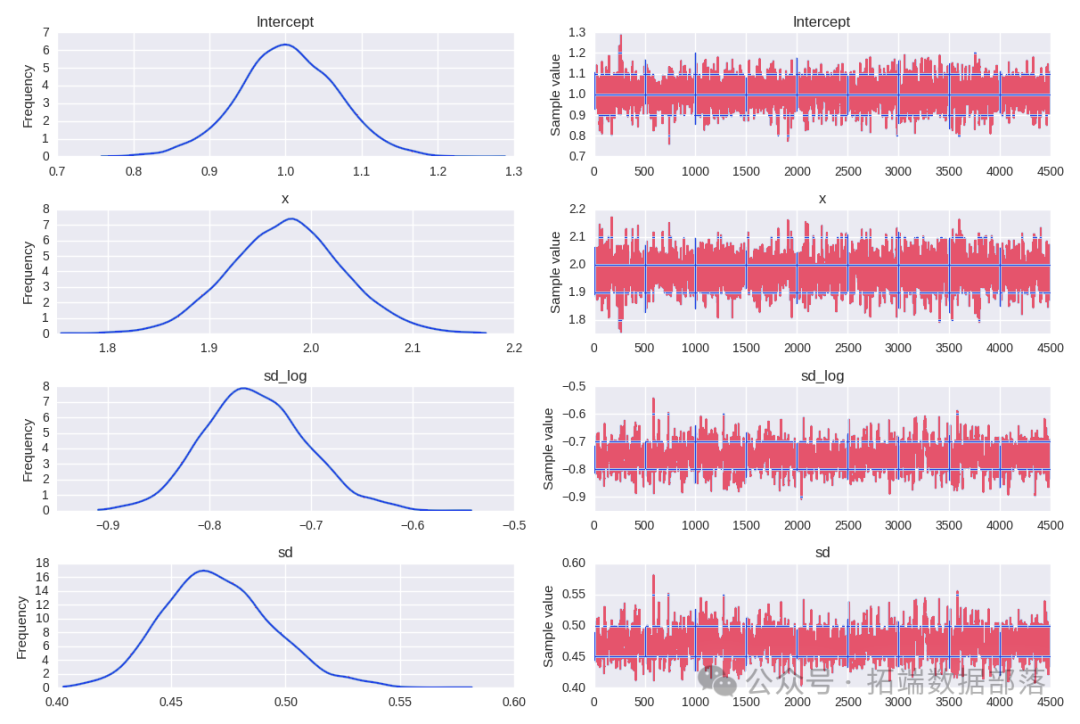
az.plot\_trace(idata,?var\_names=\["a",?"w",?"sigma"\]);跡圖顯示模型的鏈已經收斂,并且沒有明顯的趨勢,進一步表明模型已經很好地從后驗分布中抽樣。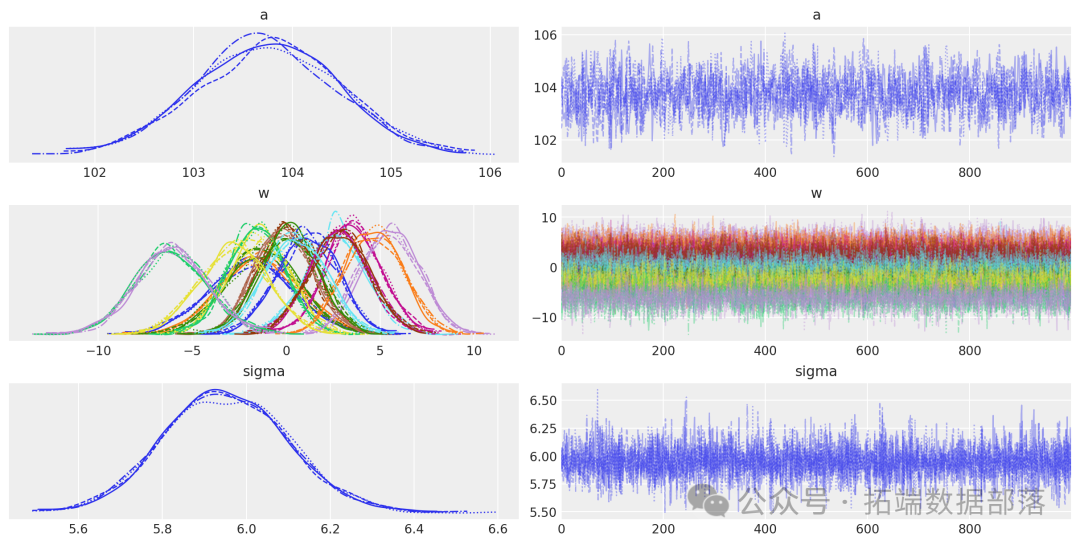
另一種可視化擬合樣條值的方法是繪制它們與基矩陣的乘積。節點邊界再次顯示為垂直線,但現在樣條基與w的值相乘(表示為彩虹色曲線)。B和w的點積——線性模型中的實際計算——以黑色顯示。
pd.DataFrame(B?* wp.T)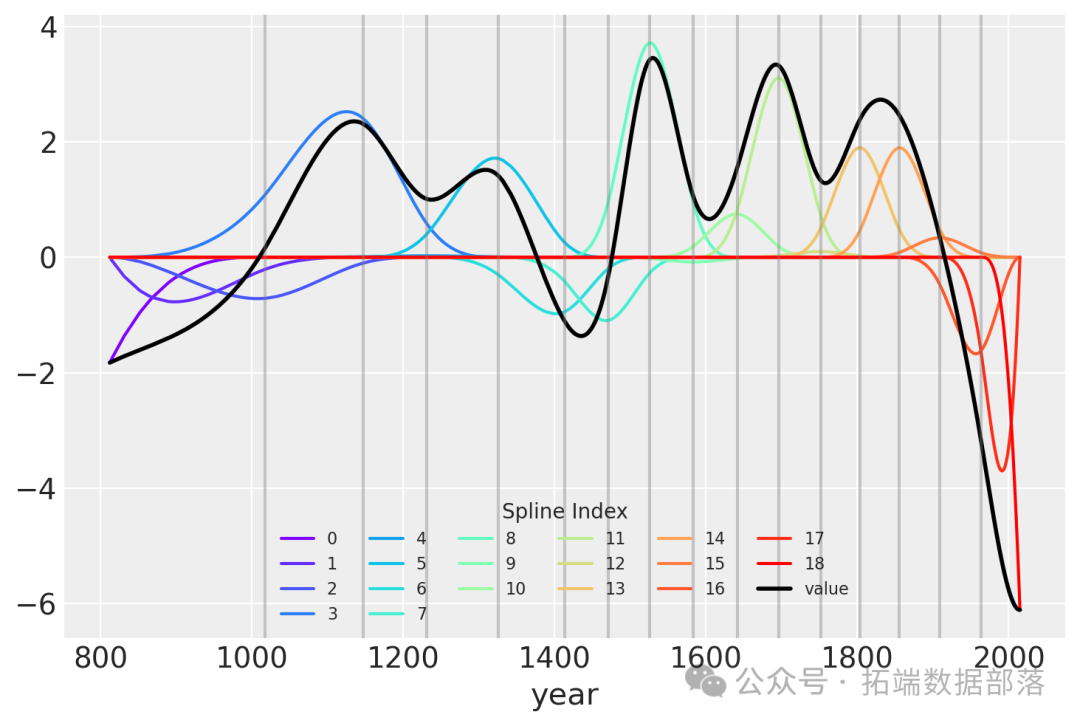
模型預測
AI提示詞:根據模型后驗抽樣結果idata,計算模型預測值的均值、最高密度區間(HDI)的下限和上限,并將預測值添加到原始數據中
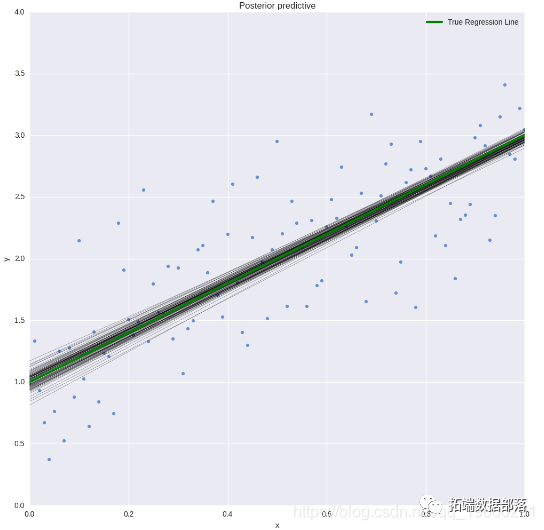
post\_pred?=?az.summary(idata, var\_names=\["mu"\]).reset_index(drop=True)通過可視化模型預測結果,我們可以看到模型在原始數據上的擬合效果。
for knot in knot_list:?
plt.gca().axvline(knot, color="grey", alpha=0.4)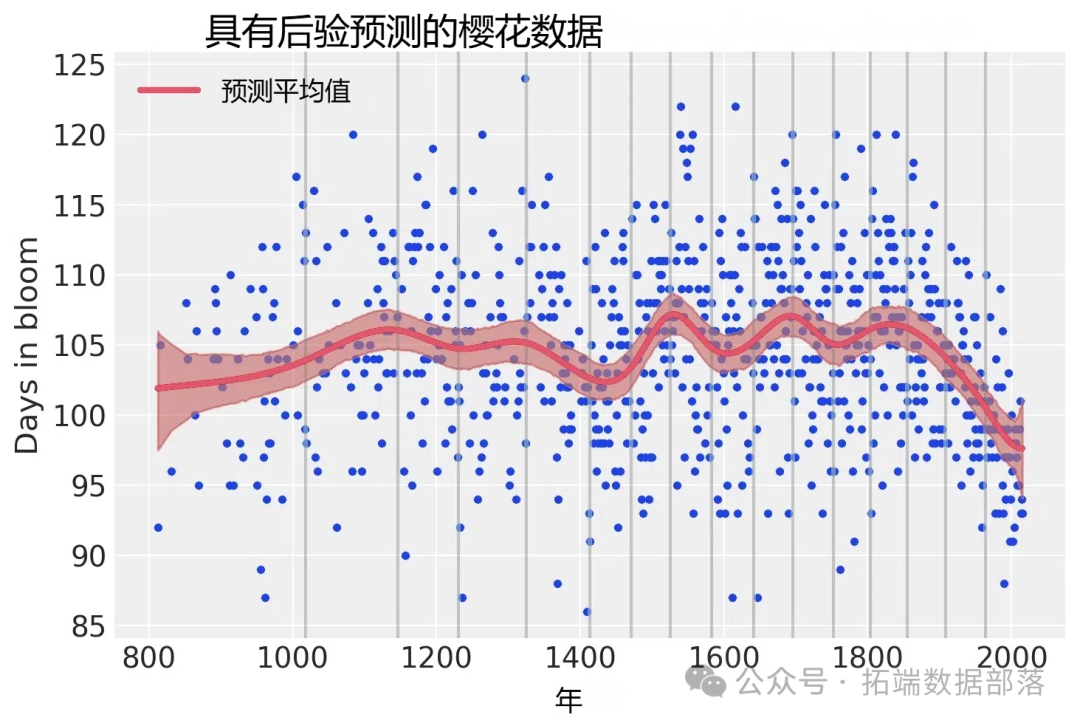
新數據預測
AI提示詞:使用PyMC庫重新定義模型,添加Data容器,將原始數據中的年份和開花天數作為Data變量,設置模型的坐標信息,構建樣條基矩陣等
year\_data?=?pm.Data("year", cherry\_blossom_data.year)w?=?pm.Normal("w", mu=0, sigma=3, dims="spline")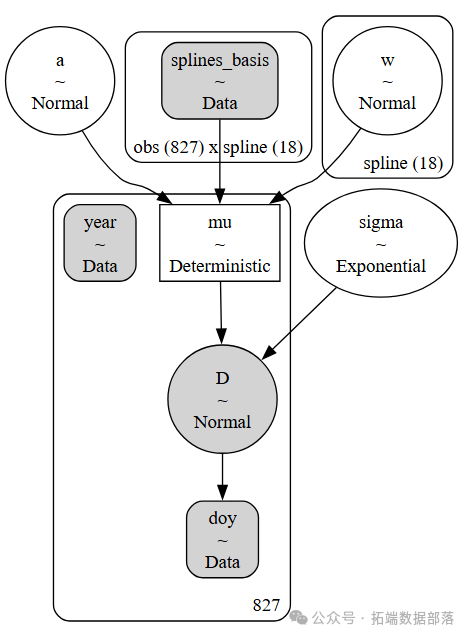
idata = pm.sample(nuts_sampler="nutpie",
現在我們可以替換數據并使用新數據更新設計矩陣:
cherry\_blossom\_data.sample(50,使用set_data更新模型中的數據:
new_data={"year": year\_data\_new,而剩下的就是從后驗預測分布中進行抽樣:
pm.sample\_posterior\_predictive(idata, var_names=\["mu"\])繪制預測結果,以檢查是否一切正常:
cherry\_blossom\_data.plot.scatter("year","doy",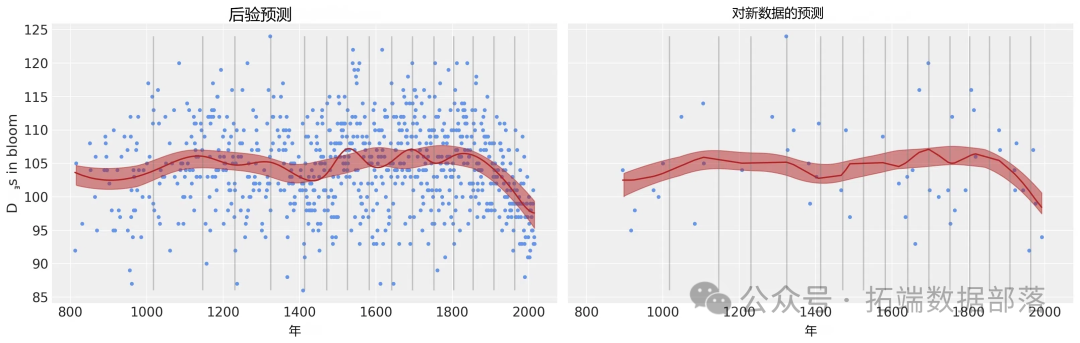
結論
通過本專題合集的研究,我們詳細地展示了如何使用PyMC軟件對櫻花花期數據進行樣條擬合分析。從數據的獲取和處理,到模型的構建、擬合、分析以及新數據預測,每個環節都進行了深入的探討。
在數據準備階段,我們對原始的櫻花花期數據進行了清洗,剔除了缺失值,為后續的分析奠定了基礎。模型構建時,基于正態分布建立了合理的模型結構,引入了樣條擬合的方法來捕捉數據中的非線性關系。通過精心設置模型參數的先驗分布,使得模型更加合理可靠。
在模型擬合過程中,利用PyMC強大的抽樣功能,獲取了模型參數的后驗分布。通過對后驗分布的分析,我們發現模型參數的估計結果符合預期,并且模型的收斂性良好,鏈已經充分混合,這表明我們的模型能夠較好地擬合數據。
在模型分析方面,通過對參數估計的詳細解讀,我們了解了每個參數在模型中的作用和影響。同時,通過繪制各種可視化圖形,如跡圖、森林圖等,直觀地展示了模型的性能和參數的分布情況。模型預測部分,我們不僅對原始數據進行了預測,還展示了如何使用模型對新數據進行預測,盡管樣條擬合方法存在不能外推到原始數據范圍之外的局限性,但在已知數據范圍內,模型能夠給出較為準確的預測結果。
本專題合集的研究成果對于理解和應用樣條擬合方法具有重要的參考價值,希望能夠為相關領域的研究和實踐提供有益的指導,幫助數據科學領域的從業者和愛好者更好地應用數據分析方法解決實際問題,同時也為進一步探索和改進數據分析方法提供了思路。

本文中分析的完整數據、代碼、文檔分享到會員群,掃描下面二維碼即可加群!?

資料獲取
在公眾號后臺回復“領資料”,可免費獲取數據分析、機器學習、深度學習等學習資料。

點擊文末“閱讀原文”
獲取完整代碼、數據、文檔。
本文選自《Python+AI提示詞用貝葉斯樣條回歸擬合BSF方法分析櫻花花期數據模型構建跡圖、森林圖可視化》。
點擊標題查閱往期內容
R語言用WinBUGS 軟件對學術能力測驗建立層次(分層)貝葉斯模型
R語言Gibbs抽樣的貝葉斯簡單線性回歸仿真分析
R語言和STAN,JAGS:用RSTAN,RJAG建立貝葉斯多元線性回歸預測選舉數據
R語言基于copula的貝葉斯分層混合模型的診斷準確性研究
R語言貝葉斯線性回歸和多元線性回歸構建工資預測模型
R語言貝葉斯推斷與MCMC:實現Metropolis-Hastings 采樣算法示例
R語言stan進行基于貝葉斯推斷的回歸模型
R語言中RStan貝葉斯層次模型分析示例
R語言隨機搜索變量選擇SSVS估計貝葉斯向量自回歸(BVAR)模型
R語言使用Metropolis-Hastings采樣算法自適應貝葉斯估計與可視化
WinBUGS對多元隨機波動率模型:貝葉斯估計與模型比較
視頻:R語言中的Stan概率編程MCMC采樣的貝葉斯模型
R語言RStan貝葉斯示例:重復試驗模型和種群競爭模型Lotka Volterra
R語言MCMC:Metropolis-Hastings采樣用于回歸的貝葉斯估計



![]()








基礎學習與實例:預測序列的未來)







)


——帶哨兵位循環雙向鏈表)
