KMP算法是計算機科學中的一種字符串匹配算法,KMP是三個創始人名字首字母

題目
AcWing - 算法基礎課
前置知識點
KMP算法是一種高效的字符串匹配算法,算法名稱取自于三位共同發明人名字的首字母組合。該算法的主要使用場景就是在字符串(也叫主串)中的模式串(也叫子串)定位問題,常見的有“求子串出現的起始位置”、“求子串的出現次數”等。
前綴和后綴
假設一個字符串“ababa"
他的前綴就是a,ab,aba,abab (ababa,ababa,ababa,ababa)
他的后綴就是a,ba,aba,baba (ababa,ababa,ababa,ababa)
前綴和后綴的最大長度,是原字符串長度-1
思路
最淺顯易懂的 KMP 算法講解_嗶哩嗶哩_bilibili
F03【模板】KMP 算法——信息學競賽算法_嗶哩嗶哩_bilibili
給定一個主串S,模式串P,求P在S中出現的位置
普通暴力枚舉
一個字符一個字符的雙指針枚舉,一旦發現不同
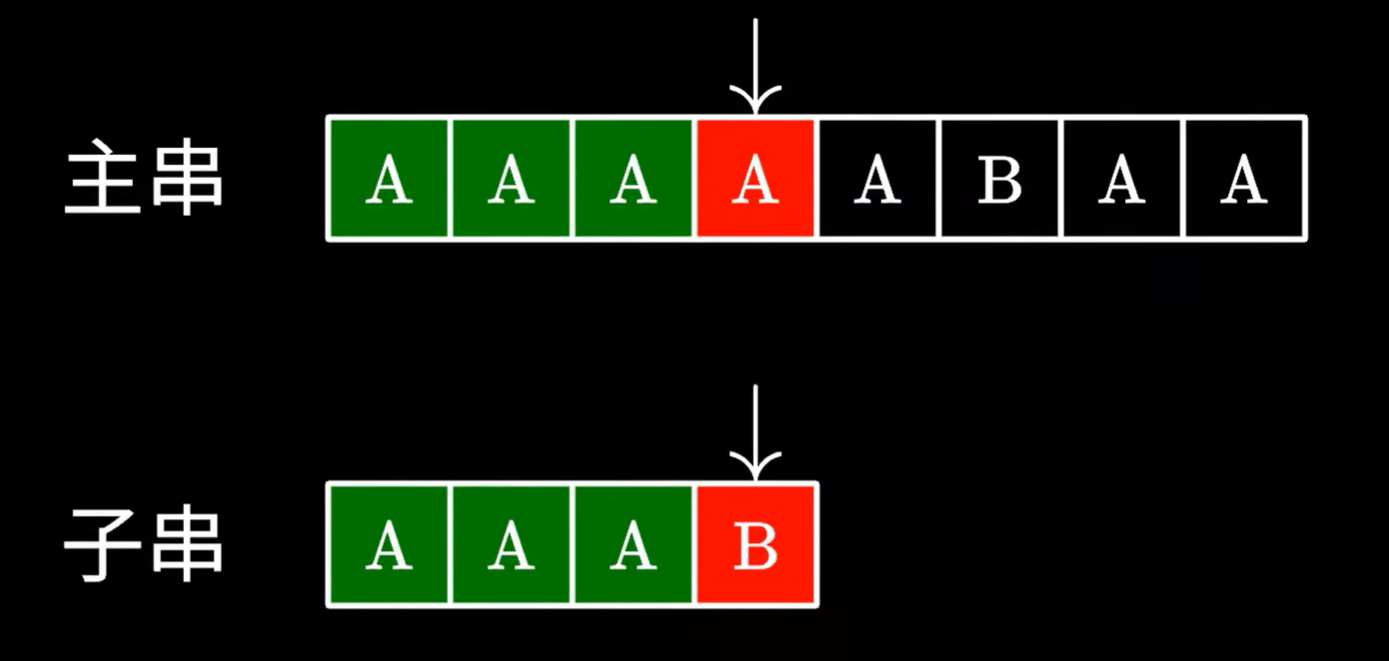
主串又要從第二個開始匹配,子串要從頭開始匹配

缺點:時間復雜度太高
kmp優化思路
在比對失敗時,我們已經知道曾經讀過哪些字符了
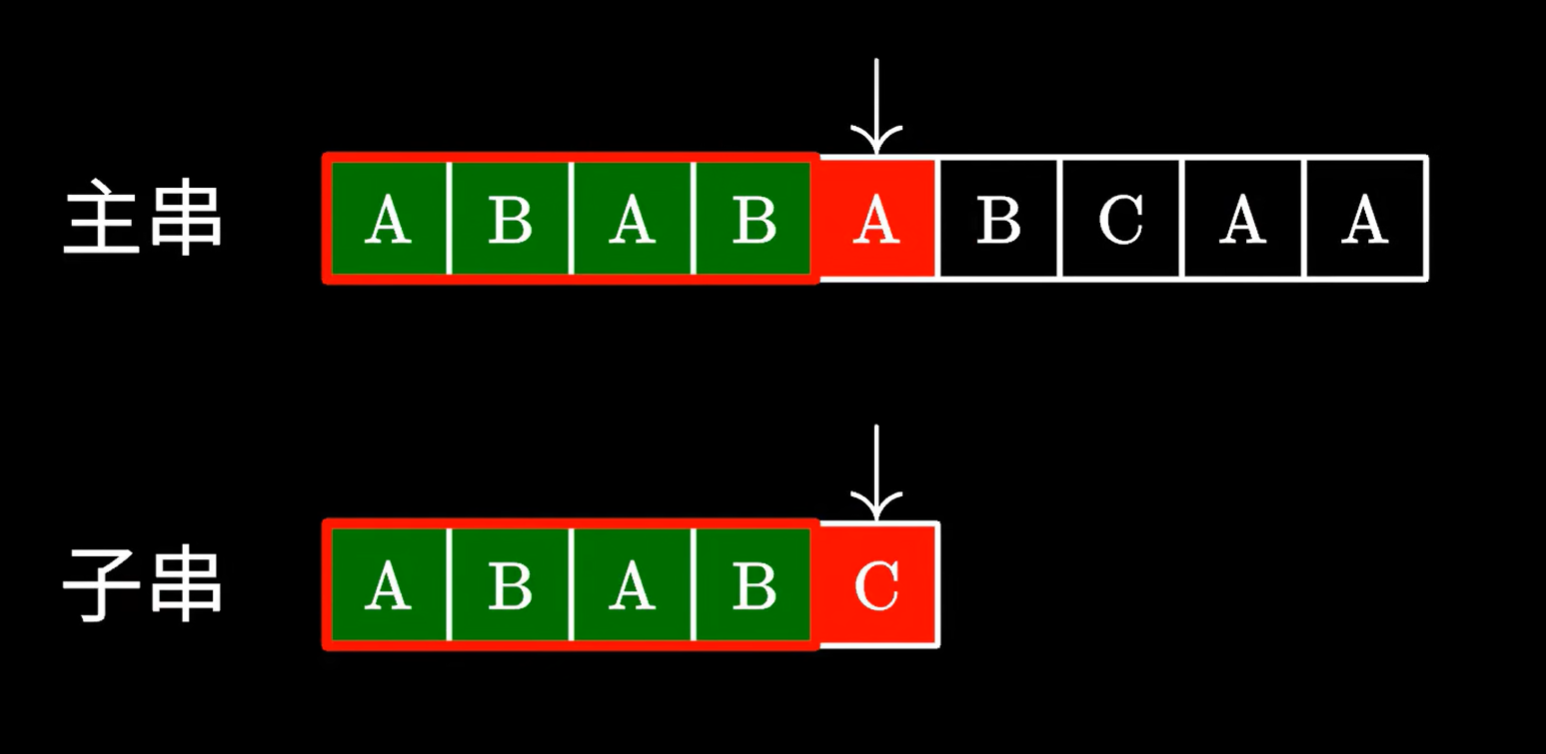
已經匹配的子串,有相同的后綴, 前綴,那我們是不是可以保留相同的前綴,再去查找不同的剩下的字符串
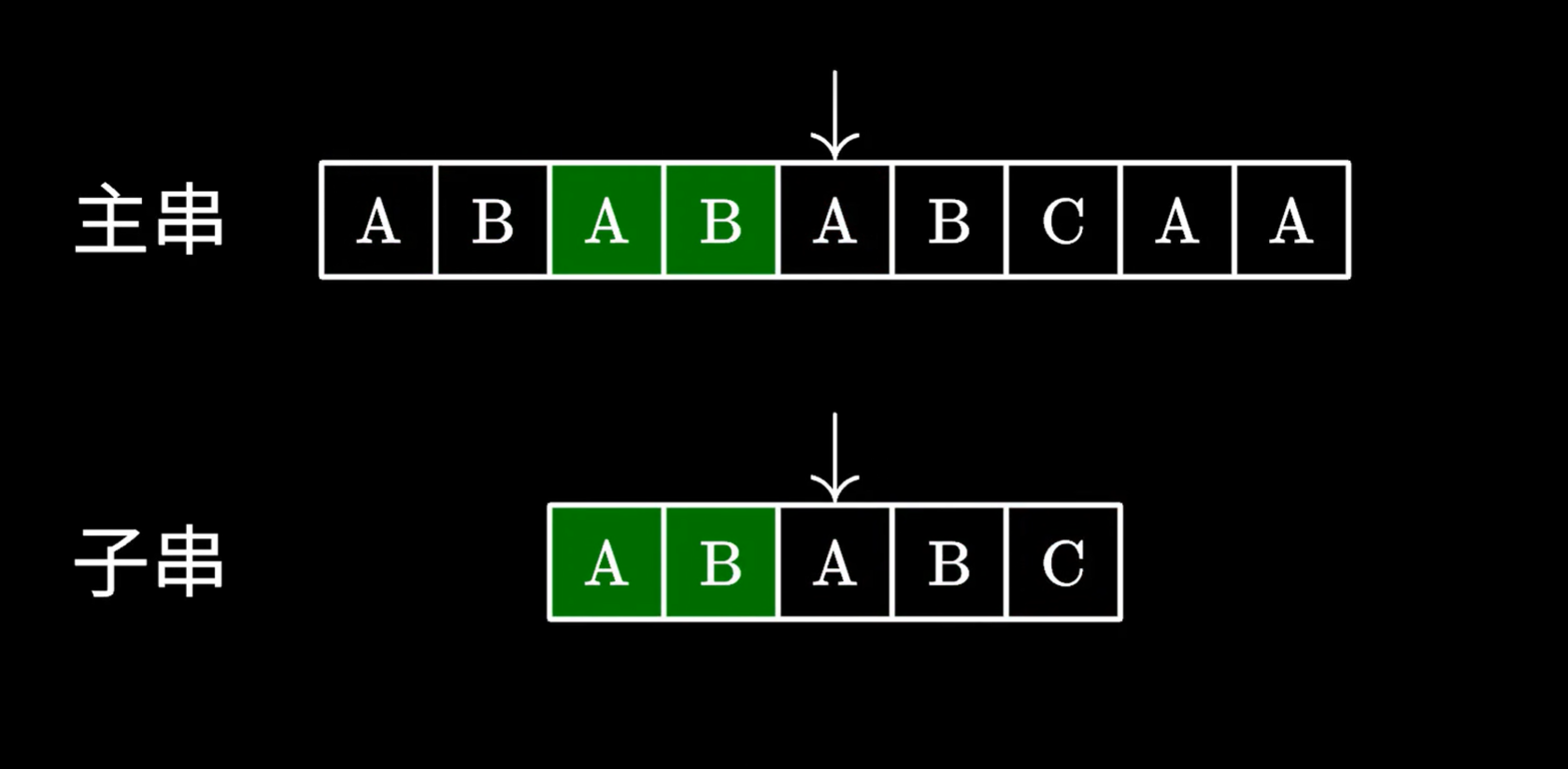
如下圖,主串保留的綠色,實際上是匹配的子串的后綴,子串里保留的綠色部分,就是匹配的子串的前綴
他們是相同的,則可以把主串里匹配的子串的后綴,視為子串前綴,繼續在主串查找相同前綴后面的字符串
next數組使用
我們已經知道kmp的優化思路,那么如何將知道,該保留的前綴呢?再暴力雙指針循環太麻煩
kmp三個人提出了next數組,我們先不看如何實現,先看如何使用,next數組功能
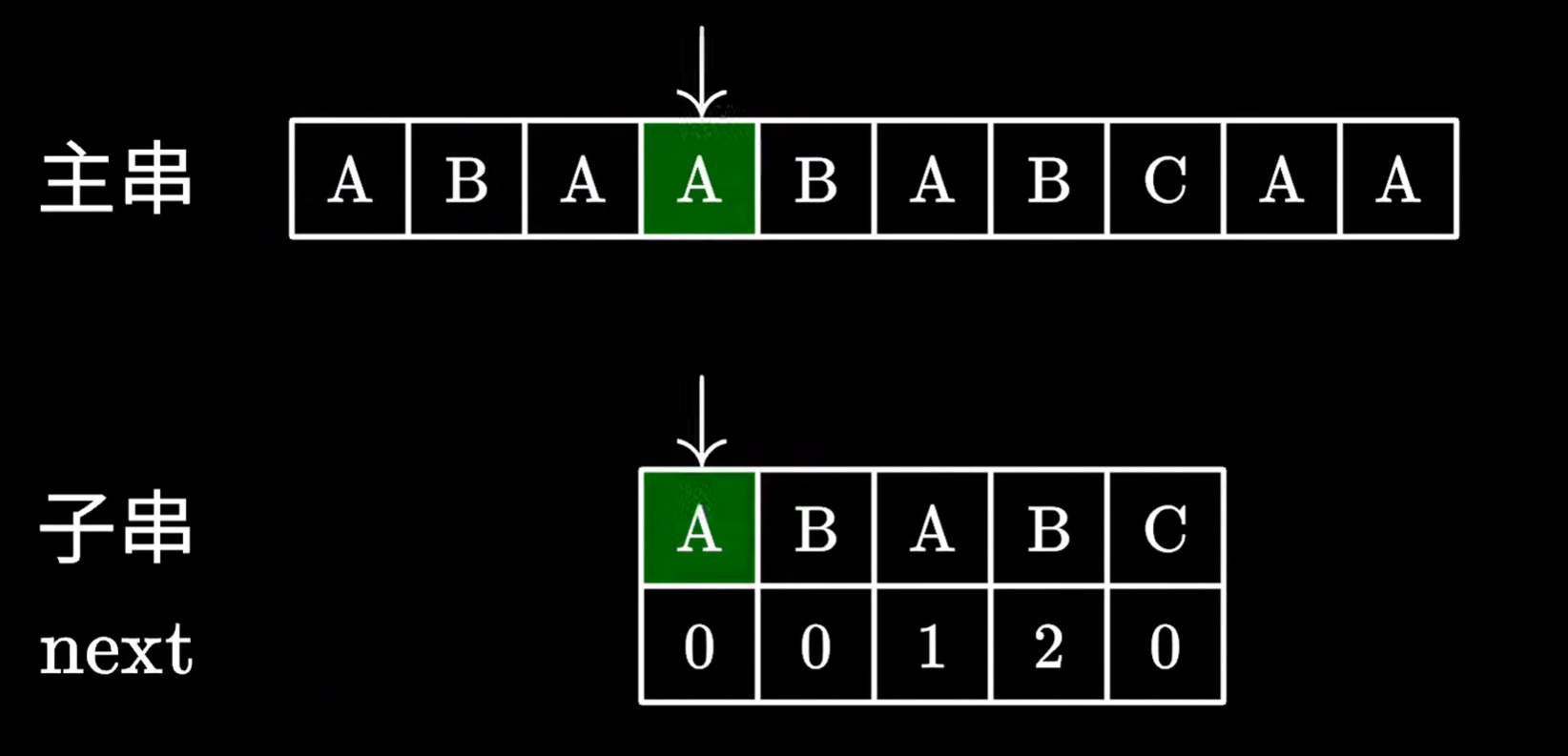
下圖是一個初始狀態
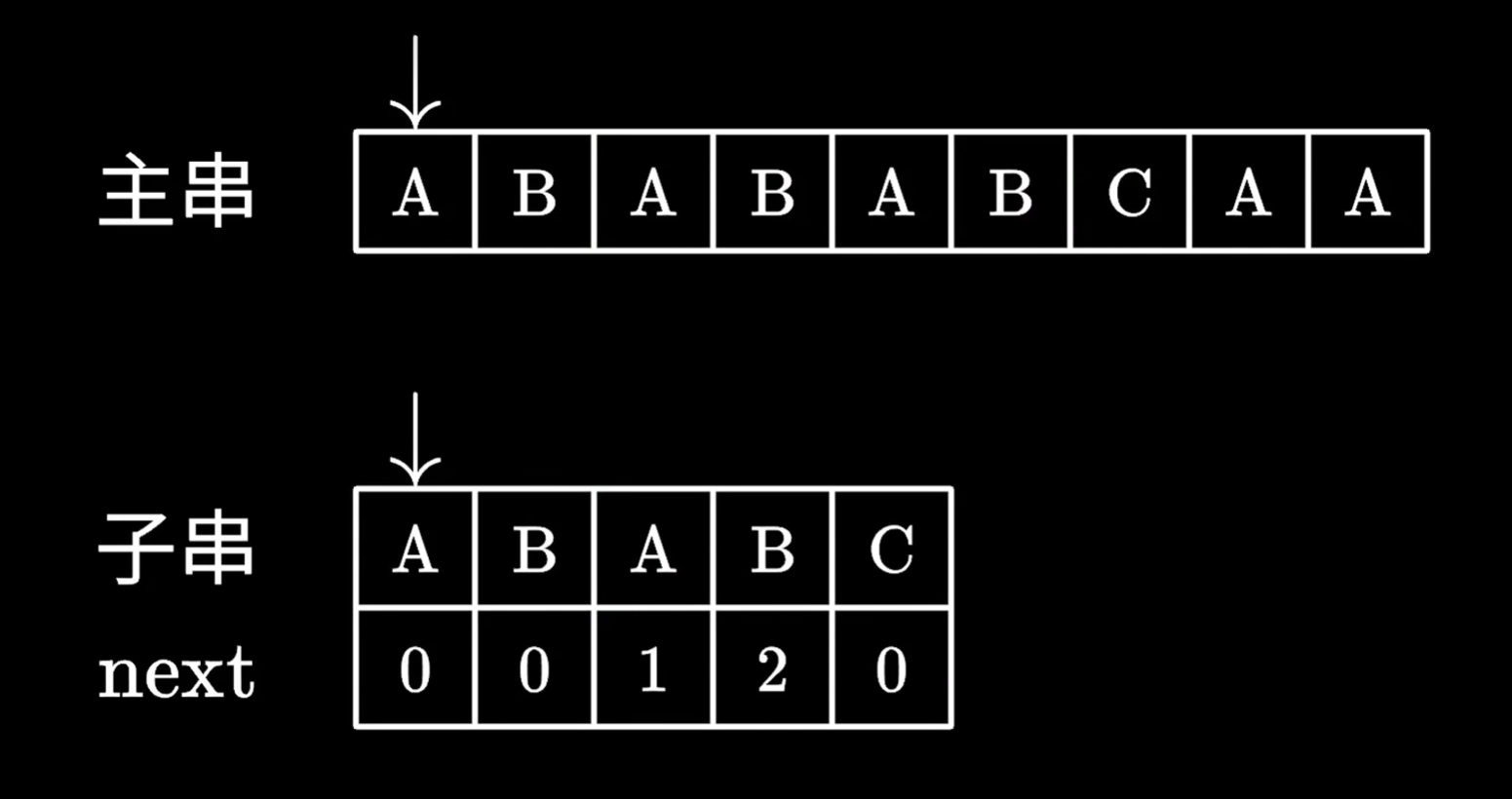
kmp算法匹配失敗時,去看最后一個匹配成功的子串的字符,對應的next數組里的值

查到對應的值后,我們移動子串,跳過next數組里的值對應的字符個數,例如值是2,我們就跳過前兩個字符
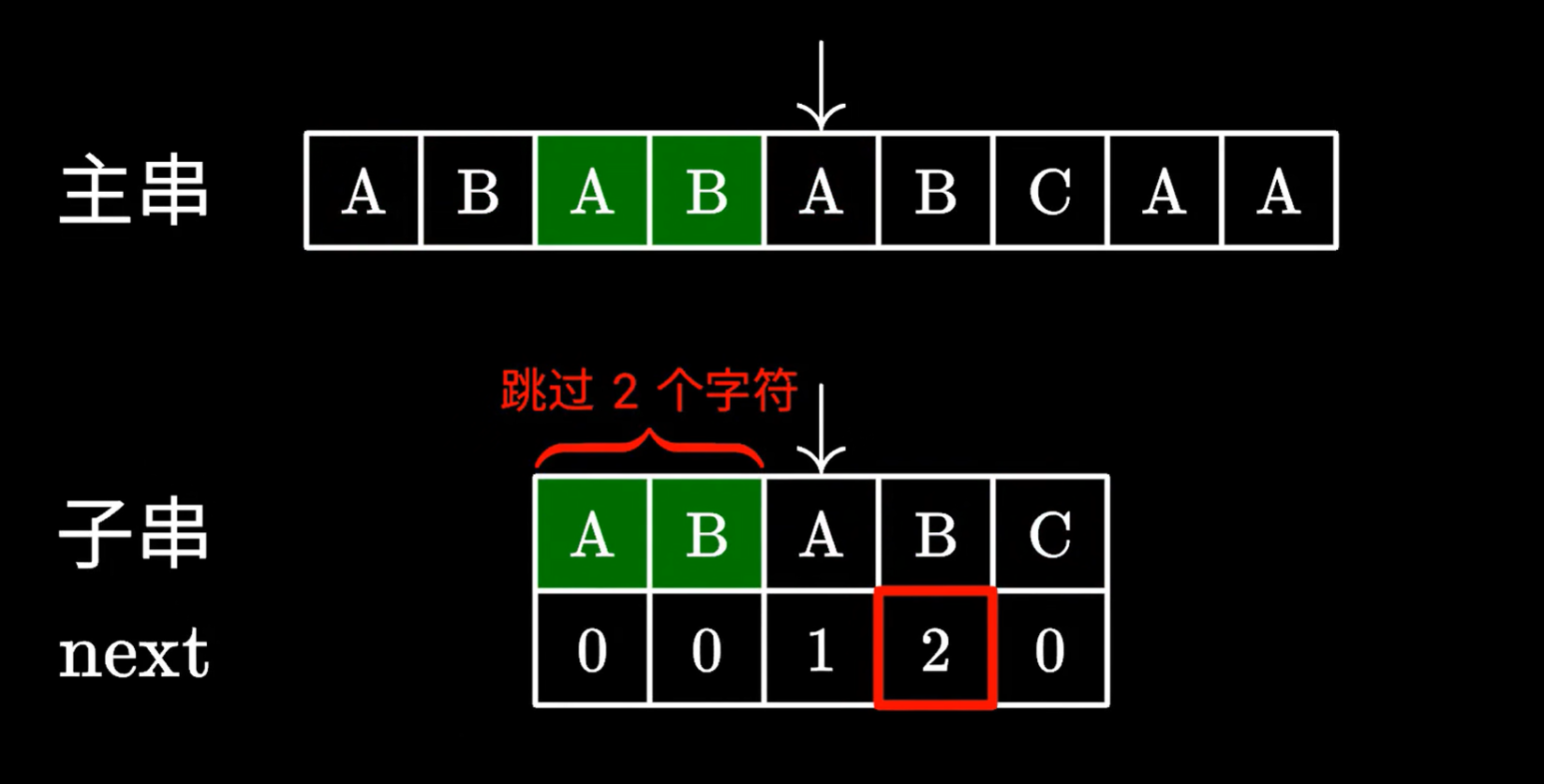
我們發現,跳過的這兩個字符,確實能和主串指針指向位置前的兩個字符對應
所以繼續枚舉即可,不需要從頭枚舉
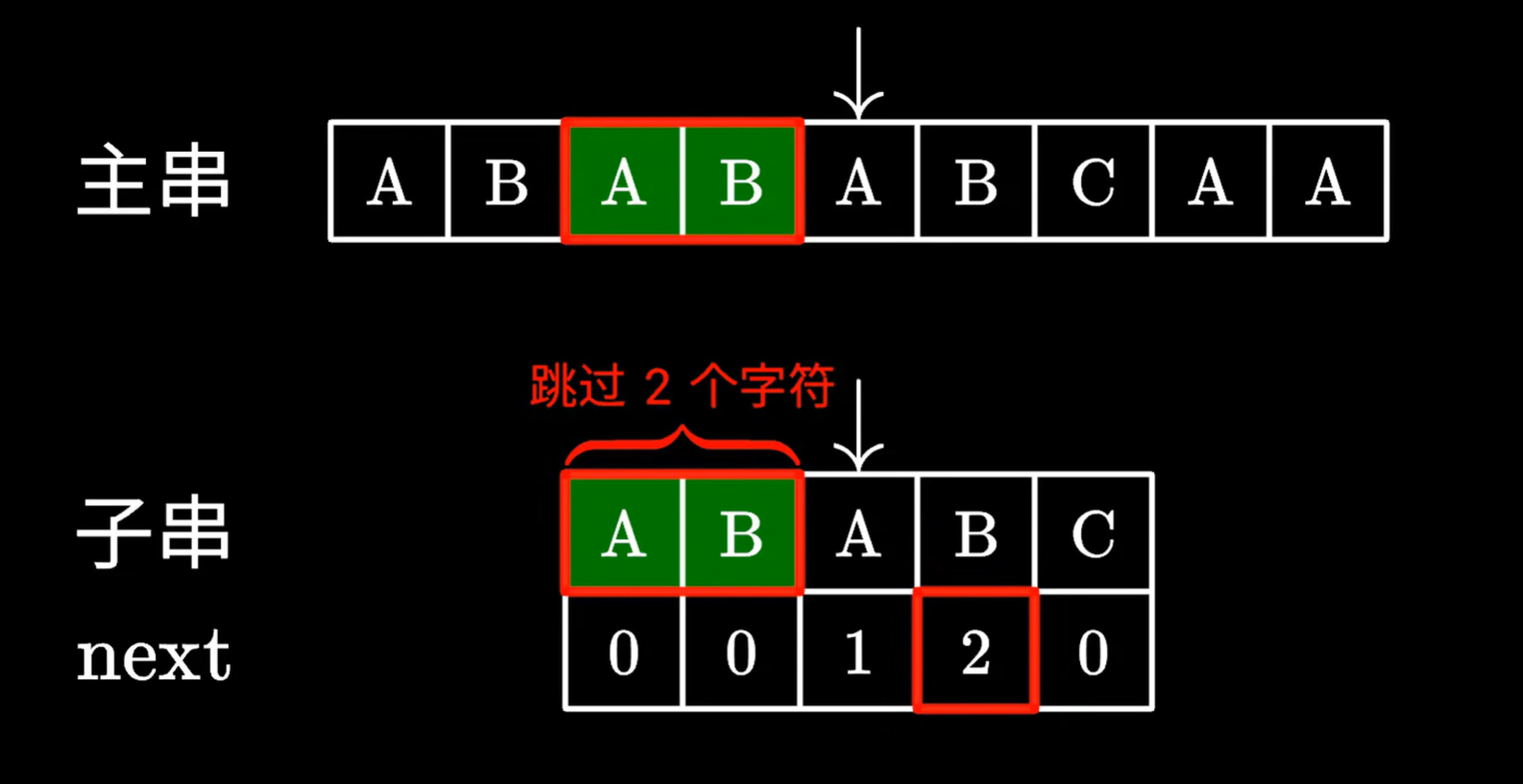
這樣,我們永遠不需要回退主串指針,一次遍歷主串,就可以找到匹配子串
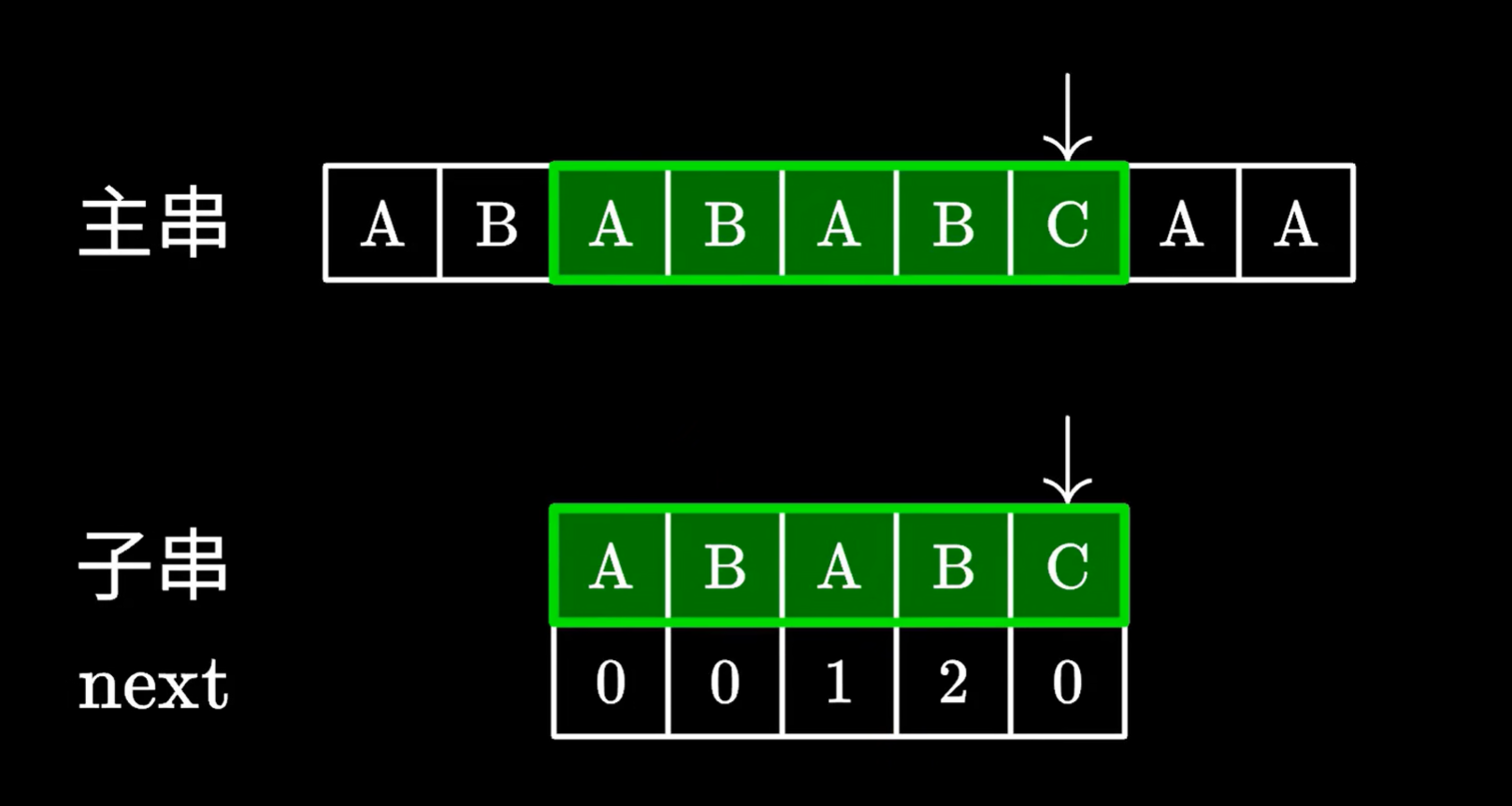
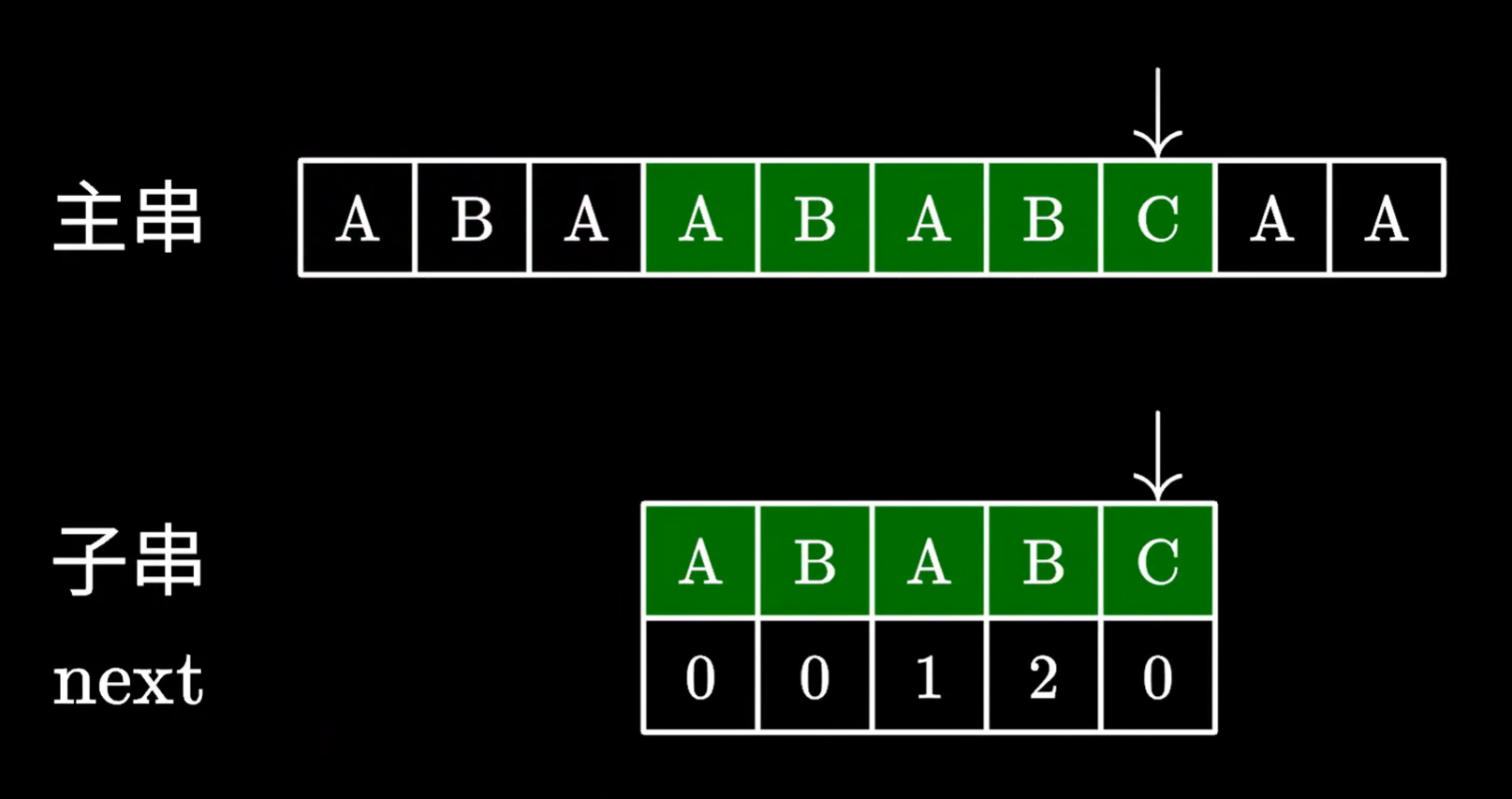
再看一下 ,如果子串對應next是0時
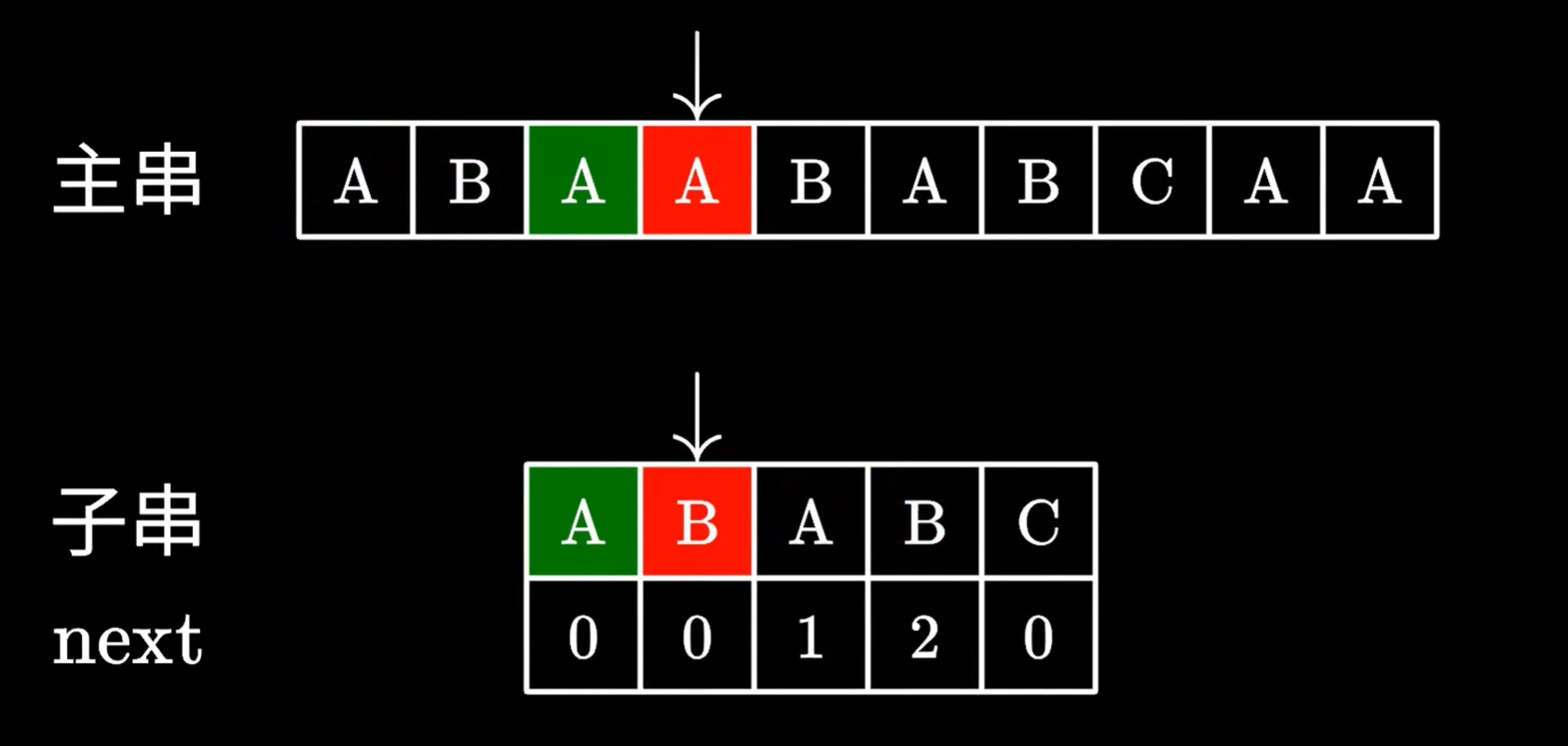
如果為0,也是從頭開始匹配子串,沒有相同的前綴和后綴,則子串一定不在已經遍歷過的主串里有
則已經遍歷過的主串里的字符,一定沒有子串的子串,所以主串之前的部分可以直接舍棄,不用移動主串指針
推導next數組
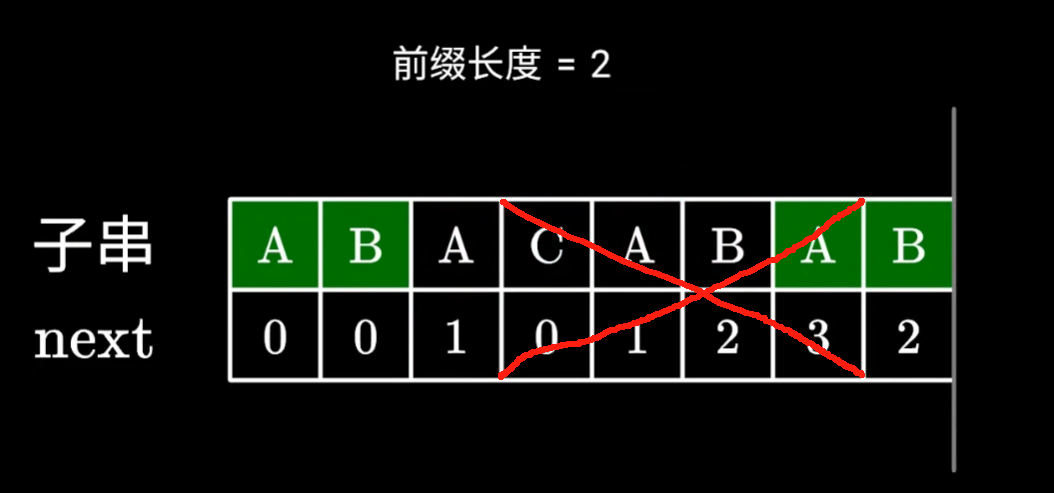
next數組中的值,實際上就是,子串以當前字符串結尾,在當前字符串中,最長的前綴,后綴相同的字符串長度
如下圖
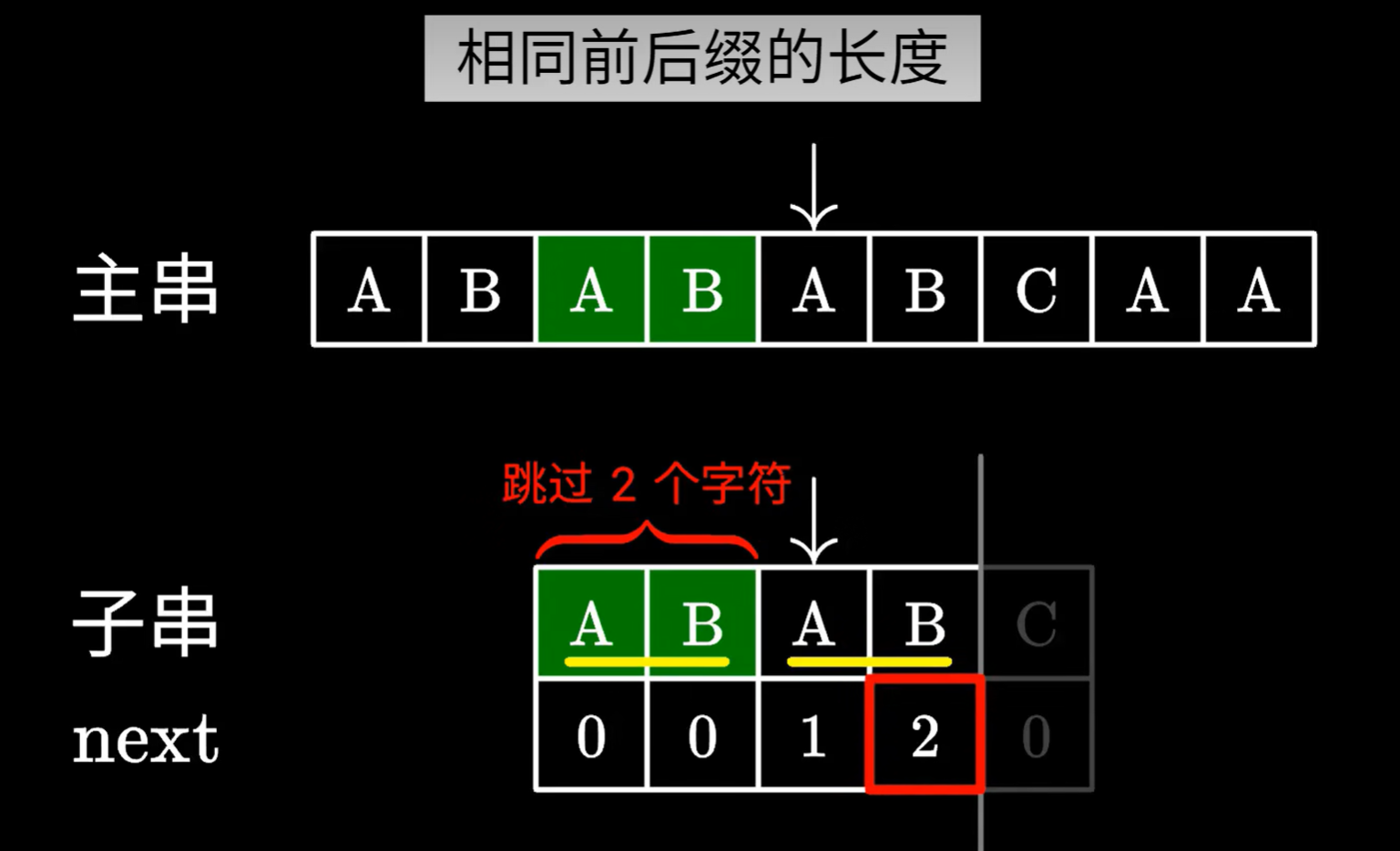
ABAB最長的相同前綴,后綴,該前綴或者后綴的長度是2
我們現在知道next的數組里的值代表什么了
那我們想一下,如何推導出next數組里的值
在后綴下一個字符,和前綴后一個字符相同時,我們只需要把next數組對應的值+1,然后填入即可

那在不同時,應該怎么辦,循環遍歷可以,但是時間復雜度較高
舉例,上圖再往下走一個
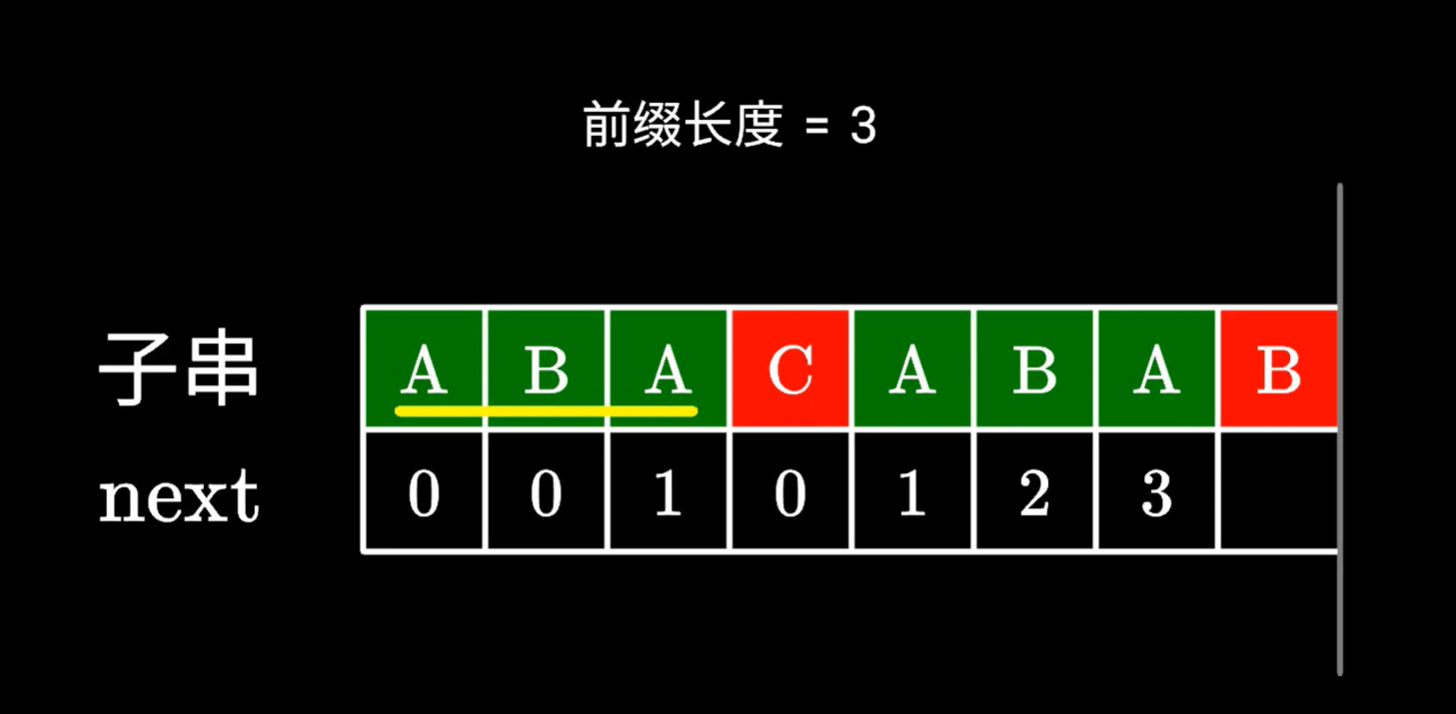
C和B不同,如何求B的對應的next值
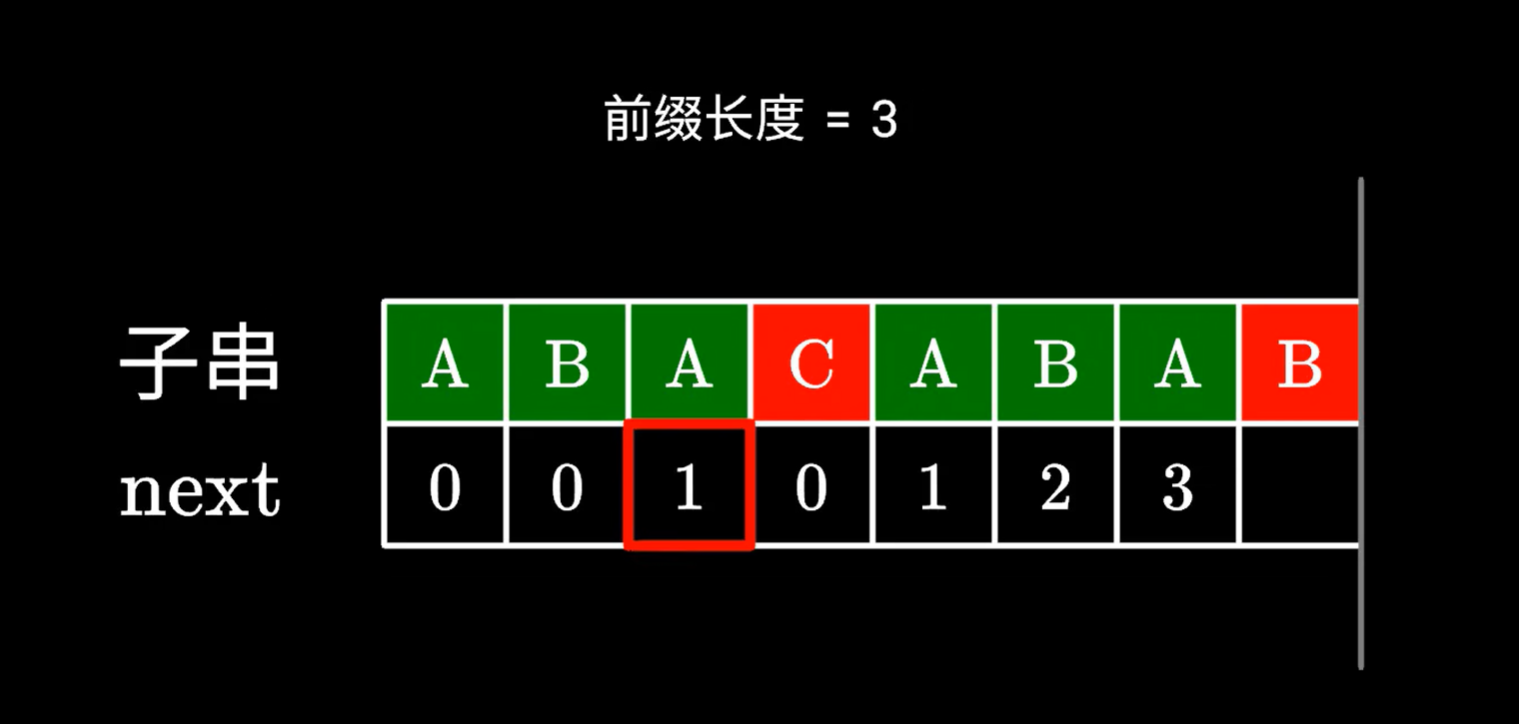
下位字符不同,沒辦法構成更長的相同前后綴,我們看看有沒有更短的前后綴
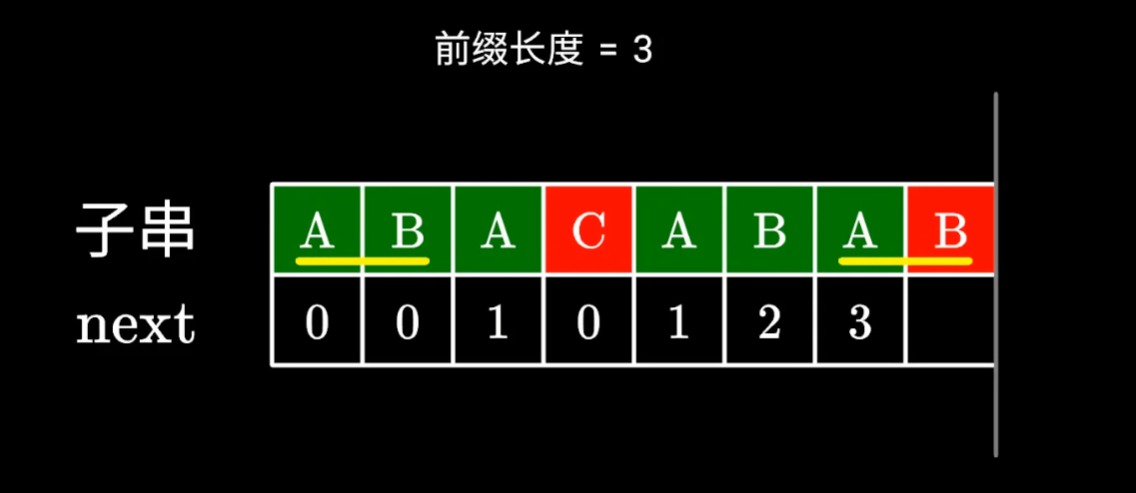
我們可以發現,確實存在更短的,兩位的前后綴,但是這步在程序中如何體現,暴力求解似乎時間復雜度有點高
其實我們next數組里還有信息,也就是next[i]=3,則子串前3個數,和i-3到i,這兩個字符串是相同的
字符串前三個字符,和i-3到i,就是前后綴,前三個數,和后三個數

也就是右邊的后綴,其實等于左邊的前綴,那我們其實可以忽略中間其他的值,直接去找到最左邊
為什么不會有漏?第一,右邊的后綴和左邊的前綴完全相等
第二,后綴第四個字符和前綴第四個字符不同,所以不會比右邊的后綴,或左邊的前綴更長,也就不會用更多字符

這樣,就相當于是求ABAB的前后綴
第三個A對應的值是1,B是字符串ABAB后綴的第二個字符(因為A對應的是1)
比較B和前綴的第二個字符是否相等
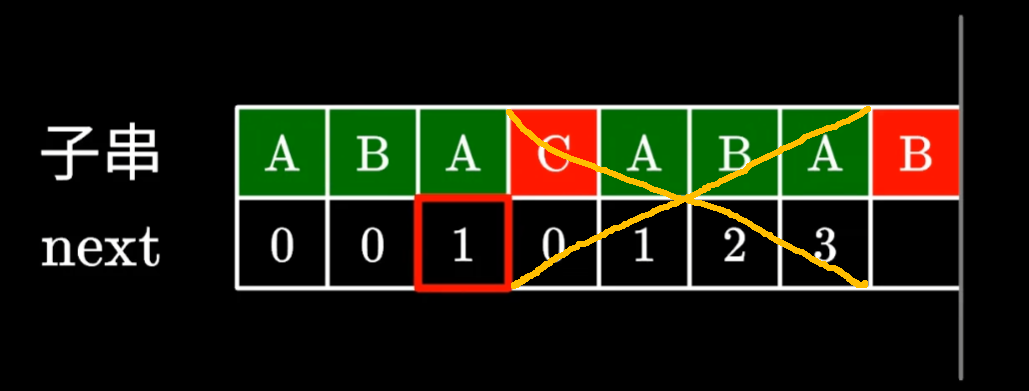
相等,則在B所處位置對應的next數組的值+1
B對應的next的數組的上一位的值,是通過第三個A獲取的,但是實際上,和他組成后綴的是倒數第二個A
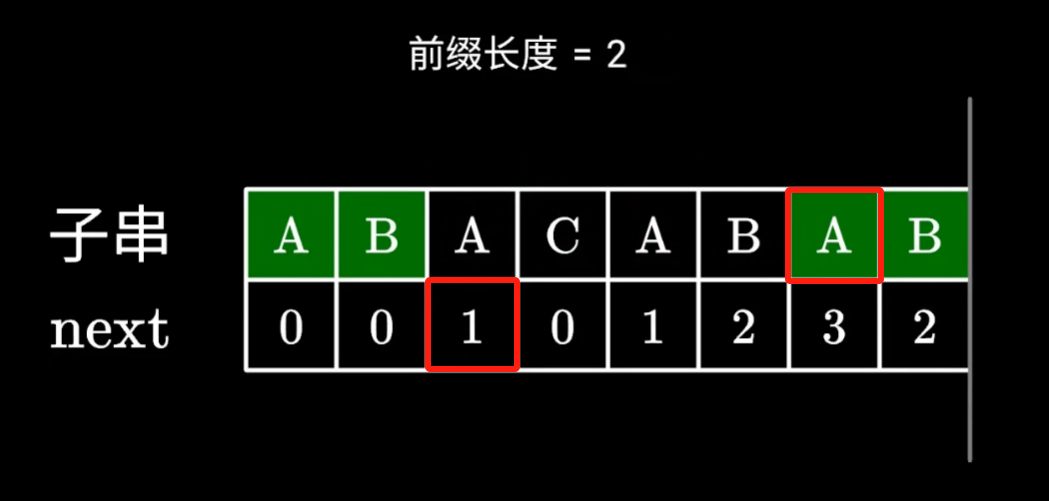
實際上是這樣得到的next對應的值,抽象上是和第三個A組成的前后綴
因為倒數第二個A,對應的next的值為3,也就是和前三個字符前綴完全相等
所以可以直接拿第二個A的next計算,因為前三個字符,和后三個字符(這說的字符串next=3對應的A)完全一樣
前三個有的字符,后三個都有,所以B可以和后三個字符組成的后綴,和前三個字符也可以組成相同的后綴
后三個字符代表的next值代表的前后綴相同的長度又太長,利用前三個字符代表的前后綴長度,即可完成回退
代碼實現
next[i]代表子串p[1,i]相同前后綴的最大長度
i代表的指針,永遠不往前回退,指向的是后綴的最后一個字符
j代表的指針,可以通過next數組回退,指向的是前綴最后一個字符
注:next在c++中有關鍵字,所以使用ne[]
next數組推導實現
ne[1]=0;
//兩個字符串數組實際上都是從1開始
//i等于2是因為指向第二個字符即可,至少兩個字符才有前后綴
//j=0,因為j從j+1開始比,也就是j=0是為了j從1開始
for(int i=2,j=0;i<=n;i++){ //j不為0,為0表示回到的子串第一個數的位置//i代表目前指到的位置,j代表相同前后綴的前綴的最后一個字符的位置//如果下位字符不同時,回退到j的值代表的前ne[j]位//上圖中說前綴后綴完全相等,j回到相同的前綴的最后一個字符的位置//看ne[j]的下一位p[j+],和i指向的字符是否相等//相等結束循環,否則繼續,直到相等或者j=0(回退到第一個字符串)while(j&&p[i]!=p[j+1])j=ne[j];//如果是相等,而不是j回退到了0,則j++,表示長度+1//j的值是ne[j]的值,j++= 就是 j=ne[j]+1,if(p[i]==p[j+1])j++;//記錄下j的值,j現在指向的是相同前后綴的前綴的最后一個字符//代表的值是最長相同前后綴長度//把這個值加在ne[i]指針上,指向的是相同前后綴后綴的最后一個字符ne[i]=j;
} 子串位置查找實現,查找主串出現子串的起始位置
//推導子串出現位置,這次i等于1是因為,此循環判斷的不是前后綴相同,而是判斷是否為子串//因為兩個完全一樣的字符串,也互相為子串,子串第一個數有可能從i=1,j=1就開始了//所以這里要令i=1for(int i=1,j=0;i<=m;i++){//跳躍式找到主串現在指向的值,在子串中存在的位置while(j&&s[i]!=p[j+1])j=ne[j];//i指向主串的字符,和子串的字符下一個字符相等,則可以再推進走一步if(s[i]==p[j+1])j++;if(j==n)//長度一致,找到子串{cout<<i-j<<" ";//返回子串起始位置//可省略,意思是將j回退到除本身外,最大的相同前后綴長度,避免下個循環j+1越界j=ne[j];}}整合代碼
AcWing - 算法基礎課
#include<iostream>
using namespace std;
const int N = 100010;
char p[N],s[N*10];
int ne[N];
int n,m;
int main(){cin >> n >> p + 1 >> m >> s + 1;ne[1]=0;//推導nxet數組for(int i=2,j=0;i<=n;i++){while(j&&p[i]!=p[j+1])j=ne[j];if(p[i]==p[j+1])j++;ne[i]=j;}//推導子串出現位置for(int i=1,j=0;i<=m;i++){//跳躍式找到主串現在指向的值,在子串中存在的位置while(j&&s[i]!=p[j+1])j=ne[j];if(s[i]==p[j+1])j++;if(j==n)//長度一致,找到子串{cout<<i-j<<" ";//返回子串起始位置//可省略,意思是將j回退到除本身外,最大的相同前后綴長度,避免下個循環j+1越界j=ne[j];}}return 0;
}
)









)







