Part1:Hadoop、Hive、Spark關系概覽
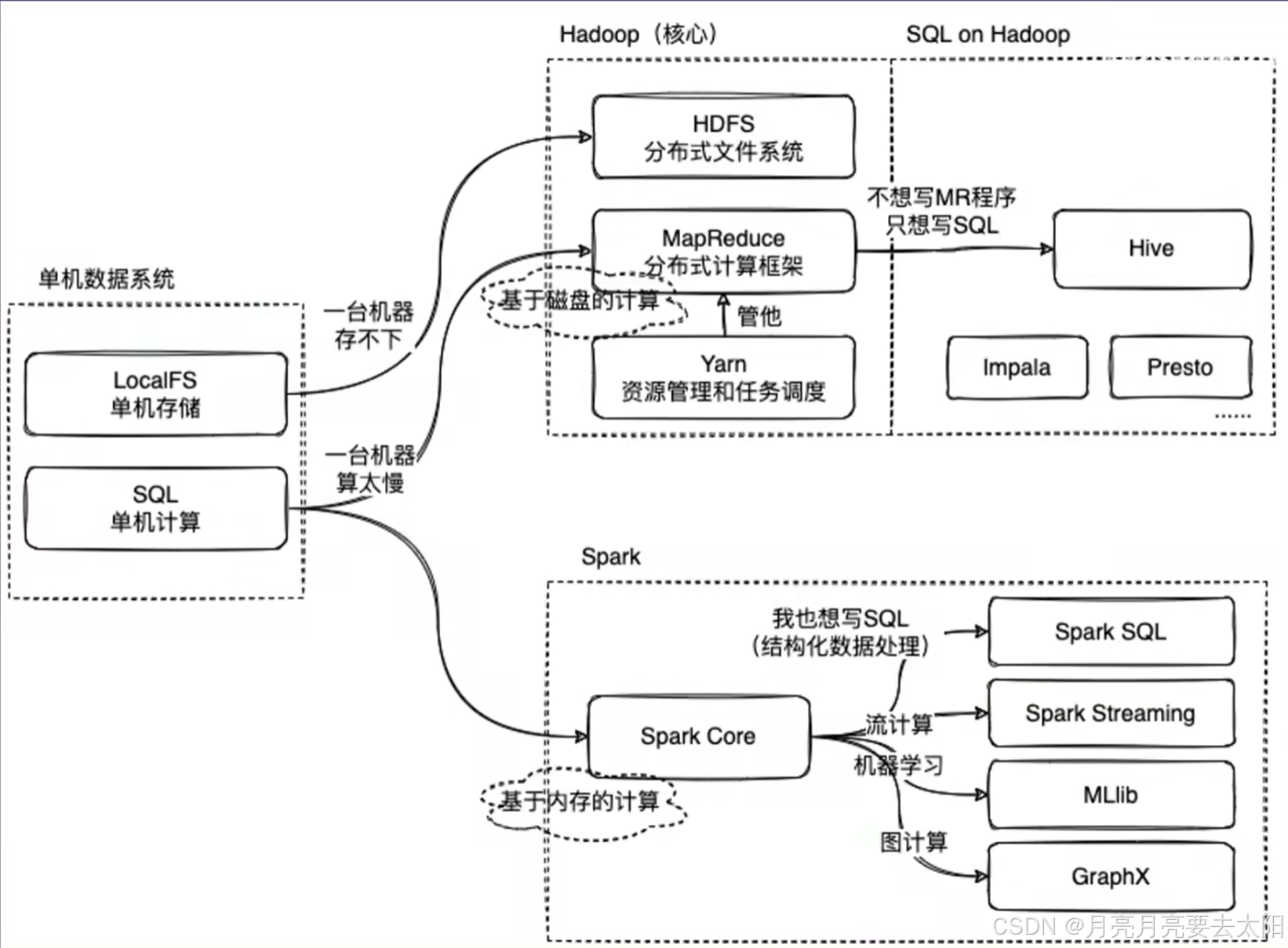
1、MapReduce on Hadoop 和spark都是數據計算框架,一般認為spark的速度比MR快2-3倍。
2、mapreduce是數據計算的過程,map將一個任務分成多個小任務,reduce的部分將結果匯總之后返回。
3、HIve中有metastore存儲結構化信息,還有執行引擎將sql翻譯成mapreduce,再把加工結果返回給用戶。
Part2:十道Hadoop相關的題目
一、Hadoop生態系統簡介:請簡要描述Hadoop的核心組件及其作用。
Hadoop是一個開源的分布式計算框架,專門用于存儲和處理大規模數據集(通常從TB到PB級別)。Hadoop的核心思想是分布式存儲和分布式計算,通過將數據和計算任務分散到多個節點上,實現高性能和高容錯性。
其核心組件包括HDFS、mapreduce、TARN.
(1)HDFS(Hadoop Distributed File System)
- 作用:HDFS是Hadoop的分布式文件系統,用于存儲海量數據。
- 特點:
- 數據被分割成多個塊(默認128MB或256MB),并分布存儲在不同的節點上。
- 具有高容錯性,數據會自動復制多份(默認3份)存儲在不同的節點上。
- 關鍵角色:
- NameNode:管理文件系統的元數據(如文件目錄結構、塊的位置等)。
- DataNode:存儲實際的數據塊。
(2)MapReduce
- 作用:MapReduce是Hadoop的分布式計算框架(the same with Hadoop),用于處理大規模數據集。
- 工作原理:
- Map階段:將輸入數據分割成小塊,并行處理并生成中間結果(鍵值對)。
- Reduce階段:對Map階段的中間結果進行匯總和計算,生成最終結果。
- 特點:
- 適合批處理任務,但不適合實時計算(因為mapreduce的機制)。
(3)YARN(Yet Another Resource Negotiator)
- 作用:YARN是Hadoop的資源管理系統,負責集群資源的調度和任務管理。
- 特點:
- 將資源管理和任務調度分離,支持多種計算框架(如MapReduce、Spark等)。
- 提高了集群的利用率和靈活性。
二、Hadoop的工作流程
1. 數據存儲:
數據被上傳到HDFS,分割成多個塊并分布存儲在不同的DataNode,NameNode記錄文件的元數據和塊的位置信息。
2. 數據處理:
用戶提交一個MapReduce任務:YARN負責分配資源,啟動Map任務和Reduce任務,Map任務讀取HDFS上的數據,生成中間結果,Reduce任務對中間結果進行匯總,生成最終結果并寫回HDFS。
三、HDFS:解釋HDFS的架構,說明NameNode和DataNode的作用。
HDFS是Hadoop的核心組件,存儲和管理大規模數據,具有高容錯性和高吞吐量的特點。其架構采用主從模式,主要包括以下組件:
1. NameNode(主節點)
作用:
元數據管理:存儲文件系統的元數據,如文件名、目錄結構、文件塊位置等。
協調客戶端訪問:處理客戶端的讀寫請求,并協調DataNode的操作。
特點:
單點故障:NameNode是單點,故障會導致整個系統不可用。Hadoop 2.0通過備用NameNode解決這一問題。
內存存儲:元數據存儲在內存中,以加快訪問速度。
2. DataNode(從節點)
作用:
數據存儲:實際存儲文件數據,文件被分割成多個塊(默認128MB),并在多個DataNode上復制(默認3份)以實現容錯。
數據塊管理:負責數據塊的創建、刪除和復制,并定期向NameNode報告狀態。
特點:
分布式存儲:數據塊分布在多個DataNode上,提供高吞吐量和容錯性。
本地存儲:數據塊存儲在本地文件系統中。
3. Secondary NameNode(輔助NameNode)
作用:
輔助NameNode:定期合并NameNode的編輯日志和鏡像文件,減少NameNode的啟動時間。
非備用NameNode:它不是NameNode的備用節點,不能直接接管NameNode的工作。
總結
NameNode:負責管理元數據和協調客戶端訪問,是HDFS的核心。
DataNode:負責實際數據存儲和塊管理,分布在多個節點上以提供高吞吐量和容錯性。
Secondary NameNode:輔助NameNode進行元數據管理,但不提供故障切換功能。
四、HDFS的工作流程
1. 文件寫入:
客戶端向NameNode請求寫入文件;NameNode分配DataNode并返回其列表;客戶端將數據寫入第一個DataNode,該節點再將數據復制到其他DataNode。
2. 文件讀取:
客戶端向NameNode請求讀取文件;NameNode返回存儲該文件塊的DataNode列表;客戶端直接從DataNode讀取數據。
3. 容錯與復制:
每個數據塊默認復制3份,存儲在不同DataNode上;如果某個DataNode失效,NameNode會檢測到并將數據塊復制到其他節點。
五、MapReduce:描述其工作流程,并解釋Mapper和Reducer作用。
MapReduce是一種用于大規模數據處理的編程模型,由Google提出,主要用于分布式計算。它將任務分解為兩個主要階段:Map和Reduce。
工作流程
1. 輸入分片(Input Splitting):
輸入數據被劃分為多個分片(splits),每個分片由一個Mapper處理。
2. Map階段:
每個Mapper處理一個輸入分片,生成鍵值對(key-value pairs)作為中間結果。
3. Shuffle和Sort:
系統將Mapper輸出的中間結果按鍵分組并排序,確保相同鍵的值被送到同一個Reducer。
4. Reduce階段:
Reducer接收分組后的中間結果,進行匯總處理,生成最終輸出。
5. 輸出:
Reducer的輸出寫入存儲系統,如HDFS。
Mapper的作用:
數據處理:Mapper讀取輸入分片,逐條處理并生成鍵值對。
并行處理:多個Mapper可以同時處理不同分片,提升效率。
中間結果生成:Mapper的輸出是中間結果,供Reducer進一步處理。
Reducer的作用
數據匯總:Reducer對Mapper輸出的中間結果進行匯總。
聚合計算:Reducer執行如求和、計數等聚合操作。
生成最終結果:Reducer的輸出是最終結果,通常存儲在分布式文件系統中。
示例:假設統計文本中單詞的出現次數
1. Map階段:每個Mapper讀取一部分文本,生成形如`(word, 1)`的鍵值對。
2. Shuffle和Sort:系統將相同單詞的鍵值對分組,如`("hello", [1, 1, 1])`。
3. Reduce階段:Reducer對每個單詞的計數求和,生成`("hello", 3)`。
4. 輸出:最終結果寫入文件,如`hello 3`。
總結
Mapper:負責數據的分片處理和中間結果的生成。
Reducer:負責中間結果的匯總和最終結果的生成。
六、MapReduce中,數據是如何進行分區和排序的?解釋Partitioner和Combiner的作用。
在MapReduce中,數據的分區和排序的步驟主要由Partitioner和Combiner來完成。
數據分區(Partitioning)
Partitioner的作用
數據分配:Partitioner負責將Mapper輸出的鍵值對分配到不同的Reducer。它通過哈希函數對鍵進行計算,決定數據應發送到哪個Reducer。
負載均衡:合理的分區策略可以確保各Reducer的負載均衡,避免某些Reducer過載。
分區過程:
1. Mapper輸出:Mapper生成鍵值對后,Partitioner根據鍵的哈希值決定其所屬分區。
2.分區數量:分區數量通常等于Reducer的數量。
3. 數據發送:每個分區的數據被發送到對應的Reducer。
默認Partitioner
HashPartitioner:MapReduce默認使用哈希分區器,通過`hash(key) % numReduceTasks`計算分區。
數據排序(Sorting)
排序過程
1. Mapper端排序:Mapper輸出的鍵值對在發送到Reducer之前,會在本地進行排序。
2. Reducer端排序:Reducer在接收到所有Mapper的數據后,會再次進行全局排序,確保相同鍵的值按順序處理。
排序機制
按鍵排序:MapReduce框架默認按鍵進行排序,確保Reducer處理時鍵是有序的。
自定義排序:可以通過實現`WritableComparable`接口自定義排序邏輯。
示例:假設統計文本中單詞的出現次數:
1. Map階段:
Mapper生成鍵值對,如`("hello", 1)`。
2. Combiner階段:
Combiner對Mapper的輸出進行局部聚合,如將`("hello", [1, 1, 1])`合并為`("hello", 3)`。
3. Partitioner階段:
Partitioner根據鍵的哈希值決定數據發送到哪個Reducer。
4. Sort階段:
數據在發送到Reducer之前進行排序,確保相同鍵的值按順序處理。
5. Reduce階段:
Reducer對接收到的數據進行最終聚合,生成`("hello", 3)`。
總結:
Partitioner:負責將Mapper輸出的鍵值對分配到不同的Reducer,確保負載均衡。
Combiner:在Mapper端進行局部聚合,減少數據傳輸量,優化性能。
七、YARN在Hadoop中的作用,及其與MapReduce的關系
YARN是Hadoop 2.0引入的核心組件,用于資源管理和作業調度。它的主要作用是解耦資源管理和數據處理邏輯,使得MapReduce只需專注于數據處理,同時支持其他計算框架。
YARN的架構
YARN主要由以下幾個組件組成:
1. ResourceManager (RM):全局資源管理+啟動ApplicationMaster。
2. NodeManager (NM):節點資源管理+向ResourceManager報告資源使用情況和任務狀態。
3. ApplicationMaster (AM):
- 作業管理:每個應用程序都有一個ApplicationMaster,負責與ResourceManager協商資源,與NodeManager協作執行任務。
- 任務調度:ApplicationMaster負責將任務調度到合適的容器中執行。
4. Container:理解為資源的封裝,任務在Container中執行,由NodeManager監控。
YARN與MapReduce的關系:
1. 解耦資源管理和作業調度:
- 在Hadoop 1.0中,MapReduce既負責資源管理又負責作業調度,導致擴展性和靈活性受限。
- YARN將資源管理和作業調度解耦,使得MapReduce只需專注于數據處理邏輯。
2. MapReduce作為YARN的一個應用程序:
- 在YARN架構下,MapReduce作為一個應用程序運行,由ApplicationMaster負責作業的管理和任務調度。
- MapReduce的ResourceManager和JobTracker功能被YARN的ResourceManager和ApplicationMaster取代。
3. 支持多計算框架:
YARN不僅支持MapReduce,還支持其他計算框架如Spark、Flink等,使得Hadoop成為一個通用的數據處理平臺。
示例:一個MapReduce作業
用戶提交MapReduce作業到YARN的ResourceManager,ResourceManager為該作業分配資源,并啟動一個ApplicationMaster,ApplicationMaster與ResourceManager協商資源,將Map和Reduce任務調度到各個NodeManager的Container中執行,NodeManager監控任務的執行情況,并向ApplicationMaster報告狀,ApplicationMaster在作業完成后,向ResourceManager注銷并釋放資源。
八、Hadoop MapReduce和Apache Spark都是大數據處理框架,請簡要說明它們的主要區別。
1. 數據處理模型
Hadoop MapReduce:批處理,適合靜態數據;數據處理分為Map和Reduce兩個階段,中間結果需要寫入磁盤。
Apache Spark:支持批處理、流處理、交互式查詢和機器學習等多種數據處理模式;利用內存進行計算,減少磁盤I/O,顯著提高性能。
2. 性能
Hadoop MapReduce:磁盤I/O性能相對較低,適合高延遲的批處理作業。
Apache Spark:內存計算+低延遲。
3. 易用性
Hadoop MapReduce:編程模型相對復雜+API限制(API較為底層,開發效率較低)
Apache Spark:高級API(Spark提供了豐富的高級API(如Scala、Java、Python、R),易于使用。)+開發效率高。
4. 生態系統
Hadoop MapReduce:MapReduce是Hadoop生態系統的一部分,依賴HDFS進行數據存儲,
Hadoop生態系統成熟穩定,適合大規模批處理。
Apache Spark: Spark有自己的生態系統(獨立),支持多種數據源(如HDFS、S3、Cassandra)。+豐富庫:Spark提供了豐富的庫(如Spark SQL、Spark Streaming、MLlib、GraphX),支持多種數據處理需求。
總結:
Hadoop MapReduce:適合大規模批處理和高容錯性需求的場景,但性能較低,編程復雜。
Apache Spark:適合實時數據處理、迭代計算和多種數據處理模式,性能高,易于使用。
九、在配置Hadoop集群時的關鍵配置參數
1. dfs.replication:
? 作用:指定HDFS中每個數據塊的副本數量。
? 解釋:默認值為3,表示每個數據塊會在集群中存儲3個副本。增加副本數可以提高數據的可靠性和容錯性,但也會增加存儲開銷。
2.mapreduce.tasktracker.map.tasks.maximum和 mapreduce.tasktracker.reduce.tasks.maximum:
? 作用:分別指定每個NodeManager上可以同時運行的Map任務和Reduce任務的最大數量。
? 解釋:這些參數影響集群的并發處理能力。合理設置這些參數可以優化資源利用率和作業執行效率。
3. yarn.scheduler.maximum-allocation-mb:
? 作用:指定YARN可以為每個容器分配的最大內存量。
? 解釋:這個參數決定了單個任務可以使用的最大內存資源。合理設置可以防止單個任務占用過多資源,影響其他任務的執行。
十、數據本地性優化:在Hadoop中,數據本地性(Data Locality)是什么?為什么它對性能優化至關重要?
**數據本地性(Data Locality)**是指計算任務在數據所在的節點上執行,盡量減少數據的網絡傳輸。
? 重要性:
? 減少網絡開銷:數據本地性可以減少數據在網絡中的傳輸,降低網絡帶寬的消耗。
? 提高性能:本地數據處理速度遠快于通過網絡傳輸數據后再處理,顯著提高作業的執行效率。
? 負載均衡:數據本地性有助于均衡集群中各節點的負載,避免某些節點過載。
十一、Hadoop故障處理:在Hadoop集群中,如果某個DataNode宕機,系統會如何處理?NameNode在這個過程中扮演了什么角色?
1. 檢測故障:
? NameNode通過心跳機制檢測到DataNode宕機。
2. 副本復制:
? NameNode會檢查宕機DataNode上存儲的數據塊,發現副本數量不足時,會啟動副本復制過程,將數據塊復制到其他健康的DataNode上。
3. 更新元數據:
? NameNode更新元數據信息,記錄新的數據塊副本位置。
NameNode的角色:
? 元數據管理:NameNode負責管理文件系統的元數據,包括文件到數據塊的映射和數據塊的位置信息。
? 故障檢測與恢復:NameNode通過心跳機制檢測DataNode的狀態,并在DataNode宕機時協調數據塊的復制和恢復。
十二、Hadoop應用場景
應用場景:日志分析
? 場景描述:大型互聯網公司每天生成大量的日志數據,需要對這些日志進行分析,以提取用戶行為、系統性能等信息。(大規模數據處理+成本效益+高容錯性+批處理)

![[密碼學實戰]Java實現國密TLSv1.3單向認證](http://pic.xiahunao.cn/[密碼學實戰]Java實現國密TLSv1.3單向認證)
)








 深入使用cdk(API Gateway + event bridge))




)


