作者: Defined2014 原文來源: https://tidb.net/blog/7077577f
什么是 TiDB 全局索引
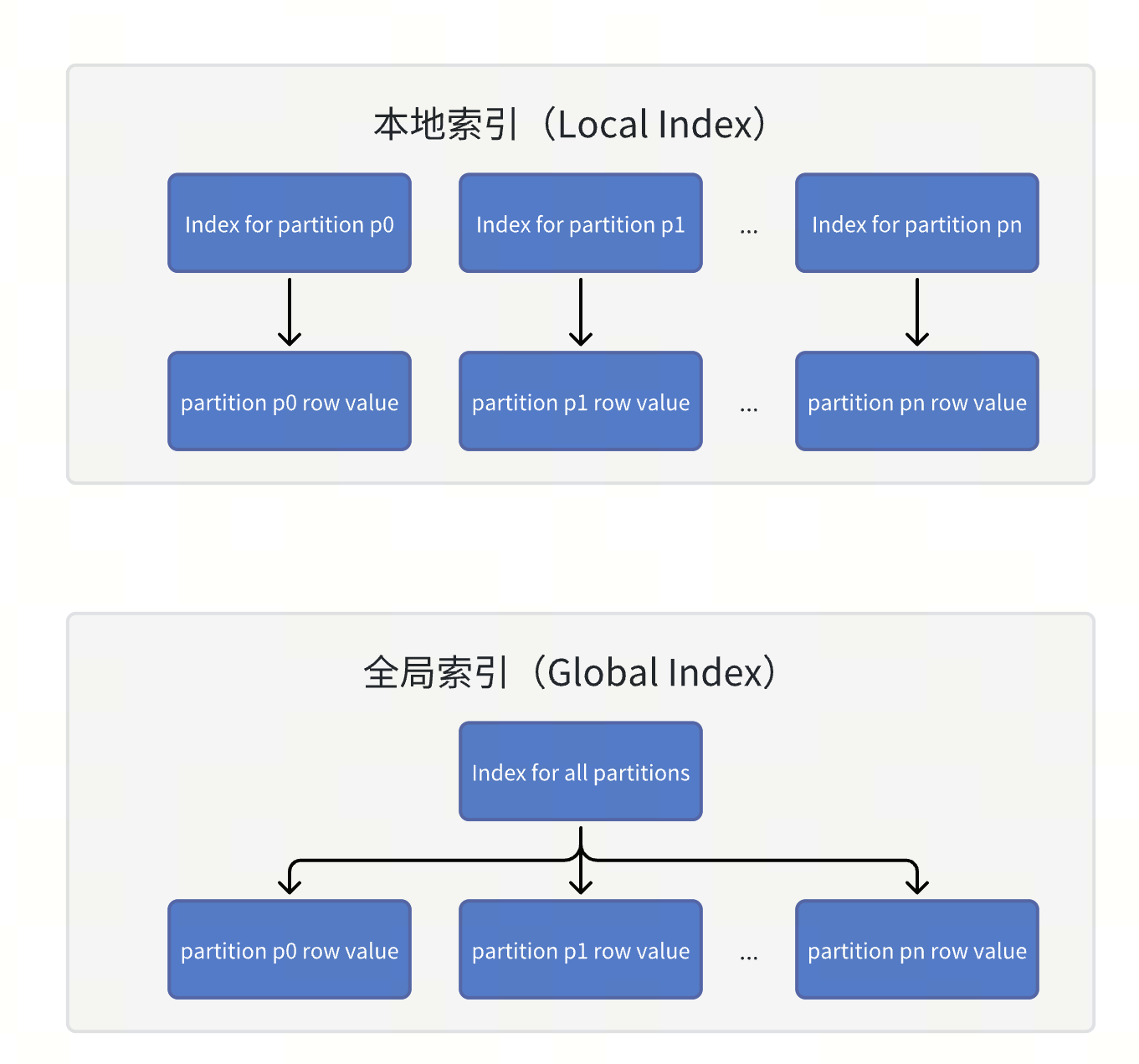
在 TiDB 中,全局索引是一種定義在分區表上的索引類型,它允許索引分區與表分區之間建立一對多的映射關系,即一個索引分區可以對應多個表分區。這與 TiDB 早期版本中的本地索引(Local Index)不同,本地索引的索引分區與表分區之間是一對一的映射關系,即一個分區對應一個局部的索引塊。
全局索引能覆蓋整個表的數據,使得主鍵和唯一鍵在不包含分區鍵的情況下仍能保持全局唯一性。此外,全局索引可以在一次操作中訪問多個分區的索引數據,而無需對每個分區的本地索引逐一查找,顯著提升了針對非分區鍵的查詢性能。
下圖簡單展示了本地索引和全局索引的區別
TiDB 全局索引的發展歷程
- v7.6.0 版本之前 :TiDB 僅支持分區表的本地索引。這意味著,對于分區表上的唯一鍵,必須包含表分區表達式中的所有列。如果查詢條件中沒有使用分區鍵,那么查詢將不得不掃描所有分區,這會導致查詢性能下降。
- v7.6.0 版本 :引入了系統變量
tidb_enable_global_index,用于開啟全局索引功能。然而,當時該功能仍在開發中,不推薦用戶啟用。 - v8.3.0 版本 :全局索引功能作為實驗性特性發布。用戶可以通過在創建索引時顯式使用
GLOBAL關鍵字來創建全局索引。 - v8.4.0 版本 :全局索引功能正式成為一般可用(GA)特性。用戶可以直接使用
GLOBAL關鍵字創建全局索引,而無需再設置系統變量tidb_enable_global_index。從這個版本開始,該系統變量被棄用,并且始終為ON。 - v8.5.0 版本 :全局索引功能支持了包含分區表達式中的所有列。
- v9.0.0 版本 :全局索引功能支持了非唯一索引的情況。在分區表中,除聚簇索引外都可以被創建為全局索引。
TiDB 全局索引的語法
在 TiDB 中,創建全局索引(Global Index)時,可以在 CREATE INDEX 或 ALTER TABLE 語句中使用 GLOBAL 關鍵字,或在建表時通過 GLOBAL 關鍵字或 /*T![global_index] GLOBAL */ 注釋指定。
創建全局索引的語法:
CREATE [UNIQUE] INDEX index_name ON table_name (column_list) [GLOBAL];
ALTER TABLE table_name ADD [UNIQUE] INDEX index_name (column_list) [GLOBAL];
示例:
- 創建全局唯一索引:
CREATE UNIQUE INDEX idx_global ON employees (email) GLOBAL;
此語句在 employees 表的 email 列上創建一個全局唯一索引,確保每個電子郵件地址在整個表中唯一。
- 添加全局索引:
ALTER TABLE orders ADD INDEX idx_global_order_date (order_date) GLOBAL;
此語句向 orders 表添加一個名為 idx_global_order_date 的全局索引,索引列為 order_date 。
- 在建表時創建全局索引:
CREATE TABLE `sbtest` (`id` int NOT NULL,`k` int NOT NULL DEFAULT '0',`c` char NOT NULL DEFAULT '',KEY `idx1` (`k`) GLOBAL,KEY `idx2` (`k`) /*T![global_index] GLOBAL */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
PARTITION BY HASH (`id`) PARTITIONS 5;
此語句在創建 sbtest 表時同時創建了兩個名為 idx1 和 idx2 的全局索引,兩個索引的索引列都為 k 。
TiDB 全局索引的優勢
提升查詢性能
全局索引能夠有效提高檢索非分區列的效率。當查詢涉及非分區列時,全局索引可以快速定位相關數據,避免了對所有分區的全表掃描,可以顯著降低 cop task 的數量,這對于分區數量龐大的場景尤為有效。
經過測試,在分區數量為 100 的情況下,sysbench select_random_points 場景得到了 53 倍 的性能提升。
增強應用靈活性
全局索引的引入,消除了分區表上唯一鍵必須包含所有分區列的限制。這使得用戶在設計索引時更加靈活,可以根據實際的查詢需求和業務邏輯來創建索引,而不再受限于表的分區方案。這種靈活性有助于更好地優化查詢性能,滿足多樣化的業務需求。
減少應用修改工作量
在數據遷移和應用修改過程中,全局索引可以減少對應用的修改工作量。如果沒有全局索引,在遷移數據或修改應用時,可能需要調整分區方案或重寫查詢語句以適應索引的限制。有了全局索引之后,這些修改可以被避免,從而降低了開發和維護成本。
如在將 Oracle 數據庫中的某張表遷移到 TiDB 時,因為 Oracle 支持全局索引,可能在某些表上存在一些不包含分區列的唯一索引,在遷移過程需要對表結構進行調整,以適應 TiDB 的分區表限制。然而,隨著 TiDB 對全局索引的支持,用戶只需簡單地修改索引定義,將其設置為全局索引,即可與 Oracle 保持一致,從而顯著降低遷移成本。
TiDB 全局索引的工作原理
基本思想
在 TiDB 的分區表中,本地索引的鍵值前綴是分區表的 ID 而全局索引的前綴是表的 ID。這樣的改動確保了全局索引的數據在 TiKV 上分布是連續的,降低了查詢索引時 RPC 的數量。
CREATE TABLE `sbtest` (`id` int(11) NOT NULL,`k` int(11) NOT NULL DEFAULT '0',`c` char(120) NOT NULL DEFAULT '',KEY idx(k),KEY global_idx(k) GLOBAL
) partition by hash(id) partitions 5;
以上面的表結構為例, idx 為普通索引, global_idx 為全局索引。索引 idx 的數據會分布在 5 個不同的 ranges 中,如 PartitionID1_i_xxx , PartitionID2_i_xxx 等,而索引 global_idx 的數據則會集中在一個 range ( TableID_i_xxx ) 內。
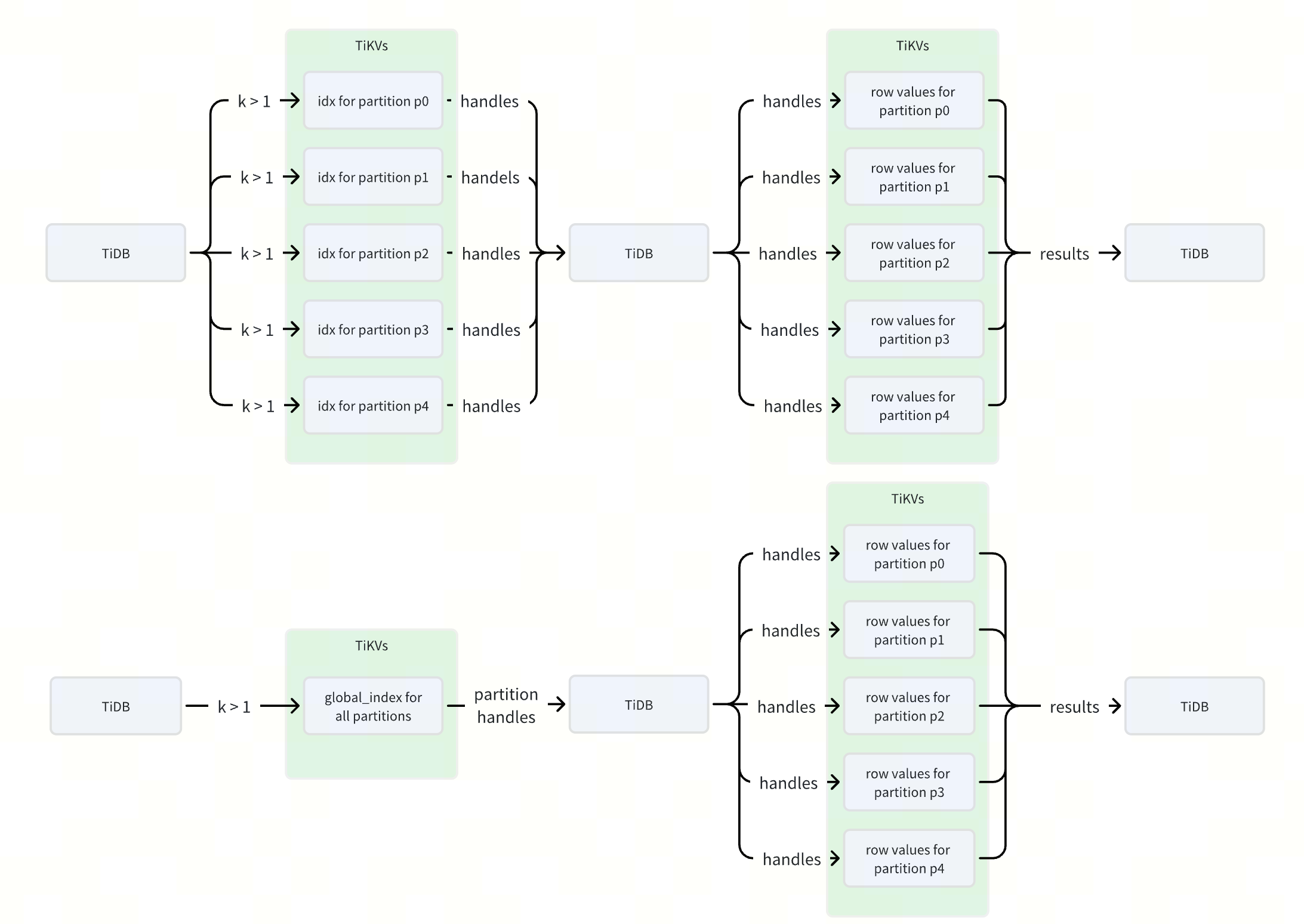
這樣當我們進行 k 相關的查詢時,如 select * from sbtest where k > 1 ,通過索引 idx 會構造 5 個不同的 ranges,而通過全局索引 global_idx 則只會構造 1 個 range,每個 range 在 TiDB 中對應一個或多個 RPC 請求,這樣使用全局索引可以降低數倍的 RPC 請求數,從而提升查詢索引的性能。
下圖更加直觀地展示了在使用 idx 和 global_idx 兩個不同索引執行 select * from sbtest where k > 1 查詢語句在 RPC 請求和數據流轉過程中的差異。
編碼方式
在 TiDB 中,索引項被編碼為鍵值對。對于分區表,每個分區在 TiKV 層被視為一個獨立的物理表,擁有自己的 partitionID 。因此,分區表的索引項也被編碼為:
唯一鍵
Key:
- PartitionID_indexID_ColumnValuesValue:
- IntHandle- TailLen_IntHandle- CommonHandle- TailLen_IndexVersion_CommonHandle非唯一鍵
Key:
- PartitionID_indexID_ColumnValues_HandleValue:
- IntHandle- TailLen_Padding- CommonHandle- TailLen_IndexVersion
在全局索引中,索引項的編碼方式有所不同。為了使全局索引的鍵布局與當前索引鍵編碼保持兼容,新的索引編碼布局為:
唯一鍵
Key:
- TableID_indexID_ColumnValuesValue:
- IntHandle- TailLen_PartitionID_IntHandle- CommonHandle- TailLen_IndexVersion_CommonHandle_PartitionID非唯一鍵
Key:
- TableID_indexID_ColumnValues_HandleValue:
- IntHandle- TailLen_PartitionID- CommonHandle- TailLen_IndexVersion_PartitionID
這種編碼方式使得全局索引的鍵以 TableID 開頭,而 PartitionID 被放置在 Value 中。這樣設計的優點是,它與現有的索引鍵編碼方式兼容,但同時也帶來了一些挑戰,例如在執行 DROP PARTITION, TRUNCATE PARTITION 等 DDL 操作時,由于索引項不連續,需要進行額外的處理。
TiDB 全局索引的限制與注意事項
影響部分 DDL 性能
當分區表中存在全局索引時,執行諸如 DROP PARTITION(刪除分區)、TRUNCATE PARTITION(清空分區)、REORG PARTITION(重組分區)等部分 DDL 操作時,需要同步更新全局索引的值,這會顯著增加 DDL 操作的執行時間。
在 v8.5.0 默認參數下,測試顯示對包含全局索引的 sysbench 表執行 DROP PARTITION 或 TRUNCATE PARTITION 操作時, oltp_read_write 負載的性能會下降 15% 至 20%。
聚簇索引 (Clustered Index)
聚簇索引不能成為全局索引,是因為如果聚簇索引是全局索引,則表將不再分區。這是因為聚簇索引的鍵是分區級別的行數據的鍵,但全局索引是表級別的,這就造成了沖突。如果需要將主鍵設置為全局索引,則需要顯式設置該主鍵為非聚簇索引,如 PRIMARY KEY(col1, col2) NONCLUSTERED GLOBAL 。
性能測試數據
-
select_random_pointsin sysbench
示例表結構
CREATE TABLE `sbtest` (`id` int(11) NOT NULL,`k` int(11) NOT NULL DEFAULT '0',`c` char(120) NOT NULL DEFAULT '',`pad` char(60) NOT NULL DEFAULT '',PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */,KEY `k_1` (`k`)/* Key `k_1` (`k`, `c`) GLOBAL */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
/* Partition by hash(`id`) partitions 100 */
/* Partition by range(`id`) xxxx */
負載 SQL
SELECT id, k, c, pad
FROM sbtest1
WHERE k IN (xx, xx, xx)
| Range Partition (100 partitions) | ||||
| Concurrency | 1 | 32 | 64 | Average RU |
| Clustered non-partitioned table | 225 | 19,999 | 30,293 | 7.92 |
| Clustered table range partitioned by PK | 68 | 480 | 511 | 114.87 |
Clustered table range partitioned by PK, with Global Index on k, c columns | 207 | 17,798 | 27,707 | 11.73 |
| Hash Partition (100 partitions) | ||||
| Concurrency | 1 | 32 | 64 | Average RU |
| Clustered non-partitioned table | 166 | 20361 | 28922 | 7.86 |
| Clustered table hash partitioned by PK | 60 | 244 | 283 | 119.73 |
Clustered table hash partitioned by PK, with Global Index on k, c columns | 156 | 18233 | 15581 | 10.77 |
- 通過上述測試可以看出,在高并發環境下,全局索引能夠顯著提升分區表查詢性能,提升幅度可達 50 倍。同時,全局索引還能夠顯著降低資源(RU)消耗。隨著分區數量的增加,這種性能提升的效果將愈加明顯。
最佳實踐
全局索引和本地索引
全局索引適用場景 :
- 數據歸檔不頻繁 :例如,醫療行業的部分業務數據需要保存 30 年,通常按月分區,然后一次性創建 360 個分區,且很少進行
DROP或TRUNCATE操作。在這種情況下,使用全局索引更為合適,因為它能提供跨分區的一致性和查詢性能。 - 查詢需要跨分區的數據 :當查詢需要訪問多個分區的數據時,全局索引可以避免跨分區掃描,提高查詢效率。
本地索引適用場景 :
- 數據歸檔需求 :如果數據歸檔操作很頻繁,且主要查詢集中在單個分區內,本地索引可以提供更好的性能。
- 需要使用分區交換功能 :在銀行等行業,可能會將處理后的數據先寫入普通表,確認無誤后再交換到分區表,以減少對分區表性能的影響。此時,本地索引更為適用,因為在使用了全局索引之后,分區表將不再支持分區交換功能。
全局索引和聚簇索引
由于聚簇索引和全局索引的原理限制,一個索引不能同時作為聚簇索引和全局索引。然而,這兩種索引在不同查詢場景中能提供不同的性能優化。在遇到需要同時兼顧兩者的需求時,我們可以將分區列添加到聚簇索引中,同時創建一個不包含分區列的全局索引。
假設我們有如下表結構:
CREATE TABLE `t` (`id` int DEFAULT NULL,`ts` timestamp NULL DEFAULT NULL,`data` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
PARTITION BY RANGE (UNIX_TIMESTAMP(`ts`))
(PARTITION `p0` VALUES LESS THAN (1735660800)PARTITION `p1` VALUES LESS THAN (1738339200)...)
在上面的 t 表中, id 列的值是唯一的。為了優化點查和范圍查詢的性能,我們可以選擇在建表語句中定義一個聚簇索引 PRIMARY KEY(id, ts) 和一個不包含分區列的全局索引 UNIQUE KEY id(id) 。這樣在進行基于 id 的點查詢時,會走全局索引 id ,選擇 PointGet 的執行計劃;而在進行范圍查詢時,聚簇索引則會被選中,因為聚簇索引相比全局索引少了一次回表操作,從而提升查詢效率。
修改后的表結構如下所示:
CREATE TABLE `t` (`id` int NOT NULL,`ts` timestamp NOT NULL,`data` varchar(100) DEFAULT NULL,PRIMARY KEY (`id`, `ts`) /*T![clustered_index] CLUSTERED */,UNIQUE KEY `id` (`id`) /*T![global_index] GLOBAL */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
PARTITION BY RANGE (UNIX_TIMESTAMP(`ts`))
(PARTITION `p0` VALUES LESS THAN (1735660800),PARTITION `p1` VALUES LESS THAN (1738339200)...)
通過這種方式,我們既能優化基于 id 的點查詢,又能提升范圍查詢的性能,同時確保表的分區列在基于時間戳的查詢中能得到有效的利用。
總結
TiDB 全局索引是 TiDB 在分區表索引方面的重要特性,它通過允許索引分區與表分區之間提供一對多的映射關系,提供了更靈活的索引設計和更高效的查詢性能。全局索引的引入,不僅提升了 TiDB 分區表在處理復雜查詢和大數據量場景下的能力,還為用戶在數據庫設計和優化方面提供了更多的選擇。
然而,全局索引也帶來了一些挑戰,如維護成本的增加。在使用全局索引時,需要根據具體的業務需求和數據特點,合理設計索引,權衡查詢性能和數據修改性能,以達到最佳的數據庫性能。
總之,TiDB 全局索引是一個強大且靈活的特性,能夠幫助用戶更好地優化數據庫性能,滿足多樣化的業務需求。在實際應用中,合理使用全局索引,可以顯著提升查詢性能,提高數據庫的整體效率。
)








之結構體、共同體、枚舉、引用、函數重載)



,源碼可白嫖!)





)