目錄
cors解決跨域
依賴注入使用
分層服務注冊
緩存方法使用
內存緩存使用
緩存過期清理
緩存存在問題
分布式的緩存
cors解決跨域
前后端分離已經成為一種越來越流行的架構模式,由于跨域資源共享(cors)是瀏覽器的一種安全機制,它會阻止前端應用向不同域的服務器發起請求,保護用戶的隱私和數據安全。為了在前后端分離的應用中確保前端可以安全地訪問后端的接口,不會受到瀏覽器的跨域限制,這里我們可以通過后端進行相應的cors配置。
首先我們先搭建一下.net core webapi的框架,不了解的可以參考我之前的文章:地址?,然后我們配置了一個登錄的接口,返回的結果是記錄的類型,然后固定了一下登錄成功的用戶和密碼,如下所示:
/// <summary>
/// 登錄驗證
/// </summary>
/// <param name="res"></param>
/// <returns></returns>
public record LoginRequest(string UserName, string Password);
public record ProcessInfo(long Id, string Name, long WorkingSet); // 記錄類型
public record LoginResponse(bool OK, ProcessInfo[]? ProcessInfos);
[HttpPost]
[Route("login/user")] // 特性路由
public LoginResponse Login(LoginRequest res)
{if (res.UserName == "admin" && res.Password == "123456"){var items = Process.GetProcesses().Select(x => new ProcessInfo(x.Id, x.ProcessName, x.WorkingSet64));return new LoginResponse(true, items.ToArray()); // 返回記錄類型}else{return new LoginResponse(false, null);}
}然后我們就需要在入口文件Program.cs中配置一下我們允許要跨域的源,這里我們直接輸入前端運行服務器的域名和端口即可,然后設置允許規則,這里我們正常就都允許,如果想配置部分允許的話,通過With函數進行篩選即可,如下:
// 配置跨域策略
builder.Services.AddCors(options =>
{options.AddDefaultPolicy(builder =>{builder.WithOrigins("http://localhost:3000") // 允許跨域的源.AllowAnyHeader() // 允許任何頭.AllowAnyMethod() // 允許任何方法.AllowCredentials() // 允許攜帶憑證.WithExposedHeaders("X-Custom-Header"); // 暴露自定義頭信息});
});app.UseCors(); // 使用跨域策略
然后前端的話,這里我們就使用react框架通過axios發起請求,不了解react的朋友,可參加我之前的文章:地址 ,然后我們通過如下的一個示例代碼進行請求的發起:
import axios from "axios"
import { useState } from "react"const WebApi = () => {const [userName, setUserName] = useState<string>('')const [password, setPassword] = useState<string>('')const [processInfo, setProcessInfo] = useState<any>([])const reqPost = () => {axios.post('http://localhost:5263/First/login/user', { userName: userName, password: password }).then(res => {if (res.data.ok) {setProcessInfo(res.data.processInfos)} else {alert('登錄失敗, 請重新登錄!')}})}return (<div>賬戶: <input type="text" onChange={(e: any) => setUserName(e.target.value)} /> <br />密碼: <input type="password" onChange={(e: any) => setPassword(e.target.value)} /> <br /><button onClick={() => reqPost()}>發起請求</button>{processInfo.map((item: any) => <div key={item.id}>{item.name}</div>)}</div>)
}export default WebApi最終呈現的效果如下所示:

依賴注入使用
依賴注入通過將對象的創建和管理交給框架,而不是在類內部直接創建,可以有效地解耦各個模塊,使得每個組件都能夠獨立地進行測試和維護。這對于實現前后端分離的架構至關重要,因為它允許開發者更靈活地控制和管理后端服務,使得前端與后端的交互更加清晰、可靠。具體可以參考我之前的文章:地址?,這里不再贅述,然后接下來我們開始演示在WebAPI中如何使用依賴注入:
構造函數注入服務操作:傳統且經典的創建依賴注入
創建服務:這里我們直接可以創建一個兩數相加的服務函數,如下所示:
namespace netCoreWebApi
{public class Calculator{public int Add(int i1, int i2){return i1 + i2;}}
}服務注冊:然后我們在入口文件中進行服務注冊,如下所示:
builder.Services.AddScoped<Calculator>(); // 注冊Calculator服務依賴注入:然后我們在控制器文件中通過構造函數進行服務注入:
using Microsoft.AspNetCore.Mvc;
using netCoreWebApi.WebCore;namespace netCoreWebApi.Controllers
{[ApiController][Route("api/[controller]/[action]")][ApiExplorerSettings(GroupName = nameof(ApiVersionInfo.V1))]public class FirstController : ControllerBase{private readonly Calculator calculator;public FirstController(Calculator calculator){this.calculator = calculator;}[HttpGet]public int Add1(){return calculator.Add(1, 2);}}
}允許項目得到的結果如下所示,果然是3:

低使用頻率服務:一些耗時的依賴注入可能會影響其他接口的調用,這里我們需要使用該注入方式進行解決,一般的接口創建不需要使用該服務,只有調用頻率不高且資源的創建比較消耗資源的服務才會使用
創建服務:這里我們直接可以創建一個比較耗費資源的掃描文件服務函數,如下所示:
namespace netCoreWebApi
{public class SearchService{private string[] files;public SearchService(){this.files = Directory.GetFiles("d:/","*.exe", SearchOption.AllDirectories);}public int Count{get{return this.files.Length;}}}
}服務注冊:然后我們在入口文件中進行服務注冊,如下所示:
builder.Services.AddScoped<SearchService>(); // 注冊SearchService服務依賴注入:然后我們在控制器文件中通過構造函數進行服務注入,把Action用到的服務通過Action的參數注入,在這個參數上標注[FromServices],和Action的其他參數不沖突,只有Action方法才能使用[FromServices],普通的類默認不支持,如下所示:
[HttpGet]
public int Test1([FromServices]SearchService searchService) // 只有請求這個方法時才會注入SearchService
{return searchService.Count;
}如下當請求耗費較多資源的時候,請求時間才會過長,請求其他不耗費資源的接口,正常請求:

分層服務注冊
從上面的依賴服務注冊使用我們可以了解到,當我們想進行依賴注入的使用,都需要在入口文件進行服務的注冊,但是項目一旦龐大起來或者說服務一旦多起來,多人協作開發的時候再要求所有的服務都必須注冊在入口文件中就會導致一些問題的沖突,如下所示就是典型的例子:

這里我們需要對服務注冊進行解耦操作,即進行分層處理。在分層項目中,讓各個項目負責各自的服務注冊,這里我們需要先安裝一下下面這個依賴包:

然后這里我們創建多個類庫,模擬多個服務的使用,然后將這些服務引用到項目上:

然后在每個項目中創建一個或多個實現IModuleInitializer接口的類,然后將服務注冊的函數寫道該接口類當中,如下所示:

然后我們通過反射原理,將服務注冊的函數來映射到入口函數當中,具體代碼如下所示:
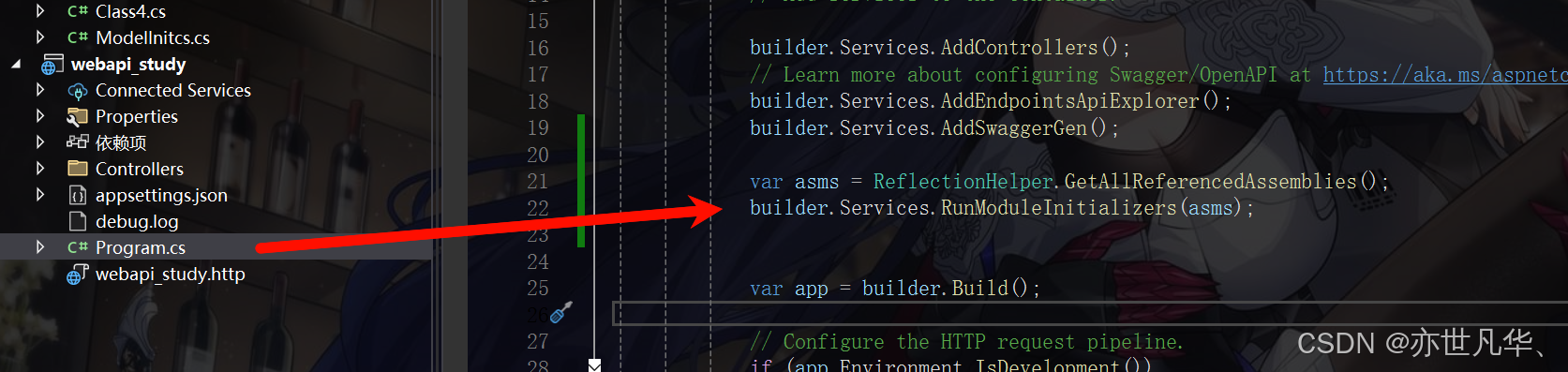
然后我們再次運行項目,發現我們的服務還是成功被運行起來了,如下所示:

緩存方法使用
緩存:是系統優化中簡單又有效的工具,投入小收效大,數據庫中的索引等簡單有效的優化功能本質上都是緩存,其將經常訪問的數據存儲在一個快速訪問的存儲區域(如內存)中,從而減少對數據庫或其他慢速存儲系統的重復訪問。緩存能夠顯著提高應用程序的性能,尤其是在需要頻繁讀取大量數據時。
客戶端響應緩存:RFC7324是HTTP協議中對緩存進行控制的規范,其中重要的是cache-control這個響應報文頭,服務器如果返回cache-control: max-age-60,則表示服務器指示瀏覽器端可以緩存這個響應內容60秒
這里我們只需要給進行緩存控制的控制器的操作方法添加ResponseCache這個Attribute,.net core會自動添加cache-control報文頭,如下所示我們設置了一個獲取當前時間的接口,正常情況下每次請求接口都是最新的時間,這里添加了緩存20秒導致了請求在20秒之內的數據都是不變的:


服務端響應緩存:服務端緩存整個HTTP響應,而不是僅僅緩存其中的數據或部分內容。這樣,服務器可以直接返回已經緩存的響應,而不需要重新處理請求和生成新的響應。服務端響應緩存可以顯著提高性能,特別是在處理重復的請求時。
如果.net core中安裝了響應緩存中間件,那么.net core不僅會繼續根據[ResponseCache]設置來生成cache-control響應報文頭來設置客戶端緩存,而且服務器端也會按照[ResponseCache]的設置來對響應進行服務器端緩存,使用方法如下所示,在入口文件處在app.MapControllers()之前添加app.UseResponseCaching(),請確保如果你的項目如果存在app.UseCors()的話,該函數的調用也要寫在app.UseResponseCaching()之前,如下所示:

注意,如果你勾選了瀏覽器當中的禁用緩存的按鈕,不僅是客戶端,服務器端在請求的時候由于帶上了no-cache,服務器端也會禁用掉所有的緩存:
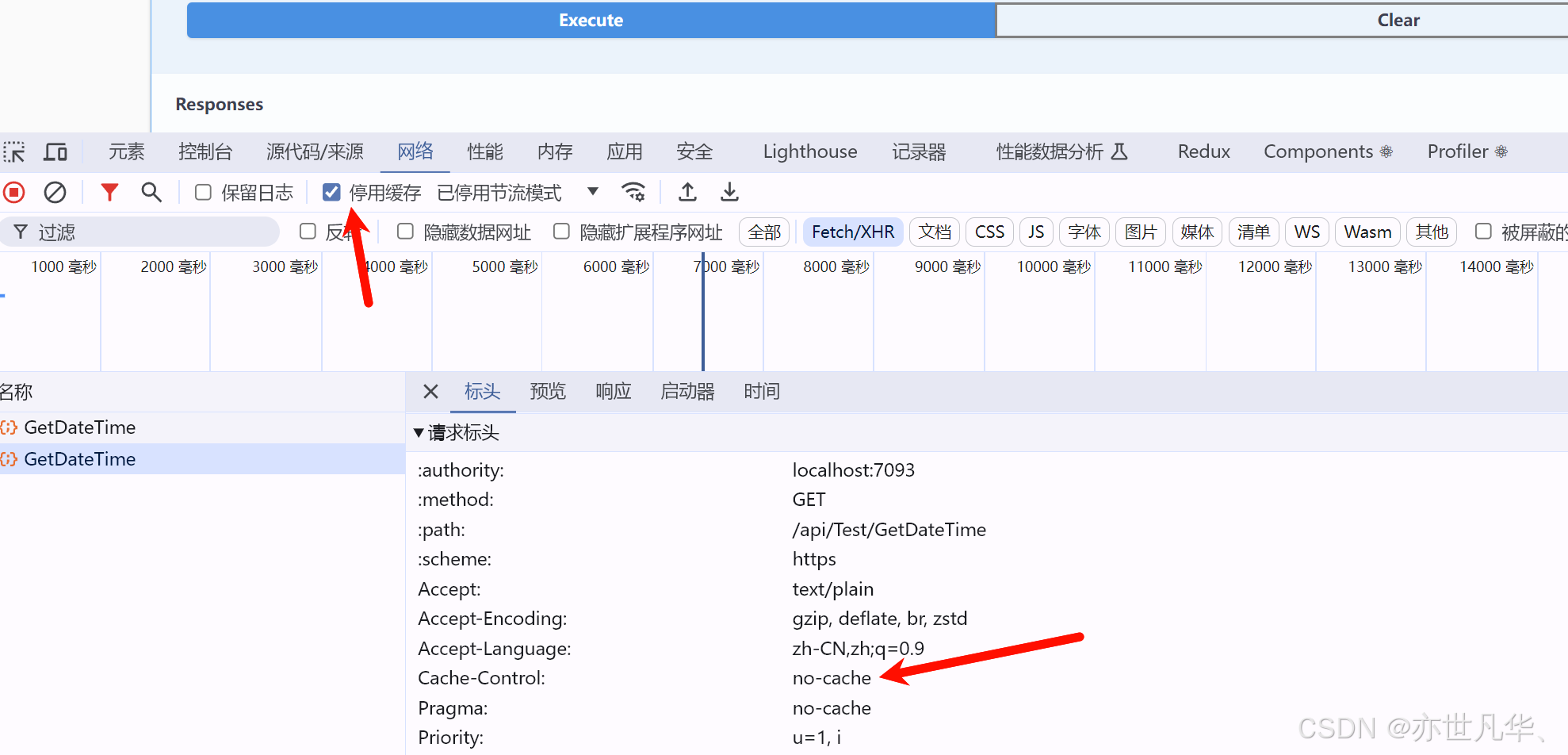
當然服務器緩存還是很雞肋的,它無法解決惡意請求帶給服務器的壓力,服務器響應緩存還有很大的限制,包括但不限于:響應狀態碼為200的GET或者HEAD響應才能被緩存;報文頭中不能含有Authorization、Set-Cookie等,為了解決這些問題我們還需要采用內存或者分布式進行緩存。
內存緩存使用
內存緩存:是指將數據存儲在計算機的內存中以便快速訪問和提高系統性能的一種技術,通常內存緩存用于存儲那些頻繁訪問且計算或獲取成本較高的數據,目的是減少從磁盤或其他慢速存儲設備中讀取數據的次數,從而加速應用程序的響應速度。
內存緩存的數據保存在當前運行的網站程序的內存中,是和進程相關的。因為在Web服務器中多個不同的網站是運行在不同的進程中的,因此不同的網站的內存緩存是不會相互干擾的,而且網站重啟之后內存緩存中的所有數據也就都被清空了。內存緩存的使用方法如下所示:
注冊內存緩存服務:這里我們需要先在入口文件進行內存緩存服務的注冊,如下所示:
builder.Services.AddMemoryCache(); // 添加內存緩存服務這里我們先創建一個MyDbContext來模擬一下數據庫當中的數據,并設置一個函數返回數據:
namespace webapi_study
{public class MyDbContext{public static Task<Book?> GetByIdAsync(long id){var result = GetById(id);return Task.FromResult(result);}public static Book? GetById(long id){switch (id){case 0:return new Book(0, "C#", "張三");case 1:return new Book(1, "Java", "李四");case 2:return new Book(2, "Python", "王五");default:return null;}}}
}接下來我們在控制器的接口中注冊一下緩存服務,通過GetOrCreateAsync函數拿到緩存當中的數據,如果緩存當中沒有數據的話我們就正常請求接口拿到數據即可,如下所示:
using Microsoft.AspNetCore.Mvc;
using Microsoft.Extensions.Caching.Memory;namespace webapi_study.Controllers
{[ApiController][Route("api/[controller]/[action]")]public class TestController : ControllerBase{private readonly IMemoryCache cache; // 注入緩存服務private readonly ILogger<TestController> logger; // 注入日志服務public TestController(IMemoryCache cache, ILogger<TestController> logger){this.cache = cache;this.logger = logger;}[HttpGet]public async Task<ActionResult<Book?>> GetBookById(long id){// 1) 從緩存中獲取數據 2)從數據庫中獲取數據 3)返回給調用者并將數據存入緩存logger.LogInformation($"開始執行GetBookById: {id}");Book? b = await cache.GetOrCreateAsync("book" + id, async (e) =>{logger.LogInformation($"緩存中沒有找到,到數據庫中查一查,id={id}");return await MyDbContext.GetByIdAsync(id);});logger.LogInformation($"GetOrCreateAsync結果是:{id}");if (b == null){return NotFound($"Book with id {id} not found");}else{return b;}}}
}最終呈現的效果如下所示,我們請求兩次接口,第一次請求數據庫中的數據因為沒有緩存數據,所有是請求的接口,第二次是由于緩存中已經存在數據了,我們就直接拿到緩存當中的數據即可:

緩存過期清理
上面我們簡單的介紹了一下內存緩存的簡單使用,但是上面的例子中緩存是不會過期的,除非重啟服務器進行重置操作,但是重置服務器的代價太大了,這里我們需要對在數據改變的時候緩存的處理,如下所示:
手動清理緩存:在數據改變的時候調用Remove或者Set來刪除或修改緩存(優點:及時)
設置過期時間:只要過期時間比較短,緩存數據不一致的清空也不會持續太少時間,可以通過兩種過期時間策略進行:絕對過期時間;滑動過期時間
絕對過期時間:顧名思義就是我設置了一個過期時間,超過這個時間緩存自動被清除,如下所示:

滑動過期時間:顧名思義就是只要在緩存沒過期的時候請求一次,緩存就會自動續命一段時間:

兩種過期時間混用:使用滑動過期時間策略,如果一個緩存項一直被頻繁訪問,那么這個緩存項就會一直被續期而不會過期,可以對一個緩存項同時設定滑動過期時間和絕對過期時間,并且把絕對過期時間設定比滑動過期時間長,這樣緩存項的內容會在絕對過期時間內隨著訪問被滑動續期,但是一旦超過了絕對過期時間,緩存項就會被刪除,如下所示:

總結:無論使用哪種過期時間策略,程序中都會存在緩存不一致的清空,部分系統(博客系統等)無所謂,部分系統不能忍受(比如金融),可以通過其他機制獲取數據源改變的消息,再通過代碼調用IMemoryCache的Set方法更新緩存。
緩存存在問題
在內存緩存中,緩存穿透和緩存雪崩是兩種常見且需要特別注意的問題,下面簡要討論這兩個問題及其解決方法:
緩存穿透:是指查詢的數據在緩存中不存在,并且每次查詢都直接訪問數據庫。通常緩存穿透發生在以下幾種情況:
1)查詢的請求數據根本不在數據庫中(例如,惡意請求或數據不存在)。
2)數據被誤刪除或沒有被正確存入緩存。
造成影響:
1)每次請求都訪問數據庫,導致數據庫負載加重,降低系統性能。
2)緩存無法有效提高訪問速度,因為每次都需要從數據庫中讀取數據。解決方案如下:
緩存空結果:對于一些常見的不存在數據(例如查詢某個ID的數據返回為空),可以將“空”數據也緩存起來。設置一個較短的過期時間防止數據庫不斷查詢相同的無效數據:

緩存雪崩:是指緩存中的大量數據在同一時刻過期或失效,導致大量請求同時訪問數據庫,造成數據庫壓力劇增,甚至崩潰。常見的觸發場景是:
1)大量緩存失效:如果緩存的失效時間設置相同或接近,那么這些緩存項會在同一時刻失效,導致大量請求同時查詢數據庫。
2)數據庫訪問壓力驟增:所有緩存失效后,系統會將大量的請求直接發送到數據庫,從而加重數據庫負載。
造成影響:
1)短時間內大量請求集中訪問數據庫,容易造成數據庫崩潰或性能嚴重下降。
2)數據庫的負載激增,可能導致響應延遲和系統整體性能下降。
解決方案如下:
在基礎過期時間之上再加一個隨機的過期時間:

分布式的緩存
分布式緩存是一種將緩存數據分布在多個節點上的技術,目的是提高系統的可擴展性、可用性和性能。在大型系統中,單一的緩存節點往往無法滿足高并發、高可用的需求,分布式緩存應運而生。
分布式內存緩存:如果集群節點的數量非常多的話,這樣的重復查詢也同樣可能會把數據庫壓垮

分布式緩存服務器: 分布式緩存是指將緩存數據分布到多個不同的服務器節點上,這些節點共同協作提供緩存服務。用戶的請求通過負載均衡的方式訪問不同的緩存節點。常見的分布式緩存技術有:
1)Redis:最流行的分布式緩存系統之一,支持內存存儲和豐富的數據結構。
2)Memcached:另一個常見的分布式緩存,適合簡單的鍵值對緩存場景。
3)Alibaba Tair:阿里巴巴自研的分布式緩存系統,主要服務于大規模的互聯網應用。

.net core中提供了統一的分布式緩存服務器的操作接口IDistributedCache,用法和內存緩存類似,分布式緩存和內存緩存的區別在于:緩存值的類型為byte[],需要我們進行類型轉換,也提供了一些安裝string類型存取緩存值的擴展方法,如下所示:
| 方法 | 說明 |
|---|---|
| Task<byte[]>GetAsync(string key) | 查詢緩存鍵key對應的緩存值,返回值是byte[]類型,如果對應的緩存不存在,則返回null。 |
| Task RefreshAsync(string key) | 刷新緩存鍵key對應的緩存項,會對設置了滑動過期時間的緩存項續期。 |
| Task RemoveAsync(string key) | 刪除緩存鍵key對應的緩存項 |
| Task SetAsync(string key, byte[] value,DistributedCacheEntryOptions options) | 設置緩存鍵key對應的緩存項:value屬性為byte類型的緩存值,注意value不能是null值 |
| Task<string> GetStringAsync(string key) | 按照string類型查詢緩存鍵key對應的緩存值,返回值是string類型,如果對應的緩存不存在則返回null。 |
| Task SetStringAsync(string key. string value,DistributedCacheEntryOptions options) | 設置緩存鍵key對應的緩存項,value屬性為string類型的緩存值,注意value不能是null值。 |
對于用什么做緩存服務器,用SQL Server做緩存其性能并不好;Memcached是緩存專用,性能非常高但是集群、高可用等方面比較弱,而且有”緩存鍵的最大長度為250字節“等限制,可以安裝EnyimMemcachedCore這個第三方NuGet包;Redis不局限于緩存,Redis做緩存服務器比Memcached性能稍差,但是Redis的高可用、集群等方面非常強大,適合在數據量大、高可用性等場合使用,可以按照如下插件進行使用:

然后我們在入口文件進行服務注冊:
builder.Services.AddStackExchangeRedisCache(options =>
{options.Configuration = "localhost:6379"; // 配置連接字符串options.InstanceName = "SampleInstance"; // 配置實例名稱,避免緩存沖突
});然后我們在控制器當中構造分布式緩存的服務:

然后通過GetStringAsync函數構造當前的id,來判斷當前是否存在緩存
[HttpGet]
public async Task<ActionResult<Book?>> GetBookById1(long id)
{Book? book;string? s = await disCache.GetStringAsync("book" + id);if (s == null){book = await MyDbContext.GetByIdAsync(id);await disCache.SetStringAsync("book" + id, JsonSerializer.Serialize(book));}else{book = JsonSerializer.Deserialize<Book?>(s);}if (book == null){return NotFound($"Book with id {id} not found");}else{return book;}
}通過redis服務器可以看到我們的緩存信息:



)



)

使用cv2.blur()函數實現圖像像素均值處理)
介紹)

)





)

