目錄
前言
冪等性設計
冪等性設計處理流程
HTTP 冪等性
消息隊列冪等性 基于kafka?
前言
冪等性設計,就是說,一次和多次請求某一個資源應該具有同樣的副作用。為什么我們要有冪等性操作?說白了,就兩點:1、網絡的不穩定性 2、服務狀態不確定性,服務狀態不僅有成功,失敗,還有超時。超時又有多種原因引起的,有可能是網絡抖動,也有可能是負載引起的。對于這種情況,需要做重試,重試的后果是服務被調用了多次,數據不對,業務當然出問題了。打個比方吧,我們網上購物,去支付時,網絡原因超時,我們做重試,在我們發起重試后,網絡好了,是不是有可能執行了兩次,扣了兩次錢。這樣的情況其實有很多很多,還比如,訂單服務重試,創建了兩個同樣的訂單,等等。
系統超時,而調用方重試一下,給我們的系統帶來不一致的副作用。遇到這樣的情況,有幾種情況處理
-
需要下游系統提供相應的查詢接口。上游系統在 timeout 后去查詢一下。如果查到了,就表明已經做了,成功了就不用做了,失敗了就走失敗流程
-
通過冪等性的方式。也就是說,把這個查詢操作交給下游系統,我上游系統只管重試,下游系統保證一次和多次的請求結果是一樣的
-
可以在一些特殊字段比如訂單號設置成唯一索引,讓數據表自己去判斷
在這幾種處理情況中,第一點主要是需要系統提供查詢接口,第三點是根據數據庫的特性設計。第二點比較比較特殊,我會詳細講解。
以上說的是業務的冪等性,還有HTTP 的冪等性,消息隊列的冪等性主要談論kafka 冪等性的設計。
冪等性設計
冪等性設計,需要有一個唯一的標識,來標志是同一個請求發起的。這個唯一的標識一般會用全局ID,才能做到全局唯一性。那么這個全局ID,怎么分配的。
-
可以有一個中心的發號系統分配,每個請求就先請求發好系統,簡單的業務可以用redis incr 。但是這樣會有很多問題,中心的發號系統會成為系統的瓶頸,每次請求都要去請求發號系統。若設計成集群,那么全局ID 可能會重復,這個方案比較適合流量小,設計成單體系統。
-
為了解決集群ID 沖突問題,們需要使用一個不會沖突的算法,比如使用 UUID 這樣沖突非常小的算法。UUID 占用字符串空間大,索引效率低,生成的ID 太過于隨機,索引為了保證數據的順序性,可能會頁的分裂。
-
在全局唯一 ID 的算法中,這里介紹一個 Twitter 的開源項目 Snowflake。它是一個分布式 ID 的生成算法。它的核心思想是,產生一個 long 型的 ID,
1)41bits 作為毫秒數。大概可以用 69.7 年。
2)10bits 作為機器編號(5bits 是數據中心,5bits 的機器 ID),支持 1024 個實例。
3)12bits 作為毫秒內的序列號。一毫秒可以生成 4096 個序號。
它主要是有幾部分組成:41bits 為毫秒級時間+5bits data center id+5 bits worked id+12 bits 毫秒內的技術
冪等性設計處理流程
方案一:我們可以先通過記錄全局id查詢。每次請求的時候,先去查,沒有的話,就記錄下來,有的話,就不處理請求,這樣每次都必須先查詢。
對于方案一是幾個步驟:1、先查詢全局id 2、插入數據。感覺這個設計保證數據的一致性是很難的。
1、我們把全局ID放在redis中流程圖是這樣的
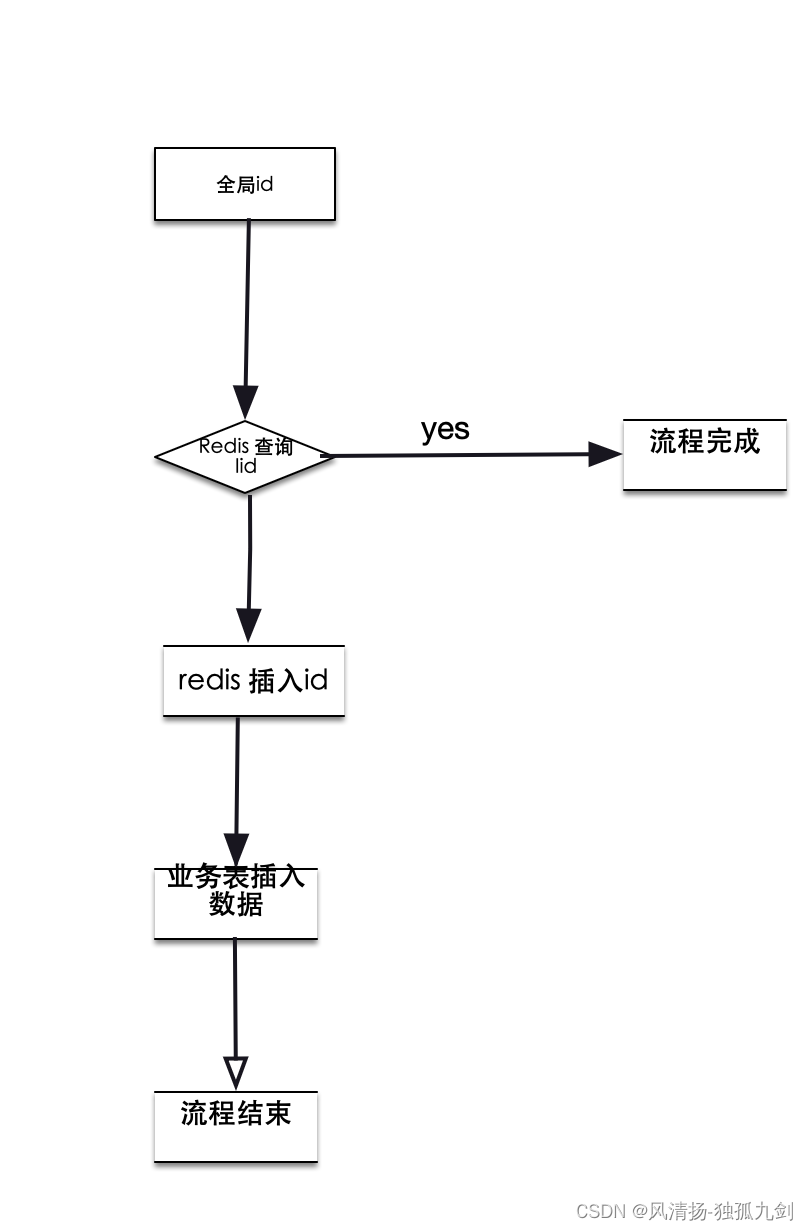
這個妥妥的是有問題的,并發請求,查詢Redis,沒有,都會同時插入數據,舍棄
2、如果直接在數據表,先查詢呢,可能有多個請求同時查詢,沒有,同時插入,也是有問題的。
這種方案需要加入分布式鎖,客戶端與客戶端之間互斥只有一個客戶端能夠操作,加入了分布式鎖無疑增加了系統的復雜度,而且效率也會低的。
方案二、其實我們可以直接用sql 語句操作。對于insert insert into … values … on DUPLICATE KEY UPDATE …
方案三 對于更新來說,如果只是狀態更新,多次操作不會有副作用,是冪等的,比如 update table set status = “paid” where id = xxx and status = “unpaid”; 當然還有mvcc 樂觀鎖去處理,都是可以的,還是建議大家用全局id
HTTP 冪等性
http 有幾個方法:GET、HEAD、OPTIONS、DELETE、POST、PUT ,http 冪等性與這幾個方法有關:
GET 方法用于獲取資源,沒有副作用,是冪等的。比如 url ,不會改變資源的狀態,調用n次返回的都不會改變資源,沒有副作用。因此是冪等的
HTTP HEAD 和 GET 本質是一樣的,區別在于 HEAD 不含有呈現數據,而僅僅是 HTTP 頭信息,不應有副作用,也是冪等的。有的人可能覺得這個方法沒什么用,其實不是這樣的。想象一個業務情景:欲判斷某個資源是否存在,我們通常使用 GET,但這里用 HEAD 則意義更加明確。也就是說,HEAD 方法可以用來做探活使用。
HTTP OPTIONS 主要用于獲取當前 URL 所支持的方法,所以也是冪等的。若請求成功,則它會在 HTTP 頭中包含一個名為“Allow”的頭,值是所支持的方法,如“GET, POST”。
HTTP DELETE 方法用于刪除資源,有副作用,但它應該滿足冪等性。比如:DELETE url,調用一次和 N 次對系統產生的副作用是相同的,即刪掉 ID 為 4231 的帖子。因此,調用者可以多次調用或刷新頁面而不必擔心引起錯誤。
HTTP POST 方法用于創建資源,所對應的 URI 并非創建的資源本身,而是去執行創建動作的操作者,有副作用,不滿足冪等性。比如:POST url?的語義是在 url 下創建一篇帖子,HTTP 響應中應包含帖子的創建狀態以及帖子的 URI。兩次相同的 POST 請求會在服務器端創建兩份資源,它們具有不同的 URI;所以,POST 方法不具備冪等性。
HTTP PUT 方法用于創建或更新操作,所對應的 URI 是要創建或更新的資源本身,有副作用,它應該滿足冪等性。比如:PUT url 的語義是創建或更新 ID 為 4231 的帖子。對同一 URI 進行多次 PUT 的副作用和一次 PUT 是相同的;因此,PUT 方法具有冪等性。
所以,對于 POST 的方式,很可能會出現多次提交的問題,就好比,我們在論壇中發帖時,有時候因為網絡有問題,可能會對同一篇貼子出現多次提交的情況。對此,一般的冪等性的設計如下。
-
首先,在表單中需要隱藏一個 token,這個 token 可以是前端生成的一個唯一的 ID。用于防止用戶多次點擊了表單提交按鈕,而導致后端收到了多次請求,卻不能分辨是否是重復的提交。這個 token 是表單的唯一標識。(這種情況其實是通過前端生成 ID 把 POST 變成了 PUT。)
-
然后,當用戶點擊提交后,后端會把用戶提交的數據和這個 token 保存在數據庫中。如果有重復提交,那么數據庫中的 token 會做排它限制,從而做到冪等性。
-
當然,更為穩妥的做法是,后端成功后向前端返回 302 跳轉,把用戶的前端頁跳轉到 GET 請求,把剛剛 POST 的數據給展示出來。如果是 Web 上的最好還把之前的表單設置成過期,這樣用戶不能通過瀏覽器后退按鈕來重新提交。這個模式又叫做 PRG 模式(Post/Redirect/Get)。
消息隊列冪等性 基于kafka?
生產端:從kafka 0.11.0 版本開始 每個生產端生成一個唯一的ID,在每條消息中生成一個sequence num 進行消息去重,只對在一個生產端內生產的消息有效。也可以在消息內容加個全局id 業務判斷,和上面一樣的。
后續補充



)



)

)
)





)


