JOIN 一直是數據庫性能優化的老大難問題,本來挺快的查詢,一旦涉及了幾個 JOIN,性能就會陡降。而且,參與 JOIN 的表越大越多,性能就越難提上來。
其實,讓 JOIN 跑得快的關鍵是要對 JOIN 分類,分類之后,就能利用各種類型 JOIN 的特征來做性能優化了。
JOIN 分類
有 SQL 開發經驗的同學都知道,絕大多數 JOIN 都是等值 JOIN,也就是關聯條件為等式的 JOIN。非等值 JOIN 要少見得多,而且多數情況也可以轉換成等值 JOIN 來處理,所以我們可以只討論等值 JOIN。
等值 JOIN 主要又可以分為兩大類:外鍵關聯和主鍵關聯。
外鍵關聯是指用一個表的非主鍵字段,去關聯另一個表的主鍵,前者稱為事實表,后者為維表。比如下圖中,訂單表是事實表,客戶表、產品表、雇員表是維表。
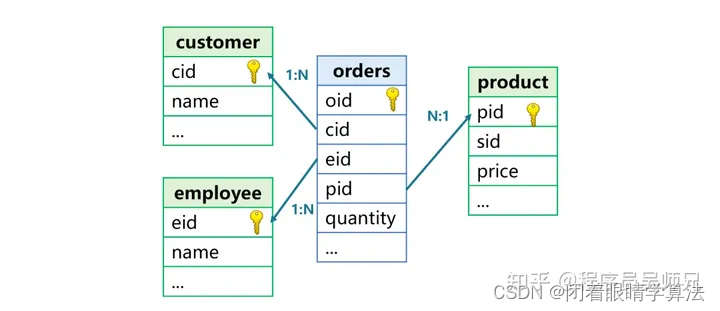
外鍵表是多對一關系,而且是不對稱的,事實表和維表的位置不能互換。需要說明的是,這里說的主鍵是指邏輯上的主鍵,也就是在表中取值唯一、可以用于唯一確定某條記錄的字段(或字段組),不一定在數據庫表上建立過主鍵。
主鍵關聯是指用一個表的主鍵關聯另一個表的主鍵或部分主鍵。比如下圖中客戶和 VIP 客戶、訂單表和訂單明細表的關聯。
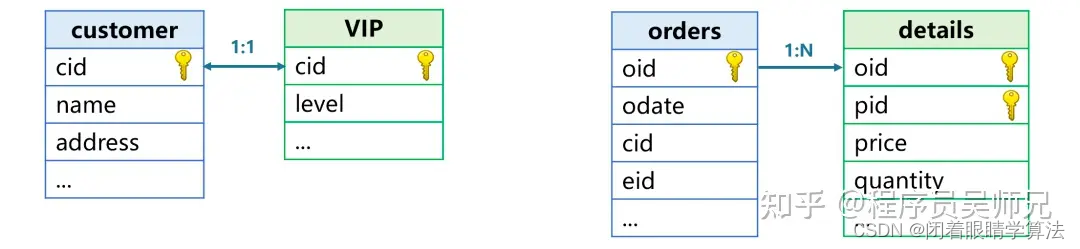
客戶和 VIP 客戶按照主鍵關聯,這兩個表互為同維表。訂單則是用主鍵去關聯明細的部分主鍵,我們稱訂單表是主表,明細表是子表。
同維表是一對一關系。且同維表之間是對稱的,兩個表的地位相同。主子表則是一對多關系,而且是不對稱的,有明確的方向。仔細觀察會發現,這兩類 JOIN 都涉及到主鍵了。
而不涉及主鍵的 JOIN 會導致多對多關系,大多數情況都沒有業務意義。換句話說,上述這兩大類 JOIN 涵蓋了幾乎全部有業務意義的 JOIN。
如果我們能利用 JOIN 總會涉及主鍵這個特征做性能優化,能解決掉這兩大類 JOIN,其實也就意味著解決了大部分 JOIN 性能問題。
但是,SQL 對 JOIN 的定義并不涉及主鍵,只是兩個表做笛卡爾積后再按某種條件過濾。這個定義很簡單也很寬泛,幾乎可以描述一切。
但是,如果嚴格按這個定義去實現 JOIN,也就沒辦法在性能優化時利用主鍵的特征了。SPL 改變了 JOIN 的定義,專門針對這兩大類 JOIN 分別處理,利用了主鍵的特征減少運算量,從而實現性能優化的目標。
下面我們來看看 SPL 具體是怎么做的。
外鍵關聯
如果事實表和維表都不太大,可以全部裝入內存,SPL 提供了外鍵地址化方法:先把事實表中的外鍵字段值轉換為對應維表記錄的地址,之后引用維表字段時,就可以用地址直接取出了。
以前面的訂單表、雇員表為例,假定這兩個表已經被讀入內存。外鍵地址化的工作機制是這樣的:對于訂單表某記錄 r 的 eid 字段,到雇員表中找到這個 eid 字段值對應的記錄,得到其內存地址 a,再將 r 的 eid 字段值替換成 a。對訂單表的所有記錄都做好這樣的轉換,就完成了外鍵地址化。
這時候,訂單表記錄 r 要引用雇員表字段時,直接用 eid 字段存儲的地址 a 取出雇員表記錄和字段就可以了,相當于常數時間內就能取得雇員表的字段,不需要再到雇員表做查找。可以在系統啟動時把事實表和維表讀入內存,并一次性做好外鍵地址化,即預關聯。
這樣,在后續關聯計算時就能直接用事實表外鍵字段中的地址去取維表記錄,完成高性能的 JOIN 計算。外鍵地址化和預關聯的詳細原理請參考:http://c.raqsoft.com.cn/article/1616970721547
SQL 通常使用 HASH 算法來做內存連接,需要計算 HASH 值和比對,性能會比直接用地址讀取差很多。
SPL 之所以能實現外鍵地址化,是利用了維表的關聯字段是主鍵這一特征。上面例子中,關聯字段 eid 是雇員表的主鍵,具有唯一性。
訂單表中的每個 eid 只會唯一對應一條雇員記錄,所以才能把每個 eid 轉換成它唯一對應的那條雇員記錄的地址。而 SQL 對 JOIN 的定義中沒有主鍵的約定,就不能認定與事實表中外鍵關聯的維表記錄有唯一性,有可能發生與多條記錄關聯的情況。
對于訂單表的記錄來講,eid 值沒有辦法唯一對應一條雇員記錄,就無法做到外鍵地址化了。而且 SQL 也沒有記錄地址這種數據類型,結果會導致每次關聯時還是要計算 HASH 值并比對。
只是兩個表 JOIN 時,外鍵地址化和 HASH 關聯的差別還不是非常明顯。這是因為 JOIN 并不是最終目的,JOIN 之后還會有其它很多運算,JOIN 本身運算消耗時間的占比相對不大。但事實表常常會有多個維表,甚至維表還會有很多層。比如訂單關聯產品,產品關聯供應商,供應商關聯城市,城市關聯國家等等。在關聯表很多時,外鍵地址化的性能優勢會更明顯。
下面的測試,在關聯表個數不同的情況下對比 SPL 與 Oracle 的性能差異,可以看出在表很多時,外鍵地址化的優勢相當明顯:
測試的詳細情況請參考:性能優化技巧:預關聯。
對于只有維表能裝入內存,而事實表很大需要外存的情況,SPL 提供了外鍵序號化方法:預先將事實表中的外鍵字段值轉換為維表對應記錄的序號。
關聯計算時,分批讀入新事實表記錄,再用序號取出對應維表記錄。
以上述訂單表、產品表為例,假定產品表已經裝入內存,訂單表存儲在外存中。外鍵序號化的過程是這樣:先讀入一批訂單數據,設其中某記錄 r 中的 pid 對應的是內存中產品表的第 i 條記錄。
我們要將 r 中的 pid 字段值轉換為 i。對這批訂單記錄都完成這樣的轉換后,再做關聯計算時,從外存中分批讀入訂單數據。
對于其中的記錄 r,就可以直接根據 pid 值,去內存中的產品表里用位置取出相應的記錄,也避免了查找動作。
外鍵序號化原理更詳細的介紹參考:http://c.raqsoft.com.cn/article/1617144101332
數據庫通常會把小表讀入內存,再分批讀入大表數據,用哈希算法做內存連接,需要計算哈希值和比對。而 SPL 使用序號定位是直接讀取,不需要進行任何比對,性能優勢比較明顯。雖然預先把事實表的外鍵字段轉換成序號需要一定成本,但這個預計算只需要做一次,而且可以在多次外鍵關聯中得到復用。SPL 外鍵序號化同樣利用了維表關聯字段是主鍵的特征。
如前所述,SQL 對 JOIN 的定義沒有主鍵的約定,無法利用這一特征做到外鍵序號化。另外,SQL 使用無序集合的概念,即使我們事先把外鍵序號化了,數據庫也無法利用這個特點,不能在無序集合上使用序號快速定位的機制,最快也就是用索引查找。
而且,數據庫并不知道外鍵被序號化了,仍然會去計算 HASH 值和比對。下面這個測試,在不同并行數情況下,對比 SPL 和 Oracle 完成大事實表、小維表關聯計算的速度,SPL 跑的比 Oracle 快 3 到 8 倍。
測試結果見下圖:
這個測試更詳細的信息請參考:性能優化技巧:外鍵序號化。
如果維表很大也需要外存,而事實表較小能裝入內存,SPL 則提供了大維表查找機制。
如果維表和事實表都很大,SPL 則使用單邊分堆算法。對于維表過濾后再關聯的情況,SPL 提供了索引復用方法及對位序列等方法。
數據量大到需要分布式計算時,如果維表較小,SPL 采用復寫維表機制,將維表在集群節點上復制多份;如果維表很大,則采用集群維表方法以保證隨機訪問。這兩種方法都可以有效的避免 Shuffle 動作。相比而言,SQL 體系下不能區分出維表,HASH 拆分方法要將兩個表都做 Shuffle 動作,網絡傳輸量要大得多。
主鍵關聯
主鍵關聯涉及的表一般都比較大,需要存儲在外存中。SPL 為此提供了有序歸并方法:預先將外存表按照主鍵有序存儲,關聯時順序取出數據做歸并計算。
以客戶和 VIP 客戶兩個表做內連接為例,假設已經預先將兩個表按照主鍵 cid 有序存儲在外存中。關聯時,從兩個表的游標中讀取記錄,逐條比較 cid 值。如果 cid 相等,則將兩表的記錄合并成結果游標的一條記錄返回。如果不相等,則 cid 小的那個游標再讀取記錄,繼續判斷。重復這些動作直到任何一個表的數據被取完,返回的游標就是 JOIN 的結果。
對于兩個大表關聯,數據庫通常使用哈希分堆算法,復雜度是乘法級的。而有序歸并算法復雜度是加法級,性能會好很多。而且,數據庫做大數據的外存運算時,哈希分堆會產生緩存文件的讀寫動作。有序歸并算法則只需要對兩個表依次遍歷,不必借助外存緩存,可以大幅降低 IO 量,有巨大的性能優勢。
預先按照主鍵排序的成本雖高,但是一次性做好即可,以后就總能使用歸并算法實現 JOIN,性能可以提高很多。同時,SPL 也提供了在有追加數據時仍然保持數據整體有序的方案。
這類 JOIN 的特征在于關聯字段是主鍵或部分主鍵,有序歸并算法正是根據這個特征來設計的。因為不管是同維表還是主子表,關聯字段都不會是主鍵之外的其他字段,所以我們將關聯表按照主鍵有序這一種方式排序存儲就可以了,不會出現冗余。而外鍵關聯就不具備這個特征,不能使用有序歸并。具體來說,是因為事實表的關聯字段不是主鍵,會存在多個要參與關聯的外鍵字段,我們不可能讓同一個事實表同時按多個字段都有序。
SQL 對 JOIN 的定義不區分 JOIN 類型,不假定某些 JOIN 總是針對主鍵的,就沒辦法從算法層面上利用主鍵關聯的特征。而且,前面說過 SQL 基于無序集合概念,數據庫不會刻意保證數據的物理有序性,很難實施有序歸并算法。
有序歸并算法的優勢還在于易于分段并行。以訂單和訂單明細按 oid 關聯為例,假如將兩表都按照記錄數大致平均分為 4 段,訂單第 2 段的 oid 有可能會出現在明細第 3 段,類似的錯位會導致錯誤的計算結果。SPL 再次利用主鍵 oid 的有序性,提供同步分段機制,解決了這個問題:先將有序的訂單表分為 4 段,再找到每一段起止記錄的 oid 值形成 4 個區間,將明細表也分成同步的 4 段。這樣,在并行計算時兩表對應分段就不會出現錯位了。由于明細表也對 oid 有序,可以迅速地按照起止 oid 定位,不會降低有序歸并的性能。
有序歸并和同步分段并行的原理,詳見:SPL 有序歸并關聯 http://c.raqsoft.com.cn/article/1647665012651
傳統的 HASH 分堆技術實現并行就比較困難了,多線程做 HASH 分堆時需要同時向某個分堆寫出數據,造成共享資源沖突;而下一步實現某組分堆關聯時又會消費大量內存,無法實施較大的并行數量。
實際測試證明,在相同情況下,我們對兩個大表做主鍵關聯測試(詳情參見性能優化技巧:有序歸并),結果是 SPL 比 Oracle 快了近 3 倍:
除了有序歸并,SPL 還提供了很多高性能算法,全面提高主鍵關聯 JOIN 的計算速度。包括:附表機制,可以將多表一體化存儲,減少存儲數據量的同時,還相當于預先完成了關聯,不需要再比對了;關聯定位算法,實現先過濾再關聯,可以避免全表遍歷,獲得更好的性能等等。
當數據量繼續增加,需要多臺服務器集群時,SPL 提供復組表機制,將需要關聯的大表按照主鍵分布到集群節點上。相同主鍵的數據在同一節點,避免分機之間的數據傳輸,也不會出現 Shuffle 動作。
回顧與總結
回顧上面兩大類、各場景 JOIN,采用 SPL 分情況提供的高性能算法,可以利用不同類型 JOIN 的特征提速,讓 JOIN 跑得更快。SQL 對上述這么多種 JOIN 場景籠統的處理,就沒辦法針對不同 JOIN 的特征來實施這些高性能算法。比如:事實表和維表都裝入內存時,SQL 只能按照鍵值計算 HASH 和比對,無法利用地址直接對應;SQL 數據表無序,在大表按照主鍵關聯時無法做到有序歸并,只能使用 HASH 分堆,有可能會出現多次緩存的現象,性能有一定的不可控性。
并行計算方面,SQL 單表計算時還容易做到分段并行,多表關聯運算時一般就只能事先做好固定分段,很難做到同步動態分段,這就難以根據機器的負載臨時決定并行數量。
對于集群運算也是這樣,SQL 在理論上不區分維表和事實表,要實現大表 JOIN 就會不可避免地產生占用大量網絡資源的 HASH Shuffle 動作,在集群節點數太多時,網絡傳輸造成的延遲會超過節點多帶來的好處。
SPL 設計并應用了新的運算和存儲模型,可以在原理和實現上解決 SQL 的這些問題。對于 JOIN 的不同分類和場景,程序員有針對性的采取上述高性能算法,就能獲得更快的計算速度,讓 JOIN 跑得更快。
SPL下載地址:集算器 (SPL) 最新版發布啦『發布日期 20220402』 - 乾學院
SPL開源地址:https://github.com/SPLWare/esProc
SPL近年引用最高論文


)







字符串:重復的子字符串(leetcode459))




)



