引言:探索語言智能的新邊界
在人工智能的發展歷程中,語言智能始終是一個核心的研究領域。隨著大語言模型(LLM)的興起,我們對語言智能的理解和應用已經邁入了一個新的階段。這些模型不僅能夠理解和生成自然語言,還能夠在多種環境中控制代理(agent)進行交互和決策。然而,盡管LLM在理解語言和規劃方面展現出了巨大的潛力,它們在從經驗中學習并改進行動策略方面仍存在限制。
傳統的強化學習方法通過試錯學習來訓練代理策略,但這種方法往往忽略了代理在特定環境中的先驗知識。而LLM正是在這方面表現出了優勢。然而,直接對大規模的LLM進行策略模型微調在實踐中是不切實際的,因此研究者們開始探索如何將歷史交互融入提示中,以利用過去的經驗來規劃未來的行動。這些方法雖然有其局限性,但也提供了新的思路。
本文提出了一種新的學習范式,即通過學習擴展和精細化行動空間,使任務與代理的規劃能力更加緊密對齊。研究者通過適應LLM的規劃來解決固定行動空間帶來的限制,例如常識知識引導的規劃與行動之間的不匹配,以及由于未滿足的先決條件或無效策略導致的行動錯誤。研究者們的方法不僅緩解了語言代理性能的瓶頸,還允許跨不同任務轉移經驗。
為了更具體地說明該方法,研究者們將介紹LearnAct框架,它旨在動態生成新的行動類型作為API,并通過反饋循環不斷精煉行動。實驗結果表明,LearnAct通過迭代精煉,不僅創造了復雜且用戶友好的行動類型,而且相較于以往的方法,實現了更有效和高效的學習。
論文標題: Empowering Large Language Model Agents through Action Learning
論文鏈接:https://arxiv.org/pdf/2402.15809.pdf
LearnAct框架介紹:動態生成新的行動類型
1. LearnAct的核心理念與目標
LearnAct框架的核心理念是通過學習擴展和精煉行動空間,從而更緊密地與代理的規劃能力相結合。與傳統的語言模型代理不同,LearnAct不僅僅在預設的行動空間內操作,而是通過經驗學習自然地擴展其行動類型。
這種方法解決了固定行動空間帶來的限制,例如常識知識引導的規劃與行動之間的不匹配,以及由于未滿足的先決條件或無效策略導致的行動錯誤。
-
例如,在制作雞尾酒的任務中,LearnAct允許LLM自然地指導代理按特定順序收集所有組件并混合它們,而封閉的行動空間可能只涉及基本操作,如移動到不同地點和抓取瓶子,這大大增加了LLM代理的任務難度。
LearnAct通過動態生成新的行動類型作為API,利用LLM的廣泛先驗知識和代碼生成能力來設計一個多樣化和具有代表性的行動空間。此外,LearnAct的迭代學習策略通過反饋循環不斷精煉行動,每個周期中,LLM使用訓練示例評估當前行動的有效性,識別并糾正失敗實例中的錯誤。
2. LearnAct的行動類型生成與迭代學習策略
LearnAct生成新的行動類型基于原子行動,以實現更具信息性和適用性的行動,類似于分層強化學習中的做法。不同于傳統的分層強化學習,LearnAct不僅使用基于代碼的行動空間,提供了更強的能力,還避免了嚴格的兩級結構,而是使用靈活的混合級別行動。
LearnAct的行動類型生成涉及兩個步驟:
-
首先,LLM被提示總結高級行動以完成任務,并以Python函數的形式為代理生成。這些函數可以調用多個基本或定義的行動來完成子任務。生成后,函數被解析并添加到行動空間中。
-
其次,生成新的行動函數后,研究者更新代理關于它們潛在應用的信息。基本指令包含行動描述和使用示例,更新后的策略指導包括每個函數的描述和使用示例。
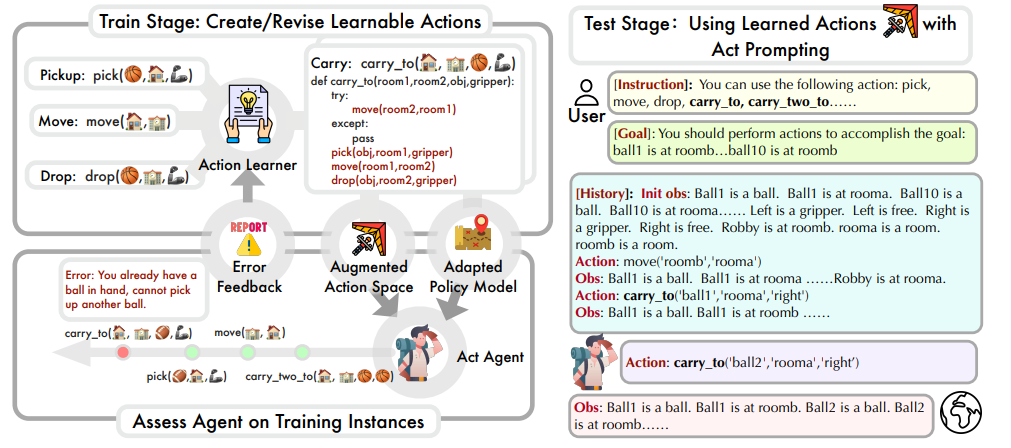
( 圖為LearnAct的訓練和測試階段示意圖)
在學習階段,代理首先嘗試用當前可用的行動空間和策略指令解決訓練集中的問題,然后通過選擇錯誤案例和行動學習操作來識別行動失敗,并迭代更新行動集,直到成功解決所有實例中的行動錯誤或超過最大優化步驟。
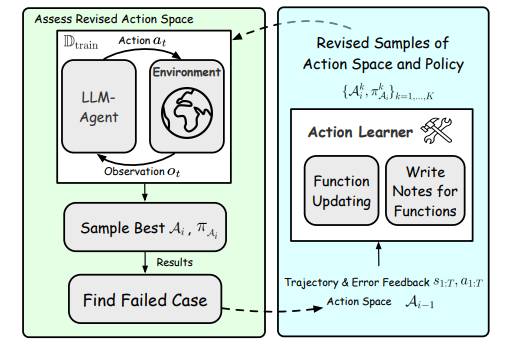
(在學習階段,代理的動作使用和動作優化被重復執行)
行動學習通過實現函數更新或編寫注釋來解決錯誤,函數更新精煉Python函數以糾正對任務的誤解和忽視,而編寫注釋則增強函數的描述,以指導代理更準確地使用行動。
LearnAct的實驗設計:挑戰與任務設置
1. 機器人規劃任務
在機器人規劃任務中,研究者在四個具有挑戰性的任務上進行了實驗,包括Gripper、Blockworld、Barman和Tyreworld。這些任務涉及長期機器人規劃問題,例如根據客戶訂單使用可用成分和容器制作雞尾酒,使用兩個夾具在不同房間之間移動物體,或重新排列一堆積木以達到指定的目標配置。這些任務對代理的長期規劃能力提出了重大要求。
2. 家庭環境任務
研究者還在AlfWorld任務上測試了代理,這些任務模擬了家庭環境中的六種目標。例如,代理需要在房子里找到一個蘋果,加熱它,然后將它放在目標區域。這些任務要求代理系統地探索房子,因為在代理觀察到特定位置之前,環境的完整狀態保持未知。此外,代理執行完成任務所需的基本步驟的能力至關重要。
LearnAct與現有方法的比較
1. 行動學習與語言智能的結合
LearnAct框架的提出,是為了解決現有大語言模型(LLM)控制的語言代理在學習經驗方面的局限性。
-
傳統的強化學習范式通過試錯來學習代理策略,而LearnAct則通過生成新的動作類型作為API,利用LLM的廣泛先驗知識和代碼生成能力,來構建一個多樣化且具代表性的動作空間。
-
與此同時,LearnAct采用迭代學習策略,通過反饋循環不斷完善動作。這種方法不僅創造了復雜且用戶友好的動作類型,而且與先前的方法如Reflexion相比,實現了更有效和高效的學習。
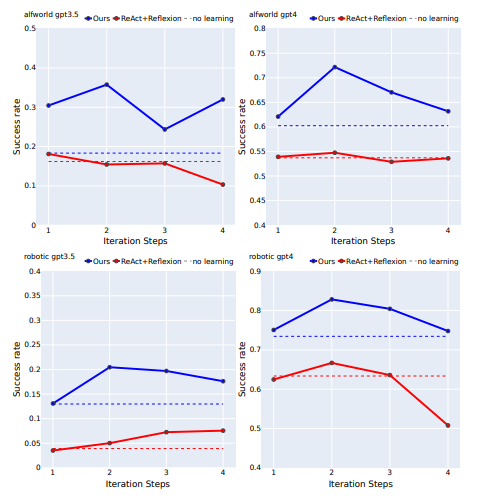
(圖為不同最大學習迭代步數的性能)
2. LearnAct在不同任務中的表現
在實驗中,LearnAct在機器人規劃和AlfWorld任務中的表現明顯優于其他基線模型。這表明,通過在動作空間內學習,LearnAct能夠顯著提高代理的性能。與直接在開環中生成代碼的CodeAsPolicy方法和缺乏迭代動作學習的Voyager方法相比,LearnAct的動作學習對于提高動作質量至關重要。
學習過程分析:行動的可靠性與實用性
1. 行動學習前后的變化
通過對比學習前后動作的使用頻率和準確性,可以看出學習后的動作在可靠性和實用性上有了顯著提升。這是因為LearnAct的學習方法專注于糾正使用過程中遇到的錯誤。此外,動作的使用率在學習后也有所提高,這可能是因為代理在認識到這些動作的有效性后更傾向于使用它們。
2. 行動學習對性能的影響
LearnAct的學習過程通過動作的可靠性和實用性提高了代理的性能。在學習迭代的過程中,代理首先嘗試用當前可用的動作空間和策略指令解決訓練集中的問題,然后通過選擇錯誤案例和動作學習來修正錯誤,直到成功解決所有實例或達到最大優化步驟。學習算法的各個組成部分,包括更新函數和編寫注釋,以及學習過程中的采樣,都對提高性能起到了關鍵作用。
LearnAct的學習算法:功能更新與注釋編寫
1. 學習算法的關鍵組成部分
LearnAct的學習算法是一種新穎的學習范式,旨在通過擴展和細化動作空間來提升LLM代理的性能。這種方法的核心在于動態生成新的動作類型,這些動作類型以Python函數的形式出現,利用LLM的廣泛先驗知識和代碼生成能力來設計一個多樣化且具有代表性的動作空間。
通過這種方式,LearnAct不僅能夠解決固定動作空間帶來的限制,比如常識知識引導的規劃與動作之間的不匹配,還能夠跨不同任務轉移經驗。

在LearnAct的學習算法中,關鍵的組成部分包括:
-
動作創建:通過生成新的動作函數,LearnAct能夠讓LLM與環境更加無縫地交互。這些動作函數能夠調用多個基礎或已定義的動作來完成子任務,從而實現更復雜的邏輯表達。
-
策略指令生成:生成新動作函數后,需要更新代理的策略指令,以包含每個函數的描述和使用示例,從而指導LLM在適當的場景中使用新動作。
-
基于錯誤反饋的動作學習:在創建初始動作集后,可能存在錯誤或對任務的誤解。LearnAct通過試錯的訓練階段,讓語言模型通過反饋循環不斷地完善動作,包括修正函數或編寫注釋。
2. 學習算法的實際應用與效果
LearnAct的學習算法在實際應用中展現了顯著的效果。在一系列的實驗中,LearnAct通過迭代細化的方法,不僅創建了復雜且用戶友好的動作類型,而且與先前的最先進方法相比,實現了更有效和高效的學習。例如上文中所述的制作雞尾酒的任務。
在機器人規劃和AlfWorld任務中,LearnAct的表現顯著優于其他基線模型,無論是使用GPT-3.5 Turbo還是GPT-4作為后端。這些結果證明了LearnAct在動作空間學習方面的重要性,以及其在開發更智能和能力更強的LLM代理方面的潛力。
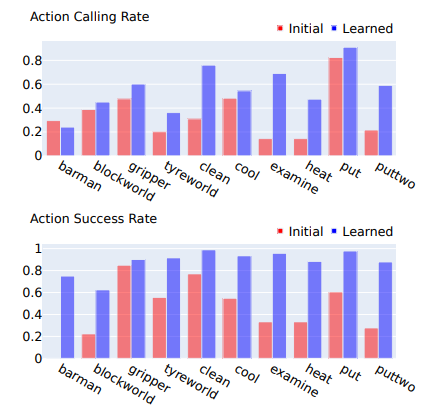
(圖為學習前后所學動作的使用頻率和準確性)
結論:LearnAct的貢獻與未來展望
LearnAct通過其創新的學習算法,為大語言模型代理提供了一種新的能力:通過直接與環境互動來學習和完善動作。這種開放式的動作學習方法與人類獲取和增強技能的方式密切相關。實驗結果表明,LearnAct在機器人規劃和AlfWorld環境中的成功應用,凸顯了動作學習在發展更智能和能力更強的LLM代理方面的巨大潛力。
未來,我們期望LearnAct能夠進一步提升其學習算法,以更好地適應各種復雜的任務和環境。隨著LLM技術的不斷進步,LearnAct有望在多個領域中發揮更大的作用,從而推動智能代理的發展和應用。



背包dp)



)





)





-基于RDKit描述符的分子從頭設計DOCK_D3N)


