大模型ChatGLM-6B實現本地部署
- 一、寫在前面:
- 二、ChatGLM-6B下載:
- 三、項目所需要的環境配置:
- 四、項目運行:
- 五、遇到的主要問題及解決
一、寫在前面:
1、 確保你的電腦中已安裝git,git lfs。
2、確保你的電腦滿足以下任一一種配置:
(1)內存不低于32G,大顯存顯卡無要求。
(2)內存不低于16G,顯存不低于8G。
3、若滿足2(2),則請確保你的顯卡驅動和cuda、cudnn已經安裝,并且相互之間版本對應。若滿足2(1),則跳過3往下看。
二、ChatGLM-6B下載:
下載主要下載兩部分,項目代碼下載和模型權重下載。
1、項目代碼下載地址:https://github.com/THUDM/ChatGLM-6B/
2、模型權重下載:本次下載的時INT4量化的模型方法如下,按照以下三個步驟完成下載:
(1)第一步:模型依賴文件下載:
進出ChatGLM-6B目錄下,運行以下命令(官方提供的命令中,鏡像地址是:https://huggingface.co,而這個地址我們很難訪問,所以,把這個鏡像地址換成:https://hf-mirror.com,就變成了下面這條命令):
GIT_LFS_SKIP_SMUDGE=1 git clone https://hf-mirror.com/THUDM/chatglm-6b-int4
執行完成后在你當前目錄下,會產生如下圖所示的文件夾,文件夾中是加載模型的依賴文件。
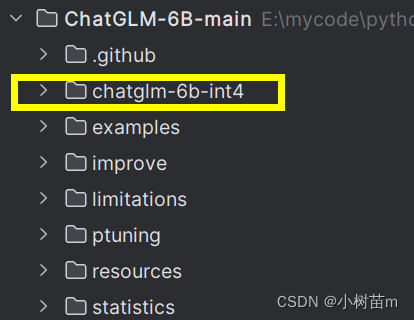
(2)第二步:模型權重下載:
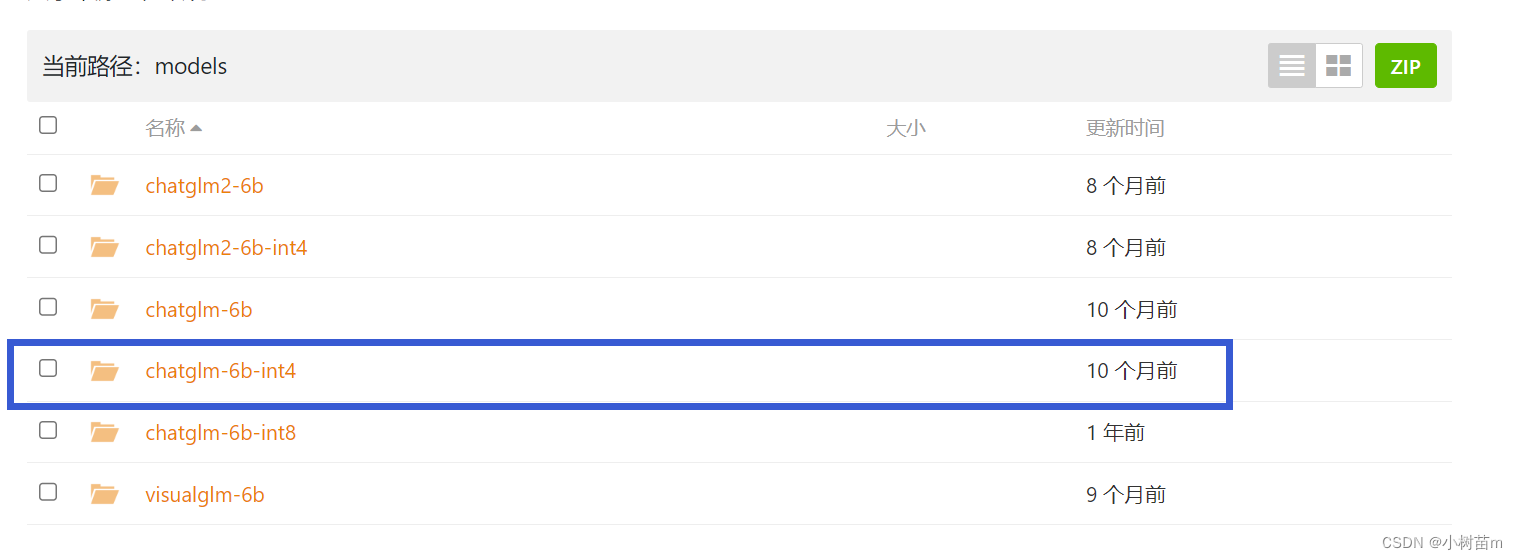
模型參數下載地址:https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/,進去之后,頁面如下圖所示,將藍色框里面的文件全部下載下來。
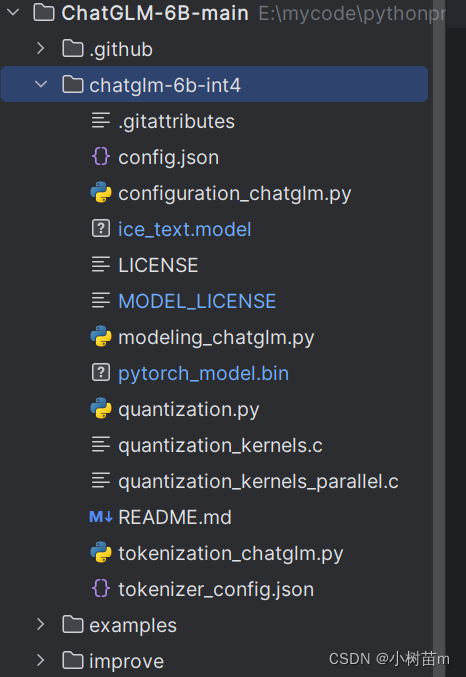
(3)第三步:將第二步下載的所有文件,復制到第一步中所產生的文件夾(chatglm-6b-int4)中,就變成了如下這樣:
三、項目所需要的環境配置:
常規操作,安裝requirements.txt文件即可,命令如下:
pip install -r requirements.txt
四、項目運行:
在主項目目錄下新建一個py文件,寫入代碼如下:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("chatglm-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm-6b-int4", trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你是誰", history=[])
print(response)
五、遇到的主要問題及解決
問題1:下載模型、模型配置文件時,官方提供的很多命令無法下載,愿意是官方提供的鏡像地址是https://huggingface.co,我們無法訪問。
解決:我找到了新的鏡像地址:https://hf-mirror.com。將下載時鏈接地址里面有:https://huggingface.co的全部換成:https://hf-mirror.com。
問題2:啟動項目時,有時會直接退出,這是因為你上次執行時,系統還沒有釋放資源,雖然你自己去看的時候已經釋放資源了,其實沒有釋放完全。這種情況在windows中比較常見,Linux中從未遇到過。
解決:重新釋放資源,或著重啟。


函數)
















