文章目錄 專欄導讀 背景 測試代碼 數據分析 將獲取鏈接再獲取文章內容 寫入word 完整代碼 總結
????本文已收錄于《Python基礎篇爬蟲》 ????本專欄專門針對于有爬蟲基礎準備的一套基礎教學,輕松掌握Python爬蟲,歡迎各位同學訂閱,專欄訂閱地址:點我直達 ????此外如果您已工作,如需利用Python解決辦公中常見的問題,歡迎訂閱《Python辦公自動化》專欄,訂閱地址:點我直達
由于我最近想學習關于人民網的一些信息,我看到頁面有三個模塊,分別是【最新】【國內】【國際】,于是我想獲取這三個模塊的文章,并寫入word文檔中
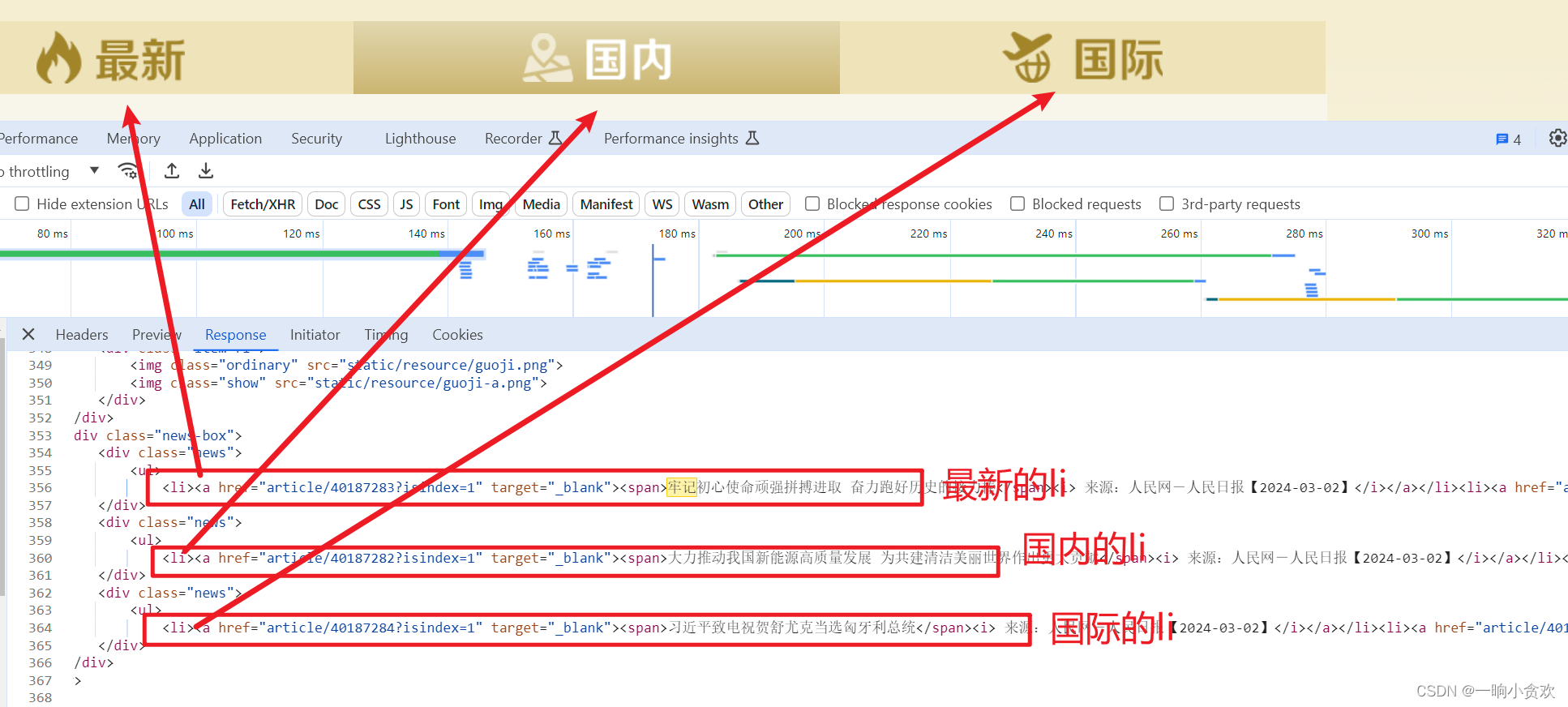
1、首先我們發現請求響應的返回不在【Response】中,而是直接在網頁中
2、我們發現網頁中有三個【li】標簽,分別表示【最新】【國內】【國際】中的文章url
3、所以我們決定此次爬蟲應該是用 lxml+xpath 比較合適,說干就干!
url: http://jhsjk.people.cn/
無
'''
@Project :人民網爬蟲
@File :main_.py
@IDE :PyCharm
@Author :一晌小貪歡(278865463@qq.com)
@Date :2024/3/3 11:54
'''
import jsonimport requestsurl = 'http://jhsjk.people.cn/' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36' } res_data= requests. post( url= url, headers= headers)
res_data. encoding = "utf-8"
print ( res_data. text)
我們看見每一個 文章鏈接在a標簽中 ,文章標題在span標簽中
知道這個就好辦了!
先利用lxml獲取所有的【li】
news_data = tree. xpath( '//div[@class="news-box"]//div[@class="news"]//ul//li' )
獲取文章鏈接
url_data = i. xpath( 'a/@href' ) [ 0 ]
獲取標題
title = i. xpath( 'a/span' )< 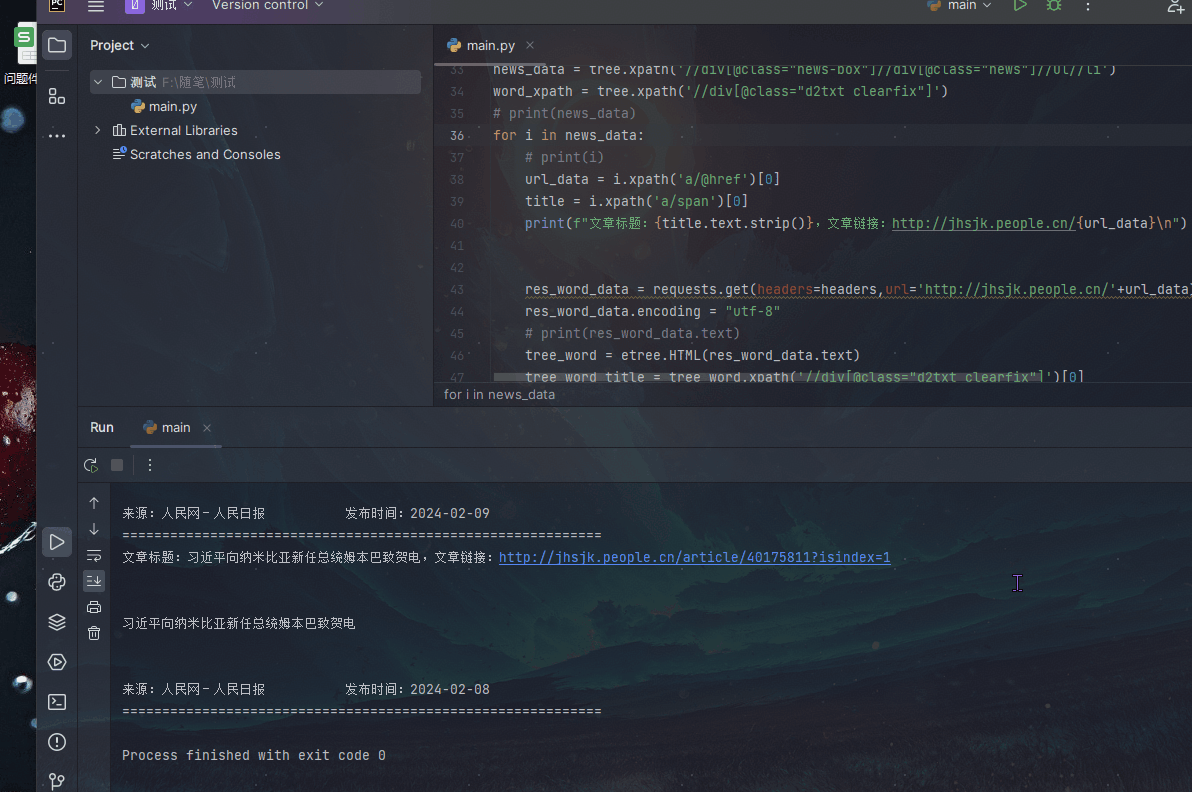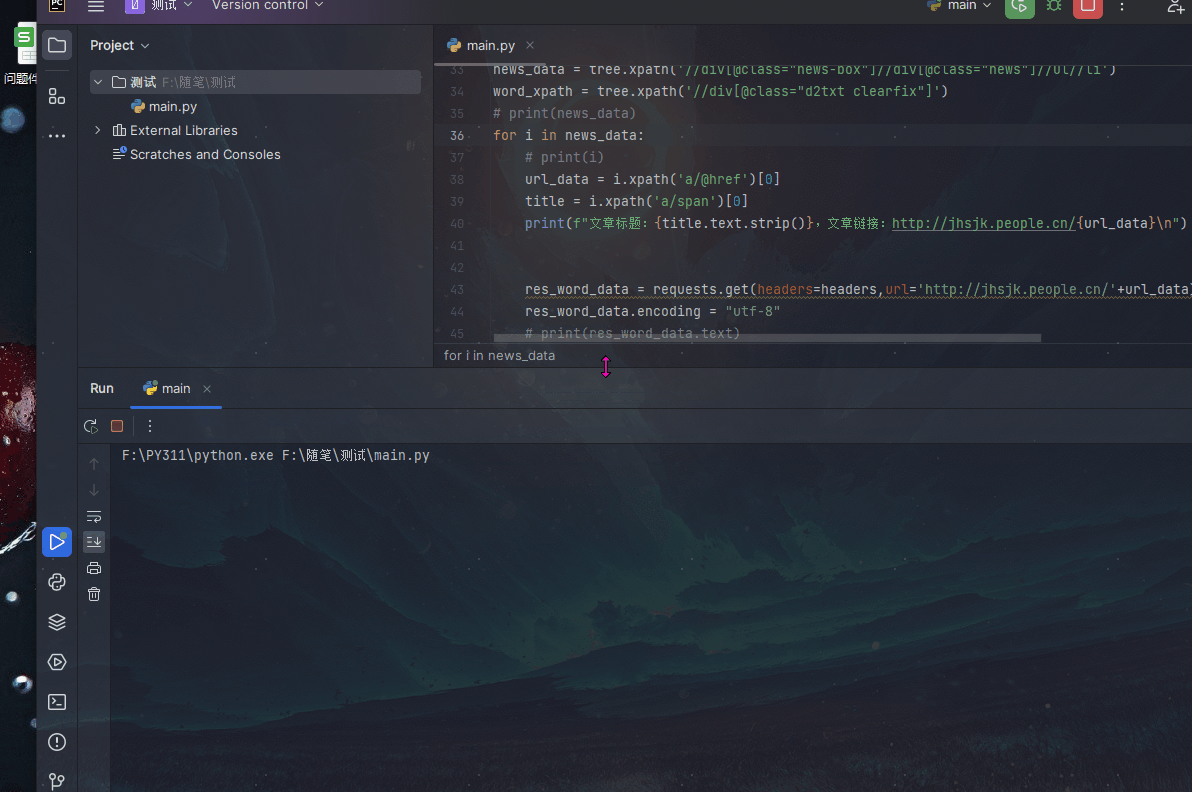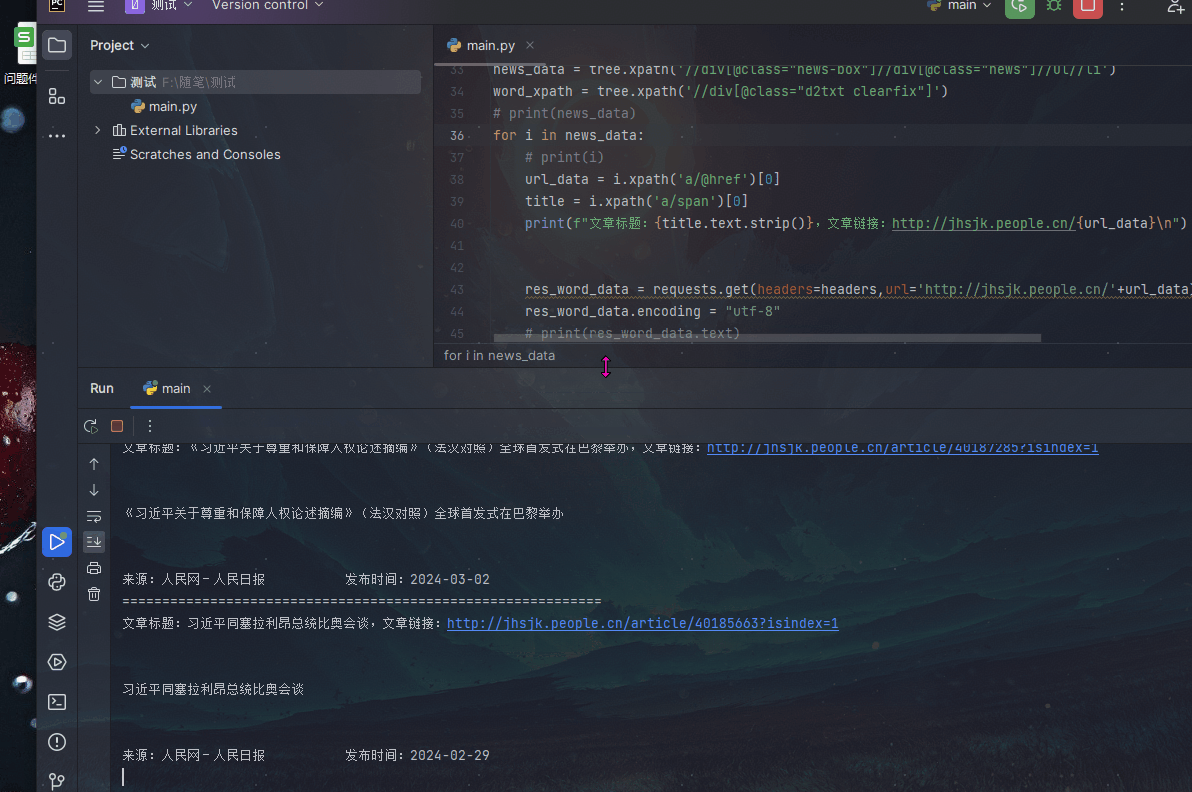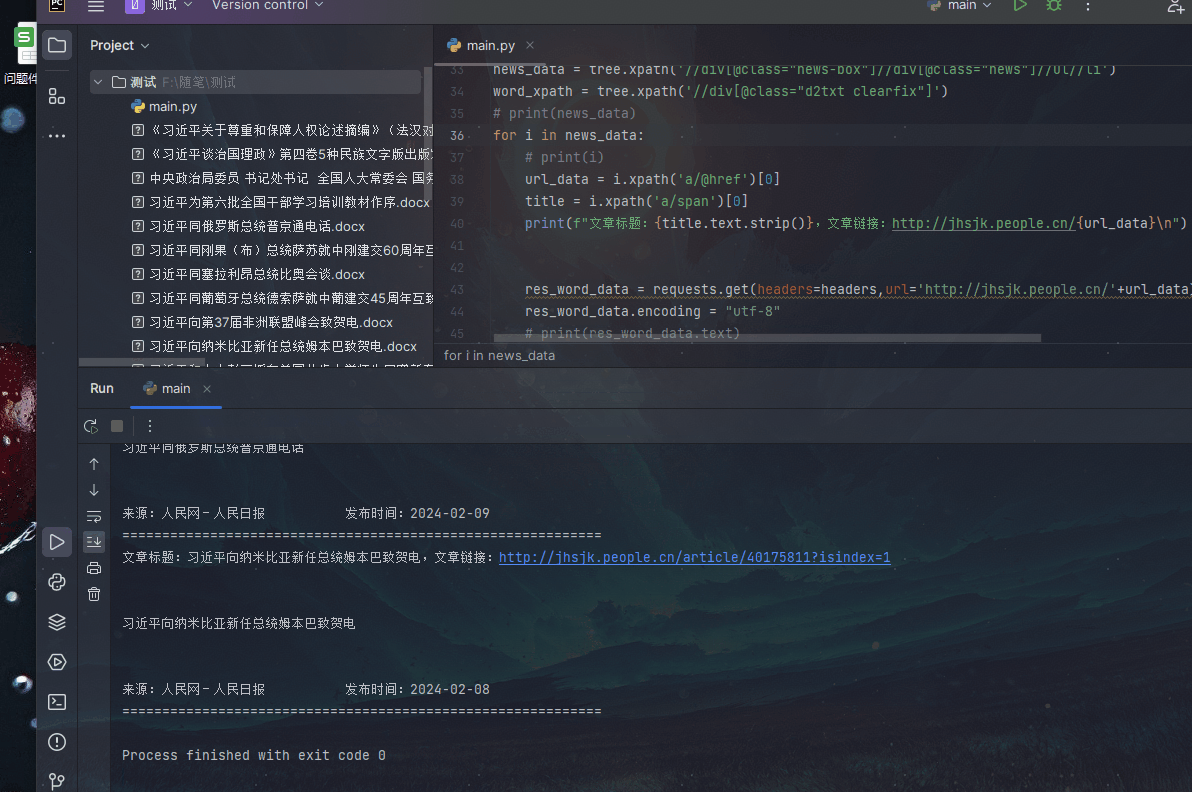

(含源碼)(圖文版))


)
)


)


:能源行業應用)








