
一、引言
在當今汽車產業的快速發展中,軟件已經成為提升車輛性能、安全性和用戶體驗的關鍵因素。從車載操作系統到智能駕駛輔助系統,軟件技術的進步正在重塑我們對汽車的傳統認知。我有幸參與了一個創新項目,該項目專注于開發和集成先進的汽車軟件系統,旨在通過信息抽取技術,進一步提升汽車智能化水平。這些系統不僅優化了駕駛體驗,還為汽車制造商提供了新的競爭優勢。在這篇文章中,我們將深入探討這一領域的最新進展,以及它們如何為未來汽車行業的發展奠定基礎。
二、用戶案例
在項目初期,我們面臨了一個巨大的挑戰:如何從海量的汽車維修記錄、用戶反饋和技術文檔中提取有價值的信息。這些信息對于改進汽車設計、優化維修流程和提升客戶滿意度至關重要。傳統的手動信息處理方法不僅耗時耗力,而且容易出錯。我們需要一種自動化的方法來提高效率和準確性。 我們決定采用信息抽取技術來解決這個問題。
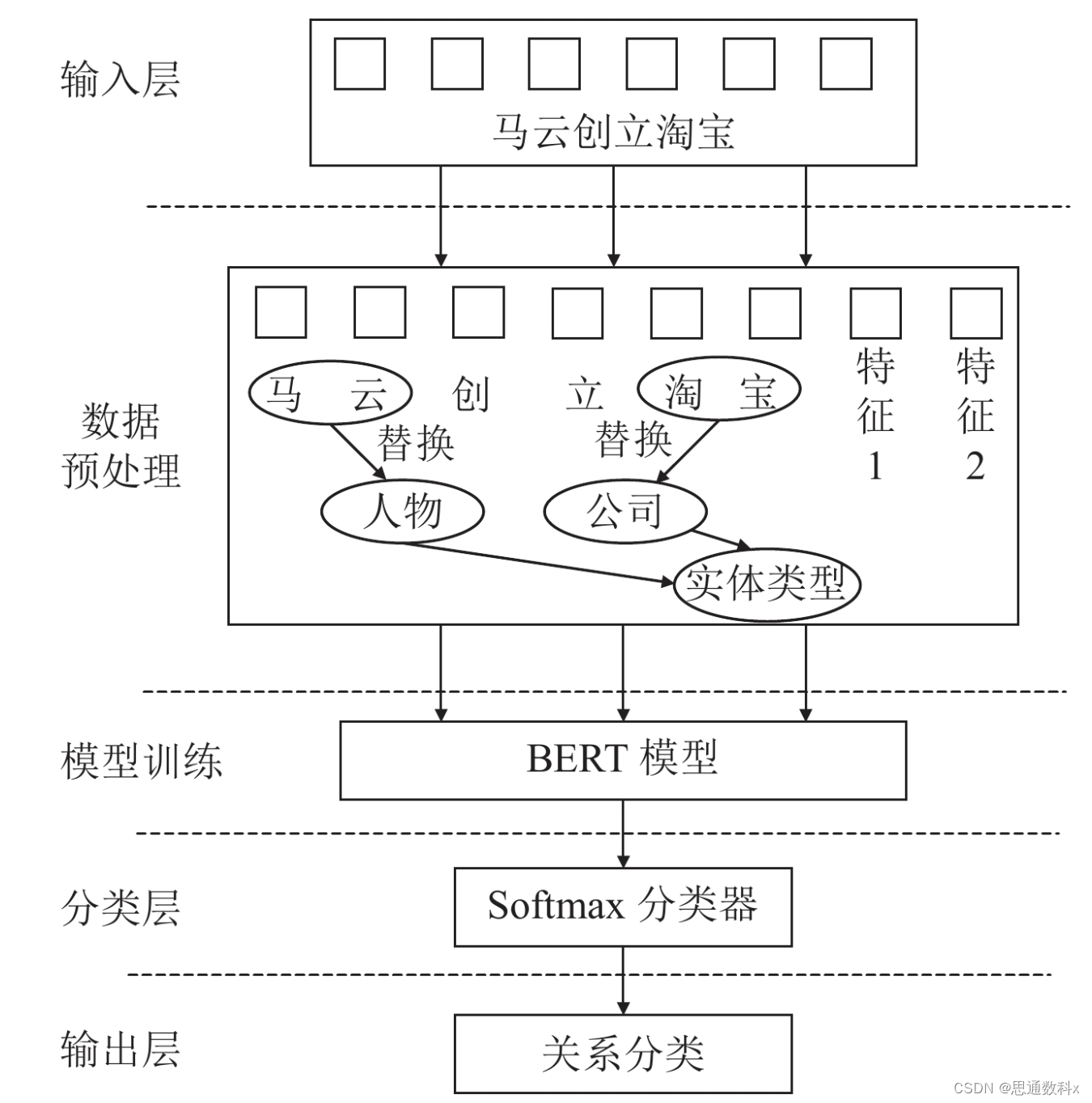
通過參數與屬性抽取,我們能夠從文本中自動識別出車輛的維修歷史、故障頻率和常見問題等關鍵參數。例如,我們能夠準確識別出某個型號的車輛在特定溫度下出現的啟動問題,或者在一定時間內的維修次數。這些數據對于我們分析汽車性能和設計缺陷提供了堅實的基礎。 在項目進行中,實體抽取技術發揮了巨大作用。我們成功地從用戶反饋中識別出了車輛型號、部件名稱和維修服務等實體。這使得我們能夠快速定位問題,并對維修流程進行優化。
例如,我們通過分析用戶反饋中的車輛型號和部件名稱,發現了一個批次的剎車片存在缺陷,及時通知生產線進行調整,避免了更大范圍的質量問題。 關系抽取技術幫助我們理解了車輛各部件之間的相互影響。我們能夠識別出哪些部件的故障會導致其他部件的損壞,從而優化維修策略。例如,我們發現某個型號的發動機問題會直接影響變速箱的性能,這促使我們在維修手冊中增加了相應的檢查步驟。
事件抽取技術則讓我們能夠追蹤和分析車輛故障的發生過程。我們能夠識別出故障發生的時間、地點和原因,這對于改進產品設計和預防未來故障具有重要意義。例如,我們通過分析一系列故障事件,發現了一個特定道路條件下的懸掛系統問題,這為我們提供了寶貴的設計改進方向。 通過這些技術的應用,我們不僅提高了信息處理的效率,還為汽車制造商提供了更深入的洞察,幫助他們在激烈的市場競爭中保持領先地位。
三、技術原理
在現代汽車制造業中,深度學習技術的應用正成為提升生產效率和產品質量的關鍵。特別是在信息抽取領域,深度學習技術通過自然語言處理(NLP)的先進模型,能夠從無結構化的文本數據中自動提取出有價值的信息。這些技術包括預訓練語言模型、任務特定微調、序列標注、序列到序列模型,以及端到端訓練等。在汽車制造的背景下,這些技術的應用可以極大地優化生產流程,提高維修效率,甚至幫助設計更加可靠的汽車產品。 預訓練語言模型,如BERT、GPT和XLNet,通過在大量文本數據上進行訓練,掌握了語言的深層結構和語義。這些模型為后續的信息抽取任務提供了堅實的基礎,使得計算機能夠理解并處理與汽車制造相關的復雜文本信息。
例如,通過這些模型,我們可以自動識別出汽車維修報告中的關鍵信息,如故障代碼、維修措施和更換零件等。 在預訓練的基礎上,通過任務特定的微調,模型能夠更加精準地適應特定的信息抽取需求。在汽車制造領域,這可能涉及到對維修手冊、技術規格書和生產日志等內容的深入理解和處理。微調后的模型能夠在這些特定類型的文本中識別出關鍵實體,如車型、部件編號、生產批次等,并能夠抽取出它們之間的關系,如部件之間的裝配關系、故障與維修措施之間的對應關系等。

序列標注技術,如條件隨機場(CRF)和雙向長短時記憶網絡(BiLSTM),能夠處理文本中的長距離依賴關系,這對于理解復雜的汽車維修流程和生產指令至關重要。這些模型能夠準確地識別出文本中的實體,并為它們分配正確的類別標簽,如將“ABS傳感器”標記為部件名稱,將“更換”標記為維修操作。 序列到序列模型,尤其是基于注意力機制的Transformer模型,能夠處理更為復雜的信息抽取任務。在汽車制造中,這些模型可以用于自動生成維修指南、生產報告摘要或者故障診斷報告。它們能夠理解輸入文本的上下文信息,并生成與輸入相關的、結構化的輸出信息,從而極大地提高了信息處理的效率和準確性。 端到端訓練意味著整個信息抽取過程,從輸入到輸出,都在一個統一的訓練框架下進行優化。
這種訓練方式不僅能夠提高模型的性能,還能夠確保模型在處理實際汽車制造相關文本時的魯棒性。在實際應用中,這意味著模型能夠更好地適應多樣化的文本格式和內容,從而提高抽取結果的可靠性。 在模型訓練過程中,通過不斷評估和優化,我們能夠確保信息抽取的準確性和效率。通過準確率、召回率、F1分數等指標的評估,我們可以對模型進行調整,如調整學習率、優化網絡結構或增加訓練數據。這些調整有助于提高模型在汽車制造領域的實際應用效果,使其能夠更好地服務于生產優化、質量控制和客戶服務等方面。 總之,深度學習在信息抽取領域的應用,特別是在汽車制造業,為提高生產效率、優化維修流程和提升產品質量提供了強大的技術支持。通過這些技術的集成和應用,汽車制造商能夠更快地響應市場變化,更好地滿足客戶需求,從而在競爭激烈的市場中保持領先地位。
四、技術實現
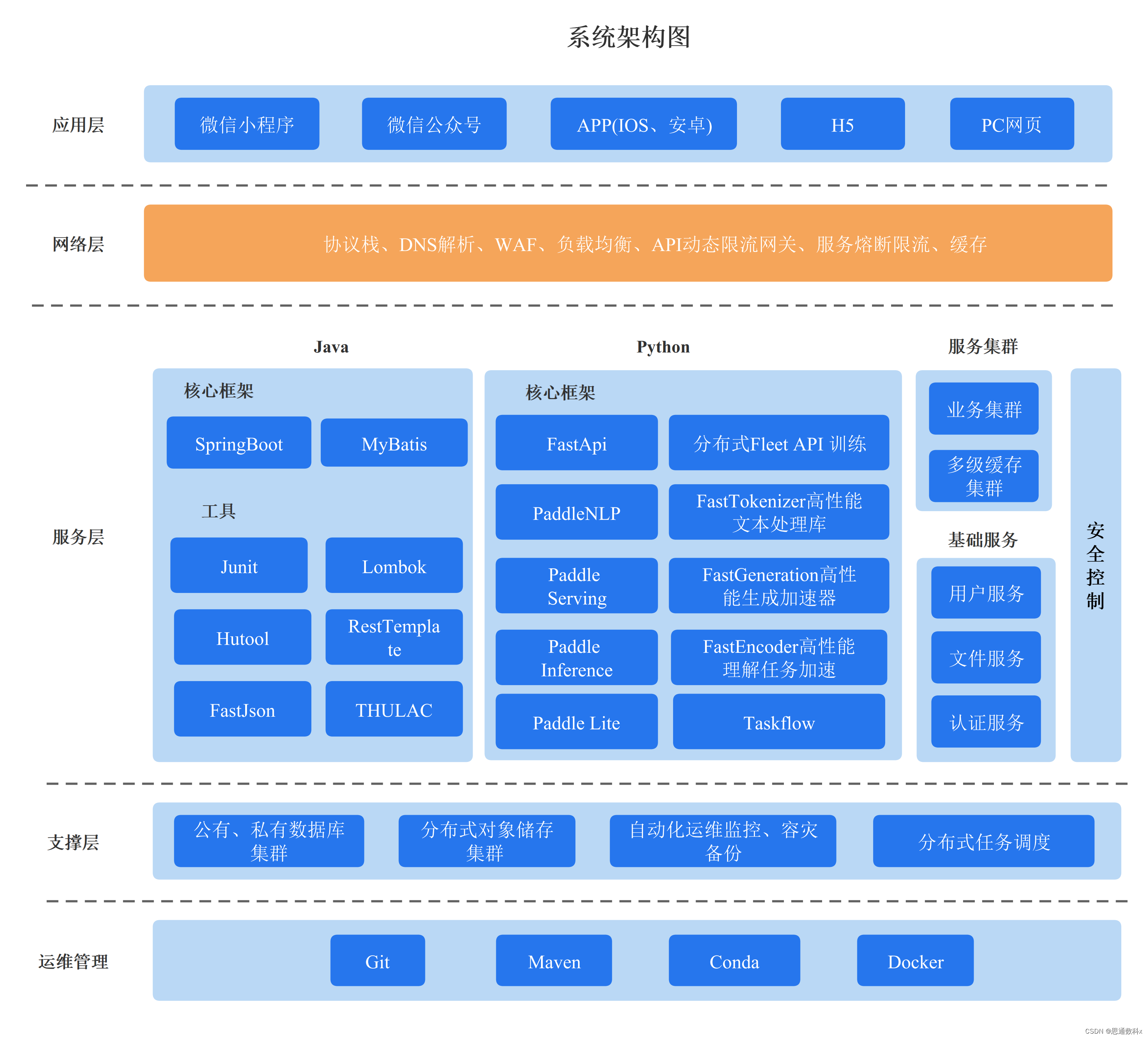
在文章的下一部分,我們將討論在項目中采用的現成NLP平臺,以及我們是如何利用它來處理技術原理的復雜性。這個平臺為我們提供了一套完整的工具,從數據收集、清洗到模型訓練和評估,都可以通過簡單的Web界面操作完成,無需編寫代碼。 首先,我們通過數據收集階段,收集了與汽車相關的各項數據樣本。這些樣本覆蓋了從維修記錄到用戶反饋的廣泛場景,確保了訓練數據的多樣性和全面性。接著,我們在數據清洗階段對這些樣本進行了預處理,以提高數據質量。這包括去除無關信息、糾正拼寫錯誤和標準化術語等步驟。 在樣本標注階段,我們使用了平臺提供的在線標注工具。這個工具幫助我們快速準確地標記文本中的實體和關系。我們確保所有標注者遵循相同的標準,以保證標注的一致性。為了確保標注質量,我們進行了多輪標注和校對。 樣本訓練階段,我們根據標注的數據提取了文本特征,并使用這些數據樣本來訓練我們的模型。我們通過調整模型參數來優化性能,以適應汽車領域的特定需求。在模型評估階段,我們使用了精確度、召回率和F1分數等指標來衡量模型性能,并確保模型具有良好的泛化能力。 最后,在結果預測階段,我們將訓練好的模型部署到生產環境中。模型現在可以自動處理新的文本輸入,執行信息抽取任務,并輸出結構化的結果。這些步驟的實現全部通過Web界面完成,用戶無需編寫任何代碼。 此外,我們還利用了平臺提供的Python代碼接口,來調用訓練和預測的結果。這使得我們能夠將模型的輸出與我們的應用程序無縫集成,進一步提升了我們項目的效率和效果。通過這種方式,我們不僅能夠處理復雜的技術原理,還能夠將這些原理應用到實際的汽車制造和維修工作中。
代碼實現示例
# 使用NLP平臺的信息抽取功能# 假設我們有一個函數 `perform_extraction`,它接受文本和抽取范圍(sch)作為輸入,# 并返回一個包含抽取結果的JSON對象。def perform_extraction(text, sch):# 設置請求頭headers = {'secret-id': '你的密鑰ID','secret-key': '你的密鑰'}# 設置請求參數data = {'text': text,'sch': sch,'modelID': 1 # 假設的模型ID}# 發送POST請求到NLP平臺response = requests.post('https://nlp.stonedt.com/api/extract', headers=headers, json=data)# 解析響應if response.status_code == 200:result = response.json()# 輸出抽取結果的JSONprint(json.dumps(result, indent=2))else:print(f"Error: {response.status_code}")# 示例文本example_text = """在最近的軟件升級中,我們針對車載操作系統進行了優化,提高了系統穩定性和響應速度。同時,智能駕駛輔助系統也得到了更新,增加了車道保持和自動緊急制動功能。這些改進預計將顯著提升汽車的性能和安全性。"""# 調用函數進行信息抽取perform_extraction(example_text, '汽車軟件系統')# 輸出結果示例(JSON格式)# {# "msg": "自定義抽取成功",# "result": [# ...# ],# "code": "200"# }在上述代碼中,我們定義了一個名為 perform_extraction?的函數,它模擬了調用NLP平臺的信息抽取功能。我們首先設置了請求頭,包括密鑰ID和密鑰,然后構建了請求參數,包括文本、抽取范圍和模型ID。接著,我們使用 requests?庫發送POST請求到NLP平臺的API,并檢查響應狀態。如果狀態碼為200,表示請求成功,我們將解析響應的JSON并打印出來。在實際應用中,這個函數可以幫助我們自動化地從文本中抽取與汽車軟件系統相關的信息,如系統性能、安全性和用戶體驗等。
數據庫表設計
-- 創建一個名為 `car_software_systems` 的表,用于存儲汽車軟件系統的相關信息CREATE TABLE car_software_systems (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主鍵ID,自增',system_name VARCHAR(255) NOT NULL COMMENT '系統名稱',system_description TEXT COMMENT '系統描述',system_version VARCHAR(50) COMMENT '系統版本',release_date DATE COMMENT '發布日期',last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新時間') COMMENT '汽車軟件系統信息表';-- 創建一個名為 `maintenance_records` 的表,用于存儲汽車維修記錄CREATE TABLE maintenance_records (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主鍵ID,自增',car_id INT COMMENT '關聯車輛ID',system_id INT COMMENT '關聯軟件系統ID',maintenance_date DATE NOT NULL COMMENT '維修日期',maintenance_description TEXT COMMENT '維修描述',maintenance_cost DECIMAL(10, 2) COMMENT '維修成本',FOREIGN KEY (car_id) REFERENCES cars(id),FOREIGN KEY (system_id) REFERENCES car_software_systems(id)) COMMENT '汽車維修記錄表';-- 創建一個名為 `user_feedbacks` 的表,用于存儲用戶反饋信息CREATE TABLE user_feedbacks (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主鍵ID,自增',car_id INT COMMENT '關聯車輛ID',system_id INT COMMENT '關聯軟件系統ID',feedback_text TEXT NOT NULL COMMENT '用戶反饋文本',feedback_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '反饋日期',FOREIGN KEY (car_id) REFERENCES cars(id),FOREIGN KEY (system_id) REFERENCES car_software_systems(id)) COMMENT '用戶反饋信息表';-- 創建一個名為 `component_failures` 的表,用于存儲車輛部件故障信息CREATE TABLE component_failures (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主鍵ID,自增',car_id INT COMMENT '關聯車輛ID',component_name VARCHAR(255) NOT NULL COMMENT '部件名稱',failure_description TEXT COMMENT '故障描述',failure_date DATE NOT NULL COMMENT '故障日期',FOREIGN KEY (car_id) REFERENCES cars(id)) COMMENT '車輛部件故障信息表';-- 創建一個名為 `events` 的表,用于存儲車輛故障事件CREATE TABLE events (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主鍵ID,自增',event_type VARCHAR(50) NOT NULL COMMENT '事件類型',event_description TEXT COMMENT '事件描述',event_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '事件發生時間',car_id INT COMMENT '關聯車輛ID',system_id INT COMMENT '關聯軟件系統ID',FOREIGN KEY (car_id) REFERENCES cars(id),FOREIGN KEY (system_id) REFERENCES car_software_systems(id)) COMMENT '車輛故障事件表';-- 創建一個名為 `extracted_data` 的表,用于存儲通過信息抽取技術獲取的數據CREATE TABLE extracted_data (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主鍵ID,自增',source VARCHAR(255) NOT NULL COMMENT '數據來源',extracted_text TEXT NOT NULL COMMENT '抽取的文本內容',extracted_data JSON COMMENT '抽取的結構化數據',extracted_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '抽取時間') COMMENT '抽取數據表';以上DDL語句設計了五個數據庫表,分別用于存儲汽車軟件系統信息、維修記錄、用戶反饋、部件故障和事件信息,以及通過信息抽取技術獲取的數據。每個表的字段都有相應的注釋,以便于理解其用途。在實際應用中,這些表將幫助我們有效地組織和存儲從各種數據源中提取的信息。
五、項目總結
在本項目實施過程中,我們成功地將先進的信息抽取技術應用于汽車軟件系統,取得了顯著的成效。通過自動化處理海量數據,我們大幅提高了信息處理的速度和準確性,減少了人工成本。具體來說,我們實現了從維修記錄中自動提取故障模式,優化了維修流程,縮短了維修時間。用戶反饋的自動分析使我們能夠快速響應市場變化,及時調整產品設計,提升了客戶滿意度。此外,通過對故障事件的深入追蹤分析,我們增強了產品的可靠性和安全性,為汽車制造商帶來了競爭優勢。
我們的解決方案不僅提升了汽車制造商的內部運營效率,還為最終用戶提供了更好的產品和服務。通過這些技術的應用,我們為汽車行業的發展貢獻了新的動力,為未來汽車智能化的實現奠定了堅實的基礎。
六、開源項目(本地部署,永久免費)
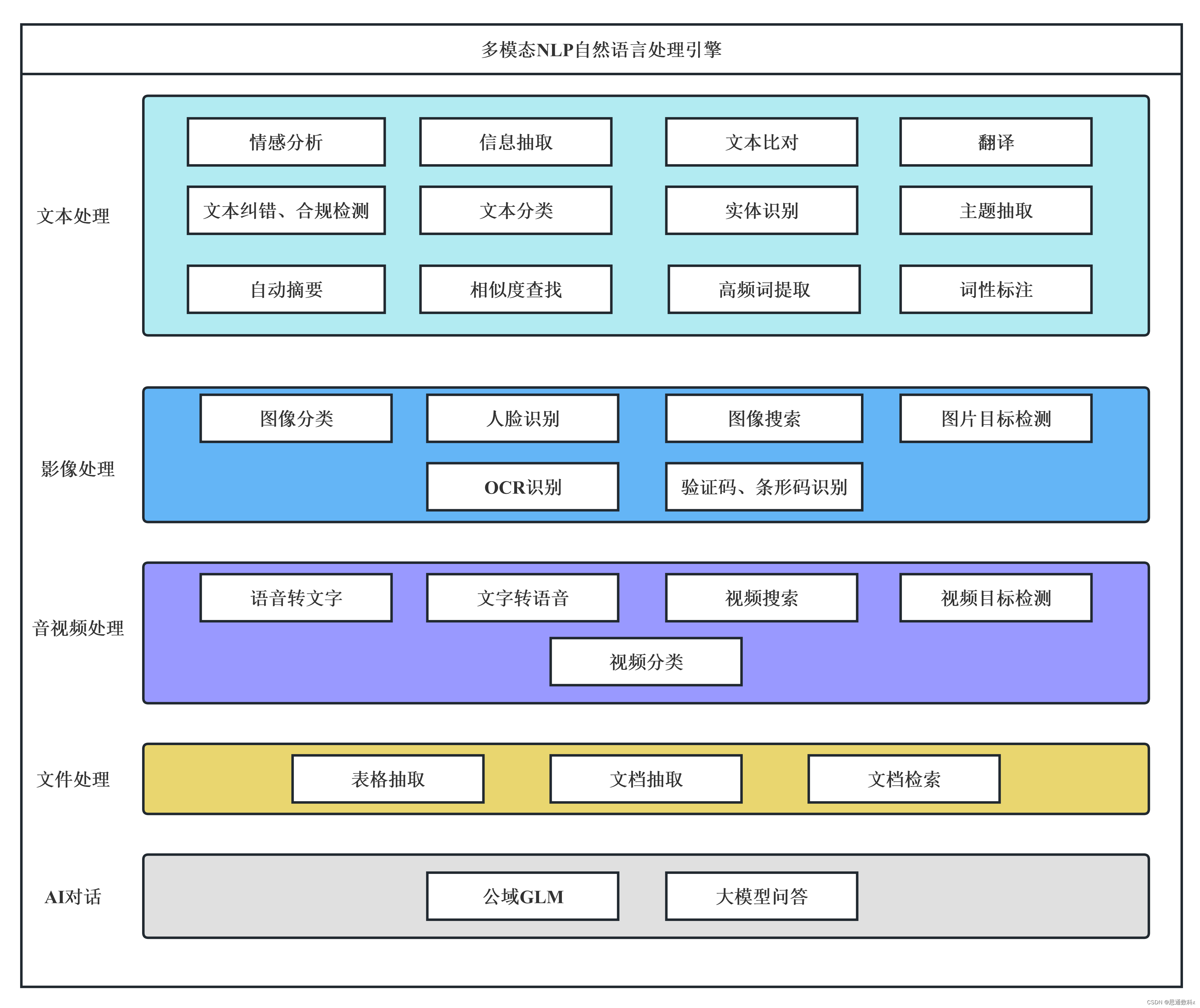
思通數科的多模態AI能力引擎平臺是一個企業級解決方案,它結合了自然語言處理、圖像識別和語音識別技術,幫助客戶自動化處理和分析文本、音視頻和圖像數據。該平臺支持本地化部署,提供自動結構化數據、文檔比對、內容審核等功能,旨在提高效率、降低成本,并支持企業構建詳細的內容畫像。用戶可以通過在線接口體驗產品,或通過提供的教程視頻和文檔進行本地部署。
思通數科多模態AI能力引擎平臺![]() https://nlp.stonedt.com
https://nlp.stonedt.com
多模態AI能力引擎平臺: 免費的自然語言處理、情感分析、實體識別、圖像識別與分類、OCR識別、語音識別接口,功能強大,歡迎體驗。![]() https://gitee.com/stonedtx/free-nlp-api
https://gitee.com/stonedtx/free-nlp-api

項目啟動過程--JobRegistryHelper 初始化 (4))

)















