指針深刻理解
看完鵬哥講的c語言進階視頻后,又找來C語言深度剖析這本書仔細看了一遍,來進一步鞏固和理解指針這個重點。
1:數組

如上圖所示,當我們定義一個數組 a 時,編譯器根據指定的元素個數和元素的類型分配確定大小(元素類型大小*元素個數)的一塊內存,并把這塊內存的名字命名為 a。名字 a 一旦與這塊內存匹配就不能被改變。a[0],a[1]等為 a 的元素,但并非元素的名字。
這里需要注意的是:
1 sizeof(數組名),計算整個數組的大小,sizeof內部單獨放一個數組名,數組名表示整個數組。
- &數組名,取出的是數組的地址。&數組名,數組名表示整個數組。除此1,2兩種情況之外,所有的數組名都表示數組首元素的地址。
A)char *p = “abcdef”;
B)char a[] = “123456”;
例子A中若是想訪問字符串中的e的話,有兩種方法,
(1)*(p+4)這是這種方法,因為p中存放著這塊內存首地址,加上偏移量4,即可訪問到e。
(2)p[4]:編譯器總是把以下標的形式的操作解析為以指針的形式的操作。p[4]這個操作會被解析成:先取出 p 里存儲的地址值,然后加上中括號中 4 個元素的偏
移量,計算出新的地址,然后從新的地址中取出值。也就是說以下標的形式訪問在本質上與以指針的形式訪問沒有區別,只是寫法上不同罷了。
B的話和A同理。
下面繼續來看一段代碼來深刻理解&a和a的區別是啥:
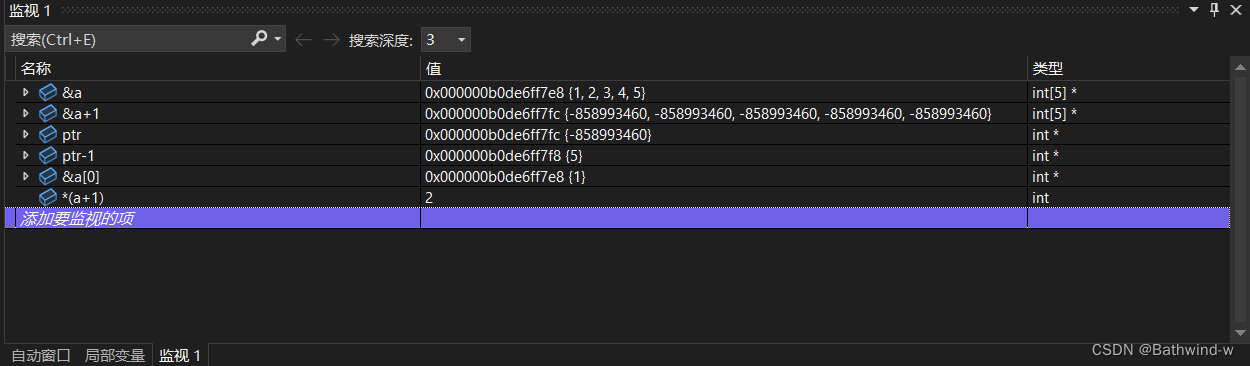
int main()
{
int a[5]={1,2,3,4,5};
int *ptr=(int *)(&a+1);
printf("%d,%d",*(a+1),*(ptr-1));
return 0;
}
首先上面已經說過了除了sizeof(數組名)和&數組名,其余的數組名都是表示數組首元素的地址。
對指針進行加 1 操作,得到的是下一個元素的地址,而不是原有地址值直接加 1。所以,一個類型為 T 的指針的移動,以 sizeof(T) 為移動單位。 因此,對上題來說,a 是一個一維數組,數組中有 5 個元素; ptr 是一個 int 型的指針。
&a + 1: 取數組 a 的首地址,該地址的值加上 sizeof(a) 的值,即 &a + 5sizeof(int),也就是下一個數組的首地址,當前指針已經越過了數組的界限。
ptr這個指針變量存放的是下一個數組的首地址,ptr也就是指向a[5],ptr-1也就是指向a[4],
*(a+1): a,&a 的值是一樣的,但意思不一樣,a 是數組首元素的首地址,也就是 a[0]的首地址,&a 是數組的首地址,a+1 是數組下一元素的首地址,即 a[1]的首地址,&a+1 是下一個數組的首地址。所以輸出 2
2:c指針數組與數組指針區別和理解
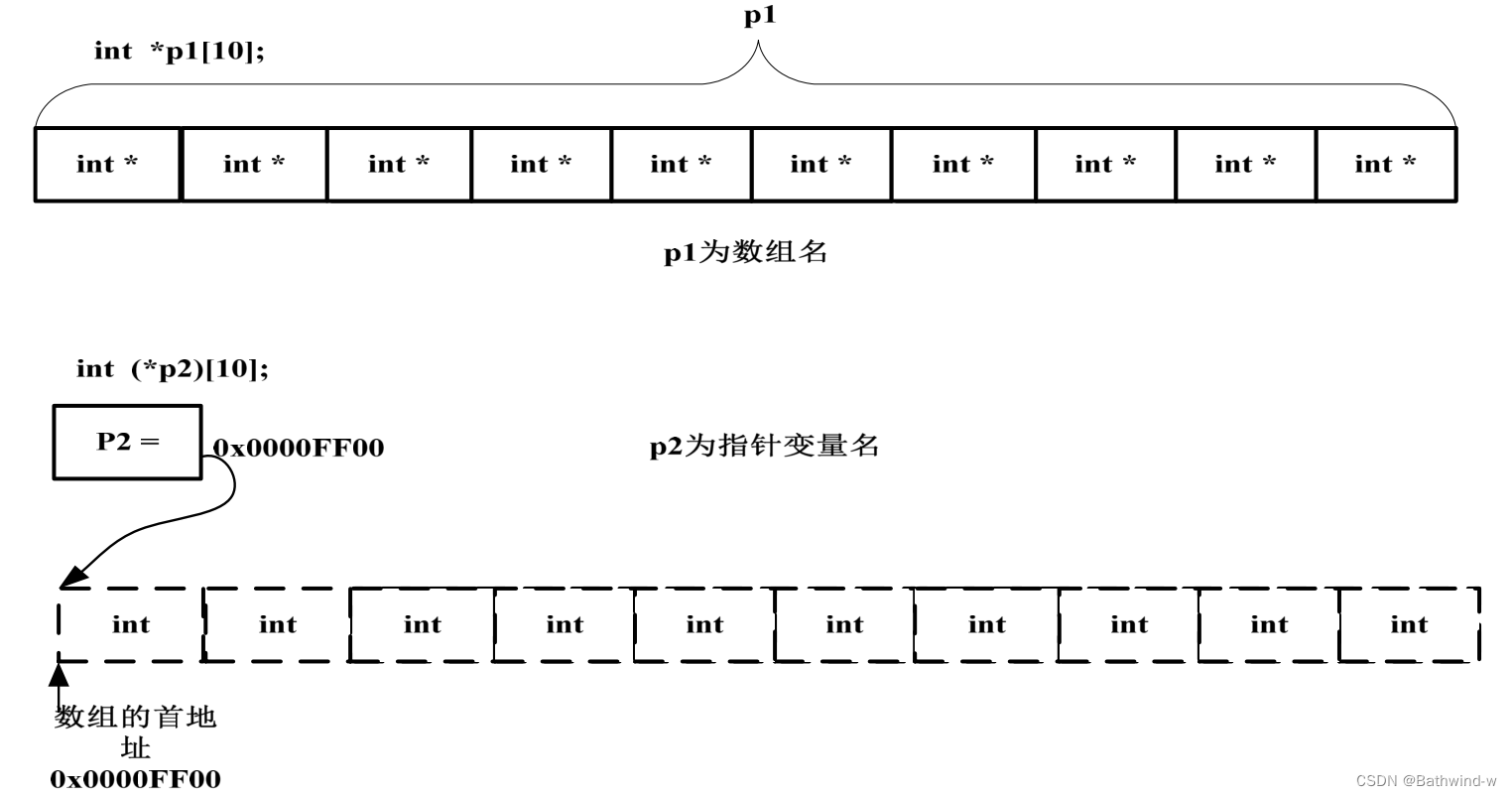
指針數組和數組指針從基本的漢字表面上去理解,會發現指針數組的主語是數組,數組指針的主語是指針,所以很明顯的第一個區別就是指針數組是數組,用來存放指針。
下面接著看一段代碼:
#include <stdio.h>int main()
{char a[5] = { 'A','B','C','D' };char(*p3)[5] = &a;char(*p4)[5] = a;return 0;
}
因為char(*p3)[5] = &a ;char(*p4)[5] = a;定義的都是數組指針,指向的數組大小為char[5]類型,雖然&a和a的值是一樣的,但是其表示的意義是不一樣的,這里一樣的原因理解是,但由于&a 和 a 的值一樣,而變量作為右值時編譯器只是取變量的值,所以運行并沒有什么問題。
對上述代碼進行更改,將數組指針指向的數組大小發生更改。
int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[3] = &a;
char (*p4)[3] = a;
return 0;
}
運行結果也好理解:p3+1 和 p4+1 的值就相當于跳過sizeof(char)*(數組指針所指向數組的大小,要是數組大小為3,這里就是3)

1:指針數組詳解
其中指針數組的一個應用是可以用一維數組模擬二維數組。
#include <stdio.h>int main()
{int arr1[] = { 1,2,3,4,5,6,7,8,9 };int arr2[] = { 7,8,9,6,5,4,1,2,3 };int arr3[] = { 7,8,9,5,2,1,0,4,6 };int* arr[] = { arr1,arr2,arr3 };//arr中每個元素都為一個指針,指針指向對應的數組;每個元素為對應數組的首地址int i;for (i = 0; i < 3; i++){int j;for (j = 0; j < 9; j++){printf("%d", *(arr[i] + j));//實現對應元素的遍歷;//printf("%d", arr[i][j]);//實現對應元素的遍歷}printf("\n");}return 0;
}兩種不同的方式來訪問并打印數組元素:
-
使用指針運算和解引用操作符
*:printf("%d", *(arr[i] + j));這里,
arr[i]獲取指針數組arr的第i個元素,即指向arr1、arr2或arr3的指針之一。arr[i] + j計算出指向當前數組第j個元素的指針,而*(arr[i] + j)解引用該指針,獲取該元素的值。 -
使用數組下標訪問:
printf("%d", arr[i][j]);這種方式更直觀。
arr[i]獲取指向某個數組的指針,而arr[i][j]直接訪問該數組的第j個元素。這是因為arr[i]被視為指向第i個數組的首元素的指針,而arr[i][j]就是訪問該指針所指向數組的第j個元素。
第二種寫法的原因如下:在C語言中,arr[i][j] 這種雙重下標訪問方式背后的原理與指針算術緊密相關。當你有一個指向指針的指針(或者數組的數組,或者指針數組,如本例所示),這種雙重下標訪問實際上是兩步操作的簡寫:
arr[i]訪問第i個元素,這里的元素是指向int的指針(在你的例子中,它指向arr1、arr2或arr3)。[j]對該指針進行解引用,訪問它所指向數組的第j個元素。
1.1理解指針的指針和數組的數組
在C語言中,當你聲明一個如 int* arr[] 的數組時,你創建了一個數組,其每個元素都能存儲一個指向 int 類型的指針。所以,arr 是一個數組,但每個 arr 的元素(比如 arr[0]、arr[1]、arr[2] 等)是一個指針,指向一個 int 數組。
1.2雙重下標訪問的工作原理
當你使用 arr[i][j] 進行訪問時,arr[i] 首先得到第 i 個數組的首地址(一個指針)。然后,[j] 操作符被應用到這個地址上,它實際上是通過指針算術來完成的:從這個地址開始,移動 j 個 int 的大小的距離,來訪問特定的元素。這是因為在C語言中,數組名或指針被用作數組時,pointer[offset] 等價于 *(pointer + offset)。
1.3為什么這樣做是有效的
這種訪問方式之所以有效,是因為C語言設計時就考慮到了這種使用場景。數組和指針在很多情況下是可以互換的。當你聲明一個像 int *arr[] 這樣的指針數組時,C語言允許你通過像訪問二維數組那樣的語法來訪問它,即使它實際上是一個數組的數組或指針的數組。這種設計極大地簡化了對于復雜數據結構的操作,同時保持了代碼的可讀性和易于理解。
簡而言之,arr[i][j] 能夠直接訪問指針所指向數組的第 j 個元素,是因為C語言的設計允許通過指針算術和解引用操作符的組合來簡化這種操作,使得指針數組的操作既直觀又高效。
3:地址的強制轉換
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
假設 p 的值為 0x100000。 如下表表達式的值分別為多少?
p + 0x1 = 0x___ ?
(unsigned long)p + 0x1 = 0x___?
(unsigned int*)p + 0x1 = 0x___?
在C語言中,當你對一個指針進行算術操作時,如 p + 1,這個操作會根據指針指向的數據類型的大小來移動指針。這意味著,如果 p 是一個指向 struct Test 的指針,那么 p + 1 不是簡單地將 p 的值增加 1,而是增加 sizeof(struct Test) 的大小,這樣 p + 1 就指向了內存中緊接著 p 指向的 struct Test 實例之后的下一個 struct Test 實例的起始位置。
給定的結構體 Test 包含以下成員:
- 一個
int類型的Num,通常是4個字節。 - 一個
char *類型的pcName,指針大小通常是4個字節(在32位架構上)或8個字節(在64位架構上)。 - 一個
short類型的sDate,通常是2個字節。 - 一個
char類型的數組cha[2],總共2個字節。 - 一個
short類型的數組sBa[4],總共8個字節。
根據這些信息,我們可以計算 struct Test 的大小。然而,實際的結構體大小還需要考慮到內存對齊(padding)。內存對齊是編譯器自動進行的,以確保結構體中的每個成員都按照其自然對齊要求放置在內存中,這可能會導致結構體的實際大小比簡單加起來的成員大小要大。,假定 struct Test 的總大小是20字節。這個大小已經考慮了可能的內存對齊。因此,當你做 p + 1 操作時,指針會按照結構體的實際大小(20字節)進行移動。
如果 p 的初始值是 0x100000,那么 p + 1 的計算將是:
0x100000 + sizeof(struct Test) * 1
如果 sizeof(struct Test) 是20字節,那么:
p + 1 = 0x100000 + 20 = 0x100014
(unsigned long)p + 0x1 = 0x100001
(unsigned int*)p + 0x1 = 0x100004
unsigned long將p強制類型轉為無符號長整型,數值不發生改變,但是所屬類型已經發生了改變。
unsigned int*一個指向無符號整型的指針,所以為4個字節。
4:二維數組
實際上內存不是表狀的,而是線性的。見過尺子吧?尺子和我們的內存非常相似。一般尺子上最小刻度為毫米,而內存的最小單位為 1 個 byte。平時我們說 32 毫米,是指以零開始偏移 32 毫米;平時我們說內存地址為 0x0000FF00 也是指從內存零地址開始偏移0x0000FF00 個 byte。既然內存是線性的,那二維數組在內存里面肯定也是線性存儲的。實際上其內存布局如下圖:
char a[3][4];

以數組下標的方式來訪問其中的某個元素:a[i][j]。編譯器總是將二維數組看成是一個一維數組,而一維數組的每一個元素又都是一個數組。a[3]這個一維數組的三個元素分別為:a[0],a[1],a[2]。a[i][j]的首地址為&a[i]+j*sizof(char) 寫為指針的形式為:a+i*sizeof(char)*4+j*sizeof(char) ,可以換算成以指針的形式表示:*(*(a+i)+j)。解釋 *(a+i) 解引用得到第 i 行的首地址這一點,可能會有些混淆。對于二維數組 char a[3][4];,a 本身可以被視為指向其第一個元素(即第一行 a[0])的指針。這里的每個元素(每一行)本身是一個 char[4] 類型的數組。因此,a 的類型是 char (*)[4],即指向一個含有 4 個字符的數組的指針。當我們說 *(a+i) 時,這里的操作實際上是在進行兩個步驟:
- 指針算術運算:
a+i計算的是第i行的首地址。由于a是指向第一行的指針,a+i實際上是利用指針算術來計算第i行的起始地址。這里的i乘以的是每行的大小(在本例中是 4 個char),這是自動完成的,不需要顯式乘以sizeof(char)或行的大小。這一步并沒有解引用,只是計算地址。 - 解引用:
*(a+i)的操作是對計算得到的地址進行解引用。但是,這里的“解引用”可能會造成一些理解上的混淆。在這個上下文中,我們不是在獲取一個char值,而是獲取指向第i行首元素的指針。這是因為a+i已經是一個指向char[4]的指針,解引用這個指針實際上給出的是char[4]類型的數組的第一個元素的地址,這與直接使用a[i]是等價的。 - 因此,當我們說“解引用得到第
i行的首地址”時,我們實際上是在描述獲取到這一行數組的起始點的過程。在 C 語言中,數組名(在這個例子中是a[i])被用作表達式時,會被轉換(除了sizeof和&操作符的情況)為指向其第一個元素的指針。所以,*(a+i)和a[i]在這里是等價的,都表示第i行的首地址。
)
)











)





