我們歷盡千辛萬苦,總算要部署模型了。這個系列也寫到62篇,不要著急,后面還有很多。
這周偷懶了,一天放出太多的文章,大家可能有些吃不消,從下周開始,本系列將正常更新。
這套大廠AI課,非常經典,我已經通過這套課程,考過了騰訊云的人工智能TCA認證。
模型的部署要考慮很多問題,面臨很多挑戰。
比如語言,我們都是用R語言或者PYTHON來開發,但是部署時,很多時候需要轉換成C或者JAVA。
我們還要考慮可移植性、可擴展性,還有算力的分配,等等。
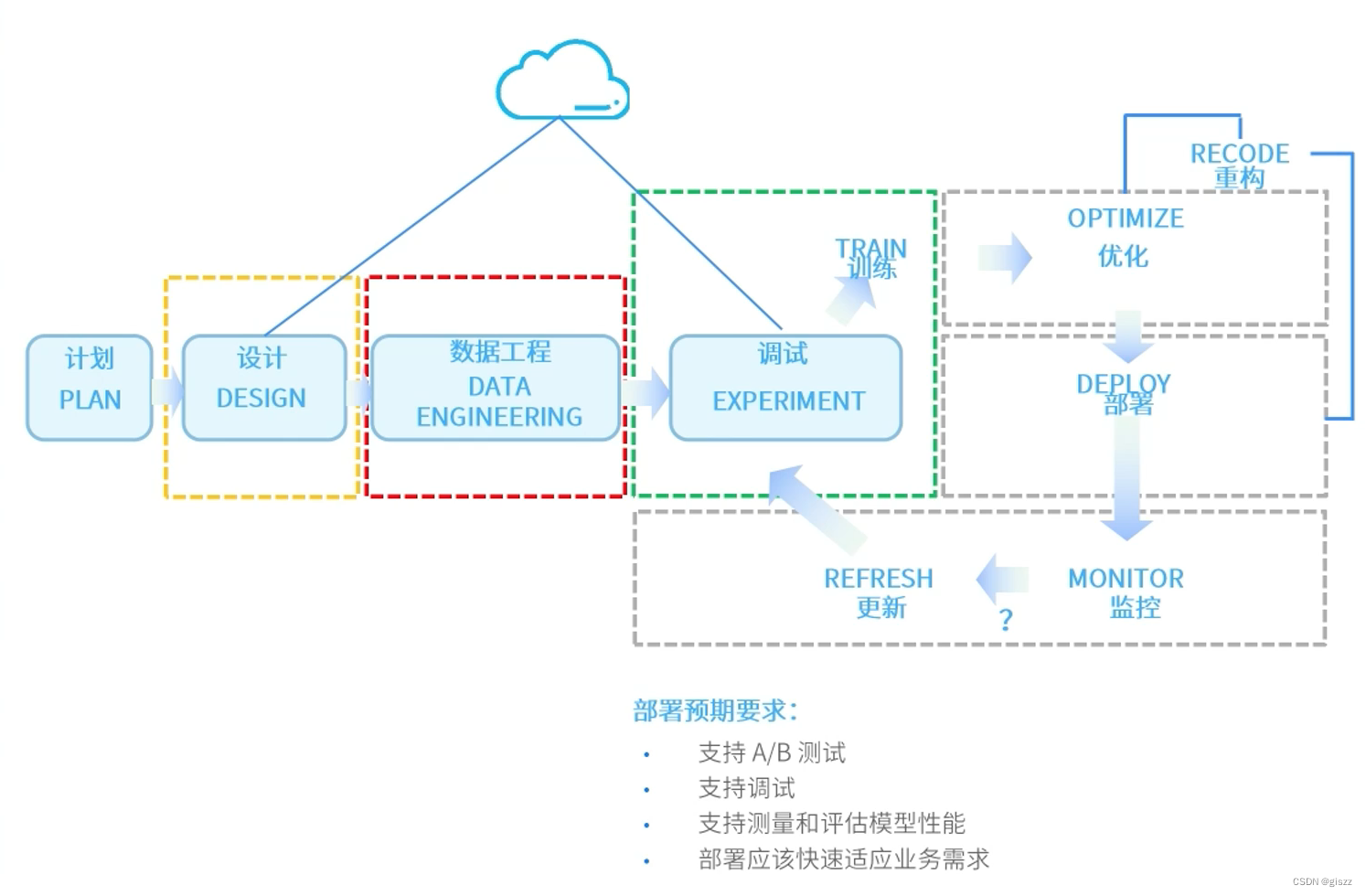
我們還需要需要模型引擎、工具庫、數據轉換器、模型庫等。
需要支持常用編程腳本語言,及相關的工具庫,docker,spark等。
模型部署是機器學習項目從開發到生產的關鍵步驟之一。在部署過程中,需要考慮代碼的轉換、算力的分配、部署工具的選擇以及其他工程步驟。下面將詳細闡述這些方面。
一、代碼轉換
在模型部署之前,通常需要將訓練代碼轉換為推理代碼。訓練代碼關注于模型的訓練和優化,而推理代碼則關注于使用訓練好的模型進行預測。這個轉換過程需要考慮以下幾個方面:
- 模型格式轉換:不同的深度學習框架(如TensorFlow、PyTorch等)可能使用不同的模型格式。在部署時,可能需要將模型轉換為與部署環境兼容的格式,如TensorFlow Lite、ONNX等。這些格式通常針對移動設備或特定硬件進行了優化,以提高推理速度。
- 代碼優化:推理代碼需要盡可能高效,以減少預測時的延遲。這包括去除訓練代碼中的不必要部分(如反向傳播、優化器等),以及使用針對推理的優化技術(如量化、剪枝等)。
- 輸入/輸出處理:推理代碼需要能夠處理來自實際應用的輸入數據,并將其轉換為模型可以接受的格式。同樣,模型的輸出也需要轉換為應用可以理解的格式。這可能需要編寫額外的數據預處理和后處理代碼。
二、算力分配
算力分配是模型部署中的另一個重要問題。根據模型的大小和復雜性,以及預期的推理速度,需要選擇合適的硬件來部署模型。這包括:
- CPU vs GPU vs TPU:中央處理器(CPU)適用于大多數簡單的模型和小規模推理任務。然而,對于大規模的深度學習模型,圖形處理器(GPU)或張量處理器(TPU)可能更合適,因為它們提供了更高的并行處理能力。
- 云端 vs 邊緣計算:對于需要實時響應的應用(如自動駕駛、智能語音助手等),將模型部署在靠近用戶的邊緣設備上可能更有優勢。這樣可以減少數據傳輸延遲,提高響應速度。然而,對于不需要實時響應的應用(如批量數據分析、圖像識別等),將模型部署在云端可能更經濟高效。
- 彈性伸縮:在實際應用中,模型的推理請求量可能會隨時間變化。因此,部署方案需要能夠彈性地擴展或縮減算力資源,以滿足不同時間段的需求。這可以通過使用云計算平臺的自動擴展功能或容器編排工具來實現。
三、部署工具
選擇合適的部署工具可以大大簡化模型部署的過程。以下是一些常用的部署工具及其特點:
- Docker:Docker是一種容器化技術,它允許開發者將應用及其所有依賴項打包到一個可移植的容器中,然后將其部署到任何Docker環境中。使用Docker可以確保模型在不同環境中的一致性和可重復性。此外,Docker還提供了強大的容器編排和擴展功能,適用于大規模部署場景。
- Kubernetes:Kubernetes是一個開源的容器編排平臺,它提供了自動擴展、自動故障恢復、自動日志收集等高級功能。使用Kubernetes可以輕松地管理和維護大規模的容器集群,適用于需要高可用性和彈性伸縮的部署場景。
- 模型服務框架:除了容器化技術外,還有一些專門用于模型部署的框架,如TensorFlow Serving、Clipper等。這些框架提供了針對機器學習模型的優化功能,如批量處理、模型版本管理、動態加載等。它們通常與特定的深度學習框架緊密集成,可以方便地部署和管理使用該框架訓練的模型。
四、其他工程步驟
除了上述三個方面外,模型部署還涉及其他一些重要的工程步驟:
- 性能測試與調優:在部署之前,需要對模型進行性能測試以評估其推理速度和準確性。根據測試結果,可能需要對模型或推理代碼進行優化以提高性能。這可能包括調整模型的參數、優化算法選擇、減少不必要的計算等。
- 安全性與隱私保護:對于涉及敏感數據的應用(如人臉識別、語音識別等),需要確保模型部署過程中的安全性和隱私保護。這包括使用加密技術保護數據傳輸、對敏感數據進行脫敏處理、限制對模型的訪問權限等。此外,還需要定期更新和修補安全漏洞以防止潛在的安全風險。
- 監控與日志收集:部署后需要設置監控機制以實時跟蹤模型的性能和穩定性。這包括收集模型的推理請求量、響應時間、錯誤率等指標,并設置相應的警報閾值以便及時發現問題。同時,還需要收集詳細的日志信息以便進行故障排查和性能優化。這可以通過使用專門的監控和日志收集工具來實現。
- 版本管理與回滾:隨著項目的進展和需求的變更,可能需要更新或替換已部署的模型。因此,需要建立完善的版本管理機制以跟蹤不同版本的模型和推理代碼。同時,還需要實現回滾功能以便在出現問題時能夠迅速恢復到之前的穩定版本。這可以通過使用版本控制工具(如Git)和持續集成/持續部署(CI/CD)流程來實現。
- 文檔編寫與維護:為了方便其他開發者了解和使用已部署的模型,需要編寫詳細的文檔說明模型的輸入輸出格式、使用方法、性能指標等信息。同時,還需要定期更新文檔以反映模型的最新變化和最佳實踐。這有助于提高項目的可維護性和團隊協作效率。
綜上所述,模型部署是一個涉及多個方面的復雜過程,需要綜合考慮代碼轉換、算力分配、部署工具選擇以及其他工程步驟等多個因素。通過合理規劃和實施這些步驟,可以確保模型在生產環境中的高效運行和穩定性。
?
![[python] dict類型變量寫在文件中](http://pic.xiahunao.cn/[python] dict類型變量寫在文件中)



)


過擬合與欠擬合)

)
解決)








