擬合就是調整參數和模型,讓結果無限接近真實值的過程。
我們先來了解個概念:?
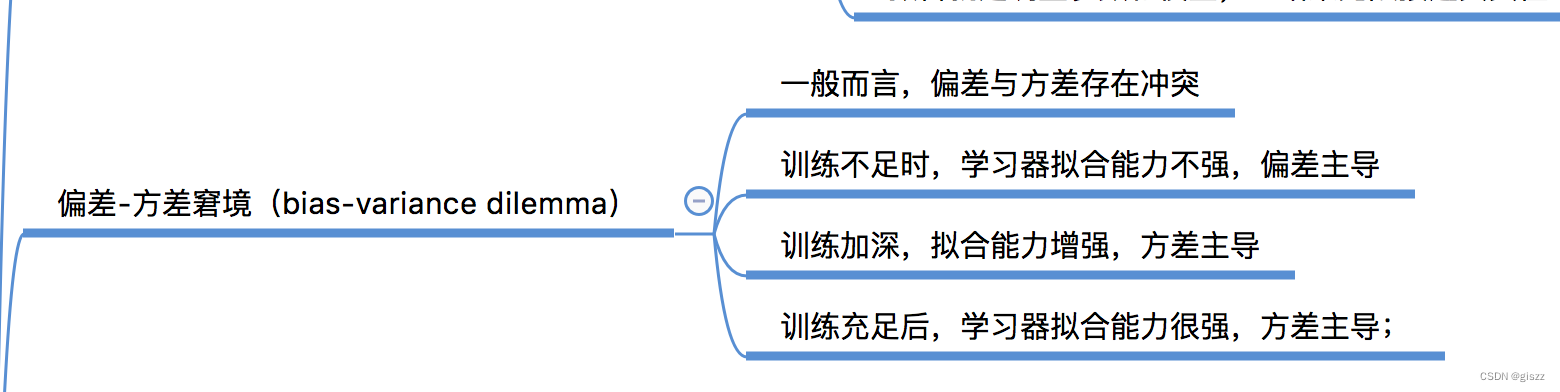
偏差-方差窘境(bias-variance dilemma)是機器學習中的一個重要概念,它涉及到模型選擇時面臨的權衡問題。
偏差(Bias)度量了學習算法的期望預測與真實結果的偏離程度,即刻畫了學習算法本身的擬合能力。當模型過于簡單,無法捕捉到數據的所有復雜性時,就會出現高偏差的情況,此時模型可能會欠擬合(underfit)數據。
方差(Variance)則度量了在同樣大小的訓練集的變動下,學習性能的變化,即刻畫了數據擾動所造成的影響。當模型過于復雜,對訓練數據中的噪聲和特定細節過于敏感時,就會出現高方差的情況,此時模型可能會過擬合(overfit)數據。
在模型選擇時,我們通常會面臨偏差和方差之間的權衡。簡單的模型可能具有較高的偏差和較低的方差,而復雜的模型可能具有較低的偏差和較高的方差。因此,在選擇模型時,我們需要找到一個平衡點,使得模型既能夠捕捉到數據的內在規律,又不會對數據中的噪聲和特定細節過于敏感。
偏差-方差窘境的存在意味著我們無法同時最小化偏差和方差。在實際應用中,我們通常需要借助交叉驗證、正則化等技術來平衡偏差和方差,從而選擇出最優的模型。
需要注意的是,除了偏差和方差之外,還有一個重要的因素也會影響模型的性能,那就是噪聲(Noise)。噪聲表達了在當前任務上任何算法所能達到的期望泛化誤差的下界,即刻畫了學習問題本身的難度。因此,在實際應用中,我們還需要考慮噪聲對模型性能的影響。
泛化性能是由學習算法的能力,數據的充分性,以及學習任務共同難度決定了。
之前講過,在此不再贅述。
我們再學習一個概念:偏差-方差分解(bias-variance decomposition)
偏差-方差分解(Bias-Variance Decomposition)是機器學習中一種重要的分析技術,用于解釋學習算法泛化性能的一種工具。給定學習目標和訓練集規模,它可以把一種學習算法的期望誤差分解為三個非負項的和,即樣本真實噪音(Noise)、偏差(Bias)和方差(Variance)。
- 樣本真實噪音:是任何學習算法在該學習目標上的期望誤差的下界,即刻畫了學習問題本身的難度。這是由數據本身的特性所決定的,無法通過優化模型來減少。
- 偏差:度量了某種學習算法的平均估計結果所能逼近學習目標的程度,即刻畫了模型的擬合能力和準確性。偏差越小,說明模型的擬合能力越強,預測結果越接近真實值。
- 方差:度量了在面對同樣規模的不同訓練集時,學習算法的估計結果發生變動的程度,即刻畫了模型對數據擾動的敏感性。方差越小,說明模型對數據擾動的魯棒性越強,不會因為訓練集的微小變化而導致預測結果的劇烈波動。
需要注意的是,偏差和方差通常是相互矛盾的,即偏差的減小可能導致方差的增加,反之亦然。因此,在選擇模型時,需要綜合考慮偏差和方差之間的平衡,以及噪聲對模型性能的影響,從而選擇出最優的模型。
總的來說,偏差-方差分解提供了一種從偏差和方差的角度來解釋學習算法泛化性能的方法,有助于我們更好地理解模型的性能表現,并指導我們進行模型選擇和優化。
好,我們來了解過擬合與欠擬合。?
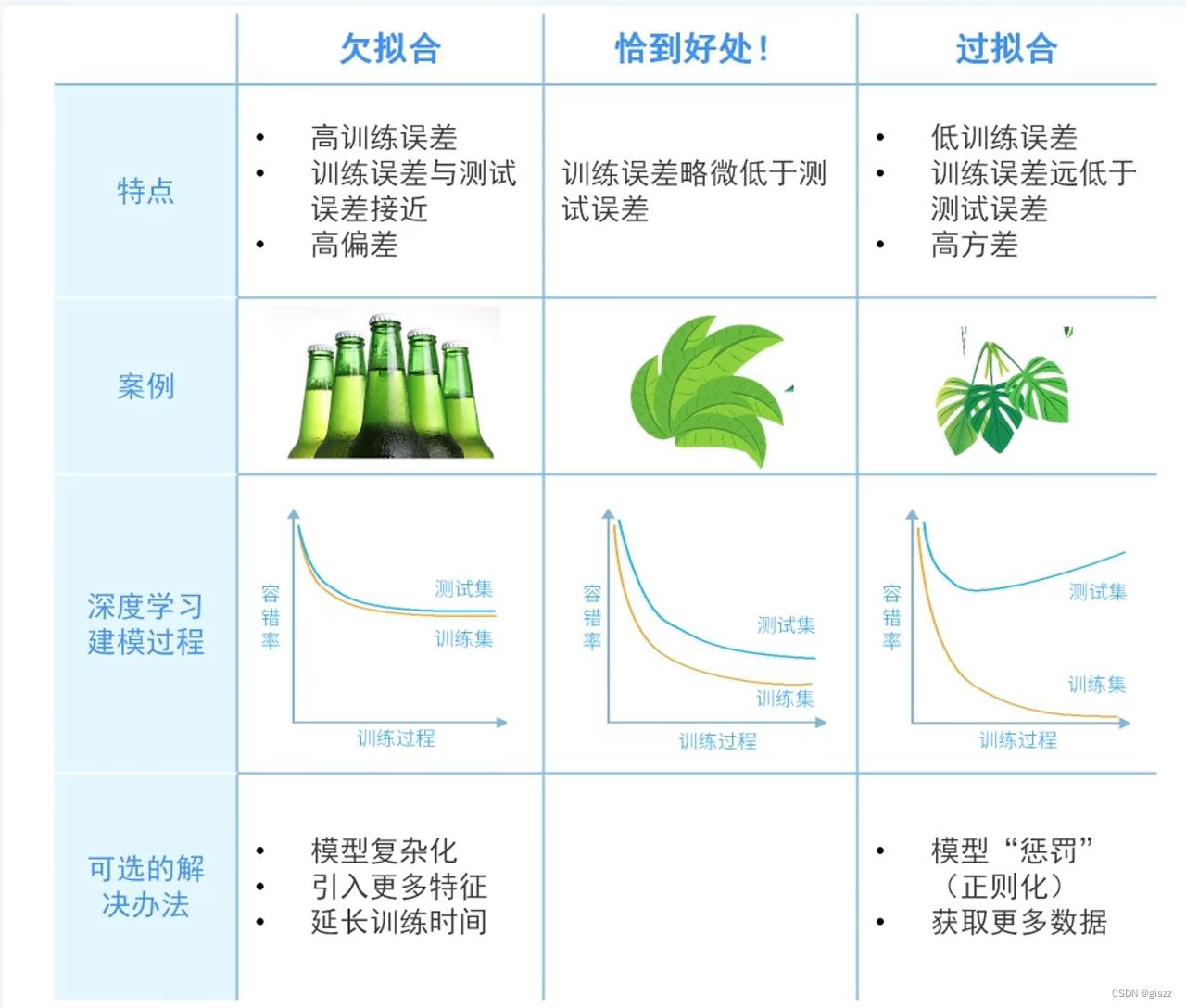
過擬合和欠擬合是機器學習和人工智能領域中兩種常見的問題,它們描述了模型在訓練數據和新數據上的表現差異。理解這兩種現象對于構建有效的模型至關重要。
過擬合:
定義:過擬合是指模型在訓練數據集上表現良好,但在測試數據集上表現較差。這通常是因為模型過于復雜,以至于它學到了訓練數據中的噪聲或特定特征,而沒有學到真實的、可以泛化到新數據的規律。
原理:在訓練過程中,模型的參數(特別是權重)被過度擬合,導致模型無法區分真實世界中的數據點和噪聲。模型變得對訓練數據過于敏感,失去了泛化到新數據的能力。
使用場景:過擬合通常發生在模型復雜度過高,或者訓練數據量不足的情況下。例如,在圖像識別任務中,如果模型參數過多,而訓練圖像數量有限,就容易出現過擬合。
避免方法:
- 增加訓練樣本數量:通過收集更多的數據或使用數據增強的技術來增加訓練樣本的數量,可以幫助模型學習到更多的真實規律,減少過擬合。
- 簡化模型結構:適當降低模型的復雜度,如減少網絡層數、神經元個數等,可以降低模型對訓練數據中的噪聲的敏感性。
- 使用權重正則化:在損失函數中加入對權重的懲罰項,如L1正則化或L2正則化,可以限制模型參數的規模,防止過擬合。
- 使用dropout:在訓練過程中隨機“關閉”一部分神經元,可以減少模型的參數數量,從而降低過擬合的風險。
- 數據擴增:通過對訓練數據進行變換(如旋轉、平移、縮放等)來人為地增加數據量,提高模型的泛化能力。
欠擬合:
定義:欠擬合指的是模型無法充分學習訓練集的規律,導致模型在訓練集和測試集上表現都不佳。這通常是因為模型過于簡單,無法捕捉到數據中的所有關系和結構。
原理:模型的復雜度不足以捕捉數據的內在規律,導致模型在訓練和預測時都表現不佳。欠擬合的模型具有較高的偏差(bias),這意味著它們在預測時會傾向于產生較大的誤差。
使用場景:欠擬合通常發生在模型復雜度過低,或者特征選擇不當的情況下。例如,在文本分類任務中,如果僅使用簡單的詞袋模型而忽略詞序和語義信息,就容易出現欠擬合。
避免方法:
- 添加新特征:當特征不足或者現有特征與樣本標簽的相關性不強時,模型容易出現欠擬合。可以嘗試添加更多的相關特征或使用特征工程技術來提取更有用的特征。
- 增加模型復雜度:通過增加模型的復雜度來提高其擬合能力。例如,在神經網絡模型中增加網絡層數或神經元個數等。
- 減小正則化系數:正則化是用來防止過擬合的,但當模型出現欠擬合現象時,則需要有針對性地減小正則化系數,以允許模型更靈活地擬合數據。
需要注意的是,在實際情況中,過擬合和欠擬合可能同時存在。因此,在選擇模型和優化策略時,需要綜合考慮偏差和方差之間的平衡,以及數據的特性。通過不斷地調整模型復雜度、特征選擇和訓練策略,可以找到最適合當前任務的模型。
?

)
解決)









中介者模式)


)


:Flink基于Kubernetes部署(7)-Kubernetes 集群搭建-3)
