文獻閱讀:Recent Advances of Monocular 2D and 3D Human Pose
Estimation: A Deep Learning Perspective
摘要:在本文中,作者提供了一個全面的 2d到3d視角來解決單目人體姿態估計的問題。首先,全面總結了人體的二維和三維表征。然后總結了自 2014年以來在統一框架下這些人體展示的主流和里程碑式的方法。
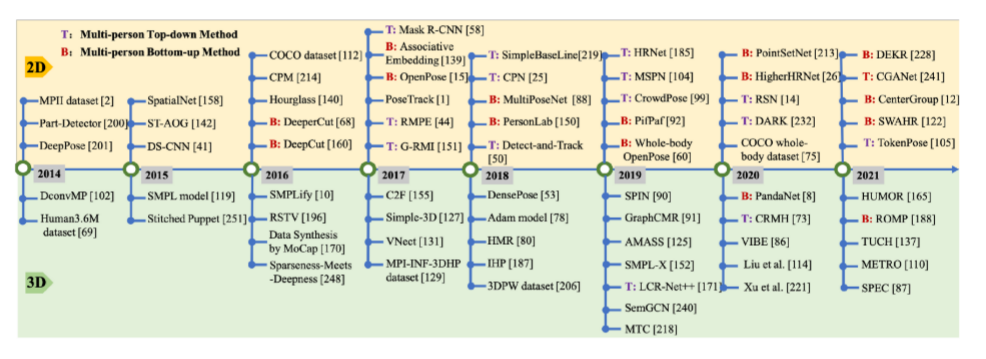
2D 3D的貢獻、想法、或者數據集的發展圖
用于mpe的深度學習框架
大多數單人姿態估計網絡可以被認為是由一個位姿encoder和位姿decoder組成,前者的目標是通過高低分辨率的過程提取高級特征。后者以基于檢測的方式或基于回歸的方式估計目標輸出、2D/3D關鍵點位置或3D網格。
多人來說,就分為自上而下和自下而上的方法,自上而下就是先把每個人從圖中分出來,然后再分別進行姿態的估計,自下而上就是先把所有關鍵點給找出來,然后把它們分類給具體的每一個人(2d的應用:openpose)。
數據集:應用最廣泛的還是Human3.6M,但他也只是包含7個人的15項室內活動。在室外的訓練數據太少了。
人體表征
從不同方面描述復雜的人體姿態,分為兩類:
1.基于關鍵點的表示
2.基于模型的表示
基于關鍵點的表示:
2D/3D關鍵點坐標、2D/3D熱圖、方位地圖(如openpose的部分親和力場)、分層骨載體(如CHP)
基于模型的表示:
基于零件的體積模型(如EllipBody 模型,以橢球體作為人體部件基本單位)、詳細統計3D人體模型(蒙皮多人線性模型SMPL)

單目2d姿態估計
單人:從輸入的數據來進行分類為圖像、視頻。
Deeppose:基于深度卷積神經網絡(DCNNs)的人體姿態估計方法,利用基于dcnn的位姿預測器級聯,DeepPose 將關鍵點估計作為一個回歸問題來表述。
IEF迭代誤差反饋網絡:利用自校正回歸模型。這是一種自上而下的反饋,逐步改變最初的關鍵點預測。
結構車身模型:結合基于dcnn的整體特征表示,探索圖形模型來描述具有空間關系的結構部分和局部部分。
多級管道:多級管道和多級特征融合對于捕捉人體細節非常有用。其中的代表作之一是堆疊式沙漏網絡。每個沙漏網絡由自下而上處理(從高分辨率到低分辨率)和自上而下處理(從低分辨率到高分辨率)之間的對稱分布組成。它利用跳躍層來保存每個分辨率的空間信息。結合中間監控,整個網絡連續堆疊多個沙漏模塊。這是其設計優化變體的堅實基礎。
CPM:多級網絡卷積式狀態機,使用中間輸入和監督來學習隱式的空間模型,而沒有顯式的圖形模型。它的序列多階段卷積體系結構日益細化關鍵點位置的預測。
姿態細化:對網絡輸出進行細化可以提高最終姿態估計的性能。比如建多源深度模型,從不同信息源中提取非線性表示,包括視覺外觀評分、外觀混合類型和變形。
多任務學習:多任務學習可以利用相關任務中的互補信息,為姿態估計提供額外的線索。Luvizon等人提出了一種聯合從視頻序列中進行 2D/3D姿態估計和人體動作識別的多任務框架。還有文獻利用對抗數據增強來解決隨機數據增強在網絡訓練中的局限性。設計了一種獎罰策略,用于增強網絡與目標(姿態估計)網絡的聯合訓練。
提高模型運行速度:提高模型效率的框架,包括使用輕量級算子、網絡二值化、模型精餾等。
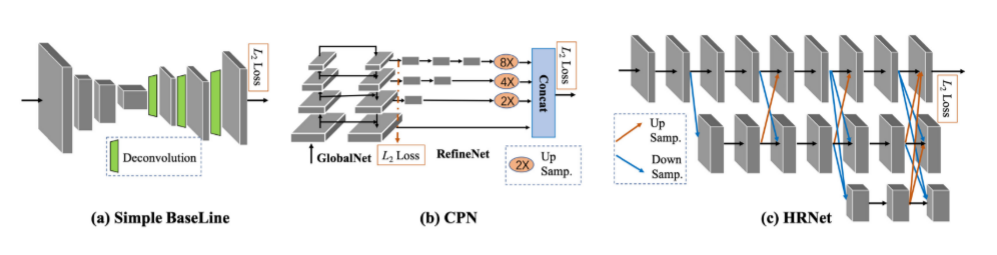
三個具有代表性的自頂向下二維多人姿態估計網絡
simple baseline:隨著精度性能的提升,模型的復雜度也越來越高,這使得找出究竟是哪種結構最為有效變得困難,作者嘗試提供一個簡單的比較基線,同時發現雖然簡單但是同樣獲得了很好的關鍵點定位的效果。提出的模型結構是一個特征提取網絡加反卷積層。沒有使用任何跳層連接,直接在最后一層特征圖上使用反卷積。
CPN:
Cascaded Pyramid Network(CPN)級聯金字塔網絡,該網絡可以有效緩解“hard” keypoints的檢測問題,CPN網絡分為兩個階段:GlobalNet和RefineNet。GlobalNet網絡是一個特征金字塔網絡,該網絡用于定位簡單的關鍵點,如眼睛和手等,但是對于遮擋點和不可見的點可能缺乏精確的定位;RefinNet網絡該網絡通過集合來自GolbalNet網絡的多級別特征來明確解決“難點”的檢測問題。
HRNet:該網絡主要是針對單一個體的姿態評估(即輸入網絡的圖像中應該只有一個人體目標)。人體姿態估計在現今的應用場景也比較多,比如說人體行為動作識別,人機交互(比如人作出某種動作可以觸發系統執行某些任務),動畫制作(比如根據人體的關鍵點信息生成對應卡通人物的動作)等等。
多人姿態估計
自頂向下、自底向上。
自頂向下
兩級管道:
Papandreou 等人提出了一種基于深度學習的兩階段自上而下的管道,名為 G-RMI。他們使用 Faster RCNN檢測器來檢測每個人,然后利用全卷積ResNet[59]來聯合預測關鍵點的密集熱圖和偏移。他們還引入了基于關鍵點的 NMS而不是盒級NMS,以提高關鍵點的可信度。
多任務學習:通過在姿態估計相關任務之間共享特征,多任務學習可以為姿態估計提供更好的特征表示。
Mask- RCNN:]首先檢測人的包圍框,然后裁剪相應提議的特征圖來預測人的關鍵點。多任務網絡,聯合預測關鍵點并對語義部分進行分割。ZoomNet:人體姿態估計器、手/臉檢測器和手/臉姿態估計器統一為一個網絡。該網絡首先定位身體關鍵點,然后放大手/臉區域,以更高的分辨率預測這些關鍵點。它可以處理人體不同部位的尺度差異。針對全文數據不足的問題,通過對COCO數據集進行全身標注擴展,提出了COCO- wholbody數據集。
多階段或多分支融合:
級聯金字塔網絡(Cascade Pyramid Network, CPN),MSPN是在多級管道中擴展了CPN。它以CPN的全局網絡為每個單級模塊,通過跨級特征聚合融合不同階段的特征,并通過由粗到細的損耗函數對整個網絡進行監控。HRnet指出高分辨率表示對于硬鍵點檢測非常重要。HRNet 在整個網絡中保持高分辨率表示,并逐漸增加高分辨率到低分辨率的子網,形成多分辨率特征。graph - pcnn:利用帶有殘差步驟網絡(RSN)模塊的多級管道來聚合內部層面的特征。在RSN的精細局部表示的基礎上,
提出了姿態精煉機(Pose Refine Machine, PRM)模塊,進一步平衡局部/全局表示,細化輸出關鍵點。
處理復雜場景:
RMPE設計了對稱空間變壓器網絡來檢測每個人,參數化姿態NMS來過濾冗余姿態,姿態引導的人建議發生器來提高網絡的多人能力,以提高對不準確的人的檢測能力。為了解決擁擠場景中的問題,Li 等首先在每個裁剪的包圍框中獲取聯合候選,然后在圖模型中解決聯合關聯問題。他們還收集了一個名為 CrowdPose 的擁擠人體姿態估計數據集,并定義了人群指數
(Crowd Index)來衡量圖像的擁擠程度。OASNet利用Siamese 網絡的注意機制,去除感知遮擋的模糊,重構無遮擋特征。
Bin et al為了擴大挑戰性案例的訓練集,提出通過結合分割的身體部位來模擬挑戰性案例來增強圖像。利用生成網絡動態調整增廣參數,生成最混亂的訓練樣本。MIPNet[84]重新考慮了自頂向下人體姿態估計器的關鍵假設,即輸入包圍框中只有一個人。
提高效率:小型快速網絡受到人們的關注。
FCPose提出了一種動態的實例感知框架,該框架消除了 roi 和關鍵點分組后處理,無論圖像中有多少人,推理時間都是快速而恒定的。CGANet提出了ROIGuider 在全局上下文信息的引導下聚合多尺度盒體特征,所提出的骨干 TNet 能夠高效地實現多尺度特征融合。為了更好地平衡準確性和效率,一些著作利用神經結構搜索(NAS)方法來設計姿態特定網絡。PoseNAS它直接搜索具有堆疊可搜索單元的面向數據的姿態網絡,可以為特定姿態任務提供最優的特征提取器和特征融合模塊。ViPNAS[222]通過精心設計五個維度的搜索空間來搜索空間,包括網絡深度、寬度、內核大小、組號和注意事項。通過搜索視頻中的時間特征融合和自動分配計算,進一步將其應用到視頻姿態估計中。TokenPose**明確關鍵點之間的約束關系**提出了基于Token表示的Transformer體系結構。每個關鍵點被顯式嵌入作為標記,以同時學習圖像中的約束關系和外觀線索。TokenPose 表明,基于變壓器的模型與基于cnn的最先進的模型相當,同時更輕量級。### 自底向上:關鍵點分組:除了為了更精確的關鍵點檢測而進行的網絡設計外,如何對關鍵點之間的連接信息進行編碼是將關鍵點
分組給不同人群的核心。
部分親和字段:目前最流行的自底向上姿態估計方法OpenPose提出通過局部親和域(paf)聯合學習關鍵點
位置及其關聯。PAF通過一組二維向量場對分支的位置和方向進行編碼。PAF的方向是從肢體的一部分指向另一
部分。然后,多人關聯進行二部匹配,對候選關鍵點進行關聯。
PIF局部強度場來定位人體部位,PifPaf網中合生成 PIF和PAF來處理低分辨率和遮擋場景。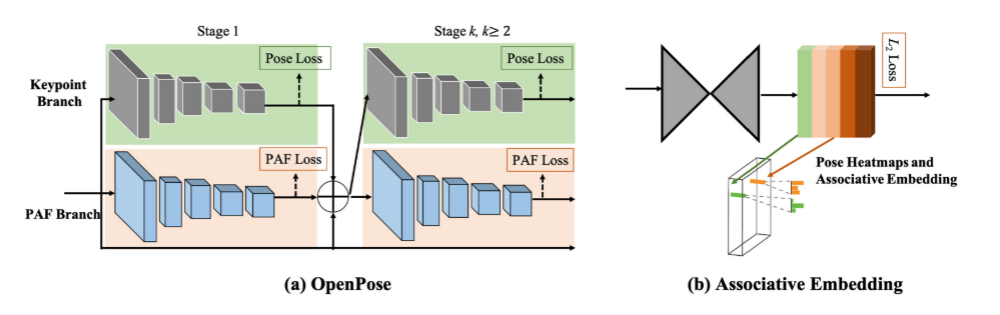Hidalgo 等人提出了第一個用于全身多人姿態估計的
單網絡方法,該方法可以同時定位圖像中身體、面部、手和腳的關鍵點。
還有文獻設計了身體部分感知的PAF對關鍵點之間的連接進行編碼,并利用注意機制對堆疊的沙漏網絡進行了改進。
兩種代表性的自底向上的2d多人姿態估計方法:openpose和關聯嵌入
關聯嵌入:這種關聯嵌入是一種檢測分組的方法,它通過檢測關鍵點并將關鍵點分組成具有嵌入特征或標記
的人。
Newell等人提出了生成關鍵點熱圖及其嵌入標簽網絡對身體的每個關節生成檢測熱圖,同時預測關聯嵌入標簽。他們為每個關節選取最熱門的檢測,并將其與其他共享相同嵌入標簽的檢測相匹配,從而產生一組最終的個體姿態預測。HigherHRNet:它從高分辨率的特征金字塔中學習尺度感知表示。利用了HRNet 中聚合的特征[185],以及通過轉置卷積上采樣的高分辨率特征,很好地處理了尺度變化,實現了自底向上姿態估計的最新技術。scale and weight adaptive heatmap regression (SWAHR),自適應調整 heatmap中每個關鍵點的標準差,平衡前背景樣本。多任務學習:MultiPoseNet:該模型可以聯合處理人的檢測、關
鍵點的檢測和人的分割。設計了位姿殘差網絡,通過測量關鍵點和被檢測人包圍盒位置的相似性來確定關鍵點和被檢測人包圍盒的位置。
PersonLab:是一個多任務網絡,可以聯合預測關鍵點熱圖和人分割圖。用近程和中程的兩兩偏移對關鍵點進行分組。同時,利用長程偏移和人體姿態檢測來區分人臉分割。**密集關鍵點回歸**:另一種自下而上的范式是直接回歸同一個人的關鍵點位置。位姿劃分網絡(PPN):它對所有關鍵點候選點使用質心嵌入。結構化姿態表示(Structured Pose Representation,
SPR:它利用根關節來表示人,并將關鍵點的位置編碼為相應根的位移。
逐像素關鍵點回歸方法:CenterNet、ConerNet、PointSetNet。對同一個人的關鍵點位置進行了密集預測。DEKR:專注于學習精確關鍵點區域的表示,并使用多分支結構進行獨立回歸:每個分支通過專用的自適應卷積學習表示,并回歸一個關鍵點。CenterGroup:是一個基于注意的框架,它使用轉換器獲取所有關鍵點和中心的上下文感知嵌入。SIMPLE:模擬了來自高性能自上而下管道的知識,并
將人體檢測和姿態估計作為一個統一的點學習框架,以相互補充。
PINet:直接從人體可見部位推斷出一個人的完整姿勢,而不是預測單個關鍵點。它是一種姿態級回歸策略,沒有邊界盒檢測和關鍵點分組。### 視頻中的2d姿態估計:視頻中的二維姿態估計也被 dcnn所提升,視頻姿態估計必須考慮幀間的時間關系,以消除運動模糊和幾何不一致性。利用好時空信息對視頻中的人體姿態估計方法進行分類。單人:是通過跨幀傳播時間線索來細化單幀
姿態結果。
Pfister 是視頻中最早基于深度學習的姿態估計的研究人員之一,他們通過在數據顏色通道中插入多幀圖像來利用時間信息來替代基于圖像的網絡中輸入的三通道 RGB圖像。?動作識別的姿態估計:時空與或圖(ST-AOG)模型,視頻姿態估計與動作識別相結合。通過增加基于光流和外觀特征的活動識別分支,使兩者相互受益。?基于光流的特征傳播:SpatialNet,該網絡通過光流將鄰幀熱圖時間上扭曲到當前幀。他們還利用參數池化層將對齊的熱圖組合成池化的置信度熱圖。ConvNet 姿態估計器,通過空間圖像匹配和光流傳播,在整個視頻中傳播高質量的姿態標注。Thin-Slicing:一個基于流的彎曲層,將先前的熱圖與當前幀對齊,然后是一個時空推理層。**時空傳播利用了具有時空關系邊的位姿配置圖的迭代消息傳遞。**?基于序列模型的特征傳播:鏈式模型:Gkioxari1等采用序列-序列循環模型來解決視頻中的結構化姿態預測。循環模型:每個主體關鍵點的預測依賴于所有之前預測的關鍵點。LSTM Pose Machine:通過增強內存的 LSTM框架來捕捉視頻中的時間依賴性。給定一幀,encoder -RNN- decoder 管道首先通過編碼器學習高級圖像表示,然后通過 RNN單元傳播時間信息并產生隱藏狀態。**他們最終通過一個以隱藏狀態作為輸入的解碼器來預測當前幀的關鍵點。 類似在**UniPose-LSTM也用了相同的概念。Pose Net 結合了運動補償ConvLSTM來傳播空間對齊的特征。**它利用壓縮流來有效地從視頻中解碼姿態序列。**### 視頻中多人姿態估計和追蹤:PoseTrack數據集是大規模和在野外的多人數據集。自上而下:自頂向下的方法遵循檢測跟蹤范式。它們**首先檢測每個幀中的人物和關鍵點,然后在幀間傳
播邊界框或關鍵點。一些方法建立在基于剪輯的技術之上。**
3D Mask R- CNN:采用全3D卷積網絡來檢測視頻片段中每個人的關鍵點。然后,使用一個關鍵點跟蹤器通過比較檢測到的包圍盒的距離來連接預測還有文獻(M.-C. Wang, J. Tighe, and D. Modolo. 2020. Combining detection and tracking for human pose estimation in videos.
In CVPR.)使用了基于剪輯的跟蹤器,通過精心設計的3D卷積層擴展HRNet,學習關鍵點之間的時間對應關系。設計了一種時空融合算法,通過時空平滑來估計出最優的關鍵點輸出。
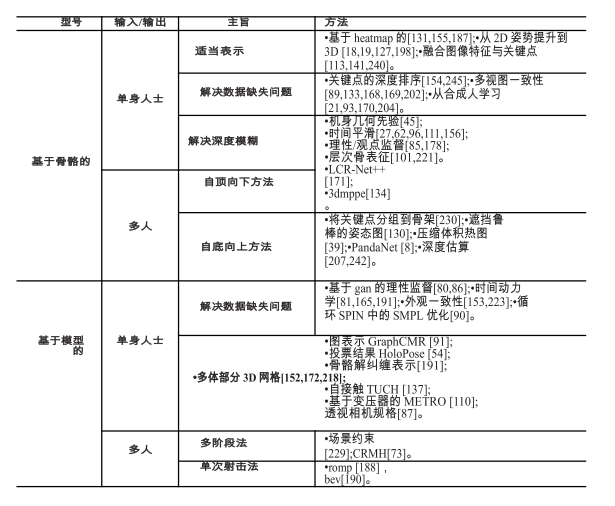
DCPose:解決運動模糊、視頻散焦或姿態遮擋問題,提出了一種多幀人體姿態估計框架,該框架利用三個模塊分別對關鍵點時空上下文進行編碼,在雙方向上計算加權姿態殘差,并對姿態估計進行細化。基于單幀檢測基礎上:(B. Xiao, H.-P. Wu, and Y.-C. Wei. 2018. Simple baselines for human pose estimation and tracking. In ECCV.)基于光流的時間位姿相似度來關聯跨不同幀的關鍵點。PGPT:解決了單幀缺失檢測的問題,將基于圖像的檢測器與在線人員位置預測器相結合來補償缺失的包圍盒。還引入了一個分層的姿勢引導的圖卷積網絡,該網絡利用人類的結構關系來增強人的表示和數據關聯。Y.-D. Yang, Z. Ren, H.-X. Li, C.-L. Zhou, X.-C. Wang, and G. Hua. 2021. Learning dynamics via graph neural networks for human pose estimation and tracking. In CVPR.:設計了一個圖形神經網絡,明確地解釋了時空和視覺信息。它輸入歷史位姿,直接預測下一幀對應的位姿,然后將預測的位姿與檢測到的位姿進行聚合。POINet:研究了一個姿態引導的 ovonic 洞察網絡,以學習統一的端到端網絡中的特征提取、相似性度量和身份分配。R. Umer, A. Doering, B. Leibe, and J. Gall. 2020. Self-supervised keypoint correspondences for multi-person pose estimation and tracking in videos. In ECCV.提出了一種自監督關鍵點通信,它不僅可以恢復缺失的位姿檢測,還可以跨幀將檢測到的位姿和恢復到的位姿關聯起來。KeyTrack:提出了一種基于變壓器的跟蹤器,它只依賴于 15個關鍵點。基于變壓器的網絡利用二進制分類來預測一個姿勢是否在時間上跟隨另一個。自下而上: **先使用單幀姿態估計預測每幀中的所有關鍵點,然后以時空優化的方式跨幀分配關鍵點。**有基于圖劃分的方法擴展了圖像級自底向上的多人姿態估計;PoseFlow:利用在不同幀中測量姿勢距離的姿勢流來跟蹤同一個人。還有文獻受到OpenPose的空間部分親和力場的啟發,利用時間流場來指示關鍵點跨幀的傳播方向。還有使用了關聯嵌入,對其進行擴展,構建了**時空嵌入**。總結:綜上所述,基于cnn的網絡設計,借助身體部位結構關系、多級管道、多級特征融合、姿態細化、多任務學習和效率感知設計,極大地推動了二維位姿估計的發展。在多人情況下,**優秀的自頂向下方法依賴于精確的檢測網絡和可靠的單人姿態估計網絡**。對于自底向上的方法,最**重要的部分是如何將檢測到的關鍵點在不同的人之間進行關聯。**在視頻級姿態估計與跟蹤中,有代表性的研究集中在如何有效傳播時空信息以保證預測的一致性和平滑性。## **單目三維姿態估計**:缺乏室外3D數據、深度模糊。數據集標注困難又貴。大多數數據集偏向于特定的環境。因此使用2d位姿數據集來提高泛化能力。(M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele. 2014. 2D human pose estimation: New benchmark and state of the art analysis. In CVPR.)(S. Johnson and M. Everingham. 2010. Clustered pose and nonlinear appearance models for human pose estimation.In BMVC.)(T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C.-L. Zitnick. 2014. Microsoft COCO:Common objects in context. In ECCV.)**單目輸入在描述深度信息時是不明確的。由于多個三維姿態可以映射到相同的二維觀測,因此很難確定精確的三維姿態。特別是對于多階段方法,這種模糊性更加嚴重。許多方法試圖利用各種先驗信息來解決這一問題**,如幾何先驗知識,統計模型和時間平滑。### 基于骨骼:直接估計人體關節的三維坐標。### 基于模型:采用統計的三維模型:SMPL
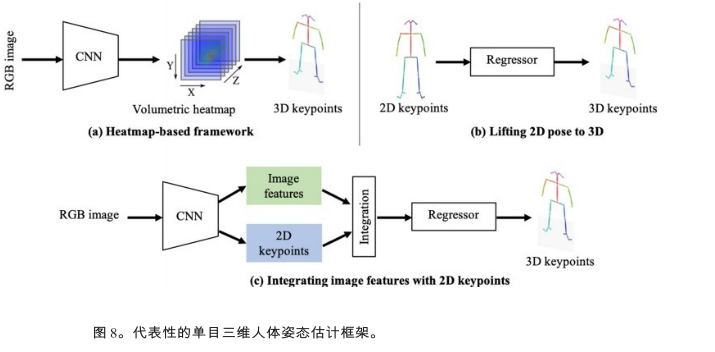
代表性的單目三維人體姿態框架
單人3d姿態估計方法:(**1)體積熱圖**基于熱圖的方法將每個三維關鍵點表示為熱圖中的三維高斯分布。在后處理過程中,通過獲取局部最大值,從估計的體積熱圖中得到三維關鍵點坐標。如heatmap方法,通過端到端框架直接從單目圖像中估算出體積熱圖。C2F(由粗至細)網絡,將沙漏網絡進行疊加,并逐步向細粒度結果的預測熱圖的體積方向進行擴展。VNect:是一種實時單目三維姿態估計方法。它使相干運動骨架在后處理中擬合,從而產生基于相干運動骨架的時間穩定位姿結果。Integral Human Pose(IHP)提出了一種積分運算,在推理熱圖直接以可微的方式轉換為關鍵點坐標。**它在基于熱圖的方法和基于回歸的方法之間架起了一座橋梁。****(2)由2d姿態估計提升到3d姿態估計**step1:從單目圖像中估計 2D位姿step2:將估計的2D位姿提升到3Dsimple - 3d:這是一種著名的簡單基線方法,從 2D位姿估計每個關鍵點的深度。它只包含兩個完全連接的塊,同時在相關的基準測試中獲得良好的性能。**位姿匹配**解決了 2d - 3d關鍵點提升問題。為了豐富匹配庫,他們利用隨機相機將 3D姿態投影到2D圖像平面上,生成大量的2D-3D姿態對。然后,他們得到一個大型的2D-3D姿勢對庫。給定一張2D圖像,他們只
需要預測2D姿勢,并從庫中搜索最相似的 2D- 3d姿勢對。選擇成對的三維姿態作為三維姿態估計結果。(C.-H. Chen and D. Ramanan. 2017. 3D human pose estimation = 2D pose estimation+ matching. In CVPR.)
一個多級卷積網絡來遞歸地優化估計的 3D姿態:他們使用估計的 3D姿態的反投影來
細化中間的 2D姿態,這逐步提高了 2D和3D姿態估計的準確性。(Lifting from the deep: Convolutional 3D pose estimation from a single image. In CVPR.)
C.-H. Chen, A. Tyagi, A. Agrawal, D. Drover, S. Stojanov, and J.-M. Rehg. 2019. Unsupervised 3D pose estimation
with geometric self-supervision. In CVPR.:二維位姿輸入與估計的三維位姿的二維投影之間的雙循環一致性,以無監督的方式學習二維到三維的提升函數。它們在一個循環中隨機變換提升的3D姿態,以避免在一個恒定的深度下收斂到局部最小值。
**(3)圖像特征與2d姿態融合**B.-X. Nie, P. Wei, and S.-C. Zhu. 2017. Monocular 3D human pose estimation by predicting depth on joints. In ICCV.:關鍵點的局部**圖像紋理特征整合到全局二維骨架**中。然后,建立了LSTM網絡的兩級層次結構,逐步對全局和局部特征進行建模。SemGCN:提取聯合級圖像特征,并將其與關鍵點坐標進行整合,形成多個圖節點。利用圖像特征,利用 GCN或LSTM來探討關鍵點節
點之間的關系。
**解決數據不足的問題:大多數方法嘗試以無監督或弱監督。**Pavlakos認為優勢在于監管重點之間的弱順序深度關系。實驗表明,**與基于地面真實三維姿態標注的直接監控相比,順序監控
也能取得比較好的效果。**
Hemlets通過 heatmap **三態損失**將相鄰關鍵點的顯式深度排序編碼為ground truth。#### 使用多視圖一致性進行監督(**但是還是采用的單目圖像作為輸入**)如果只考慮多視圖一致性,則會得到退化解決方案,模型可能會陷入局部最小值,并在不同輸入下產生相似的零姿態。(H. Rhodin, J. Sp?rri, I. Katircioglu, Victor V. Constantin, F. Meyer, E. Müller, M. Salzmann, and P. Fua. 2018. Learning monocular 3D human pose estimation from multi-view images. In CVPR.)Rhodin提出使用少量的標記數據來避免局部最小值,并修正預測。提出使用連續圖像為身體表征學習提供先驗時間一致性。EpipolarPose:利用多視圖 2D姿勢,通過極向幾何圖形生成 3D姿勢標注。通過這種方式,可以以自我監督的方式訓練整個框架。Umar:通過一種新的基于對準的目標函數來解決退化陷阱,而不需要外部攝像機校準。他們使用無標簽的多視圖圖像和 2D姿勢數據集訓練模型。Mitra:提出以半監督的方式學習視點不變的姿態嵌入。通過使左盆骨平行于XZ平面,訓練模型來估計視圖不變的 3D姿態。**從合成的數據中學習**:1)二維圖像拼接管道Rogez試圖從3D動作捕捉(MoCap)數據集中生成 3D姿勢的2D圖像。Chen 等人的和Varol 等人遵循 3D模態渲染流水線。他們使用 SCAPE或SMPL 3D人體模型,將有紋理的統計人體模型投影到 2D野外背景圖像上進行數據生成。**二維圖像拼接管道有潛力生成更逼真的人物圖像,而三維模型投影管道可以獲得更全面的三維標注**2)三維模型渲染管道**PGP-human**:利用3d - 2d投影構建了一個自監督的訓練管道。PGP-human利用了從野外視頻中采樣的圖像對,其中包含同一個人在不同的背景下執行不同的動作。該模型通過訓練,將圖像對中提取的外觀和姿態信息進行混合,進行圖像再合成。**解決內在的深度模糊**:采用各種先驗約束來確定特定的位姿。許多方法使用時間一致性和動力學來解決單個2D位姿的模糊性。RSTV:將視頻序列中裁剪出來的單人圖像塊作為輸入,在中心幀中估計出三維姿態。
Fang等人通過層次結構明確地將身體先驗(包括運動學、對稱性和驅動關節協調)納入模型的雙向RNN。
Lin 等人、Hossain等人、Lee 等人開發了由LSTM單元組成的序列-序列網絡,從二維位姿序列估計出三維位姿序列。VideoPose3D和OANet對二維位姿序列采用時間卷積來保證時間一致性。完整的卷積結構使高效的并行計算成為可能。OANet 使用圓柱體人體模型生成遮擋標簽,幫助模型學習人體各部位之間的碰撞。Sharma 等人以生成對抗的方式解決了歧義。他們訓練了一個有條件的 VAE網絡,以證明在2D位姿條件下生成的 3d位姿樣本的合理性。ActiveMoCap:試圖估計不同預測的不確定性,這些預測用于選擇模糊度較低的最佳輸出。它幫助模型學習三維姿態估計的最佳視點。分層骨表示的模型(Cascaded deep monocular 3D human pose estimation with evolutionary training data. In CVPR.)J.-W. Xu, Z.-B. Yu, B.-B. Ni, J.-C. Yang, X.-K. Yang, and W.-J. Zhang. 2020. Deep kinematics analysis for monocular
3D human pose estimation. In CVPR.
該模型明確地模擬了相鄰關節的幾何依賴關系,主要關注于監測骨骼長度和關節方向。得益于分層的骨骼表示,三維人體骨骼是可分離的,可以很容易地混合合成新的骨骼。### 多人三維姿態估計:還是自上而下和自下而上。自上而下:LCR-Net++建立在通用的基于錨點的兩級檢測框架之上。他們首先從主播提議中收集姿勢候選人,然后根據得分排名確定最終輸出。Camera distance-aware top-down approach for 3D multi-person pose estimation from a single RGB image. In ICCV.是建立在基于錨點的檢測框架上。他們從檢測到的人體區域及其包圍盒位置的特征中提取獨立的分支來估計三維絕對根定位和相對根姿態估計自底向上:Zanfir提出了一種自底向上的多階段框架,用于單目多人 3D姿態估計。它首先從單個圖像中估計體積熱圖,以確定 3D關鍵點位置。然后,對檢測到的關鍵點之間所有可能連接的置信度得分進行預測,形成肢體。最后,他們進行骨骼分組,將四肢分配給不同的人。Mehta提出了開發了一種遮擋-魯棒姿態圖(occlusion - robust Pose- Maps, ORPM),將冗余遮擋信息包含在部分親和性圖中。此外,他們提出了第一個多人三維姿勢數據集 MuCo3DHP,極大地促進了該領域的發展。Fabbri提出了編碼器-解碼器的方式估計體積熱圖,并從中回歸多人的三維姿態。PandaNet是一個基于錨點的多人 3D姿
態估計單鏡頭模型。它直接預測每個錨點位置的2D/3D姿勢。
SMAP估計了多個map,表示體根深度和零件在每個位置的相對深度。hor它通過實例級、部分級和聯合級對多人順序關系進行分層估計。[HMOR: Hierarchical multi-person ordinal relations for
monocular multi-person 3D pose estimation. In ECCV](HMOR: Hierarchical multi-person ordinal relations for
monocular multi-person 3D pose estimation. In ECCV)
### 基于模型的三維姿態估計**通過這種方式,他們將3D位姿估計表示為估計SMPL的位姿和形狀參數,一般框架是直接從單人2D RGB圖像中估計相機和 SMPL參數。**單人方法分為1解決3d數據短缺的問題,2促進基于模型的3d姿態估計更恰當的表示。多人方法:1多階段方法 2單次方法解決數據缺失:人體網格恢復(HMR)[80]利用了從 2D
姿勢和 3D動作捕捉(MoCap)數據集的未配對數據中學習的方法。為了引導模型從已有的數據中明確地學習、一些方法對二維圖像的固有特性進行了監督。
A. Kanazawa, J. Zhang, P. Felsen, and J. Malik. 2019. Learning 3D human dynamics from video. In CVPR.從時間動態中學習,**訓練一個3D人體動力學模型**來估計當前、過去和未來幀的 3D姿態。Kocabas開發了一個名為**VIBE**的時間網絡。在HMR之后,他們使用了一個運動鑒別器,以生成對抗的方式監督預測運動序列的合理性。通過門控循環單元(Gated Recurrent Units, GRUs),描述運動序列的 SMPL參數在每個時間步長被映射到一個潛在的表示。**HuMoR**使用條件變分自動編碼器建立時間先驗,以優化輸入運動的動力學和魯棒性。TexturePose除了利用時間信息外,還利用同一個人在多視點或相鄰視頻幀之間的外觀一致性進行監控。身體紋理從2D圖像映射到UV映射,這在語義上對齊多視圖或順序紋理。Holo- Pose提出了一個多任務網絡,它可以估計
DensePose、2D和3D關鍵點,以及基于零件的3D重建。提出了一種迭代優化的方法來改進基于模型的二維三維關鍵點的三維估計與 DensePose 的對齊。此外,**人體網格變形(Human Mesh Deformation, HMD)**利用額外的信息,包括身體關鍵點、輪廓和每像素陰影,來細化估計的 3D網格。通過層次網格投影和變形細化,人體網格與輸入的 2D圖像中的人很好地對齊。
簡化smpl,通過將3D人體網格擬合到預測的 2D關鍵點上,并將再投影誤差最小化,迭代地細化 3D人體網格。**SPIN**:結合了基于回歸和基于優化的方法的優點。他們利用 simplify來優化訓練循環中的估計結果,以提供額外的3D監督。模型表示:探索基于模型的三維姿態估計更合適的表示方法。比如GraphCMR:利用基于圖形的表示來回歸 SMPL體網格。他們將SMPL模板網格的每個頂點作為圖卷積網絡的一個節點。每個節點附加一個圖像特征向量,估計對應頂點的三維坐標。然后,可以從這些頂點估計 SMPL參數。**I2L-MeshNet**提出了一種 image-to-lixel(線+像素)預測網絡,該網絡預測一維熱圖上的逐像素可能性,以回歸每個網格頂點坐標。使用差分渲染器將估計的體網格渲染回 IUV圖,并與輸入進行比較以進行監督。Sun利用雙線性變換開發了一種骨架解糾纏表示,以解決二維位姿和其他細節的特征耦合問題。
METRO采用基于變壓器的網絡,從圖像特征估計三維體網格。通過將 CNN特征附加到模板網格的節點和頂
點上,利用基于變壓器的模型對三維坐標進行回歸輸出。
一些作品探索了全身 3D網格恢復的表現,包括臉和手。
SMPL+H:將三維手模型集成到 SMPL身體模
型中,共同恢復身體和手的三維網格。
Xiang提出了MTC方法,利用分離的CNN網絡估計身體、手和臉,然后將Adam模型聯合擬合到所有身體部位的輸出上。**SMPL- x:**將FLAME head 模型與SMPL+H相結
合,通過將模型擬合到三維掃描數據中來學習與姿態相關的混合形狀。
SMPLify-X:通過將SMPL-X迭代擬合人臉、手和身體的二維關鍵點,恢復人體全身三維網格。Sun:提出了一種解糾纏框架及其基于綜合的學習管道,可以一次性同時估計多個身體部位的網格。
此外,其他作品開始探索顯式的高級表示,以模擬圖像中一些復雜的角色,如身體自接觸、相機姿態
和地面約束。
**TUCH**明確地模仿和學習身體的自我接觸。他們觀察到,自接觸的頂點在歐幾里得距離上是接近的,而在測地線距離上彼此是遙遠的。基于這一觀察結果,設計了一種基于優化的方法,以避免相互滲透,同時鼓勵聯系。**SPEC**估計部分透視相機參數,使三維網格恢復更加準確。了解相機的姿態有助于克服透視投影帶來的失真。**Rempe**提出通過檢測腳地接觸來細化三維人體運動序列,減少了腳滑和腳地滲透。## 多人3D網格恢復雖然單目三維場景中人體姿態和形狀的估計已經取得了很大的進展,但處理存在**截斷、環境遮擋**和**人-人遮擋**的多人場景仍然至關重要。**現有的多階段方法為單人管道配備了一個 2D人探測器,以處理多人場景。**與 2D/3D關鍵點估算僅估算幾十個人體關節不同,近期的作品也試圖探索 3D網格恢復的特殊性。Zanfir 等人提出在多人場景中使用自然場景約束。為了得到初始的三維體網格,他們將SMPL模型與從圖像中估計出的三維姿態及其語義分割進行了擬合。Jiang 等提出使用**多人相干重建**(coherent reconstruction of multiple human, CRMH)實現多人三維網格恢復。他們基于 **fast - rcnn**構建了他們的方法,其中 roi 對齊的特征被用來預測SMPL參數。具體來說,他們開發了一種可微分插值損失,以避免體網格之間的碰撞。Sun 等人提出了一種實時的單階段方法,**ROMP**,用于多人網格恢復。在ROMP中,人體的二維中心位置和三維網格分別表示為二維熱圖和網格參數圖。這種基于中心的顯式表示保證了像素級特征編碼。Sun等人在ROMP簡潔的單階段架構的基礎上,進一步發展了 **BEV**,從單目圖像回歸人之間的相對位置,特別是在深度上。
他們開發了一個鳥瞰視圖表示來明確地推斷深度。他們還會逐漸喪失對年齡的意識,從而利用從嬰兒到成人的 3D
體型空間。他們還創建了一個名為“相對人類”(Relative Human)的數據集,以有效地了解野外圖像中的相對深度和年齡。
## 評價指標二維姿態估計:PCP (Percentage of Correct Parts)來衡量身體部位預測的準確性。PCK (Percentage of Correct Keypoints)被廣泛用于測量二維關鍵點預測。AP (Average Precision)被廣泛用于測量二維關鍵點預測。多人姿態估計,平均精度(AP)是通過測量對象關鍵點相似度(OKS)來計算的。三維姿態估計:關節平均位置誤差(Mean Per Joint Position Error, MPJPE)Procrustes Aligned MPJPE (PA-MPJPE)是對MPJPE 的一種改進,該方法通過將預測的位姿與以毫米為單位的地面真
實度剛性對齊得到。
3D PCK是PCK度量的 3D 版本。平均聯合角誤差(MPJAE)測量的角度之間的預測關鍵點方向和地面真實方向的程度。Procrustes Aligned MPJAE (PA-MPJAE)測量所有預測方向上由旋轉矩陣歸一化的 MPJAE。## 數據集### 2dMPII 數據集是一個大規模的圖像級數據集,包含豐富的活動和捕獲環境。Microsoft Common Objects in COntext (MSCOCO)數據集包含了用于對象檢測、全景分割和關鍵點檢測的注釋。PoseTrack 數據集是第一個大規模視頻級多人姿態估計和跟蹤數據集。### 3dHuman3.6M是應用最廣泛的單人 3D人體姿態基準。HumanEva是一個單人 3D 姿勢數據集,包含兩個子集HumanEva- i 和HumanEva- ii。mpi - info - 3dhp是在一個擁有 14 臺攝像機的工作室中拍攝的,使用的是一種商業無標記的運動捕捉設備,用于獲取地面真實的 3D姿勢。MoVi是一個大規模的單人視頻數據集,具有同步的 3D身體姿勢和網格標注。3dw是一個單視圖、多人、野外的 3D人體姿勢數據集,包含 60 個視頻序列(24 列、24 測試和 12 個驗證),包含爬山、高爾夫和在海灘上放松等豐富的活動。
數據集在不同方法的姿態空間分析
不同活動在位姿空間和不同聚類中的分布如所示。位
姿空間的樣本密度非常不均勻。大多數樣本都是聚集在一起的。從四個基準的聚類結果中可以得出類似的結論。我們觀察到大多數樣本的 3D姿勢接近行走或站立的姿勢。在 Human3.6M中,除了行走和站立,坐著的樣本也聚集在一起。**根據腿部運動所形成的聚類結果,證明下肢運動相對于較為復雜的上肢運動而言,相對簡單而相似。**視頻中
的演員往往會更多地移動他們的上半身而不是他們的腿。**用這些數據集訓練的模型在估計上肢的 3D姿勢方面比腿的效果更好。極端的姿勢(即異常值)在樣本中很少見。**位姿空間的分布是有偏差的,這限制了這些數據集的多樣性。
未來方向
復雜姿態和擁擠場景的姿態估計。如體操、跳水和跳高等體育比賽中,運動員可能會在很短的時間內表現出極端的姿勢。
3D Mesh Recovery 的基準、協議和工具箱。
逼真的身體與表情的臉,手,頭發和衣服。
與3D世界和其他代理的事物互動
帶有情感、語言和交流的虛擬數字人類一代。虛擬數字人是指具有數字外貌特征的虛擬人。
數據集附錄
?2D姿態數據集:Leeds Sports Pose (LSP) Dataset來自Flickr,使用8項體育活動(田徑、羽毛球、棒球、體操、
跑跑、足球、網球和排球)的標簽。它包含 2,000 張圖像,其中 1,000 張用于訓練,1,000 張用于測試。每個人全
身有14個關鍵點。與這些新發布的數據集相比,LSP的規模相對較小。它是對單個人姿態估計的初始性能評估。
電影幀標記(FLIC)數據集包含了從好萊塢電影中收集的 5003張圖像。他們在30部電影中每 10幀運行一個人探
測器。最初,2萬名候選人會被眾包市場亞馬遜土耳其機器人(Amazon Mechanical Turk)選中,在上半身貼上 10個
關鍵點的標簽。人被遮擋或嚴重非正面的圖像會被過濾掉。最后,選取1,016幅圖像作為測試集。
AI-Challenger 數據集,也稱為人體骨骼系統關鍵點檢測數據集(HKD),包含 300K高分辨率的關鍵點檢測和中文字幕圖像,81658 幅圖像用于零拍識別。大型數據集有多人和各種姿勢。每個人都有一個邊界框和 14個關鍵點。整個數據集分為訓練集、驗證集、測試A集和測試B集,分別使用210K、30K、30K和30K的圖像。由于其規模大、
分辨率高、場景豐富,AI-Challenger 數據集作為2D/3D姿態估計網絡訓練和姿態相關任務的輔助數據集已被廣泛應用。
CrowdPose Dataset旨在更好地評估擁擠場景中的人體姿態估計方法。這些圖像是通過測量人群指數從MSCOCO(個人子集)、MPII 和AI 挑戰者中收集的。定義人群指數來評價圖像的擁擠程度。通過 Crowd Index 對30K幅圖像進行分析,最終選出 20K幅高質量圖像。接下來,為大約 80K人注釋 14個關鍵點和全身邊界框。
J-HMDB Dataset,簡稱聯合標注的HMDB,是HMDB51 數據庫的一個子集,包含 51 個人類動作的超過 5100 個片段。J-HMDB數據集包含 928個剪輯,21個動作類別。每個動作類包含 36-55 個片段。每個剪輯包含 15-40 幀。亞馬遜土耳其機器人上標注了 31838 張圖片。多達 15個可見的身體關鍵點被標記,連同規模,視點,分割,木偶蒙版和木偶流。訓練圖像與測試圖像的數量之比約為 7:3。J-HMDB數據集在視頻姿態估計和動作識別中得到了廣泛的應用。
Penn Action Dataset是另一個不受約束的視頻數據集,包含包含 15 個動作的 2326 個視頻剪輯。訓練集和測試集都有 1163 個視頻剪輯。該數據集包含各種類內角色外觀、動作執行率、視點、時空分辨率和復雜的自然背景。注釋通過部署在亞馬遜土耳其機器人上的半自動化視頻注釋工具進行。每個人都帶有帶有 2D坐標、可見性和攝
像機視點的13個關鍵點。
3D姿態數據集:
SURREAL是一個通過在背景圖像上渲染紋理SMPL模型的單人合成視頻數據集。SMPL模型是由大量的3D運動捕捉數據驅動的。這樣,SURREAL包含 6M RGB幀,包含深度、身體部位、光流、2D/3D
姿勢和表面法線標注。由于身體紋理的低分辨率限制,渲染的 2D圖像的真實感還有待提高。然而,通過綜合生成數據,我們可以獲得大量現實中難以獲得的注釋。如何合成更逼真的圖像是一個很有價值的研究方向。
AMASS是一個大規模的動作捕捉(MoCap)數據集。它通過MoSh++將 15 個MoCap數據集轉換為 SMPL/DMPL
參數,從而統一了 15 個MoCap 數據集[125]。它包含超過 40 小時的運動數據,涵蓋超過 300 個對象,超過 110K
個運動。除了 3D身體姿勢,它還包含真實的軟組織運動。AMASS被廣泛用于通過監督估計的姿態或運動的合理
性來建立一個先驗的人體運動空間。
CMU Panoptic是一個大規模的多視圖、多人三維姿態數據集。目前,它包含 65 個序列和 150 萬個3D骨骼。他們建造了一個令人印象深刻的 360 度運動捕捉穹頂,其中包含 480個VGA攝像頭(25 FPS), 31 個高清攝像頭(30FPS), 10個Kinect2傳感器(30 FPS)和 5個DLP投影機。特別是,它包含多人社交場景。多人三維姿態估計方法
通常提取部分數據進行評估。
Zanfir 等和 Jiang 等選擇四種社交活動(Haggling, Mafia, Ultimatum,Pizza)的兩個子序列(9600幀,分別來自HD camera 16和30)進行評價。它包含豐富的注釋,如 2D/3D身體/手姿勢。
然而并不是每個視頻序列都被完全注釋。
JTA (Joint Track Auto)是一個用于多人三維姿態評估的綜合數據集。JTA是使用視頻游戲俠盜獵車手 v生成的。它包含了 512個高清視頻,行人在城市場景中行走。每個視頻長度為 30秒,拍攝速度為 30 FPS,分辨率為 1920× 1080。它包含了視頻中所有人的2D/3D身體姿勢和身份標注。
本周總結
下周打算找個一篇具有代表性且相對簡單、開源的文獻作為baseline進行跑一跑。在知乎上看別個講到的,深度學習代碼學習,先從模塊化的角度來看待,它作用是什么?有哪些重要的類和函數,這些類和函數在哪里調用,作用是什么;數據的輸入輸出的格式,看看別人是怎么處理的。然后就逐行進行看、分析,做筆記,就記不住就抄下來。要記到腦子里,避免因為信息檢索技術、大模型技術帶來的便利導致腦袋空心化。
這篇綜述,講了2d、3d姿態估計的技術、主要是從單目的角度講,還有數據集的介紹,后續的工作就是去看2d、3d主流的一些方法的文獻,搞明白別人的網絡模型,創新點,貢獻。現階段看很多方法都是很蒙蔽的狀態。我覺得需要多和師兄師姐們交流,幫他們打下手,快速了解到一次完整的科研是什么經歷。對于自己的方向,我覺得是從輕量化、單方向的3維人體姿態估計入手。**3維的數據集就是個問題,缺少室外的數據集,很多方法都是采用弱監督、無監督來進行處理的,因為標注數據集就很貴也很麻煩,深度模糊也是三維面臨的困境。**其余的我還沒有太多思路,因為到現在,我都沒有完整地復現過一篇這個領域的文章。





)


)





)
)
![LeetCode 刷題 [C++] 第73題.矩陣置零](http://pic.xiahunao.cn/LeetCode 刷題 [C++] 第73題.矩陣置零)
)
和機器視覺(Machine Vision))

)