分布式ID生成策略-雪花算法Snowflake
- 一、其他分布式ID策略
- 1.UUID
- 2.數據庫自增與優化
- 2.1 優化1 - 共用id自增表
- 2.2 優化2 - 分段獲取id
- 3.Reids的incr和incrby
- 二、雪花算法Snowflake
- 1.雪花算法的定義
- 2.基礎雪花算法源碼解讀
- 3.并發1000測試
- 4.如何設置機房和機器id
- 4.雪花算法時鐘回撥問題
這里主要總結雪花算法,其他的分布式ID策略不常用,這里簡要描述,而且各大公司生產基本都是選擇雪花算法,所以這里針對雪花算法進行詳細解讀,其他常見的分布式id策略則只做簡略描述。
一、其他分布式ID策略
分布式ID是分布式架構中比較基礎和重要的場景,好的分布式ID策略可以提供更強大的并發,保障業務的正常展開。各大公司最為常用的是雪花算法,和在雪花算法基礎上進行改進的算法,當然也有其他的比如數據庫自增等,這里先對其他分布式ID策略的簡述,這樣才能更清晰比對和雪花算法的差異。
1.UUID
UUID是一串32個字符,128位的隨機字符串。UUID在數據庫比較小并發量不高的服務中使用是完全可以的,他的最大的特點就是簡單易用,使用簡潔,對于數據量不大的系統推薦使用,比如OA等公司內部系統。JDK自帶UUID的api,可以直接使用:
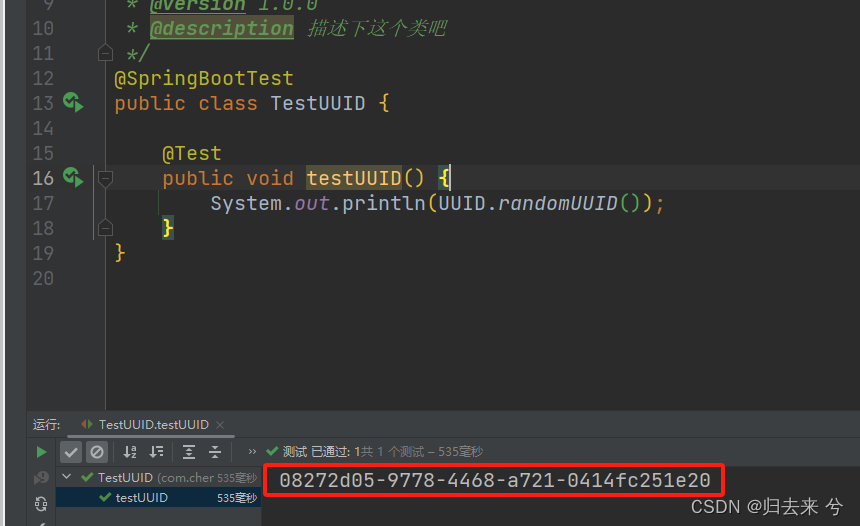
package com.cheng.common.snowflake.api.test;import org.junit.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.UUID;/*** @author pcc* @version 1.0.0* @description 描述下這個類吧*/
@SpringBootTest
public class TestUUID {@Testpublic void testUUID() {System.out.println(UUID.randomUUID());}
}只需要上面一行簡單的代碼就可以獲取到UUID了,使用起來可以說是非常簡單了。
優點:簡單易用、生成效率高
缺點:字符串隨機生成,當數據量特別大時使用mysql數據庫,插入效率會比較低下,原因是因為Mysql的索引是B+Tree,B+Tree所有數據都存儲在葉子節點上,且按順序排列,若是隨機字符串會增加尋址成本,造成插入效率低下,因為是隨機字符串在進行范圍查詢時索引效率也很低下。
使用總結:不推薦使用,如果用只能用在數據量比較小的服務,這是一個悖論,數據量小也沒有必要使用分布式服務分布式id了,直接使用數據庫自增就行,所以這里不推薦使用。
2.數據庫自增與優化
這里的數據庫自增就是指數據庫的auto_increment,當我們為主鍵設置auto_increment時,那么這個主鍵就會隨著表記錄創建而填充且id是逐個遞增的,數據量不大的情況是是完全可以使用這種方式的,但當有分庫分表時,數據量和并發量大時數據寫入就會變慢,因為首先單庫的并發量是有限的,其次單表數據量增大后單表操作就會越來越慢,也會影響性能,所以需要對數據庫進行垂直和水平拆分(分庫分表)。
2.1 優化1 - 共用id自增表
上面的數據庫自增很顯然在分庫分表時是無法滿足數據庫id唯一且自增的,因為是多個庫多個表,所以這里需要進行優化,優化的方式也比較簡單,就是單獨使用一個表來維護id,數據插入之前通過這個表來分配數據庫的id。這樣就可以保證多個庫多個表的主鍵的不沖突了,但當并發量繼續增高時,即使這個表單獨只做id分配也會吃力,此時還需要為這個表提供優化,此時還可以考慮將這個表所在的庫做主-主的設置,來提升并發能力。
那這個優化的核心其實就是獲取id的這個表了。這種方式會將表結構設置為如下:
CREATE TABLE `gene_id` (`id` int(11) NOT NULL AUTO_INCREMENT,`stub` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `stub` (`stub`)
);
這里需要注意兩點:
- 主鍵需要自增AUTO_INCREMENT,因為id需要靠這個表來維持,所以需要設置id自增
- stub需要唯一約束,這個字段是需要根據值進行替換達到id自增的目的的輔助列,所以需要唯一約束(根據唯一值進行替換)。
表結構出來以后,需要處理的是如何正確的自增id,網上的說法都是使用這個:
BEGIN;
REPLACE INTO gene_id (stub) values ('stub');
SELECT LAST_INSERT_ID();
COMMIT;
這里簡單說下這個sql,REPLACE INTO的作用是如果存在則刪除重新插入,如果不存在則直接插入。所以可以實現id主鍵的自增。LAST_INSERT_ID則是msyql內置的方法可以獲取到上一次增加的id,使用這種方式可以一次獲取到我們想要的id
思考:這個獲取id的方式會不會存在幻讀問題
假如我們不使用上面這個方式獲取id,我們使用的是select 通過id倒排獲取最大id是很可能會出現幻讀的問題的,幻讀就會導致大家可能獲取的id是同一個,從而出現了數據id的重復。那這里會不會呢,這里其實是不會的,因為使用的是LAST_INSERT_ID,這個方法只會返回當前事物中新增的id,對于其他事務的新增id并不會返回,所以不會有幻讀的問題,所以使用這種方式獲取自增的id才是正確的姿勢。
2.2 優化2 - 分段獲取id
上面的2.1 其實還可以繼續優化,而且這里的優化也是美團實際在用的,廢話不多說,如何優化呢?核心思想就是減少和數據庫的交互,從而提升性能,現在是獲取一次id就需要和id管理表交互一次,優化的思想是分段獲取id,比如一次獲取1000個id,那么就可以減少獲取id數量的999次交互,而獲取到的1000個id可以放入到內存中,當需要時從內存中獲取id,這樣無疑會提升很多性能。
這種方式也可能會面臨臨界點時id獲取多線程阻塞問題,可以通過提前加載的方式來解決這種問題。
3.Reids的incr和incrby
Redis因為真正執行CRUD的操作是單線程,所以他的操作是原子性的,此時我們可以利用他的命令incr(redis的++操作),incrby(incrby key 10意思是將key的值增加10),這種命令來實現和數據庫類似的id的自增,而且redis也是支持持久化的,我們可以同時開啟redis的rdb和aof來保證數據的不丟失。而且redis本身也是支持高并發的,對redis進行集群擴展也比較方便,所以使用redis也是可以的。
二、雪花算法Snowflake
1.雪花算法的定義
雪花算法最早由Twitter開源,用于產生一個64bit的整數(換算成10進制則是19位)。同時64bit在java中正好是long的長度(long是8字節,一字節是8bit),在數據庫mysql中正好是BIGINT的長度。在雪花算法中64bit的整數被劃分了4部分:1位符號位+41位時間戳位+10位機器位+12位隨機數位,如下:

-
1位符號位:
二進制數據中首位表示正負,這里是0不可變 -
41位的時間戳:
41位用來標識時間戳,最大值是2的41次方-1為:2199023255552,轉換成時間戳的話是2039-09-07 23:47:35,所以這個41為的時間戳如果不特殊處理可以表示最大的范圍就是到2039年(從1970年算是69年),

2039年對于大部分公司來說肯定是不行的(不能說用到2039年就不用了吧)所以一般這個41位的時間戳不會直接用當前的時間戳來直接填充,而是使用當前時間戳減去一個默認的時間戳這樣就可以獲得更大的表示范圍了,這個默認的時間戳通常是系統的上線時間,假如系統上線時間是2024年3月1號,根據上面的69年的表示范圍那么這個分布式id的時間范圍就可以表示到2093年。2093年對于任何公司來說都是可用的了,尚不說公司能不能存在到那時候,即使存在了系統肯定也早需要重構了,不會有任何系統給你用這么久的。
-
10位的機器位:
機器位最大為10位,一般做法是5位用于機房id的標識,5位用于機器id的標識。這樣無論是機房和機器都可以最大容納2的五次方減1(31)的數量。不過實際使用時可以根據實際情況進行調整,因為機房數量一般也到不了31,就是機器數量到達31的也不多。所以可以根據實際情況來進行調整機器位10個bit的分配。 -
12位的隨機數:
12位的隨機數最大可以表示2的12次方減1的數據(4095)所以也就是說最大我們可以在1ms內產生4095個id(時間戳位是ms),那么1s內就是4095000≈400W。而且這是單臺機器上的每秒可產生的不重復id,如果橫向擴展機器的話,這個值還會更大。所以12位的隨機數位是肯定夠用的了,當然真正使用時是不能使用隨機數的,而是應該進行整數的自增,這樣才能保證不重復。
總結一句話就是雪花算法是一個可以在單機每秒鐘最高產生400w不重復id的id生成算法(假如機器性能扛得住)。在橫向擴展后這個值會更大,如果是3臺機器則是1200w,所以分布式id基本上可以適用任何并發場景。
2.基礎雪花算法源碼解讀
雪花算法并不難,只需要知道生成策略其實大部分人應該都是可以寫出來的,所以說最重要的一直不是動手的能力而是你思維的能力,可以做到的遠比可以想到的要多得多。
package com.cheng.ebbing.message.snowflake;import java.util.concurrent.ConcurrentHashMap;/*** @author pcc* @version 1.0.0* @description 雪花算法生成id*/
public class SnowflakeIdGenerator {// 起始的時間戳private final long twepoch = 1288834974657L;// 每一部分占用的位數private final long workerIdBits = 5L;private final long datacenterIdBits = 5L;private final long sequenceBits = 12L;// 每一部分的最大值private final long maxWorkerId = -1L ^ (-1L << workerIdBits);private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);private final long maxSequence = -1L ^ (-1L << sequenceBits);// 每一部分向左的位移private final long workerIdShift = sequenceBits;private final long datacenterIdShift = sequenceBits + workerIdBits;private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;// 記錄上一次生成ID的時間戳private long lastTimestamp = -1L;// 0,并發控制private long sequence = 0L;private final long workerId;private final long datacenterId;public SnowflakeIdGenerator(long workerId, long datacenterId) {if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException("Worker ID can't be greater than " + maxWorkerId + " or less than 0");}if (datacenterId > maxDatacenterId || datacenterId < 0) {throw new IllegalArgumentException("Datacenter ID can't be greater than " + maxDatacenterId + " or less than 0");}this.workerId = workerId;this.datacenterId = datacenterId;}public synchronized long generateId() {long timestamp = timeGen();// 時鐘回撥直接異常if (timestamp < lastTimestamp) {throw new RuntimeException("Clock moved backwards. Refusing to generate id for " + (lastTimestamp - timestamp) + " milliseconds.");}if (timestamp == lastTimestamp) {// 按位與只要都為1才為1否則為0// 4095的十進制數在二進制中表示為111111111111,而4096的十進制數在二進制中表示為1000000000000。sequence = (sequence + 1) & maxSequence;if (sequence == 0L) {// 當前毫秒的序列號已經用完,等待下一毫秒timestamp = tilNextMillis(lastTimestamp);}} else {// 不同毫秒內,序列號重置為0sequence = 0L;}// 記錄上一次生成ID的時間戳lastTimestamp = timestamp;// 計算時間戳左移22位,加上數據中心ID左移17位,加上機器ID左移12位,加上序列號return ((timestamp - twepoch) << timestampLeftShift) |(datacenterId << datacenterIdShift) |(workerId << workerIdShift) |sequence;}private long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}private long timeGen() {return System.currentTimeMillis();}
}上面是一個雪花算法的生成源碼很簡單,應該是一看就懂了,唯一可能需要說的是生成id的時候這個對于位運算和按位或操作不熟悉的可能有些懵,之類簡單說下。二進制的位運算可以類比十進制的乘以10的操作,假如11(十進制的3)這個二進制數左移兩位則表示在末尾添加兩個00,也就是1100(十進制12),不清楚的這么記就行。而按位或則是對比操作的兩個數的相同位,有一個為1則記為1,否則為0,這里左移以后末尾補零,左移按位或就可以理解為10進制的加法了,相同與有一個10禁止的1乘以100以后,在他的個位和10位上進行加數。
3.并發1000測試
這里使用1000個線程并發來壓測,其實肯定不會有重復的,這里將產生的id放入到ConcurrentHashMap的key中,如果最后key的數量和線程數保持一致,則說明這個源碼沒有問題:
// 示例用法public static void main(String[] args) {// 數據中心ID和機器ID分別為1和1SnowflakeIdGenerator idGenerator = new SnowflakeIdGenerator(1, 1); // 用于存放產生的idConcurrentHashMap<Long, Long> ids = new ConcurrentHashMap<>();// 假設有1000個線程同時生成id,那么這時候測試下是否有重復的idfor (int i = 0; i < 1000; i++) {new Thread(()->{ids.put(idGenerator.generateId(),1L);}).start();}// 等待所有線程執行完畢try {Thread.sleep(2000);} catch (InterruptedException e) {throw new RuntimeException(e);}// 如果重復,那么肯定是小于線程數的System.out.println("生成的id數量:" + ids.size());}
測試結果自然是和我們聲明的線程量是一致的。
生成的id數量:1000進程已結束,退出代碼0
上面的id生成例子用起來其實沒啥大問題,但一般也不會直接用,還需要考慮如下一些場景的適配。
4.如何設置機房和機器id
這里得機器id和機房id都是通過傳入的,那生產環境該如何定義這個值呢,主要是兩種方案:
- 1.通過注冊中心定義
分布式id的服務如果有多個,可以都注冊到注冊中心里,在服務啟動后獲取所有實例,根據實例ip進行排序然后分配機器id和機房id。 - 2.服務器直接定義
也可以直接在機器上定義一個變量,項目中根據服務器上定義的變量定義機器id和服務器id,springboot配置文件中使用${workid}這種方式來獲取機器上定義的環境變量。
4.雪花算法時鐘回撥問題
時鐘回撥問題是指,單臺機子上時間出現回退導致id出現重復的問題,可以說只要時間回退了id重復的概率基本是99%了,此外不要想著時間回退不容易碰到,這個基本都會碰到。有以下幾種可能會出現時間回退:
- 1.潤秒:
世界時間(國際原子時)與地球自轉時間(世界時)之間存在微小差異。為了使時間保持同步,國際原子時不時地進行調整,即通過插入或刪除“潤秒”(leap second)來實現,這種如果是刪除就會導致時間回退。 - 2.時間漂移
服務器因硬件、溫度問題導致的時間不一致 - 3.時間同步問題
每個電腦都不是和標準時間實時同步的,都是間隔一段時間去同步一次,這個時間也是可能出現回退的。 - 4.手動調整
這種也有可能發生,服務器管理員進行了手動調整,且時間向后調整了
所以說時間回退是很可能會碰到的,這個問題也是必須要解決的,而上面的代碼是沒有解決這個問題的。時間回退造成的問題是出現了相同的時間戳,而因為是同一臺機器同一個機房所以id重復概率很高。下面來說下通常解決時間回退問題的解決方案。
- 方案一:阻塞等待
這個適合時間回退沒有太久時,可以在上面代碼中進行判斷下,根據自己的業務并發量進行計算下看看可以接受多大時間的阻塞而不會影響線上的運行。 - 方案二:id接續生成
這個需要記錄下每個ms內id生成的最大數,當然這個數量也不能存儲過多,頂多存儲個幾十秒的每毫秒的最大id。當出現時間回退時,我們可以接著出現回退的ms內的最大id繼續生成,這樣也不會有id重復的問題,但是如果時間回退的較多使用這種方式也是不合適的。 - 方案三:預留時間回退位
當時間回退較多時,無論是阻塞還是id接續生成都是不合適的,此時還可以考慮針對64位的數據進行預留時間回退位置,比如我們可以在10位的機器和機房id中預留2位用以標識時間回退,讓機房id和機器id只占8位具體如何分配可以根據自己實際情況來說,當出現時間回退時可以打開該標識。 - 方案四:下線時間回退機器
這個是有風險的,雖然下線了服務器,但是如果是因為潤秒原因導致的時間回退,很可能會導致大片機器同時下線,所以這種方式是很有安全隱患的。














![[數據結構]棧](http://pic.xiahunao.cn/[數據結構]棧)
![[ai筆記14] 周鴻祎的ai公開課筆記1](http://pic.xiahunao.cn/[ai筆記14] 周鴻祎的ai公開課筆記1)



