OpenChat:性能高達105.7%,第一個超越ChatGPT的開源模型?
前幾天開源模型第一還是是Vicuna-33B、WizardLM,這不又換人了。對于開源模型的風起云涌,大家見怪不怪,不斷更新的LLM榜單似乎也沒那么吸引人了。
最近,開源模型 OpenChat 發布了新的版本,據說在 AlpacaEval 和 VicunaGPT-4 評估上的性能超過了ChatGPT。

這次#擊敗ChatGPT的開源模型#有些唬人,到底如何呢?
根據官方介紹,OpenChat 的性能表現:
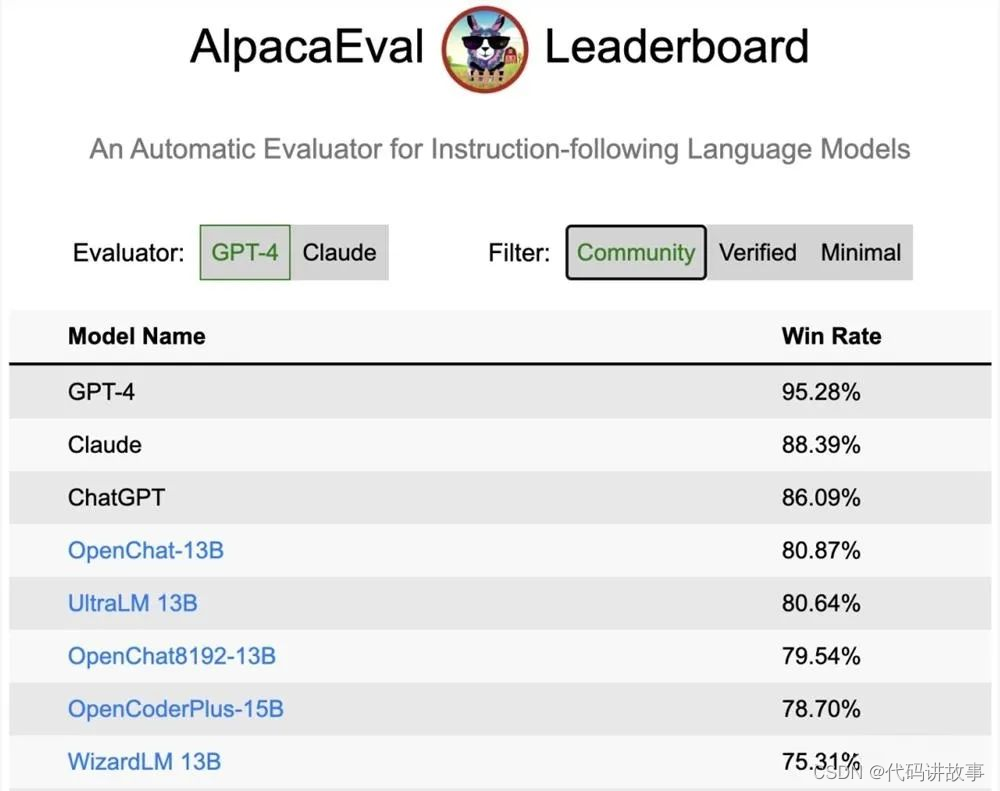
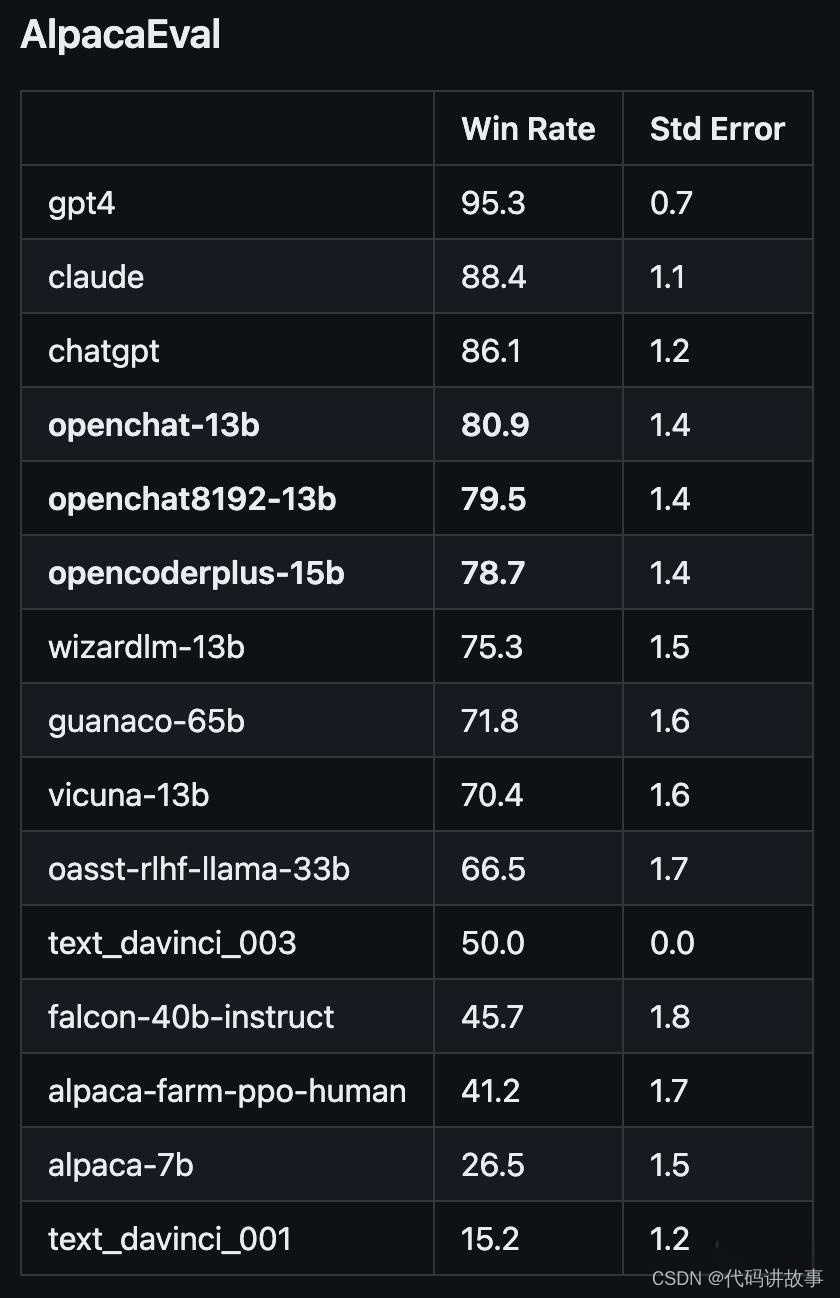
在斯坦福AlpacaEval上,以80.9%的勝率位列開源模型第一;
在Vicuna GPT-4評測中,性能則達到了ChatGPT的105.7%。
PART 01
開源模型 OpenChat 超越 ChatGPT
OpenLLM 是一個在多樣化且高質量的多輪對話數據集上進行微調的開源語言模型系列。
具體地,研究人員從約 90K 的ShareGPT對話中,過濾出約 6K 的GPT-4對話用于微調。清洗后的GPT-4對話與對話模板和回合結束時的token相結合,然后根據模型的上下文限制進行截斷(超出限制的內容將被丟棄)。
數據處理流程包括三個步驟:
清洗:對HTML進行清理并轉換為Markdown格式,刪除格式錯誤的對話,刪除包含被屏蔽詞匯的對話,并進行基于哈希的精確去重處理
篩選:僅保留token為Model: GPT-4的對話
轉換:為了模型的微調,針對所有的對話進行轉換和分詞處理
要運行數據處理流程,可執行以下命令:
./ochat/data/run_data_pipeline.sh INPUT_FOLDER OUTPUT_FOLDER
OpenLLM 被證明可以在有限的數據下實現高性能。

OpenLLM 有兩個通用模型,即 OpenChat 和 OpenChat-8192。
OpenChat 模型是基于 LLaMA 模型進行微調的,它充分利用了極小、多樣且高質量的多輪對話數據集。這樣的數據集有助于 OpenChat 模型在對話場景中產生更準確、更自然的回復。

具體地,OpenChat:基于LLaMA-13B微調,上下文長度為2048
在 Vicuna GPT-4 評估中達到ChatGPT分數的105.7%
在 AlpacaEval 上取得了驚人的80.9%的勝率
具體地,OpenChat-8192:基于LLaMA-13B微調,上下文長度為8192
在 Vicuna GPT-4 評估中達到ChatGPT分數的106.6%
在 AlpacaEval 上取得的79.5%勝率
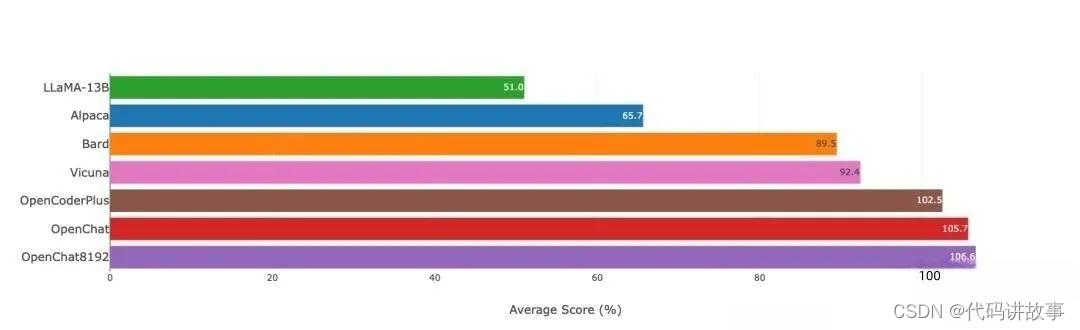
圖注:Vicuna GPT-4評估(v.s. gpt-3.5-turbo)
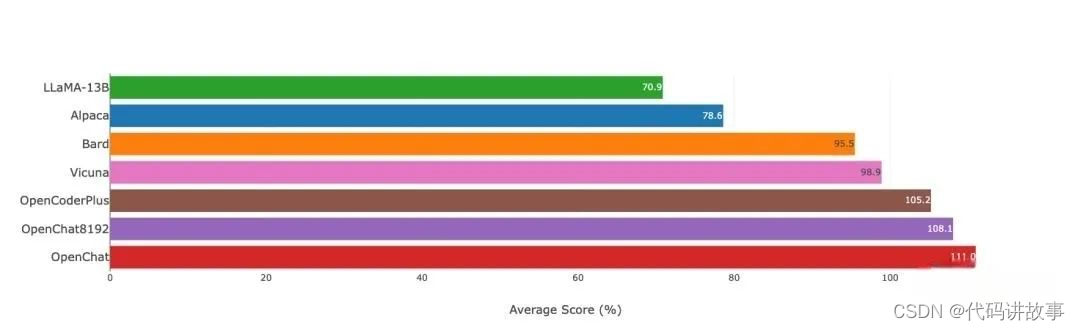
圖注:Vicuna GPT-3.5-Turbo評估(v.s. gpt-3.5-turbo)
除此之外,OpenLLM還有代碼模型:
在 Vicuna GPT-4 評估中達到ChatGPT分數的102.5%
在 AlpacaEval 上獲得78.7%的勝率

PART 02
OpenChat 安裝和權重
要使用OpenLLM,需要安裝CUDA和PyTorch。用戶可以克隆這個資源庫,并通過pip安裝這些依賴:
git clone git@github.com:imoneoi/OChat.git
pip install -r requirements.txt
目前,官方提供所有模型的完整權重作為Hugging Face repos。用戶可以使用以下命令來啟動本地 API 服務器,網址是 http://localhost:18888。
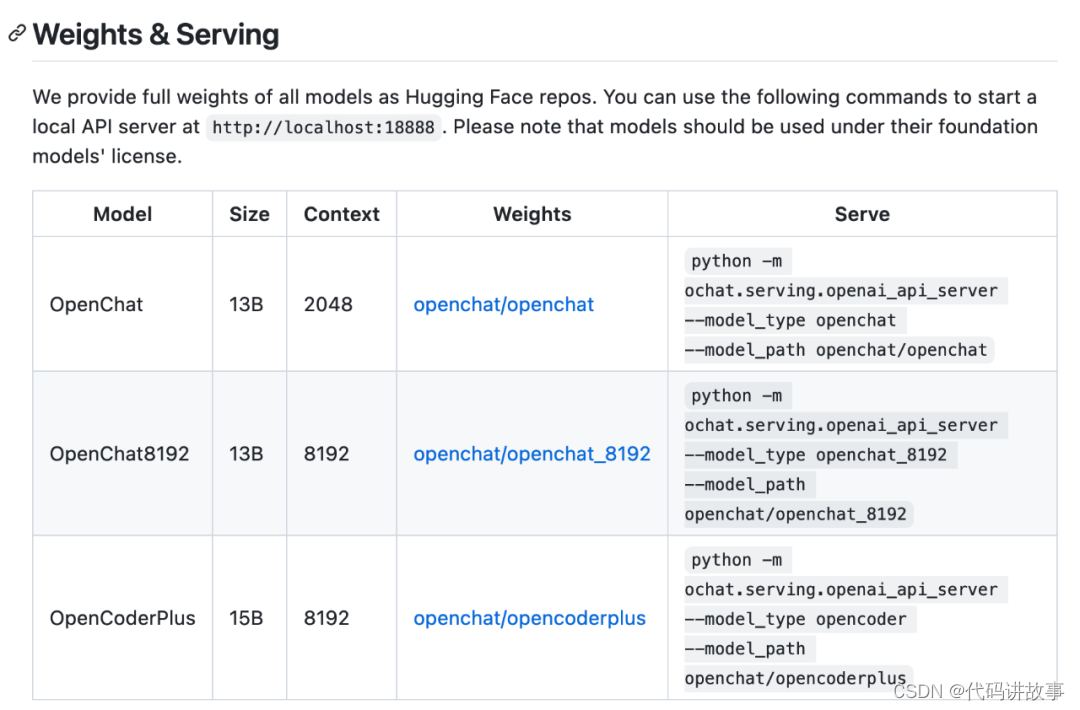
該服務器與 ChatCompletions協議(請注意,有些功能不完全支持)和openai軟件包兼容。用戶可以通過設置來指定openai包的服務器:
openai.api_base = "http://localhost:18888/v1"
當前支持的ChatCompletions參數有:

PART 03
對 OpenChat 的爭議
研究者采用的評估模式與 Vicuna 的略有不同,還使用了證據校準(EC)+平衡位置校準(BPC)來減少潛在的偏差。
雖然 OpenChat 模型在 AlpacaEval 和 VicunaGPT-4 評估中超越了ChatGPT,但這一消息并未引起網友的熱烈討論。爭議聲音認為 OpenChat 的評價方式夸張,并呼吁使用更高級的MT-bench基準進行評估。
為了回應這些爭議,Vicuna官方回應稱他們正在使用更高級的MT-bench基準進行評估。這一基準可以更全面地評估模型的性能,使評估結果更具有說服力。

OpenLLM 雖然夠實現優秀的性能,但仍然受到其基礎模型固有限制的限制,如:
復雜推理
數學和算術任務
編程和編碼挑戰
另外,OpenLLM 有時可能會產生不存在或不準確的信息,也稱為「幻覺」。
這表明開源模型仍需要進一步改進,包括構建更好的基礎模型和增加指令調優數據。無論如何,開源模型的發展仍然充滿希望,我們期待未來能夠看到更多的突破和進步。
參考:
https://github.com/imoneoi/openchat
https://tatsu-lab.github.io/alpaca_eval/



—— 循環語句)

![[藍橋杯 2020 省 B1] 整數拼接](http://pic.xiahunao.cn/[藍橋杯 2020 省 B1] 整數拼接)


)





)




)