之前只看了ViT的大概結構,具體的模型細節和代碼實現知之甚少。隨著ViT逐漸成為CV領域的backbone,有必要重新審視下。

patch -> token
為了將圖片處理成序列格式,很自然地想到將圖片分割成一個個patch,再把patch處理成token。

假設圖片大小為 224 × 224 × 3 224 \times 224 \times 3 224×224×3 (即 H × W × C H \times W \times C H×W×C ),每個patch大小為 16 × 16 × 3 16 \times 16 \times 3 16×16×3,那么序列長度就是 196 196 196,序列的形狀是 196 × 768 196 \times 768 196×768。
如何將大小為 16 × 16 × 3 16 \times 16 \times 3 16×16×3 的patch,映射為 768 768 768 維的token?源碼是直接將其reshape
在reshape之后,還需要過一層 768 × 768 768 \times 768 768×768的embedding層。因為reshape后的 768 768 768維向量是參數無關的,不參與梯度更新,過完embedding層,即擁有了token embedding的語義信息。
處理成patch的好處
- 減少計算量:如果按照pixel維度計算self-attention,那復雜度大大增加。patch size越大,復雜度越低。stable diffusion也是這個思路,在latent space進行擴散,而不是pixel
- 減少圖像冗余信息:圖像是有大量冗余信息的,處理成patch不影響圖片語義信息
position embedding
論文采用的是可學習式位置編碼,跟bert類似,初始化一個可學習的1-d參數向量
其它的位置編碼方案結果對比:

個人感覺2-d位置編碼更make sense,它保留了patch之間的空間位置關系,跟CNN類似。直接粗暴地拉平成一維序列,則丟棄了這種空間信息。
實驗結果

在相同的數據集JFT-300M上預訓練后,ViT在所有的下游任務上,都超過了BiT。值得注意的是,準確率上提升不大,但訓練時間大為縮短。
可能是基于Transformer架構的VIT,和卷積神經網絡相比,更適合做切分均勻的矩陣計算,這樣我們就能把參數均勻切到不同卡上做分布式訓練,更好利用GPU算力,提升訓練效率。
但transformer架構有個獨門絕技,那就是大力出奇跡。數據量越大,模型參數越多,任務效果就越好。下圖就是證明:

ViT學習到空間局部性了嗎?
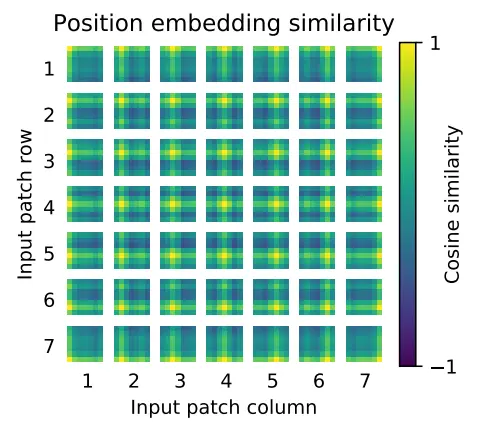
可以看到,每個patch除了跟自己最相似外,其與周圍的patch相關性高于距離較遠的patch。這就說明ViT通過位置編碼,已經學到了一定的空間局部性。
總結
- ViT證明了Transformer架構在CV領域的可行性,以后Transformer將大一統各領域。NLP的成功經驗非常有潛力遷移到CV領域,比如scaling law,大數據+大模型的范式將開拓出CV的新一片天地。
- 大數據+大模型真的是既無腦又有效,通過這種方式讓Transformer自己去學習到特定領域的歸納偏置。可以說Transformer下限比CNN低,但上限又是CNN無法企及的。
參考
- 再讀VIT,還有多少細節是你不知道的

—— 循環語句)

![[藍橋杯 2020 省 B1] 整數拼接](http://pic.xiahunao.cn/[藍橋杯 2020 省 B1] 整數拼接)


)





)




)

