Flink學習筆記
前言:今天是學習 flink 的第 9 天啦!學習了 flink 四大基石之 Time的應用—> Watermark(水印,也稱水位線),主要是解決數據由于網絡延遲問題,出現數據亂序或者遲到數據現象,重點學習了水位線策略機制原理和應用,以及企業級的應用場景,結合自己實驗猜想和代碼實踐,總結了很多自己的理解和想法,希望和大家多多交流!
Tips:轉碼之路,溯洄從之,道阻且長!希望自己繼續努力,學有所成,讓華麗的分割線,成為閃耀明天的起跑線!
文章目錄
- Flink學習筆記
- 三、Flink 高級 API 開發
- 2. WaterMark
- 2.1 為什么需要 WaterMark
- 2.2 多并行度與 WaterMark
- 2.3 KeyBy 分流與 WaterMark
- 2.4 水印的生成策略
- 2.4.1 內置水印生成策略
- (1) 固定延遲生成水印
- (2) 單調遞增生成水印
- 2.4.2 自定義水印生成策略
- (1) ==周期性 watermark 策略==
- (2) ==間歇性 watermark 策略==
- 2.5 在非數據源之后使用水印 [重點]
- 2.5.1 WaterMark 的四種使用情況
- (1) 本來有序的 Stream中的 Watermark
- (2) 亂序事件中的Watermark
- (3) 并行數據流中的Watermark
- (4) 自定義 Watermark
- 2.6 在數據源之后使用水印 (Kafka) [重點]
- 2.6.1 kafka 向指定分區寫入數據
- 2.6.2 水印機制消費 kafak 數據
- 2.7 Flink 對嚴重遲到數據的處理
三、Flink 高級 API 開發
2. WaterMark
2.1 為什么需要 WaterMark
當 flink 以 EventTime 模式處理流數據時,它會根據數據里的時間戳來處理基于時間的算子。但是由于網絡、分布式等原因,會導致數據亂序的情況。

結論:
-
只要使用 event time,就必須使用 watermark,在上游指定,比如:source、map算子后。
-
Watermark 的核心本質可以理解成一個延遲觸發機制。
-
因為前面提到,數據時間 >= 窗口結束時間,觸發計算,這里想要延遲觸發計算,所以水印時間一般比數據事件時間少幾秒
-
水印時間 = 事件時間 - 設置的水印長度
-
水印的功能:在不影響按照事件時間判斷數據屬于哪個窗口的前提下,延遲某個窗口的關閉時間,讓其等待一會兒延遲數據。
舉例:
窗口5秒,延遲(水印)3秒,按照事件時間計算來一條數據事件時間3, 落入窗口0-5.水印時間0
來一條數據事件時間7, 落入窗口5-10,水印時間4
來一條數據事件時間4,落入窗口0-5,水印時間1
來一條數據事件時間8,落入窗口5-10,水印時間5
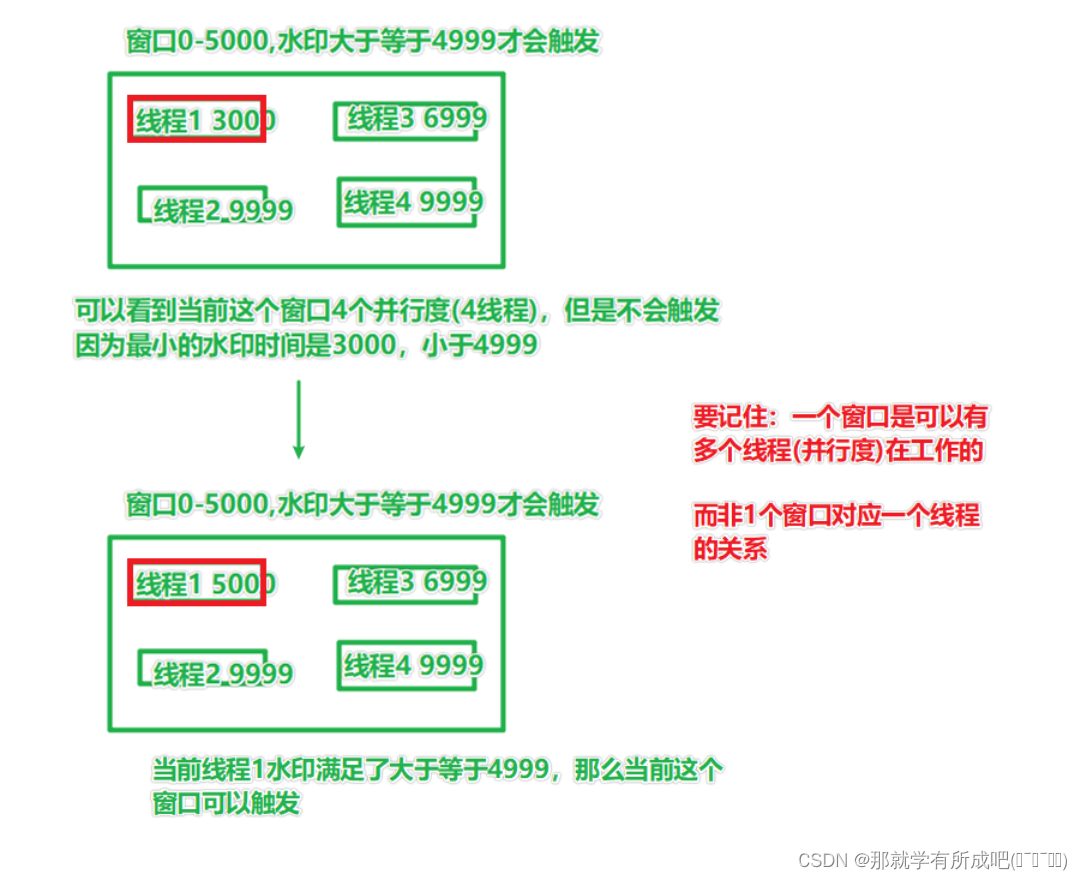
2.2 多并行度與 WaterMark
- 如果并行度是 n,那么watermark 就有 n 個
- 觸發條件以線程中最小的 watermark 為準
2.3 KeyBy 分流與 WaterMark
- 一個程序中有多少個水印和并行度有關,和 keyby 無關
舉例:
比如有單詞hadoop spark
按照keyby,會分成hadoop組 和spark組
但是這兩個組是共用1個水印的
hadoop來的數據滿足了觸發條件,會將spark組的數據也觸發
2.4 水印的生成策略
2.4.1 內置水印生成策略
(1) 固定延遲生成水印
簡介:設置最大延遲時間
例子:
DataStream dataStream = ...... ;
dataStream.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)));
(2) 單調遞增生成水印
簡介:當前時間戳就可以充當 watermark,因為后續到達數據的時間戳不會比當前的小(網絡延遲)。
例子:
DataStream dataStream = ...... ;
dataStream.assignTimestampsAndWatermarks(WatermarkStrategy.forMonotonousTimestamps());
2.4.2 自定義水印生成策略
(1) 周期性 watermark 策略
- 升序watermark:單調遞增生成水印
- 亂序watermark:固定延遲生成水印
都是基于周期性生成,默認的周期是 200ms,一般不去改,保持在 ms 級別 onPeriodicEmit()
(2) 間歇性 watermark 策略
- 每一個事件時間都會產生一個watermark
2.5 在非數據源之后使用水印 [重點]
2.5.1 WaterMark 的四種使用情況
(1) 本來有序的 Stream中的 Watermark
例子:以 java bean 的數據輸入作為有序事件時間
package cn.itcast.day09.WaterMark;/*** @author lql* @time 2024-03-01 21:11:00* @description TODO*/import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;/*** 使用單調遞增水印,解決數據有序的場景(大多數情況都是亂序的數據,因此該場景比較少見)* 需求:從socket接受數據,進行轉換操作,然后應用窗口每隔5秒生成一個窗口,使用水印時間觸發窗口計算** 使用水印的前提:* 1:數據必須要攜帶事件時間* 2:指定事件時間作為數據處理的時間* 3:指定并行度為1* 4:使用之前版本的api的時候,需要增加時間類型的代碼** 測試數據:* sensor_1,1547718199,35 -》2019-01-17 17:43:19* sensor_6,1547718201,15 -》2019-01-17 17:43:21* sensor_6,1547718205,15 -》2019-01-17 17:43:25* sensor_6,1547718210,15 -》2019-01-17 17:43:30** todo 如果窗口銷毀以后,有延遲數據的到達會被丟棄,無法再次觸發窗口的計算了*/
public class MonotonousWaterMark {public static void main(String[] args) throws Exception {//todo 1)創建flink流處理的運行環境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//設置 Flink 程序中流數據時間語義為 EventTime。// 在處理數據時 Flink 程序會按照數據事件發生的時間進行處理,而不是按照數據到達 Flink 程序的時間進行處理。env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);//todo 2) 接入數據源SingleOutputStreamOperator<WaterSensor> lines = env.socketTextStream("node1", 9999).map(new MapFunction<String, WaterSensor>() {@Overridepublic WaterSensor map(String value) throws Exception {String[] data = value.split(",");return new WaterSensor(data[0], Long.valueOf(data[1]), Integer.parseInt(data[2]));}});//todo 3)添加水印處理//flink1.12之前版本的api編寫(單調遞增水印本質上還是周期性水印)SingleOutputStreamOperator<WaterSensor> waterMarkStream = lines.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<WaterSensor>() {@Overridepublic long extractAscendingTimestamp(WaterSensor element) {// 因為我們在轉換時間戳,需要毫秒級別!return element.getTs()*1000L;}});waterMarkStream.print("數據>>>");//todo 4)應用窗口操作,設置窗口長度為5秒WindowedStream<WaterSensor, String, TimeWindow> sensorWS = waterMarkStream.keyBy(sensor -> sensor.getId()).window(TumblingEventTimeWindows.of(Time.seconds(5)));//todo 5)定義窗口函數SingleOutputStreamOperator<String> result = sensorWS.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {@Overridepublic void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {out.collect("key" + s + "\n" +"數據為" + elements + "\n" +"數據條數為" + elements.spliterator().estimateSize() + "\n" +"窗口時間為" + context.window().getStart() + "->" + context.window().getEnd());}});//todo 6)輸出測試result.print();//todo 啟動運行env.execute();}/*** 水位傳感器,用來接受水位數據*/@Data@AllArgsConstructor@NoArgsConstructorprivate static class WaterSensor {private String id; //傳感器idprivate long ts; //時間private Integer vc; //水位}
}
注意:flink 1.12 版本之后的有序流添加周期水印
//注意:下面的代碼使用的是Flink1.12中新的API
SingleOutputStreamOperator<WaterSensor> sensorDS = lines//TODO 有序流中的watermark.assignTimestampsAndWatermarks(//指定watermark生成(單調遞增)WatermarkStrategy.<WaterSensor>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {@Overridepublic long extractTimestamp(WaterSensor element, long recordTimestamp) {//指定如何從數據提取時間戳return element.getTs() * 1000L;
}));
結果:
情況一:一種類別輸入
sensor_6,1547718201,15 -》2019-01-17 17:43:21
sensor_6,1547718205,15 -》2019-01-17 17:43:25
sensor_6,1547718210,15 -》2019-01-17 17:43:30輸出:
數據>>>> MonotonousWaterMark.WaterSensor(id=sensor_6, ts=1547718201, vc=15)
數據>>>> MonotonousWaterMark.WaterSensor(id=sensor_6, ts=1547718205, vc=15)
keysensor_6
數據為[MonotonousWaterMark.WaterSensor(id=sensor_6, ts=1547718201, vc=15)]
數據條數為1
(2019-01-17 17:43:20 - > 2019-01-17 17:43:25)數據>>>> MonotonousWaterMark.WaterSensor(id=sensor_6, ts=1547718210, vc=15)
keysensor_6
數據為[MonotonousWaterMark.WaterSensor(id=sensor_6, ts=1547718205, vc=15)]
數據條數為1
窗口時間為1547718205000->1547718210000
(2019-01-17 17:43:25 - > 2019-01-17 17:43:30)
情況二:兩種類別輸入
sensor_1,1547718199,35 -》2019-01-17 17:43:19
sensor_6,1547718201,15 -》2019-01-17 17:43:21
sensor_6,1547718205,15 -》2019-01-17 17:43:25
sensor_6,1547718210,15 -》2019-01-17 17:43:30輸出:
數據>>>> MonotonousWaterMark.WaterSensor(id=sensor_1, ts=1547718199, vc=35)
數據>>>> MonotonousWaterMark.WaterSensor(id=sensor_6, ts=1547718201, vc=15)
數據>>>> MonotonousWaterMark.WaterSensor(id=sensor_6, ts=1547718205, vc=15)
keysensor_1
數據為[MonotonousWaterMark.WaterSensor(id=sensor_1, ts=1547718199, vc=35)]
數據條數為1
窗口時間為1547718195000->1547718200000
(2019-01-17 17:43:15 - > 2019-01-17 17:43:20)keysensor_6
數據為[MonotonousWaterMark.WaterSensor(id=sensor_6, ts=1547718201, vc=15)]
數據條數為1
窗口時間為1547718200000->1547718205000
(2019-01-17 17:43:20 - > 2019-01-17 17:43:25)數據>>>> MonotonousWaterMark.WaterSensor(id=sensor_6, ts=1547718210, vc=15)
keysensor_6
數據為[MonotonousWaterMark.WaterSensor(id=sensor_6, ts=1547718205, vc=15)]
數據條數為1
窗口時間為1547718205000->1547718210000
(2019-01-17 17:43:25 - > 2019-01-17 17:43:30)
總結:
- 1- 體現窗口左閉右開思想(即右端時間重合的數據不參與計算)
- 2- 有序數據的水印窗口標準開始時間 :時間戳(秒級)// 窗口長度 * 窗口長度 * 1000 (這里的整除可以去掉余數)
// 如果是秒級,而不是時間戳:
1)start = timestamp - (timestamp - offset + windowSize) % windowSize; ?事件時間 - (事件時間 - 0 + 窗口大小)%窗口大小 ?????????時間戳按照窗口長度 取整數倍(以1970年1月1日0點為起點 => 倫敦時間) ?2)end = start + size ???????? 開始時間 + 窗口長度3)左閉右開: 屬于本窗口的最大時間戳 = end -1ms , 所以時間為 end這條數據,不屬于本窗口,所以是開區間
-
3- 有序數據的水印窗口標準結束時間 :標準開始時間 + 窗口長度
-
4- 此時水位線的變化和事件時間保持一致(因為是有序時間,就不需設置延遲,那么 t 就是 0。
? watermark = maxtime - 0 = maxtime)
-
5- 環境并行度設置為 1,方便觀察現象
-
6- flink 1.12 之前版本,需要指定事件時間,env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
-
7- 轉換時間戳時需要毫秒級別
-
8- window().getStart() 獲取窗口標準開始時間,window().getEnd()獲取窗口標準結束時間
-
9- spliterator().estimateSize() 獲取窗口內數據條數
-
10- api版本區別:
- flink1.12之前:調用 assignTimestampAndwatermarks,new 一個 AscendingTimestampExtractor,重寫方法獲取時間戳
- flink1.12之后:調用 assignTimestampAndWatermarks,有序流回調本質周期水印策略
- WatermarkStrategy.forMonotonousTimestamps.withTimestampAssigner
- new 一個序列化 SerializableTimestampAssigner,重寫方法獲取時間戳
-
11- 應用場景:周期水印解決數據有序場景
(2) 亂序事件中的Watermark
例子:以 java bean 的數據輸入作為亂序事件時間
package cn.itcast.day09.WaterMark;/*** @author lql* @time 2024-03-02 15:20:38* @description TODO:*/import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;/*** 使用固定延遲水印,解決數據亂序的場景(大多數情況都是亂序的數據,使用比較多)* 需求:從socket接受數據,進行轉換操作,然后應用窗口每隔5秒生成一個窗口,使用水印時間觸發窗口計算** 使用水印的前提:* 1:數據必須要攜帶事件時間* 2:指定事件時間作為數據處理的時間* 3:指定并行度為1* 4:使用之前版本的api的時候,需要增加時間類型的代碼** 測試數據:* sensor_1,1547718199,35 -》2019-01-17 17:43:19* sensor_6,1547718201,15 -》2019-01-17 17:43:21* sensor_6,1547718205,15 -》2019-01-17 17:43:25* sensor_6,1547718210,15 -》2019-01-17 17:43:30** todo 固定延遲觸發,根據事件時間-最大亂序時間-1得到水印,根據水印時間作為觸發窗口的條件* 觸發窗口計算的兩個條件:* 1:時間達到窗口的endtime* 2:窗口中存在數據*/
public class OutOfOrdernessWaterMark {public static void main(String[] args) throws Exception {// todo 1) 設置流處理環境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// todo 2) 數據源SingleOutputStreamOperator<WaterSensor> lines = env.socketTextStream("node1", 9999).map(new MapFunction<String, WaterSensor>() {@Overridepublic WaterSensor map(String value) throws Exception {String[] data = value.split(",");return new WaterSensor(data[0], Long.valueOf(data[1]), Integer.parseInt(data[2]));}});// todo 3) 設置水印//flink1.12之前版本的api編寫SingleOutputStreamOperator<WaterSensor> waterMarkStream = lines.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<WaterSensor>(Time.seconds(3)) {@Overridepublic long extractTimestamp(WaterSensor element) {return element.getTs() * 1000L;}});waterMarkStream.print("數據>>>");//todo 4)應用窗口操作WindowedStream<WaterSensor, String, TimeWindow> sensorWS = waterMarkStream.keyBy(t -> t.getId()).window(TumblingEventTimeWindows.of(Time.seconds(5)));//todo 5) 自定義窗口SingleOutputStreamOperator<String> result = sensorWS.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {@Overridepublic void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> collector) throws Exception {collector.collect("key: " + s + "\n" +"數據為: " + elements + "\n" +"條數為:" + elements.spliterator().estimateSize() + "\n" +"時間窗口為:" + context.window().getStart() + "->" + context.window().getEnd() + "\n");}});//todo 6) 打印操作result.print();//todo 7) 啟動程序env.execute();}/*** 水位傳感器,用來接受水位數據*/@Data@AllArgsConstructor@NoArgsConstructorprivate static class WaterSensor {private String id; //傳感器idprivate long ts; //時間private Integer vc; //水位}
}
注意:flink 1.12 版本之后的無序流添加固定延遲水印
SingleOutputStreamOperator<WaterSensor> waterMarkStream = lines.assignTimestampsAndWatermarks(// 固定延遲水印,是 Duration 類型WatermarkStrategy<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {@Overridepublic long extractTimestamp(WaterSensor waterSensor, long l) {return waterSensor.getTs() * 1000L;}}));
結果:
情況一:一種類別輸入
sensor_6,1547718201,15 -》2019-01-17 17:43:21
sensor_6,1547718205,15 -》2019-01-17 17:43:25
sensor_6,1547718210,15 -》2019-01-17 17:43:30輸出:
數據>>>> OutOfOrdernessWaterMark.WaterSensor(id=sensor_6, ts=1547718201, vc=15)
數據>>>> OutOfOrdernessWaterMark.WaterSensor(id=sensor_6, ts=1547718205, vc=15)
數據>>>> OutOfOrdernessWaterMark.WaterSensor(id=sensor_6, ts=1547718210, vc=15)
key: sensor_6
數據為: [OutOfOrdernessWaterMark.WaterSensor(id=sensor_6, ts=1547718201, vc=15)]
條數為:1
時間窗口為:1547718200000->1547718205000
(2019-01-17 17:43:20 -> 2019-01-17 17:43:25)
總結:
-
1- 如果是有 key 類別的差異,觸發窗口計算往往在 key 變化時,而不需要兩個一樣的 key 作為對照
-
2- 因為設置了延遲,在觸發窗口范圍的時候,事件時間 - 延遲時間 = 水印時間
- (例子中打印了 3 條數據,即第 3 條數據觸發計算,第3條數據的水印時間的秒級:30 - 3 = 27 >= 窗口的 endTime)
- 窗口觸發兩個條件,一是水印時間達到窗口 endTime,二是窗口內有數據
-
3- api版本區別:
-
flink1.12之前:調用 assignTimestampAndWatermarks,new 一個 BoundedOutofOrdernessTimestampExtractor
注意設置
延遲時間,重寫方法獲取事件時間 -
flink1.12之后:調用 assignTimestampAndWatermarks,有序流回調固定延遲水印策略
- WatermarkStrategy.forBoundedOutOfOrderness(
Duration類型延遲時間).withTimestampAssigner - new 一個序列化 SerializableTimestampAssigner,重寫方法獲取時間戳
- WatermarkStrategy.forBoundedOutOfOrderness(
-
-
4- 應用場景:固定延遲水印解決數據亂序場景
(3) 并行數據流中的Watermark
對齊機制會取所有 Channel 中最小的 Watermark,即:
每個并行度中必須都有數據,且都滿足觸發窗口條件,才會有對齊機制
例子:將并行度設置為2,帶有線程號
package cn.itcast.day09.WaterMark;/*** @author lql* @time 2024-03-02 19:27:53* @description TODO:多并行度下的水印操作演示*/import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.stringtemplate.v4.ST;import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Date;
import java.util.Iterator;/*** 測試數據:* 并行度設置為2測試:* hadoop,1626934802000 ->2021-07-22 14:20:02* hadoop,1626934805000 ->2021-07-22 14:20:05* hadoop,1626934806000 ->2021-07-22 14:20:06*/
public class Watermark_Parallelism {//定義打印數據的日期格式final private static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");public static void main(String[] args) throws Exception {// todo 1) 流式環境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);// todo 2) 數據源SingleOutputStreamOperator<Tuple2<String, Long>> tupleDataStream = env.socketTextStream("node1", 9999).map(new MapFunction<String, Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> map(String line) throws Exception {try {String[] array = line.split(",");return Tuple2.of(array[0], Long.parseLong(array[1]));} catch (NumberFormatException e) {System.out.println("輸入的數據格式不正確:" + line);return Tuple2.of("null", 0L);}}}).filter(new FilterFunction<Tuple2<String, Long>>() {@Overridepublic boolean filter(Tuple2<String, Long> tuple) throws Exception {if (!tuple.f0.equals("null") && tuple.f1 != 0L) {return true;}return false;}});// todo 3) 水印操作SingleOutputStreamOperator<Tuple2<String, Long>> waterMarkDataStream = tupleDataStream.assignTimestampsAndWatermarks(//TODO 自定義watermark生成器WatermarkStrategy.forGenerator(new WatermarkGeneratorSupplier<Tuple2<String, Long>>() {@Overridepublic WatermarkGenerator<Tuple2<String, Long>> createWatermarkGenerator(Context context) {return new MyWatermarkGenerator<>();}}).withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {@Overridepublic long extractTimestamp(Tuple2<String, Long> element, long recordTimestamp) {// 獲取數據中的 eventTimeLong timestamp = element.f1;// 定義字符串并打印System.out.println("鍵值:" + element.f0 + ",線程號:" + Thread.currentThread().getId() + "," +"事件時間:【" + sdf.format(timestamp) + "】");return timestamp;}}));// todo 4) 分流和窗口SingleOutputStreamOperator<String> result = waterMarkDataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5))).apply(new WindowFunction<Tuple2<String, Long>, String, Tuple, TimeWindow>() {@Overridepublic void apply(Tuple tuple, TimeWindow window, Iterable<Tuple2<String, Long>> input, Collector<String> out) throws Exception {//定義該窗口所有時間字段的集合對象ArrayList<Long> timeArr = new ArrayList<>();// 首先獲取了輸入數據流(input)的迭代器Iterator<Tuple2<String, Long>> iterator = input.iterator();while (iterator.hasNext()) {Tuple2<String, Long> tuple2 = iterator.next();timeArr.add(tuple2.f1);}//對保存到集合列表的時間進行排序Collections.sort(timeArr);//打印輸出該窗口觸發的所有數據String outputData = "" +"\n 鍵值:【" + tuple + "】" +"\n 觸發窗口數據的個數:【" + timeArr.size() + "】" +"\n 觸發窗口的數據:" + sdf.format(new Date(timeArr.get(timeArr.size() - 1))) +"\n 窗口計算的開始時間和結束時間:" + sdf.format(new Date(window.getStart())) + "----->" +sdf.format(new Date(window.getEnd()));out.collect(outputData);}});//TODO 6)打印測試result.printToErr("觸發窗口計算結果>>>");//TODO 7)啟動作業env.execute();}public static class MyWatermarkGenerator<T> implements WatermarkGenerator<T>{//定義變量,存儲當前窗口中最大的時間戳private long maxTimestamp = -1L;/*** 每條數據都會調用該方法* @param event* @param eventTimestamp* @param output*/@Overridepublic void onEvent(T event, long eventTimestamp, WatermarkOutput output) {//System.out.println("on Event...");maxTimestamp = Math.max(maxTimestamp, eventTimestamp);}/**** 周期性的執行,默認是200ms調用一次* @param output*/@Overridepublic void onPeriodicEmit(WatermarkOutput output) {//System.out.println("on Periodic..."+System.currentTimeMillis());//發射watermarkoutput.emitWatermark(new Watermark(maxTimestamp -1L));}}
}
結果:
輸入:* hadoop,1626934802000 ->2021-07-22 14:20:02* hadoop,1626934805000 ->2021-07-22 14:20:05* hadoop,1626934806000 ->2021-07-22 14:20:06輸出:
鍵值:hadoop,線程號:68,事件時間:【2021-07-22 14:20:02.000】
鍵值:hadoop,線程號:69,事件時間:【2021-07-22 14:20:05.000】
鍵值:hadoop,線程號:68,事件時間:【2021-07-22 14:20:06.000】
觸發窗口計算結果>>>:2>
鍵值:【(hadoop)】觸發窗口數據的個數:【1】觸發窗口的數據:2021-07-22 14:20:02.000窗口計算的開始時間和結束時間:2021-07-22 14:20:00.000----->2021-07-22 14:20:05.000
總結:
- 1- 獲取線程號:Thread.currentThread().getId()
- 2- 自定義日期格式:new SimpleDateFormat()
- 3- 看到 input 是 Iterate 類型,需要調用 iterator()方法轉化為迭代對象,運用 while 循環結合 hashNext()邊迭代邊加入列表
- 4- Collections.sort(列表),可以對列表進行排序
(4) 自定義 Watermark
A. 周期性水印
package cn.itcast.day09.WaterMark;/*** @author lql* @time 2024-03-02 17:07:17* @description TODO*/import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;/*** 自定義周期性水印,內置水印:固定延遲水印和單調遞增水印都是基于周期性水印開發的,默認是200ms生成一次watermark*/
public class WaterMark_Periodic {public static void main(String[] args) throws Exception {// todo 1) 設置流處理環境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// todo 2) 數據源SingleOutputStreamOperator<WaterSensor> lines = env.socketTextStream("node1", 9999).map(new MapFunction<String, WaterSensor>() {@Overridepublic WaterSensor map(String value) throws Exception {String[] data = value.split(",");return new WaterSensor(data[0], Long.valueOf(data[1]), Integer.parseInt(data[2]));}});// todo 3) 設置水印操作SingleOutputStreamOperator<WaterSensor> sensorDS = lines.assignTimestampsAndWatermarks(WatermarkStrategy.forGenerator(new WatermarkGeneratorSupplier<WaterSensor>() {@Overridepublic WatermarkGenerator<WaterSensor> createWatermarkGenerator(Context context) {return new MyWatermarkGenerator<>();}}).withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {@Overridepublic long extractTimestamp(WaterSensor waterSensor, long l) {return waterSensor.getTs() * 1000L;}}));// todo 4) 分組KeyedStream<WaterSensor, String> sensorKS = sensorDS.keyBy(t -> t.getId());// todo 5) 開窗WindowedStream<WaterSensor, String, TimeWindow> sensorWS = sensorKS.window(TumblingEventTimeWindows.of(Time.seconds(10)));// todo 6) 自定義窗口SingleOutputStreamOperator<String> result = sensorWS.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {@Overridepublic void process(String s, Context context, Iterable<WaterSensor> iterable, Collector<String> out) throws Exception {out.collect("key: " + s + "\n" +"數據為: " + iterable + "\n" +"條數為:" + iterable.spliterator().estimateSize() + "\n" +"時間窗口為:" + context.window().getStart() + "->" + context.window().getEnd() + "\n");}});// todo 7) 打印和啟動result.print();env.execute();}/*** 水位傳感器,用來接受水位數據*/@Data@AllArgsConstructor@NoArgsConstructorprivate static class WaterSensor {private String id; //傳感器idprivate long ts; //時間private Integer vc; //水位}private static class MyWatermarkGenerator<T> implements WatermarkGenerator<T> {private long maxTimestamp = -1L;/*** 每條數據執行一次* @param event* @param eventTimestamp* @param watermarkOutput*/@Overridepublic void onEvent(T event, long eventTimestamp, WatermarkOutput watermarkOutput) {System.out.println("onEvent……");maxTimestamp = Math.max(eventTimestamp, maxTimestamp);}/*** 周期性執行一次* @param watermarkOutput*/@Overridepublic void onPeriodicEmit(WatermarkOutput watermarkOutput) {System.out.println("onPeriodicEmit……"+ +System.currentTimeMillis());// 發生水印watermarkOutput.emitWatermark(new Watermark(maxTimestamp));}}
}
結果:
onPeriodicEmit……1709376044007
onPeriodicEmit……1709376044214
onPeriodicEmit……1709376044415
onPeriodicEmit……1709376044631
onPeriodicEmit……1709376044834
總結:
- 1- 自定義水印:WatermarkStrategy.forGenerator(new WatermarkGeneratorSupplier)
- 重寫方法,返回新的 Class<>()
- 繼承 WatermarkGenerator ,重寫兩個方法,一個每條數據執行一次,一個周期執行一次(默認是200ms)
- 2- 更改執行周期:env.getConfig().setAutoWatermarkInterval(2000)
- 3- 調用易出錯:forGenerate 有 withTimestampAssigner 方法
B. 間歇性水印:
- 在上述自定義周期性水印方法的 onEvent 中實現 onPeriodicEmit 中的生成水印代碼即可實現
watermarkOutput.emitWatermark(new Watermark(maxTimestamp));
2.6 在數據源之后使用水印 (Kafka) [重點]
2.6.1 kafka 向指定分區寫入數據
package cn.itcast.day09.watermark.kafka;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.internals.Topic;import java.util.Properties;/*** kafka生產者工具類,模擬數據的生成,將數據寫入到指定的分區中** 第一個分區寫入:1000,hadoop、7000,hadoop-》沒有觸發窗口計算* 第二個分區寫入:7000,flink -》觸發了窗口計算*/
public class KafkaMock {private final KafkaProducer<String, String> producer;public final static String TOPIC = "test3";private KafkaMock(){Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node01:9092");props.put(ProducerConfig.ACKS_CONFIG, "all");props.put(ProducerConfig.RETRIES_CONFIG, 0);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");producer = new KafkaProducer<String, String>(props);}public void producer(){long timestamp = 1000;String value = "hadoop";String key = String.valueOf(value);String data = String.format("%s,%s", timestamp, value);producer.send(new ProducerRecord<String, String>(TOPIC, 1, key, data));producer.close();}public static void main(String[] args) {new KafkaMock().producer();}
}
2.6.2 水印機制消費 kafak 數據
package cn.itcast.day09.watermark.kafka;import org.apache.flink.api.common.eventtime.TimestampAssigner;
import org.apache.flink.api.common.eventtime.TimestampAssignerSupplier;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import scala.collection.convert.Wrappers;import java.time.Duration;
import java.util.Iterator;
import java.util.Properties;
import java.util.concurrent.TimeUnit;/*** 使用水印消費kafka里面的數據*/
public class WatermarkTest {public static void main(String[] args) throws Exception {//todo 1)初始化flink流處理環境Configuration configuration = new Configuration();configuration.setInteger("rest.port", 8081);//設置webui的端口號StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(configuration);env.setParallelism(2);env.enableCheckpointing(5000);//todo 2)接入數據源//指定topic的名稱String topicName = "test3";//實例化kafkaConsumer對象Properties props = new Properties();props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node01:9092");props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "test001");props.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");props.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");props.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "2000");props.setProperty("flink.partition-discovery.interval-millis", "5000");//開啟一個后臺線程每隔5s檢測一次kafka的分區情況FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>(topicName, new SimpleStringSchema(), props);kafkaSource.setCommitOffsetsOnCheckpoints(true);//todo 在開啟checkpoint以后,offset的遞交會隨著checkpoint的成功而遞交,從而實現一致性語義,默認就是trueDataStreamSource<String> kafkaDS = env.addSource(kafkaSource);//在數據源上添加水印SingleOutputStreamOperator<String> watermarkStream = kafkaDS.assignTimestampsAndWatermarks(WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new TimestampAssignerSupplier<String>() {@Overridepublic TimestampAssigner<String> createTimestampAssigner(Context context) {return new TimestampAssigner<String>() {@Overridepublic long extractTimestamp(String element, long recordTimestamp) {return Long.parseLong(element.split(",")[0]);}};}}).withIdleness(Duration.ofSeconds(60)));//todo 3)單詞計數操作SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = watermarkStream.map(new MapFunction<String, Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> map(String value) throws Exception {return new Tuple2<String, Long>(value.split(",")[1], 1L);}});//todo 4)單詞分組操作wordAndOne.keyBy(x-> x.f0).window(TumblingEventTimeWindows.of(Time.of(5, TimeUnit.SECONDS))).process(new ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow>() {@Overridepublic void process(String s, Context context, Iterable<Tuple2<String, Long>> elements, Collector<String> out) throws Exception {long sum = 0L;Iterator<Tuple2<String, Long>> iterator = elements.iterator();while (iterator.hasNext()){Tuple2<String, Long> tuple2 = iterator.next();System.out.println(tuple2.f0);sum += tuple2.f1;}out.collect(s + ","+sum);}}).print();env.execute();//todo 6)啟動作業env.execute();}
}
結果1:沒加 withIdleness
輸入:* 第一個分區寫入:1000,hadoop、7000,hadoop-》沒有觸發窗口計算* 第二個分區寫入:7000,flink -》觸發了窗口計算
結果2:加上 withIdleness
輸入:* 第一個分區寫入:1000,hadoop、7000,hadoop-》30s 后觸發窗口計算
結論:
- 1- 當某一個分區的觸發機制達到的時候,其他的分區觸發機制遲遲未觸發的時候,無法觸發機制
- 2- withIdleness(Duration.ofSeconds(30)),允許 30s 等待其他分區觸發計算,如果還沒有觸發,直接計算該分區
- 3- 工作中一般設置 1 - 10分鐘
- 4- kafka 數據源添加水印,withTimestampAssigner 需要 new 一個 TimestampAssignerSupplier (第一次出現)
2.7 Flink 對嚴重遲到數據的處理
例子:延遲數據處理機制設計
package cn.itcast.day09.WaterMark;/*** @author lql* @time 2024-03-03 13:11:44* @description TODO*/import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;import java.time.Duration;/*** flink默認情況下會將遲到的數據丟棄,但是對于絕大多數的業務中是不允許刪除遲到數據的,因此可以使用flink的延遲數據處理機制進行數據的獲取并處理*/
public class LatenessDataDemo {public static void main(String[] args) throws Exception {// 設置環境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 數據源DataStreamSource<String> lines = env.socketTextStream("node1", 9999);SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lines.map(new MapFunction<String, Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> map(String value) throws Exception {String[] data = value.split(",");return new Tuple2<String, Long>(data[0], Long.parseLong(data[1]));}});// 水印操作 -> 水印3秒SingleOutputStreamOperator<Tuple2<String, Long>> watermarkStream = wordAndOne.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {@Overridepublic long extractTimestamp(Tuple2<String, Long> element, long recordTimestamp) {// 報錯地方:因為我們的數據源已經是毫秒級別了,就不需要轉換 *1000L哦!return element.f1;}}));// 窗口操作 -> 5秒窗口// todo 1. 設置允許延遲的時間是通過allowedLateness(lateness: Time)設置WindowedStream<Tuple2<String, Long>, String, TimeWindow> windowStream = watermarkStream.keyBy(t -> t.f0).window(TumblingEventTimeWindows.of(Time.seconds(5))).allowedLateness(Time.seconds(2));// todo 2.初始化延遲到達的數據對象OutputTag<Tuple2<String,Long>> outputTag = new OutputTag<>("side output",TypeInformation.of(new TypeHint<Tuple2<String, Long>>() {}));// todo 3.保存延遲到達的數據WindowedStream<Tuple2<String, Long>, String, TimeWindow> sideOutputLateData = windowStream.sideOutputLateData(outputTag);// 數據聚合SingleOutputStreamOperator<Tuple2<String, Long>> result = sideOutputLateData.apply(new WindowFunction<Tuple2<String, Long>, Tuple2<String, Long>, String, TimeWindow>() {@Overridepublic void apply(String s, TimeWindow window, Iterable<Tuple2<String, Long>> input, Collector<Tuple2<String, Long>> out) throws Exception {String key = null;Long counter = 0L;for (Tuple2<String, Long> element : input) {key = element.f0;counter += 1;}out.collect(Tuple2.of(key, counter));}});result.print("正常到達的數據>>>");// todo 4.獲取延遲到達的數據DataStream<Tuple2<String, Long>> sideOutput = result.getSideOutput(outputTag);sideOutput.printToErr("延遲到達的數據>>>");env.execute();}
}
結果:
/** 每5s一個窗口,水印:3s,延遲等待:2s* 測試數據:* hadoop,1626936202000 -> 2021-07-22 14:43:22 第一個窗口的數據* hadoop,1626936207000 -> 2021-07-22 14:43:27 因為設置了水印,所以不會觸發窗口計算* hadoop,1626936202000 -> 2021-07-22 14:43:22 第一個窗口的數據* hadoop,1626936203000 -> 2021-07-22 14:43:23 第一個窗口的數據* hadoop,1626936208000 -> 2021-07-22 14:43:28 觸發了窗口計算(hadoop,3),水印時間滿足窗口endtime** ====================事件時間 28 秒 -> 水印時間 25 秒 剛好臨界 endtime =======================* ===============延遲 2s 等待機制:延遲到事件時間 30s 即 水印時間 27s 關閉第一個窗口===============** 第一個窗口時間 2021-07-22 14:43:20 -> 2021-07-22 14:43:25** hadoop,1626936202000 -> 2021-07-22 14:43:22 已經觸發過計算的窗口再次有新數據到達,(hadoop,4)(數據重復計算)* hadoop,1626936203000 -> 2021-07-22 14:43:23 已經觸發過計算的窗口再次有新數據到達,(hadoop,5)* hadoop,1626936209000 -> 2021-07-22 14:43:29 雖然 水印時間達到endtime,但是窗口里面沒有新數據,不觸發計算* hadoop,1626936202000 -> 2020-07-22 14:43:22 已經觸發過計算的窗口再次有新數據到達,(hadoop,6)* hadoop,1626936210000 -> 2021-07-22 14:43:30 滿足了窗口銷毀的條件,開始專注于第二個新窗口** 第二個窗口時間 2021-07-22 14:43:25 -> 2021-07-22 14:43:30* * ====================事件時間 33 秒 -> 水印時間 30 秒 剛好臨界 endtime ====================================* * ===============延遲 2s 等待機制:延遲到事件時間 35s 即 水印時間 32s 關閉第二個窗口===============** hadoop,1626936202000 -> 2021-07-22 14:43:22 打印遲到數據,(hadoop,1626936202000)* hadoop,1626936215000 -> 2021-07-22 14:43:35 達到水印時間觸發窗口計算:(hadoop,3),之前27,28,29秒的數據*/
總結:
-
1- 設計允許遲到數據時間:
在水印策略后面加上:allowedLateness(Times.seconds())
-
2- 初始化遲到的數據對象:
new OutputTag<>(id名字,TypeInformation.of(new TypeHint<遲到數據類型>(){ }))
-
3- 保存延遲到達遲到數據:
窗口流.sideOutputLateData(初始化對象)
-
4- 獲取延遲到達遲到數據:
結果流.getSideOutput(初始化對象)
-
5- 測輸出流是之前 Window Function API 中的重要算子
OutputTag(注意復習!)
思考:
-
allowedLateness(Times.seconds) 設計允許遲到時間和
withIdleness(Duration.ofSeconds(30)) 設計允許等待觸發時間有什么不同呢?
回答:
- (1) 從概念上看,allowedLateness 是延遲窗口關閉,不影響觸發時間,而 withIdleness 等待分區一段時間,等不到就觸發
- (2) 從應用來看,allowedLateness 適用于車聯網入隧道一段時間沒上報數據等待數據,而 withIdleness 適用于分區木桶原理等待數據,等不到數據就單獨分區觸發計算。

![Sqli-labs靶場第20關詳解[Sqli-labs-less-20]自動化注入-SQLmap工具注入](http://pic.xiahunao.cn/Sqli-labs靶場第20關詳解[Sqli-labs-less-20]自動化注入-SQLmap工具注入)

 函數支持變長參數列表)















