在當今信息爆炸的時代,網絡爬蟲作為一種自動化的數據收集工具,其重要性不言而喻。它能夠幫助我們從互聯網上高效地提取和處理數據,為數據分析、市場研究、內容監控等領域提供支持。抖音作為一個全球性的短視頻平臺,擁有海量的用戶生成內容,這些內容背后蘊含著巨大的數據價值。通過分析這些數據,企業和個人可以洞察流行趨勢、用戶偏好、市場動態等,從而做出更加精準的決策。
一、準備工作
在開始網絡爬蟲的實踐之前,我們需要做好充分的準備工作。首先,確保你的計算機上安裝了Python環境,這是進行網絡爬蟲開發的基礎。接下來,你需要安裝一些必要的Python庫,如requests用于發送HTTP請求,BeautifulSoup用于解析HTML文檔,以及Selenium用于模擬瀏覽器行為。此外,使用Selenium時,還需要下載對應瀏覽器的WebDriver,以便自動化地操作瀏覽器。
pip install requests beautifulsoup4pip install selenium
然后,你可以使用以下Python代碼作為起點:
import requests
from bs4 import BeautifulSoup# 抖音的URL
url = 'https://www.douyin.com'# 發送HTTP請求
response = requests.get(url)# 確保請求成功
if response.status_code == 200:# 解析HTML內容soup = BeautifulSoup(response.text, 'html.parser')# 打印頁面標題print("頁面標題:", soup.title.string)# 找到所有的視頻鏈接(這里假設視頻鏈接包含在特定的標簽中)video_links = soup.find_all('a', href=True) # 根據實際情況調整選擇器for link in video_links:print("視頻鏈接:", link['href'])
else:print("請求失敗,狀態碼:", response.status_code)二、靜態內容抓取
靜態內容抓取是指從網頁中直接提取信息的過程。這通常涉及到以下幾個步驟:
使用requests庫發送HTTP請求,獲取網頁的原始數據。例如,你可以使用requests.get(url)來獲取抖音首頁的HTML內容。
利用BeautifulSoup庫對獲取到的HTML進行解析。BeautifulSoup提供了豐富的方法來處理和提取HTML文檔中的數據。例如,你可以使用find()或find_all()方法來定位特定的HTML元素。
實例:抓取抖音首頁信息。首先,使用requests獲取抖音首頁的HTML。然后,創建一個BeautifulSoup對象來解析這些HTML。接下來,你可以遍歷頁面元素,提取出你感興趣的信息,如視頻標題、用戶信息、點贊數等。
如果你需要處理JavaScript動態加載的內容,你可以使用以下代碼作為起點:
from selenium import webdriver# 設置Selenium驅動
driver = webdriver.Chrome() # 或者使用其他瀏覽器驅動# 打開抖音網站
driver.get('https://www.douyin.com')# 等待頁面加載(這里可能需要根據實際情況調整等待時間)
driver.implicitly_wait(10) # 隱式等待,等待頁面元素出現# 獲取頁面源代碼
html = driver.page_source# 關閉瀏覽器
driver.quit()# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html, 'html.parser')
# ...(后續操作與上面相同)三、抓取抖音視頻列表
首先,安裝并設置好Selenium以及對應的WebDriver。
使用Selenium打開抖音的網頁,例如driver.get("https://www.douyin.com/")。
等待頁面加載完成,這可能需要一些時間,因為頁面內容是通過JavaScript動態加載的。可以使用WebDriverWait和expected_conditions來等待特定元素的出現。
一旦頁面加載完成,你可以使用find_element_by_xpath或其他定位方法來獲取視頻列表。
遍歷視頻列表,提取每個視頻的相關信息,如視頻標題、發布者、播放次數等。
如果需要,可以模擬滾動頁面以加載更多的視頻內容。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 設置WebDriver的路徑
driver_path = 'path/to/your/webdriver' # 例如:'C:/path/to/chromedriver.exe' for Chrome# 創建WebDriver實例
driver = webdriver.Chrome(executable_path=driver_path)# 打開抖音網頁
driver.get('https://www.douyin.com/')# 等待頁面加載完成
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'video-list'))) # 假設視頻列表的類名為'video-list'# 獲取視頻列表
video_list = driver.find_elements(By.CLASS_NAME, 'video-item') # 假設每個視頻的類名為'video-item'# 遍歷視頻列表并打印視頻信息
for video in video_list:# 這里假設視頻標題的類名為'title',可能需要根據實際情況調整title = video.find_element(By.CLASS_NAME, 'title').textprint(f"視頻標題: {title}")# 關閉WebDriver
driver.quit()四、抓取目標用戶視頻數據
要抓取某個博主下的所有視頻數據,你需要執行以下步驟:
定位博主頁面:首先,你需要找到博主的個人主頁。這通常可以通過在抖音平臺上搜索博主的用戶名或ID來實現。
獲取視頻列表:在博主的個人主頁上,通常會有一個視頻列表,展示了博主發布的所有視頻。你需要編寫代碼來遍歷這些視頻,并提取相關信息。
數據存儲:將抓取的視頻數據存儲在適當的格式中,如CSV、JSON或數據庫。
以下是一個簡化的Python代碼示例,展示了如何使用Selenium來抓取博主視頻列表的基本思路。請注意,這個示例假設你已經知道博主的用戶名或ID,并且抖音平臺的頁面結構沒有發生變化。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time# 設置WebDriver的路徑
driver_path = 'path/to/your/webdriver'
driver = webdriver.Chrome(executable_path=driver_path)# 打開抖音并搜索博主
driver.get('https://www.douyin.com/')
search_box = driver.find_element(By.CLASS_NAME, 'search-input') # 假設搜索框的類名為'search-input'
search_box.send_keys('博主用戶名') # 輸入博主的用戶名
search_box.submit()# 等待博主頁面加載
time.sleep(5) # 等待5秒,確保頁面加載完成# 定位博主的個人主頁鏈接并點擊進入
# 這里需要根據實際情況來定位博主的個人主頁鏈接
# 假設我們已經找到了鏈接
bloger_profile_link = driver.find_element(By.CLASS_NAME, 'profile-link') # 假設類名為'profile-link'
bloger_profile_link.click()# 等待視頻列表加載
time.sleep(5) # 等待5秒,確保視頻列表加載完成# 獲取視頻列表并提取數據
video_list = driver.find_elements(By.CLASS_NAME, 'video-item') # 假設視頻項的類名為'video-item'
videos_data = []
for video in video_list:# 提取視頻信息,這里需要根據實際的HTML結構來定位元素title = video.find_element(By.CLASS_NAME, 'video-title').textviews = video.find_element(By.CLASS_NAME, 'video-views').text# ... 其他需要的數據videos_data.append({'title': title, 'views': views, 'url': video.get_attribute('href')})# 打印抓取的視頻數據
for video in videos_data:print(video)# 關閉WebDriver
driver.quit()五、開源軟件推薦
Open-Spider是一個開源的數據采集工具,它旨在簡化數據采集的過程,使得即使沒有數據采集技術背景的用戶也能夠輕松采集海量數據。這個工具提供了一個“采集應用市場”,用戶可以在這里分享、交流和使用其他人上傳的數據采集腳本。通過這種方式,用戶可以快速獲取到自己需要采集的網站數據,并且可以在自己的電腦、服務器或云端運行這些腳本。
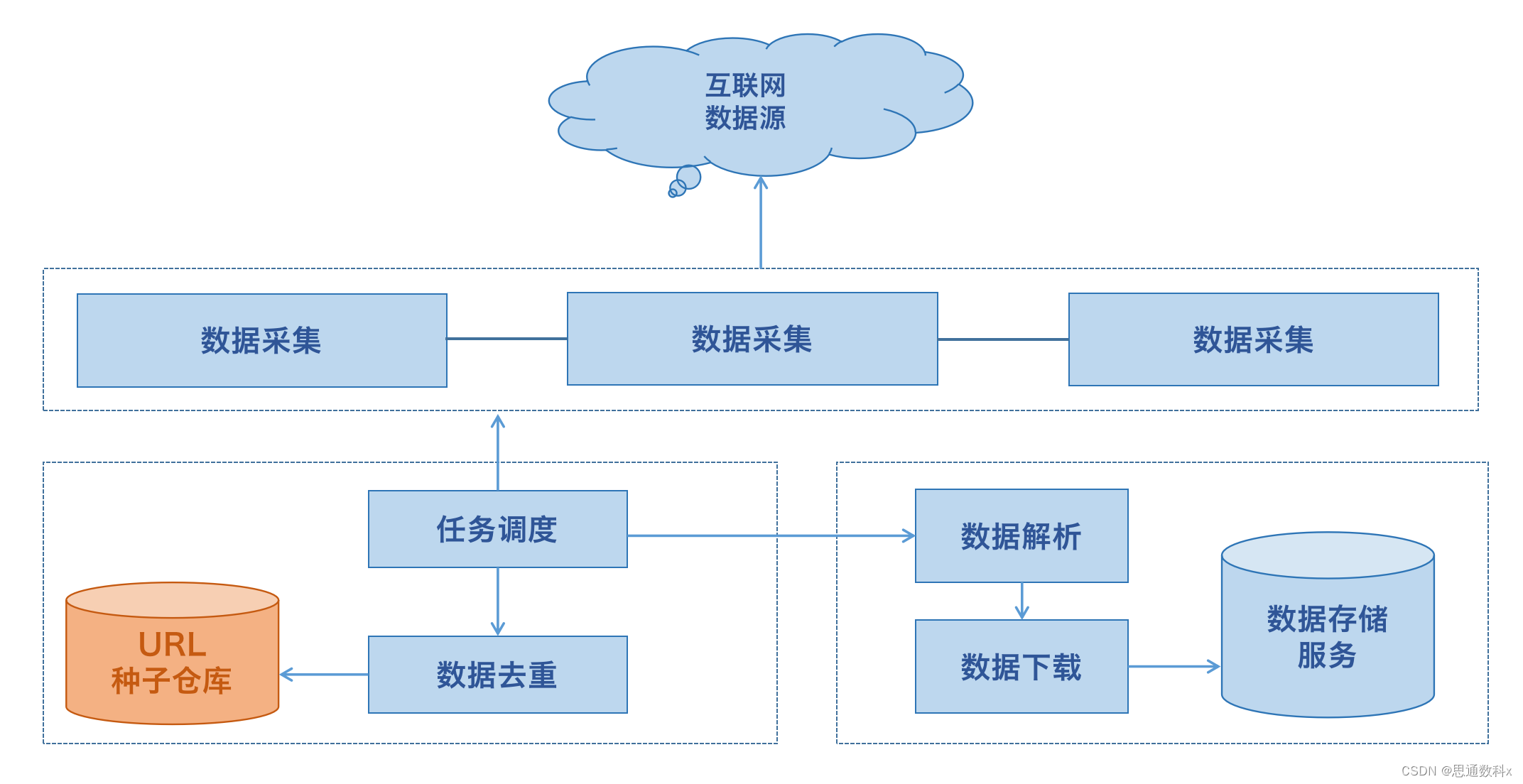
1.模板采集
模板采集模式內置上百種主流網站數據源,如京東、天貓、大眾點評等熱門采集網站,只需參照模板簡單設置參數,就可以快速獲取網站公開數據。
2.智能采集
采集可根據不同網站,提供多種網頁采集策略與配套資源,可自定義配置,組合運用,自動化處理。從而幫助整個采集過程實現數據的完整性與穩定性。
3.自定義采集
針對不同用戶的采集需求,可提供自動生成爬蟲的自定義模式,可準確批量識別各種網頁元素,還有翻頁、下拉、ajax、頁面滾動、條件判斷等多種功能,支持不同網頁結構的復雜網站采集,滿足多種采集應用場景。

六、開源項目地址
Open-Spider: 不懂數據采集技術,也可輕松采集海量數據!簡單易上手,人人可用的數據采集工具!
Open-Spider: 不懂數據采集技術,也可輕松采集海量數據!簡單易上手,人人可用的數據采集工具!![]() https://gitee.com/stonedtx/open-spider
https://gitee.com/stonedtx/open-spider


)






(4))

跳躍游戲Ⅱ)

)
)
![練習 3 Web [ACTF2020 新生賽]Upload](http://pic.xiahunao.cn/練習 3 Web [ACTF2020 新生賽]Upload)
面經)


