??每周跟蹤AI熱點新聞動向和震撼發展 想要探索生成式人工智能的前沿進展嗎?訂閱我們的簡報,深入解析最新的技術突破、實際應用案例和未來的趨勢。與全球數同行一同,從行業內部的深度分析和實用指南中受益。不要錯過這個機會,成為AI領域的領跑者。點擊訂閱,與未來同行! 訂閱:https://rengongzhineng.io/

在數字時代,編程已成為一項必不可少的技能,但有時候編程也會顯得枯燥乏味且耗時。因此,很多開發者開始尋找方法,借助大型語言模型(LLMs)來自動化和簡化他們的編碼任務。這些模型通過訓練大量來自GitHub的開源代碼庫,能夠在幾乎不需要人類干預的情況下生成、分析和記錄代碼。
本文將探索使用StarCoder2,一種全新的社區模型,對代碼LLMs的最新進展。StarCoder2支持數百種編程語言,并提供業界領先的準確性。接下來,我們將利用NVIDIA AI基礎模型和終端嘗試該模型,通過逐步指導進行定制,并將其部署到生產中。
StarCoder2是BigCode與NVIDIA合作構建的最先進的代碼LLM。你可以利用該模型的能力,包括代碼補全、自動填充、高級代碼總結和使用自然語言檢索相關代碼片段,快速構建應用程序。
StarCoder2系列包括3B、7B和15B參數模型,為你提供選擇適合自己使用場景并滿足計算資源需求的靈活性。本文將重點介紹15B模型。
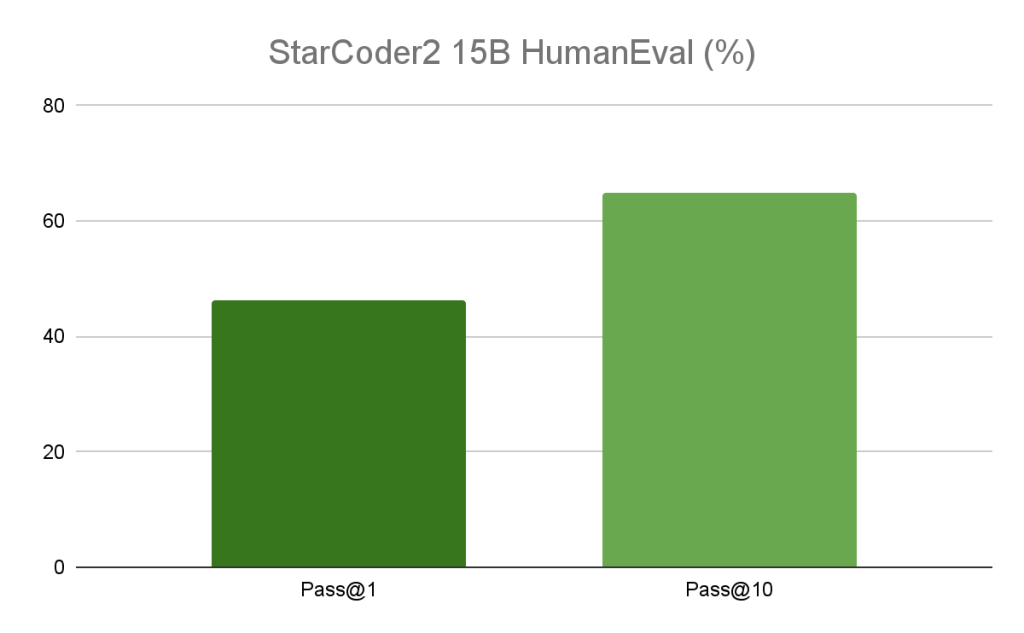
15B模型在流行的編程基準測試中超越了領先的開放代碼LLMs,提供了同類產品中最優秀的性能。例如,Starcoder2 15B模型在HumanEval基準測試中顯示,無論是Pass@1還是Pass@10,模型都展現出46%和65%的高性能。
模型訓練得體,對所有人開放,使用了來自GitHub的超過1萬億令牌的、經過負責任篩選的數據。這包括600多種編程語言、Git提交、GitHub問題和Jupyter筆記本。模型在整個過程中完全透明,包括數據來源、處理和翻譯。此外,個人可以選擇不讓自己的代碼被模型使用。
StarCoder2模型根據BigCode開放RAIL-M許可證公開可用,確保免版稅分發并簡化了公司將模型集成到他們的用例和產品中的過程。
StarCoder2作為NVIDIA AI基礎模型和終端的一部分提供,提供了一套經過策劃的社區和NVIDIA構建的生成性AI模型,供你體驗、定制和部署在企業應用中。
NVIDIA已經使用TensorRT-LLM優化了模型,這是一個用于定義、優化和執行大型語言模型推理的開源庫。這使你在推理過程中能夠實現更高的吞吐量和更低的延遲,同時在生產中降低計算成本。
現在,你可以直接通過瀏覽器使用簡單的游樂場用戶界面體驗StarCoder2,查看運行在完全加速堆棧上的模型生成的結果。
如果你更喜歡使用API測試模型,我們也為你提供了便利。注冊NGC目錄后,你將獲得NVIDIA云積分。這些積分讓你能夠將應用程序連接到API端點,并在大規模上體驗模型。
# Will be used to issue requests to the endpoint API_KEY = “nvapi-xxxx“
import requestsinvoke_url = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/835ffbbf-4023-4cef-8f48-09cb5baabe5f"
fetch_url_format = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/status/"headers = {"Authorization": "Bearer {}".format(API_KEY),"Accept": "application/json",
}payload = {"prompt": "X_train, y_train, X_test, y_test = train_test_split(X, y, test_size=0.1) #Train a logistic regression model, predict the labels on the test set and compute the accuracy score","temperature": 0.1,"top_p": 0.7,"max_tokens": 512,"seed": 42,"stream": False
}# re-use connections
session = requests.Session()response = session.post(invoke_url, headers=headers, json=payload)while response.status_code == 202:request_id = response.headers.get("NVCF-REQID")fetch_url = fetch_url_format + request_idresponse = session.get(fetch_url, headers=headers)response.raise_for_status()
response_body = response.json()
# The response body contains additional metadata along with completion text. Visualizing just the completion.
print(response_body['choices'][0]['text'])大多數企業不會直接使用模型。你需要使用你的領域和公司特定的專業語言訓練它們,以便模型能提供高精度的結果。NVIDIA使得通過NeMo定制它們變得簡單。
NVIDIA Triton推理服務器是一個開源的AI模型服務平臺,它簡化并加速了AI推理工作負載在生產中的部署。它幫助企業減少模型服務基礎設施的復雜性,縮短新AI模型在生產中部署所需的時間,并增加AI推理和預測能力。
現在就試試StarCoder2模型吧,通過用戶界面或API體驗它,如果這是適合你的應用程序的,那么就使用TensorRT-LLM進行優化,并使用NVIDIA NeMo進行定制吧。
 —— 原始 PPO 代碼解讀)



“云計算應用”賽項樣題 2)














