目錄
一、系統環境
1 鏡像拉取ppocr 進行部署
2 安裝paddlepaddle
二、訓練前的準備
1 下載源碼
2 預模型下載
3 修改模型訓練文件yml
4 編排訓練集
5 執行腳本進行訓練
6 需要修改文件夾名稱
三、開始訓練
1 執行訓練命令
2 對第一次評估進行解釋
3 引言
五、總結
一、系統環境
1. 鏡像拉取ppocr 進行部署
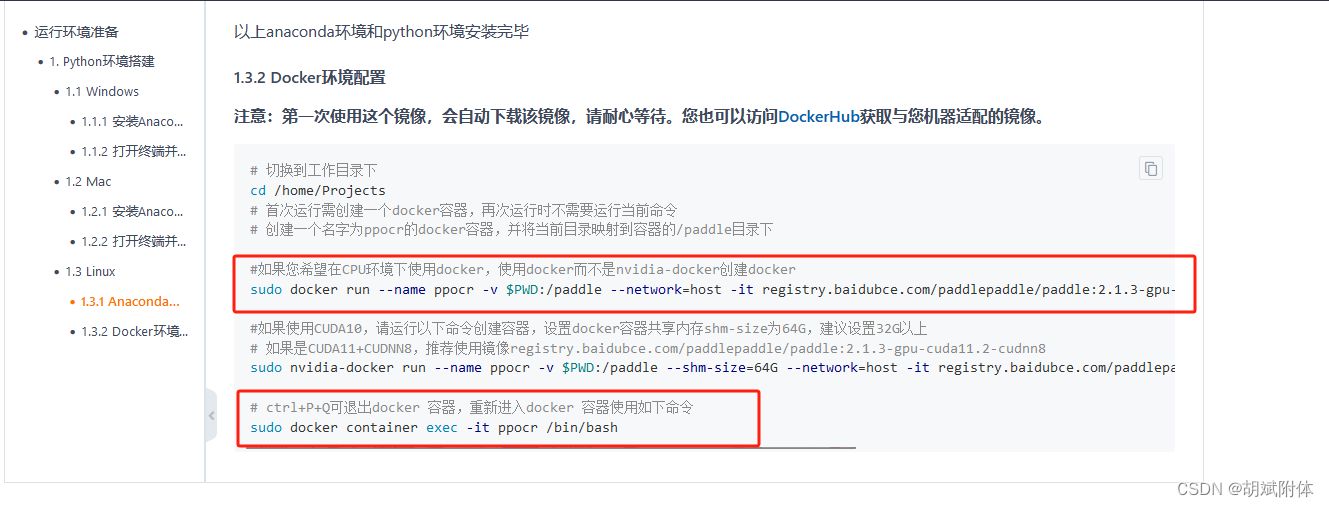
注:gitee上有提供環境準備的鏈接【鏈接】
注:其中用到了下方紅框命令
2. 安裝paddlepaddle
pip install paddlepaddle
二、訓練前的準備
1. 下載源碼
切換到 /paddle/目錄下 下載源碼
cd /paddle
git clone https://gitee.com/paddlepaddle/PaddleOCR.git
# 切換版本
git checkout origin/release/2.7
2. 預模型下載
注:預訓練模型:已經訓練好的模型。在此模型基礎上訓練,對生成新的模型進行增強
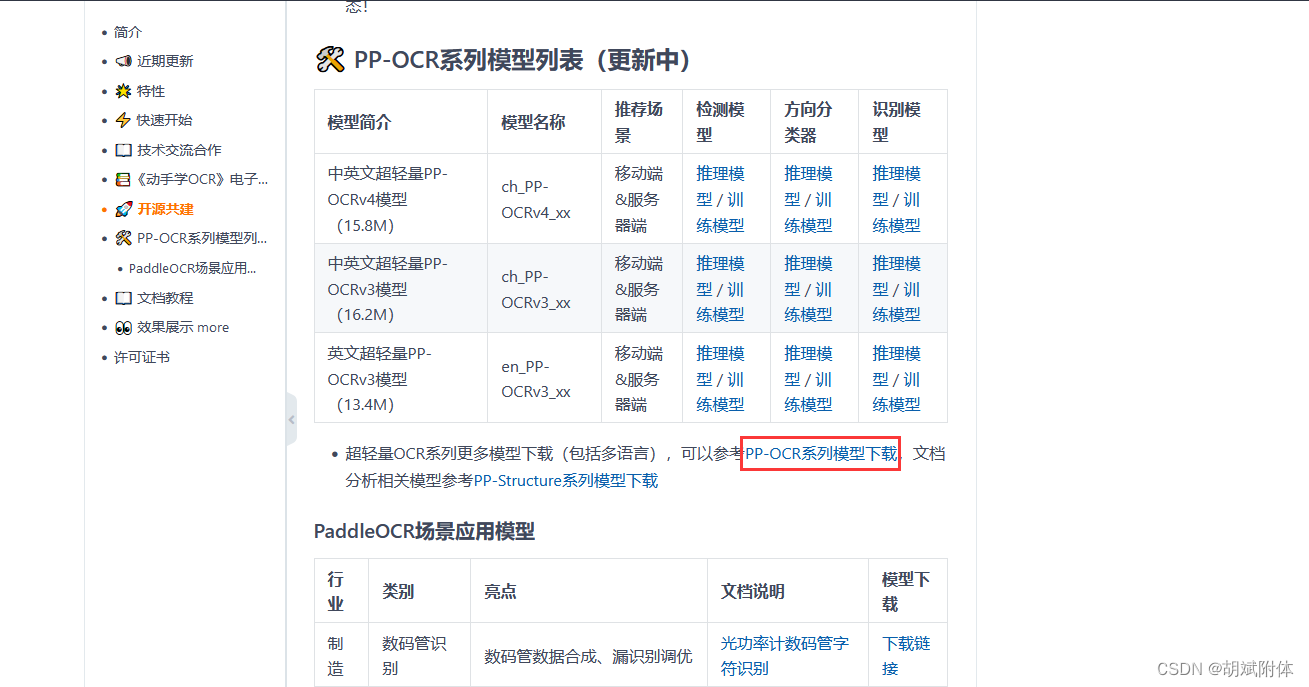
注:進入PP-OCR系列模型下載頁面
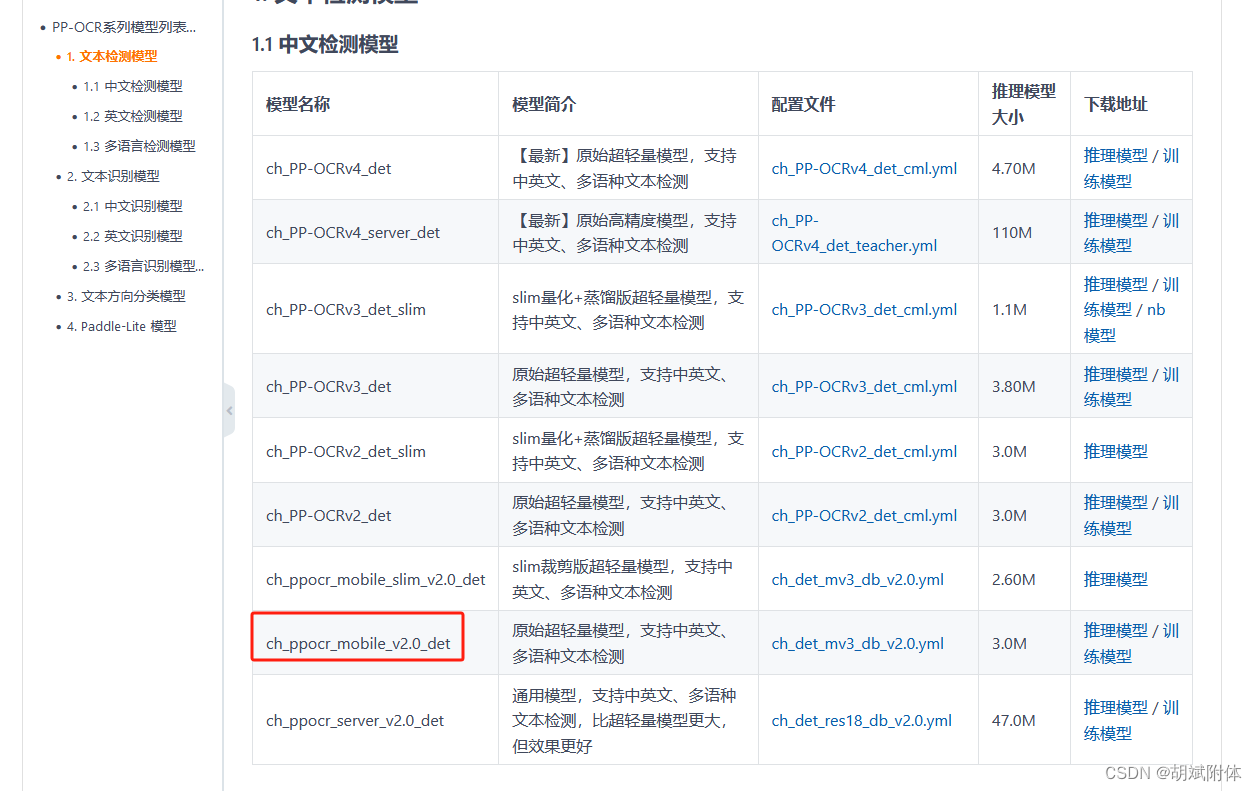
注:此處下載的訓練模型內容是 ch_det_mobile_v2.0_det ( 跟隨參考文章 )
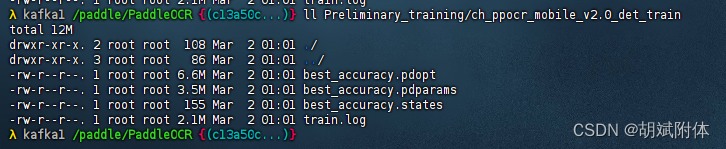
注:首先創建目錄
mkdir /paddle/PaddleOCR/Preliminary_training
注:可訓練自己的數據集,這里跳過,直接使用公開數據集 訓練自己的數據集 參考文章 >>|
注:公開數據集下載說明 >>|
注:共3部分 下載圖片和標注
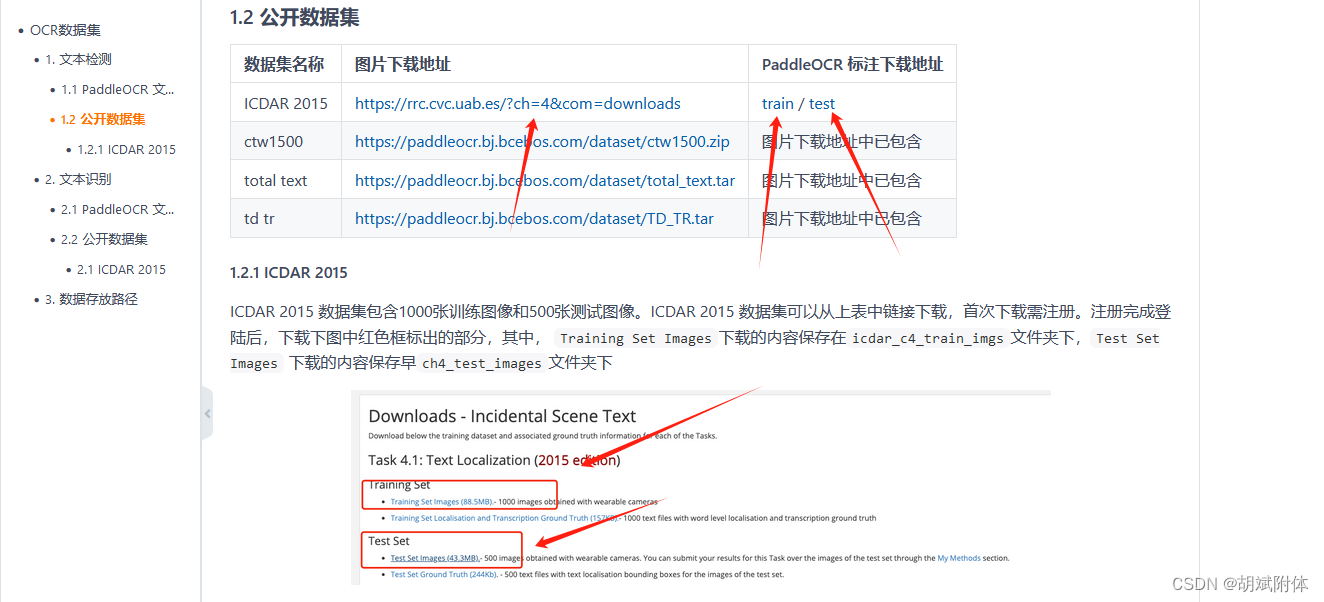
注:進入網站進行下載時需要注冊登錄
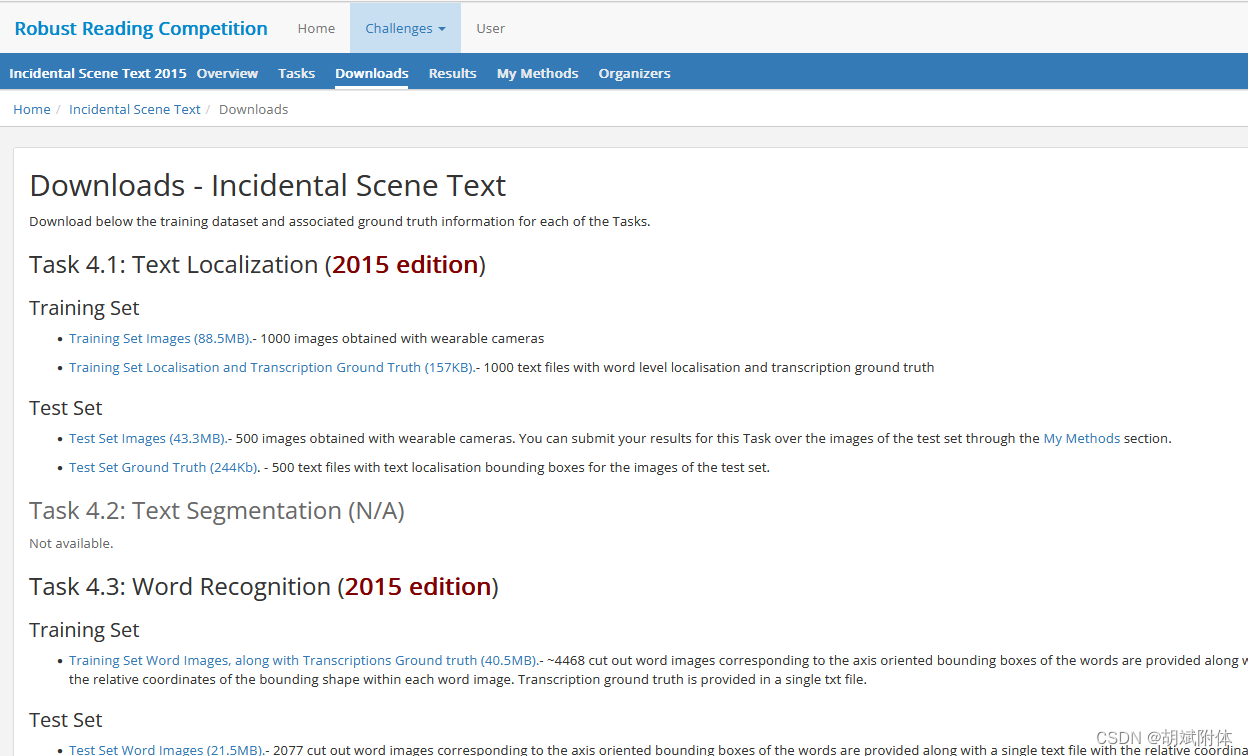
注:下圖就是下載后的內容
注:下載的文件需要對文件夾名稱做修改(留作彩蛋,文章后面會說) 去那 >>|

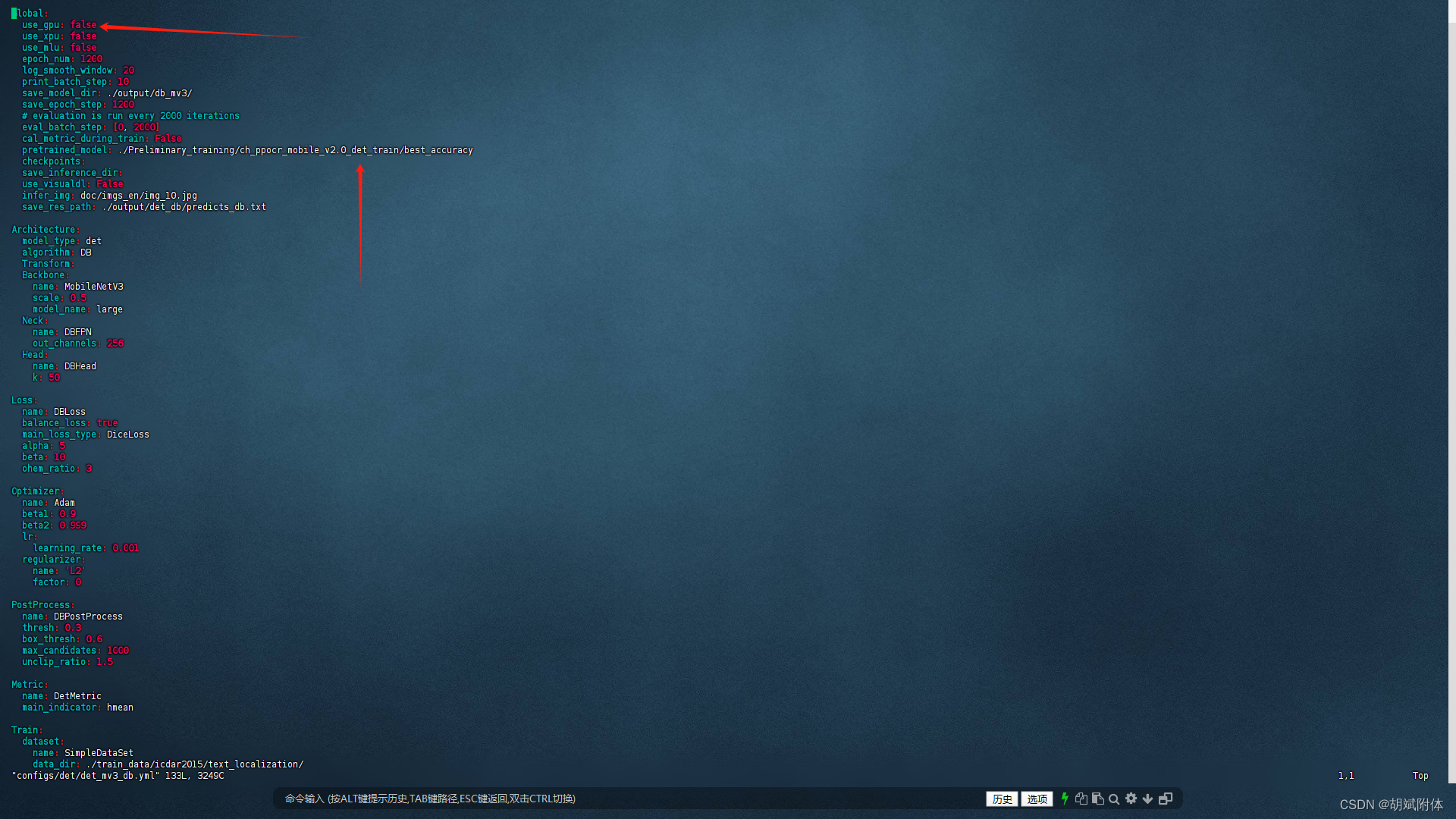
3. 修改模型訓練文件yml
注:修改預訓練模型的位置。修改use_gpu: false(因本機使用的是cpu)
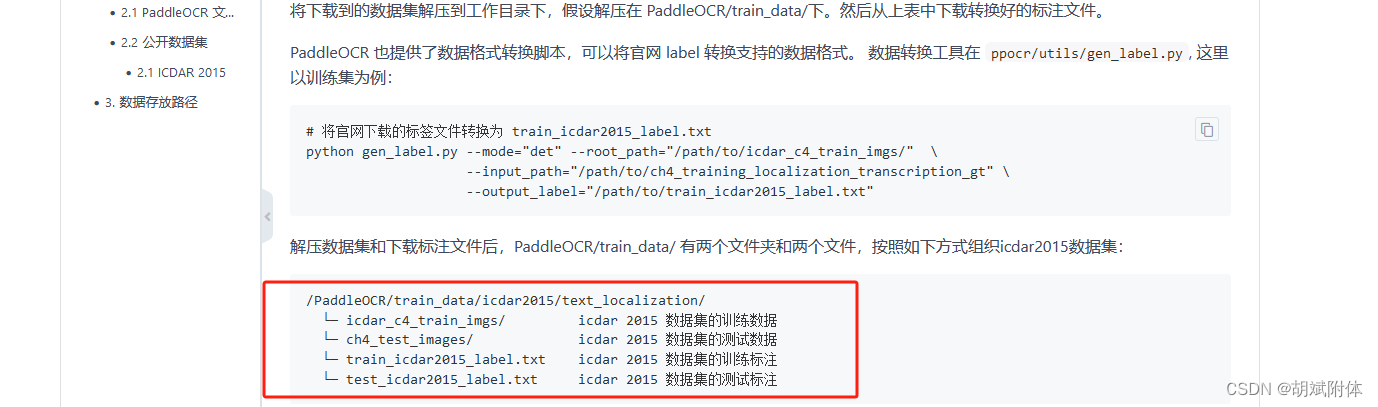
4. 將下載的訓練集進行編排
注:編排如圖
5. 執行腳本進行訓練
注:選擇配置文件進行訓練,這里選擇 ./configs/det/det_mv3_db.yml det_mv3_db的意思基于db和mobileNetV3算法的文本檢測配置文件
注:處理執行時遇到的問題
- 問題1:處理模塊不存在問題
ModuleNotFoundError: No module named 'skimage' , 'imgaug', 'pyclipper', 'tqdm', 'rapidfuzz'
注:安裝相關模塊進行解決
# 安裝圖像處理模塊
pip install scikit-image
# 安裝圖像增強模塊
pip install imgaug
# 安裝形狀裁剪模塊
pip install pyclipper
# 安裝嵌入式數據庫模塊
pip install lmdb
# 安裝進度條庫
pip install tqdm
# 安裝字符串匹配庫
pip install rapidfuzz
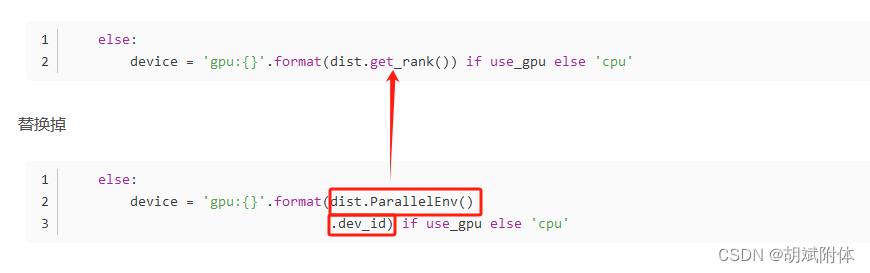
- 問題2:對象無此屬性錯誤

注:編輯報錯文件/paddle/PaddleOCR/tools/program.py 進行修改。將dist.ParallelEnv().dev_id 為 dist.get_rank()
錯誤處理參考文章>> |
6. 修改文件夾名稱(彩蛋)
注:修改訓練文件夾 ch4_training_images 為 標注文件中(train_icdar2015_label.txt)圖片路徑的名稱 icdar_c4_train_imgs
注:或者修改標注文件的內容也可以,保持一致。避免執行訓練腳本時報錯

注:查看標注文件 train_icdar2015_label.txt
cat ./train_data/icdar2015/text_localization/train_icdar2015_label.txt
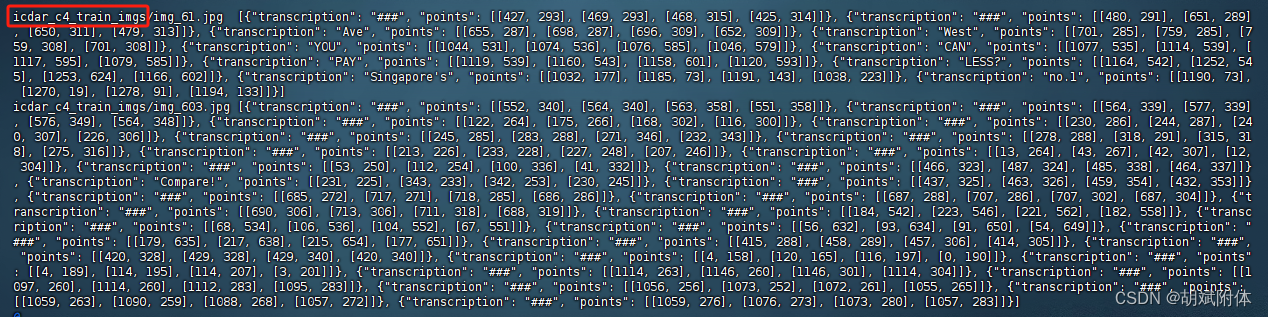
注:故將ch4_training_images 文件夾名稱改成 icdar_c4_train_imgs/

三. 開始訓練
1. 執行訓練命令
python tools/train.py -c configs/det/det_mv3_db.yml
注:解決方案是修改配置文件參數,兼容系統當前系統性能 參考 >> |
注:需要修改配置文件 yml參數 num_workers = 0, 避免報錯(內存空間不足)。空間足夠大cpu核數夠高可以嘗試修改其他數值(這里沒有再進行測試) 參考 >> |

python tools/train.py -c configs/det/det_mv3_db.yml
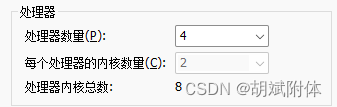
注:cpu配置 4個處理器,2個內核數量
注:內存8G
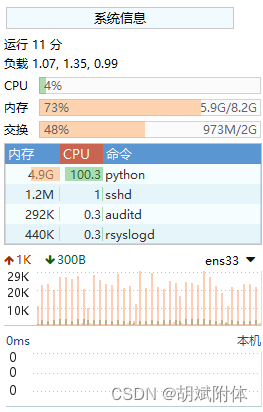
2. 訓練期間第一次評估進行解釋
注:使用的文心 做的翻譯, 向他問了下面這段內容:
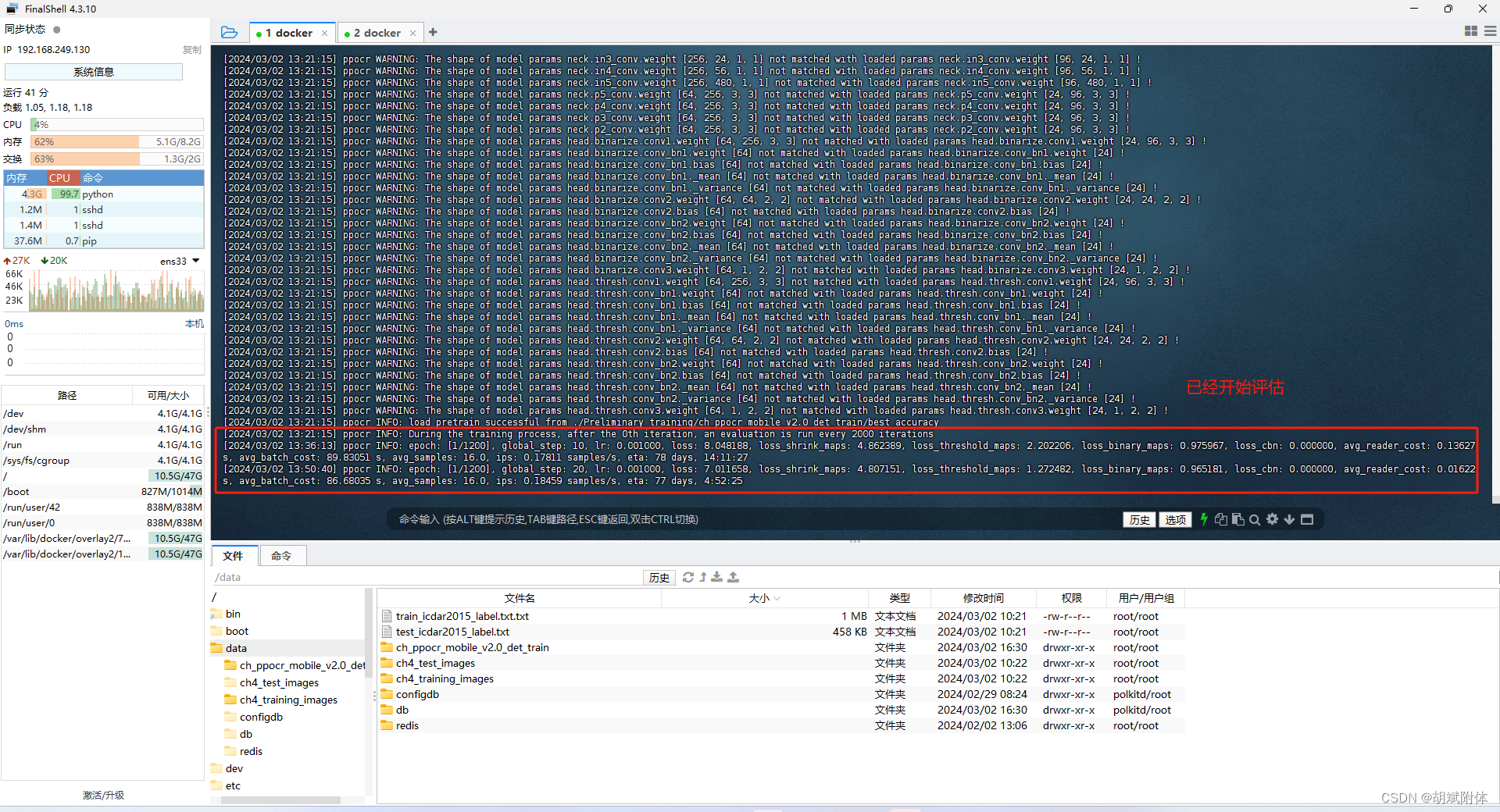
[2024/03/02 13:36:13] ppocr INFO: epoch: [1/1200], global_step: 10, lr: 0.001000, loss: 8.048188, loss_shrink_maps: 4.862389, loss_threshold_maps: 2.202206, loss_binary_maps: 0.975967, loss_cbn: 0.000000, avg_reader_cost: 0.13627 s, avg_batch_cost: 89.83051 s, avg_samples: 16.0, ips: 0.17811 samples/s, eta: 78 days, 14:11:27
注:最后的 eta 時間很大,果斷放棄,看來應該用小一點的訓練集去做

3. 引言。
注:后期會訓練自定義模型在此更新鏈接 Ocr之PaddleOcr嘗試訓練自定義模型 >> |
五、總結
1. 本篇文章只下載了檢測模型進行訓練測試。后期還會生成推理模型和對識別模型進行訓練并測試并對鏈接進行更新
- 推理模型生成 >>|
- 識別模型訓練 >>|







實現服務器(注意要回收子進程))



)



)



![[electron]窗口 BrowserWindow](http://pic.xiahunao.cn/[electron]窗口 BrowserWindow)