目錄
一、B-樹
二、B+樹
三、B*樹
四、時間復雜度
五、Mysql與B樹系列
一、B-樹
????????首先再說B樹的性質以及其他的之前,先要說一聲,好多人都把這個樹叫B減樹,其實不是,他就叫B樹,至于原因我覺的沒必要再這個名字上糾結吧!!
????????其實簡單點說B樹就是多叉平衡樹,為什么這么說呢?其實他就是在平衡二叉樹原有的基礎上,進行改進的。為什么要改進呢?其實也很簡單,就像我們排序的時候一樣,我們不可能一直在內存中進行排序,也有可能在內存外排序,也就是外排序,這個同樣的道理,就是當我們的數據多到一定程度的時候,內存中也就存不下了,而且就算存的下,也不會存,先不說大型項目中的那些數據,如果一不小把程序給關了,那么這些數據就沒了,所以我們選擇存儲在磁盤上。但是我們在磁盤上怎么找他呢?如果我們在代碼中找他的時候,那么勢必要把磁盤數據加載到內存中,而我們找數據講究的是快,所以我們采用一定的數據結構來管理這些數據,以方便我們查找的時候,可以快速的找到。
? ? ? ? 我們學習過的數據結構中,查找能排上號的就是哈希,AVL,紅黑樹等。但是此時要想到一個問題就是,用這些數據結構中的其中一個來保存這些數據,那么我們勢必要進行IO,這個是無可避免的,因為我們要知道的是,這個是從磁盤上讀取數據到內存中。所以我們每次進行比較的時候,都是一次IO,這樣就大大的降低了我們查找的效率。

如上圖中的二叉樹,其實我們一般存儲的是文件塊的地址,來一個數據,因為這里是地址,所以我們每個節點都要進行IO,所以此時就效率就低了。
也有人說用哈希,哈希其實也是一個道理,它也要進行IO。我們查找數據的時候嗎,總不能拿著地址訪問把,且有的時候,哈希沖突嚴重的時候,每個桶下面掛鏈表還不如掛成紅黑樹,此時不就又繞回來了嗎?所以,此時B樹就閃亮登場了。
B樹的規則:
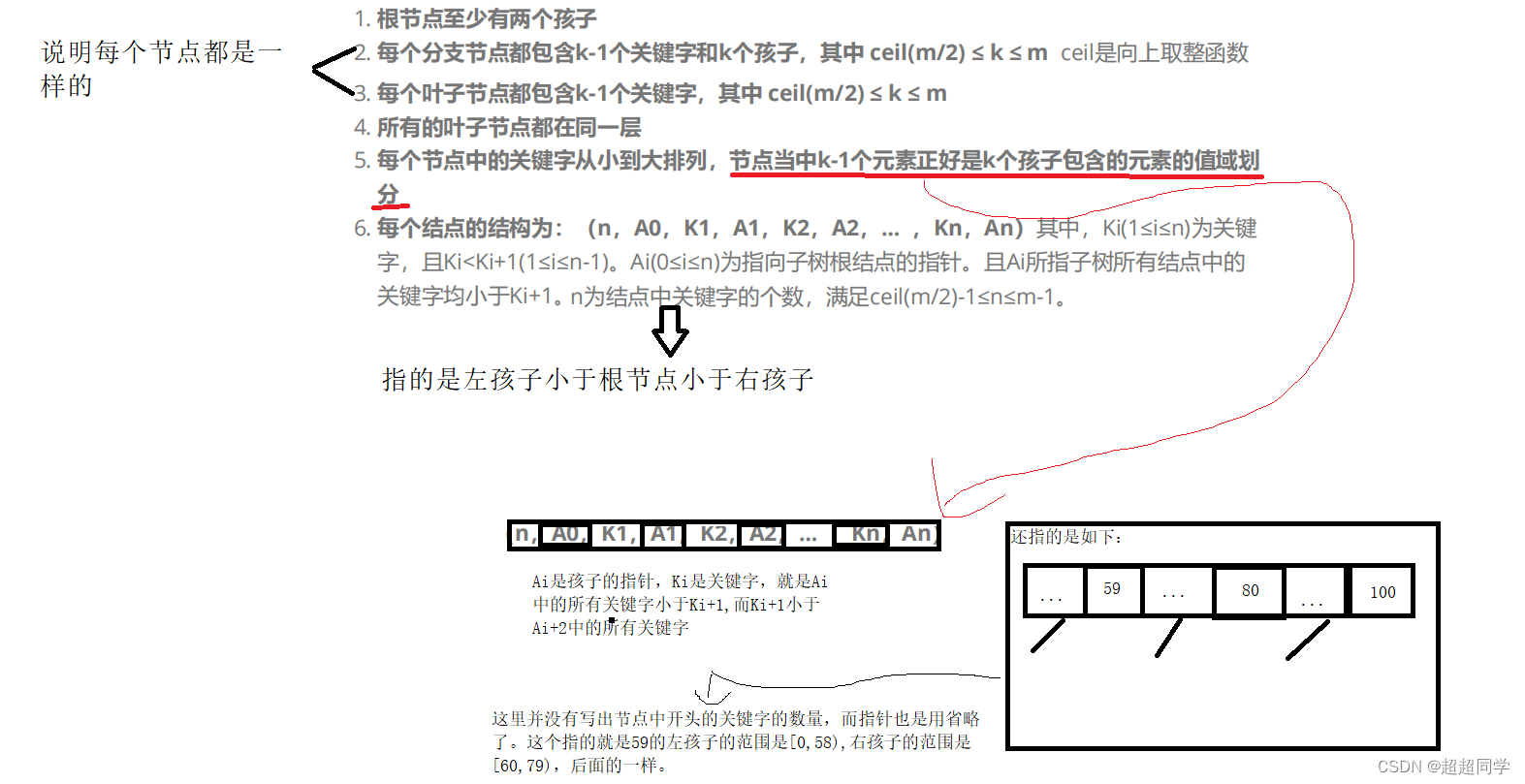 規則如上,這里就不再詳細說了。
規則如上,這里就不再詳細說了。
好了,我們知道了B樹的規則,那么我們為什么要用B樹呢?其實B樹是減少了IO次數。為什么呢?因為我們用B樹的時候,B樹的每個節點的所存儲的關鍵字數量比AVL,紅黑樹等數據結構要多,所以他每次進行IO 的時候,就可以一次讀取多個關鍵子和孩子所指向的文件數據塊。這樣,我們就變相的減少了IO次數。且B樹的每個節點的m一般系統會設置成1024,至于為什么,深入了解過文件系統的伙伴大概知道(這里我自己也是看到過網上有人說,至于原因,個人了解的也不太清楚,好像是跟文件系統的什么大小有關來著,也是1024,知道的伙伴可以說一下),這樣就大大減少了B樹的高度,最差情況下,也是進行高度次IO,而此時的IO次數最多也就是4次。所以大大提高了效率。
二、B+樹
B+樹在原有的B樹的基礎上進行了改進,就是把每個節點的孩子數量改成和關鍵字數量相等了。然后是每個分支節點只有索引,沒有映射的值。葉子結點改成了類似于鏈表的形式,且葉子結點包含映射的值,并且葉子結點中包含了所有節點的索引(關鍵字),并且是有序的。并且每個分支節點的第一個關鍵字是其對應的孩子節點的最小值。如下:

這樣的改進就使得每次搜索必然是要到葉子結點,因為只有這樣才可以拿到關鍵字所映射的內容。
而這樣的話,其實是在一定程度上減少了IO次數,因為B樹是每個節點都有關鍵字和其所映射的內容,而B+樹都是關鍵字,所以每個節點的關鍵相對于B樹是增加了的。也就是在相同空間下,B+樹一次IO的節點數比B樹一次IO的節點數要多。
其次,就是B+樹的比那里遍歷相對于B樹來說是方便了很多。它直接可以遍歷葉子結點,就可以得到所有內容。
三、B*樹
其實B*樹就是在B+樹上做了一些相應的改進,它整體是提高了空間利用率,但是其他方面與B+樹沒有什么本質區別。且在運用的時候,B+樹用的較多。而B*樹不是沒用,而是相對于B+樹來說,運用的較少而已。
四、時間復雜度
其實怎么說,老師講課的時候說的是logMN(m為底,n的對數),但是我感覺這樣有點不太對勁。后來我在網上查了些資料,有的說是mlogmn、logm*logmn,logn。其實我個人認為logmn是不對的,我自己也想了很久,其實也不能說是不對,只是這個時間復雜度是是最好的情況下是logmn,我認為我剛剛說的以上的三個是比較正確的(logmn只是個人感覺不太對,不是錯的,就是這個是最好的情況以下,才是logmn)。
1.m*logmn
因為我們都知道的是,B樹的每個節點都是有M-1個關鍵字,這里1影響不大,所以直接省略。那么最壞的情況下是每個節點都比較得到最后一個節點,比較B樹的高度次,所以就應該是m*logmn。有些伙伴說這里可以把m給省略了,就是logmn,但是我想說的是,這里不可以省略。因為將近十億個數據的高度是將近3-4層,也就是3<=logmn<=4,而系統默認給的B樹的每個節點m=1024,所以這里m的影響還是很大的,所以我認為是不可以省略的。而其實這里的時間復雜度也是跟m的取值有關。如果m取值相對于logmn的影響較小,此時才可以省略。如果就用系統默認給的m,這里我認為是不可以省略的。
2.logm*logmn
這個就很好理解了,因為每個節點的關鍵字都是有序的,所以我們在查找每個節點的關鍵字的時候,不要遍歷,只需要直接用二分查找就好,所以是logm*logmn。
后面的一個是logn其實就是二分查找這個方法的時間復雜度化簡得到的。這里簡單說一下,就是用換底公式就可以化簡出來。
五、Mysql與B樹系列
其實學習過數據庫的都知道,數據庫本質是管理文件中的數據,而數據結構是管理內存中的數據。那么,我們B樹系列的數據結構與數據庫有什么關系呢?其實也很容易就也可以想到。因為B樹系列的誕生使得我們可以進行在磁盤上進行查找數據時大大提高了效率。但是,特悶到底是什么關系呢?
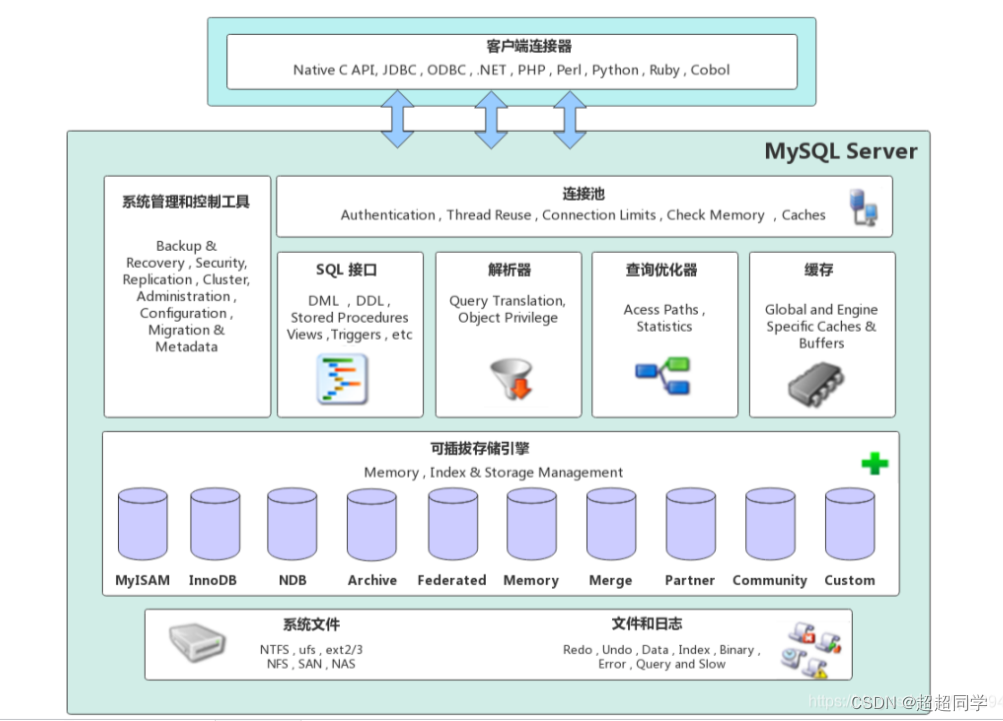
其實Mysql本質就是cs模型,這里就不詳細說明。建立數據庫其實本質上就是在存儲引擎的這里建立B+樹。然后存儲引擎下面就是文件系統。而其實緩存就是把磁盤數據加載到緩存中。就是類似于LRU這種緩存。而這里主要說一下兩種搜索引擎
1.MyISAM
其建立的B+樹是索引文件與數據文件分開的。索引在我理解來說就是B+樹種的關鍵字。再用SQL語句建立表的時候,一般都會有個主鍵,主鍵是唯一的。(這里是數據庫的知識),而B+樹建立的時候,其key就是這個主鍵,葉子結點是會掛一個val的值來對應映射。如果想用其他搜索,只需建立索引就可以。建立索引數據庫重新建立一個B+樹,然后把這個索引當成key。
2.InnoDB
其建立的B+樹是索引文件與數據文件不分離的,也就是在一起的。注意的是,這個搜索引擎建立索引的B+樹的時候,其葉子結點的val是主鍵值。
Mysql這里講的比較淺,如果有伙伴想了解的,也可以私信,可以互相探討一下。過幾天會發B樹系列的代碼實現,到時候也會詳細說數據庫與B樹系列的關系。有了代碼就好理解了。
最后,希望大家支持一下,謝謝!!!!
)

)

![LeetCode 刷題 [C++] 第347題.前 K 個高頻元素](http://pic.xiahunao.cn/LeetCode 刷題 [C++] 第347題.前 K 個高頻元素)


)

【詳解】)





算法與實現)

- 串口如何用)
)
