
?作者|謝國斌
來源|神州問學
OpenAI近期發布的Sora是一個文本到視頻的生成模型。這項技術可以根據用戶輸入的描述性提示生成視頻,延伸現有視頻的時間,以及從靜態圖像生成視頻。Sora可以創建長達一分鐘的高質量視頻,展示出對用戶提示的精準理解和視覺質量的高度保持。這標志著在生成模型領域向視頻生成的重要步驟,擴展了先前主要集中在文本和圖像上的AI應用范圍。
本文將深入探討OpenAI新推出的Sora模型的涉及到的主要算法技術。分為兩個部分:首先,我們將介紹Sora的模型架構;隨后,詳細解讀所涉及的核心算法(擴散模型、視覺Transformer、其他的創新)。
一、Sora模型架構
Sora報告原文并未詳解模型所涉及的架構。但根據OpenAI32篇參考論文和技術路線圖,我們可以猜想或模擬出Sora的模型架構。
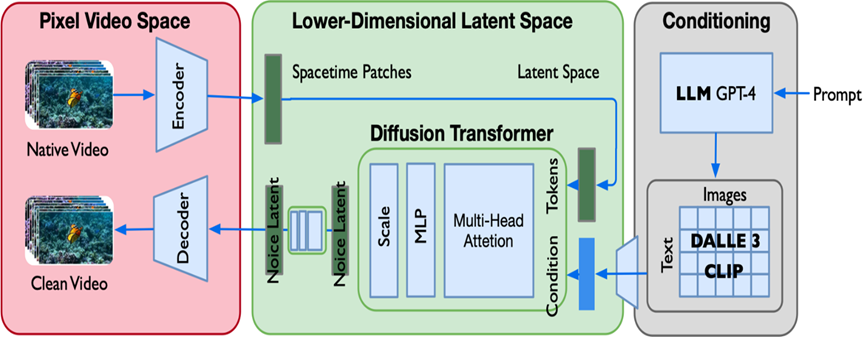
圖1 Sora的模型架構
Sora模型架構應該是在DiT(Diffusion Transformer)基礎上演進而來,分成三個部分:
●左邊紅色部分是視頻數據像素空間,上面是encoder,模型使用VAE將視頻encoder到隱空間降維表示,并對表示分解為spacetime latent patches時空塊方法編碼,生成結果同樣也是通過VAE解碼成原始大小的圖片。SORA從頭訓練了一套能直接壓縮視頻的自編碼器模型。與之前的其他工作相比,通過巧妙的引入結合時空塊的方法,SORA 的自編碼器不僅能在空間上壓縮圖像,還能在時間上壓縮視頻長度,同時對于視頻的長寬比、分辨率、時長還保持了一定的靈活性。
● 中間綠色部分是低維潛空間,是經典latent diffusion model架構的核心,其中的U-Net網絡替換成transformer。視頻在前面經過自編碼器和隱式時空塊之后,進行加噪過程,以及去噪過程。
● 右邊灰色部分是條件輸入,也就是文生視頻里面的文本輸入,即prompt。讓模型支持帶約束圖像生成,其實就是想辦法把額外的約束信息輸入進擴散模型中。除了直接拼接,在LDM中還使用了另一種融合約束信息的方法。具體實現是把DDPM的自注意力層換成交叉注意力層,把k、v換成來自約束的信息,以實現帶約束圖像生成。如本文后面圖3所示,通過把用編碼器 編碼過的約束信息輸入進擴散模型交叉注意力層的k、v,以實現了帶約束圖像生成。條件約束輸入首先是用戶的文本作為prompt喂給GPT4,GPT4進行詳盡的文字說明和擴充,然后使用DALL.E3及CLIP技術,對給定視頻生成對應的標題。
二、Sora核心技術
Sora主要依靠三條技術路徑的結合使用:1.擴散模型diffusion model;2.transformer應用于視覺大模型;3.在數據和算法方向上對已有論文成果的大膽創新應用。
1.擴散模型:文生圖領域的王者方法
擴散模型(Diffusion Models,DM)是深度學習中用于生成模型的一種方法,近年來在圖像、音頻、文本等多個領域取得了顯著的進展。該方法始于2015年(論文21),最初用于學習復雜概率分布的抽樣,這些模型利用了非平衡熱力學中的技術,尤其是擴散過程。2020年,伯克利學者提出了去噪擴散概率模型(DDPM,論文22),后續通過對該方法的持續迭代改進(論文23/24/25),逐步取代了GAN,已成為生成領域的主流方法。2021年末,Robin Rombach等提出了一種基于潛在擴散模型(LDM,論文19)方法,用于高分辨率圖像合成。這種方法通過在壓縮的空間上對圖像進行重建,生成比之前的方法更加可靠與詳細的結果。基于該方法或略微修改優化的版本Stable Diffusion Model,近年來被用于創造出Stable Diffusion、Runway和Midjourney等流行AI類產品。
1.1.擴散模型(DM,DDPM是DM的一個主要發展分支)
去噪擴散概率模型(DDPM)是一種基于擴散過程的生成模型,該模型在自然語言處理、圖像生成、音頻合成等領域展示了其優越的生成能力。它主要分為擴散過程和生成過程:
(1).擴散過程:去噪擴散概率模型通過模擬一個漸進的噪聲添加過程(正向過程)和一個噪聲移除過程(逆向過程)來生成數據。正向過程從數據分布中逐步引入噪聲,直至達到一個與預設噪聲分布接近的狀態;逆向過程則嘗試逆轉這一過程,從噪聲狀態恢復出原始數據。
(2).生成模型:通過學習逆向過程,模型能夠從高斯噪聲中生成與真實數據分布相似的樣本。
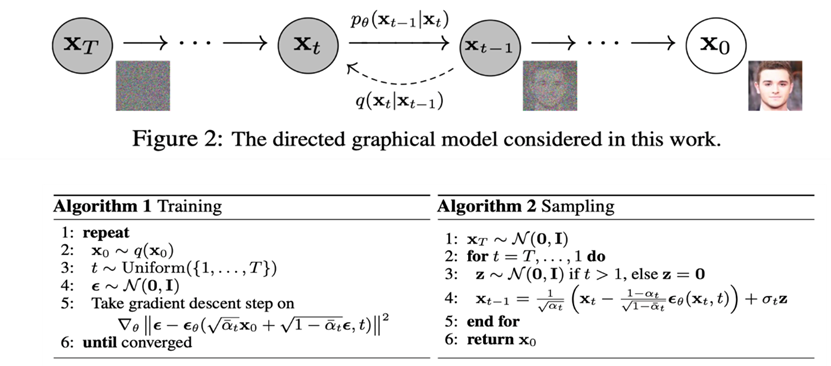
圖2 去噪擴散概率模型(DDPM)
1.2.潛擴散模型(LDM,SD產品應用的奠基之作)
潛在擴散模型(LDM)是一種結合了擴散模型和變分自編碼器VAE的生成模型。它們在處理高維數據(如圖像和視頻)生成任務中特別有效,主要是通過在一個較低維度的潛在空間中進行擴散過程來實現的。
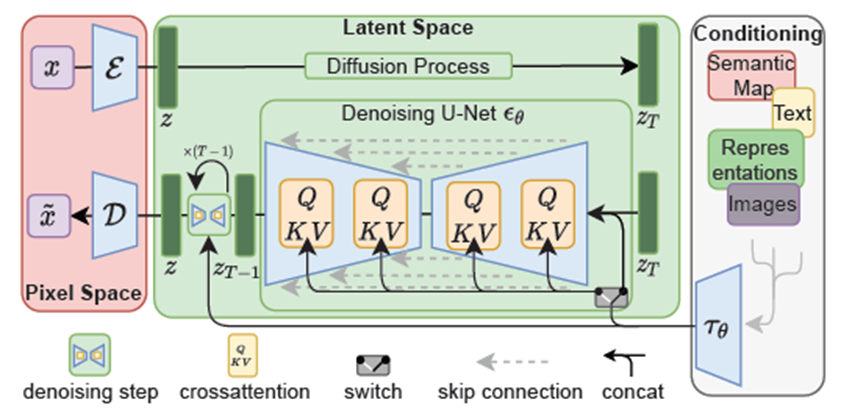
圖3 LDM模型
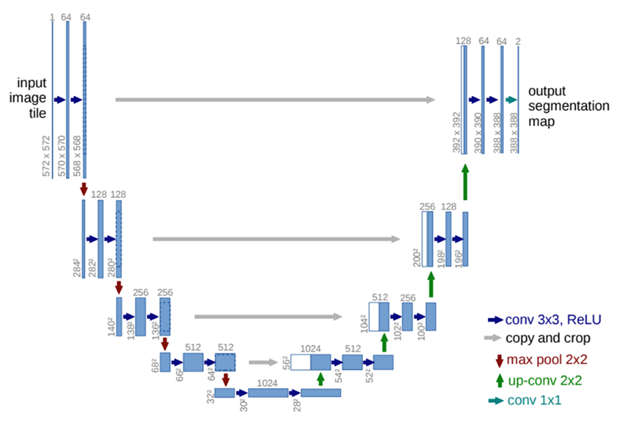
圖4 U-Net網絡結構
2.DiT:將transformer融入擴散模型
在2017年,Vaswani等人引入了Transformers模型(論文13),這是一個革命性的架構,基于注意力機制專為序列到序列的任務設計。它的核心特點是自注意力機制,這使得模型在處理序列中的每個元素時,能夠考慮到序列中所有其他元素,捕捉它們之間的依賴性。這種方法極大地提高了自然語言處理和其他序列任務的處理效率和效果,為AI模型的發展開辟了新的道路。
隨后,ViT模型(論文15)將Transformers技術擴展到了圖像領域,成為這一領域的一種主流方法。基于ViT架構,DiT模型(論文26)進一步融合了Transformers到潛在擴散模型(LDM),在圖像生成方面取得了顯著進步。DiT模型是William Peebles在Meta實習時,和Saining Xie合作產出的作品。William Peebles現在是SORA項目的主創之一,所以DiT目前在SORA模型架構中應該是起著非常重要的作用。
2021年,谷歌提出了ViViT(論文16)方法,這是一種專門用于視頻分析任務的創新方法,它結合了純Transformers架構和時空潛在塊的概念。Sora項目借鑒了ViViT的思路,首次將時空塊引入到DiT模型的輸入中,實現了擴散模型、Transformers和時空潛在塊三者的完美融合。這一算法創新實踐是在視頻生成領域的一大進步。
2.1.ViT:transformer用于圖像識別的主流方法
ViT 將transformer結構應用于圖像,圖片被劃分為多個 patch 后,將二維 patch 轉換為一維向量作為transformer encoder的輸入。

圖5 ViT模型架構
2.2.DiT:diffusion+transformer
在潛在擴散模型(圖3)中,DiT用transformer替換U-Net主干(如圖6所示),可達到很好的圖像生成效果。
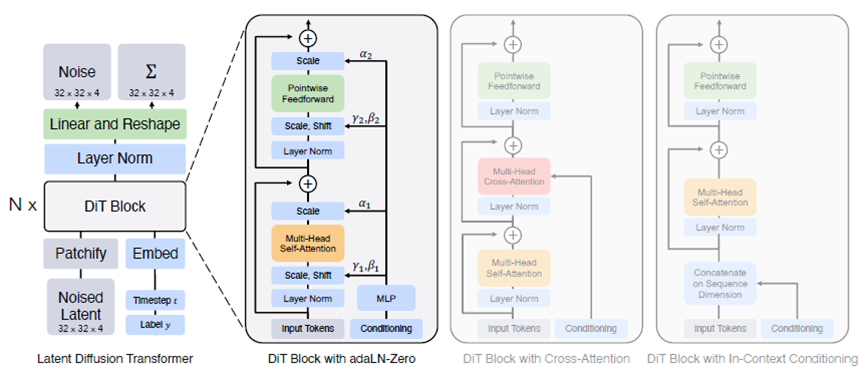
圖6 DiT模型架構
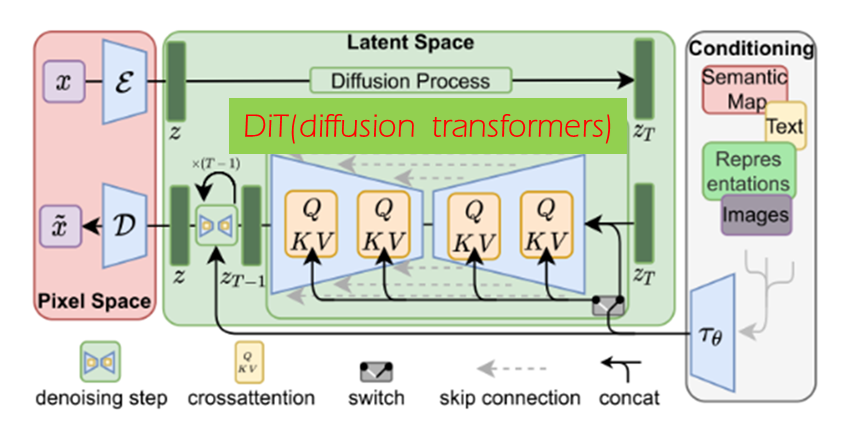
圖7 用DiT模型架構替換LDM模型中的U-Net部分
2.3.隱式時空塊(Spacetime Latent Patches)
時空塊方法是谷歌在ViViT論文(論文16)中首次提出。Sora在訓練和生成時參考借鑒了此方法,對使用的視頻可以是任何分辨率、任何長寬比、任何時長的,而不需要對視頻做縮放、裁剪等預處理,這種方法的靈活性是一個較大的創新。transformer 的計算與輸入順序無關,但要用位置編碼來指明每個數據的位置。Sora在DiT架構中可能使用了類似于(x,y,t) 這種組合的位置編碼來表示一個時空塊的位置,以實現不管輸入的視頻大小如何、長度如何,只要給每個圖塊都分配一個位置編碼,就能分清圖塊間的相對先后關系。
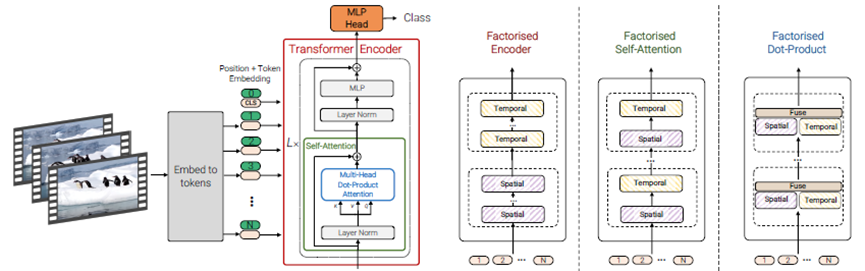
圖8 ViViT模型架構

圖9 ViviT中對視頻數據的Tubelet embedding編碼方法
3.數據和算法:多種技巧的創新應用
3.1.NaViT:抽樣多樣化和性能提升
谷歌在去年發表了Patch n’ Pack(論文19),其中的 NaViT可以在訓練過程中使用序列打包(Patch n’ Pack)的方法,可以處理任意分辨率和寬高比的輸入。相比ViT,NaViT計算性能大幅提升。同時,NaViT可在訓練和微調過程中處理各種分辨率的圖像或視頻,表現出優秀的性能,并顯著降低推理成本。
前述隱式時空塊和NaViT兩種技術的結合使用,Sora達到的效果:視頻無需任何裁剪和預處理,先用時空塊打patch,對不同分辨率、持續時間和長寬比的視頻進行訓練,既最好的利用高質量視頻的原始信息,又顯著提升模型性能,節約了訓練與推理成本。
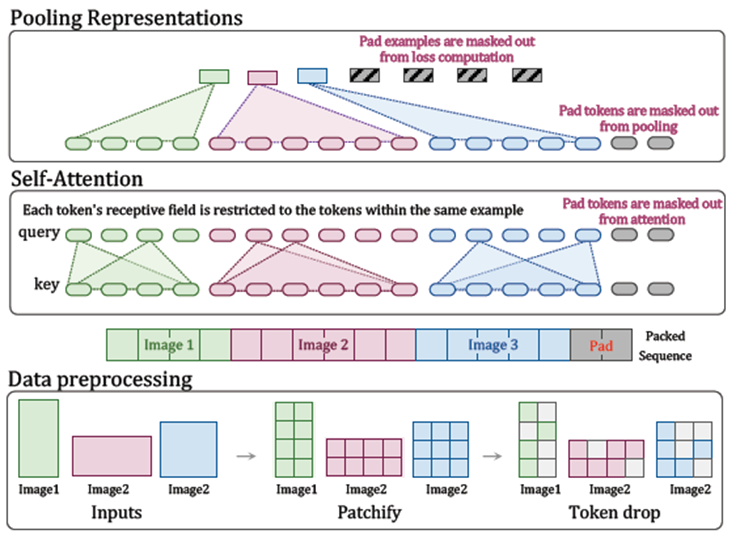
圖10 NaViT數據處理和打包方法
3.2.DALL.E3:視頻字幕生成re-caption
DALL·E3是一款最新的文本到圖像生成模型,旨在根據用戶提供的文本描述生成相應的圖像。通過DALL.E3的re-caption方法,在高度描述性的字幕模型,使用這個模型可以顯著提高給視頻生成標題的能力。具體實現過程是使用GPT把用戶的提示轉換成詳盡說明,再把這些說明送給上述字幕模型,可以生成高質量的視頻。

圖11 使用DALL-E 3生成的肖像和正方形樣本
3.3.SDEdit:對視頻的編輯與合成
SDEdit提出了一種新的圖像合成框架,該框架結合了隨機微分方程和引導擴散技術,實現了高質量的圖像生成和編輯。SDEdit通過在潛在空間中定義一個隨機微分方程來模擬圖像的生成過程,可以被用來生成新的圖像或者對現有圖像進行編輯。它使用了一種稱為“引導擴散”的技術,通過在SDE的漂移項中引入文本描述或圖像編輯指令,來控制生成圖像的內容和風格。這種方法允許在保持圖像質量的同時,實現對圖像內容的精確控制。
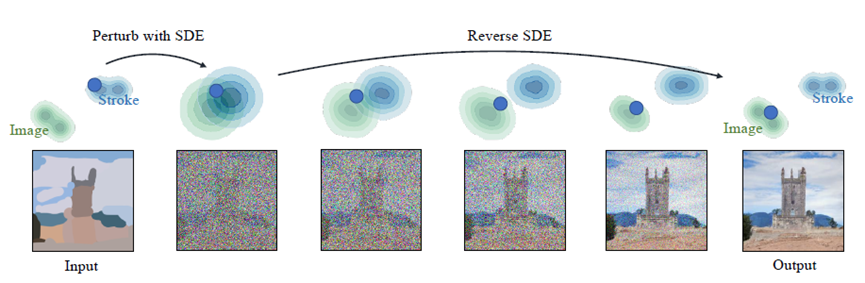
圖12 SDEdit 從筆畫合成圖像
Sora是文本生成視頻領域一個里程碑式的技術,它的很多潛在信息和用途還有待挖掘,有人評價它是圖像視覺領域的“GPT3時刻”,也有人說它是“物理世界模擬器”。OpenAI的Sora項目的成功,首先需依托海量的視頻數據和強大的算力(這一點在報告中未做太多的披露),同時Sora博取眾家之長,率先將擴散模型、transformer、隱式時空塊三者結合應用于視頻生成領域,并在此基礎上依托自身積累的GPT4、DALL.E等領先技術的加持,大膽創新,才有了呈現在世人面前的這份驚艷的報告。
期待在Sora之后,有更多的圖像或視頻領域革命性技術的涌現,推動多模態大模型向前發展,AGI加速、盡早到來。
附、Sora報告地址、論文列表和主要術語
原文地址
https://openai.com/research/video-generation-models-as-world-simulators
論文列表
視頻數據的廣義模型
1.Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhudinov. "Unsupervised learning of video representations using lstms." International conference on machine learning. PMLR, 2015.
2.Chiappa, Silvia, et al. "Recurrent environment simulators." arXiv preprint arXiv:1704.02254 (2017).
3.Ha, David, and Jürgen Schmidhuber. "World models." arXiv preprint arXiv:1803.10122 (2018).
4.Vondrick, Carl, Hamed Pirsiavash, and Antonio Torralba. "Generating videos with scene dynamics." Advances in neural information processing systems 29 (2016).
5.Tulyakov, Sergey, et al. "Mocogan: Decomposing motion and content for video generation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
6.Clark, Aidan, Jeff Donahue, and Karen Simonyan. "Adversarial video generation on complex datasets." arXiv preprint arXiv:1907.06571 (2019).
7.Brooks, Tim, et al. "Generating long videos of dynamic scenes." Advances in Neural Information Processing Systems 35 (2022): 31769-31781.
8.Yan, Wilson, et al. "Videogpt: Video generation using vq-vae and transformers." arXiv preprint arXiv:2104.10157 (2021).
9.Wu, Chenfei, et al. "Nüwa: Visual synthesis pre-training for neural visual world creation." European conference on computer vision. Cham: Springer Nature Switzerland, 2022.
10.Ho, Jonathan, et al. "Imagen video: High definition video generation with diffusion models." arXiv preprint arXiv:2210.02303 (2022).
11.Blattmann, Andreas, et al. "Align your latents: High-resolution video synthesis with latent diffusion models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
12.Gupta, Agrim, et al. "Photorealistic video generation with diffusion models." arXiv preprint arXiv:2312.06662 (2023).
transformer視覺模型架構
13.transformers:Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
14.GPT3:Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
15.ViT:Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
16.ViViT:Arnab, Anurag, et al. "Vivit: A video vision transformer." Proceedings of the IEEE/CVF international conference on computer vision. 2021.
17.He, Kaiming, et al. "Masked autoencoders are scalable vision learners." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
18.NaViT:Dehghani, Mostafa, et al. "Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution." arXiv preprint arXiv:2307.06304 (2023).
19.LDM:Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
20.Kingma, Diederik P., and Max Welling. "Auto-encoding variational bayes." arXiv preprint arXiv:1312.6114 (2013).
視頻生成的擴展transformer
21.Sohl-Dickstein, Jascha, et al. "Deep unsupervised learning using nonequilibrium thermodynamics." International conference on machine learning. PMLR, 2015.
22.DDPM:Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in neural information processing systems 33 (2020): 6840-6851.
23.Nichol, Alexander Quinn, and Prafulla Dhariwal. "Improved denoising diffusion probabilistic models." International Conference on Machine Learning. PMLR, 2021.
24.Dhariwal, Prafulla, and Alexander Quinn Nichol. "Diffusion Models Beat GANs on Image Synthesis." Advances in Neural Information Processing Systems. 2021.
25.Karras, Tero, et al. "Elucidating the design space of diffusion-based generative models." Advances in Neural Information Processing Systems 35 (2022): 26565-26577.
26.DiT:Peebles, William, and Saining Xie. "Scalable diffusion models with transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
27.Chen, Mark, et al. "Generative pretraining from pixels." International conference on machine learning. PMLR, 2020.
28.Ramesh, Aditya, et al. "Zero-shot text-to-image generation." International Conference on Machine Learning. PMLR, 2021.
29.Yu, Jiahui, et al. "Scaling autoregressive models for content-rich text-to-image generation." arXiv preprint arXiv:2206.10789 2.3 (2022): 5.
圖像和視頻的提示工程方法
30.Betker, James, et al. "Improving image generation with better captions." Computer Science. https://cdn.openai.com/papers/dall-e-3. pdf 2.3 (2023): 8
31.Ramesh, Aditya, et al. "Hierarchical text-conditional image generation with clip latents." arXiv preprint arXiv:2204.06125 1.2 (2022): 3.
32.Meng, Chenlin, et al. "Sdedit: Guided image synthesis and editing with stochastic differential equations." arXiv preprint arXiv:2108.01073 (2021).
主要術語
transformer(s): 變壓器架構
Diffusion Model(DM): 擴散模型
Denoising Diffusion Probabilistic Model (DDPM):去噪擴散概率模型
Latent Diffusion Model(LDM):潛在擴散模型
Stable Diffusion Model(SD):穩定擴散模型
Variational Autoencoder(VAE):變分自編碼器
Vision Transformer (ViT)
Diffusion Transformer(DiT)
Video Vision Transformer(ViViT)
Spacetime Latent Patches:隱式時空塊
Native Resolution ViT(NaViT):原生分辨率的視覺變壓器






![[筆記] wsl 禁用配置 win系統環境變量+代理](http://pic.xiahunao.cn/[筆記] wsl 禁用配置 win系統環境變量+代理)
)


)




)



