貝葉斯優化CNN分類matlab代碼
數據為Excel分類數據集數據。
數據集劃分為訓練集、驗證集、測試集,比例為8:1:1
數據處理: 在數據加載后,對數據進行了劃分,包括訓練集、驗證集和測試集,這有助于評估模型的泛化能力。
數據標準化: 對數據進行了 Zscore 標準化處理,有利于提高模型的收斂速度和性能。
參數設置:代碼中設置了貝葉斯迭代次數 BO_iter,通過調整這個參數,可以控制貝葉斯優化算法的迭代次數,從而更好地優化模型的超參數。
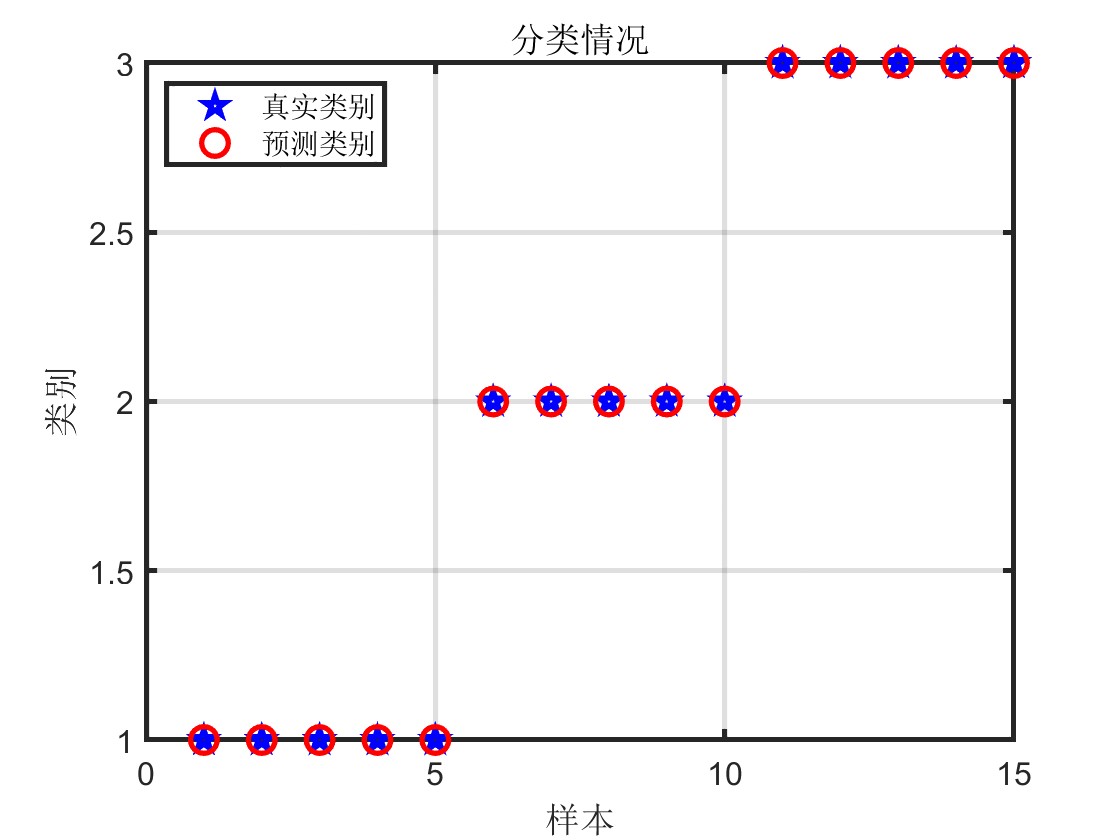
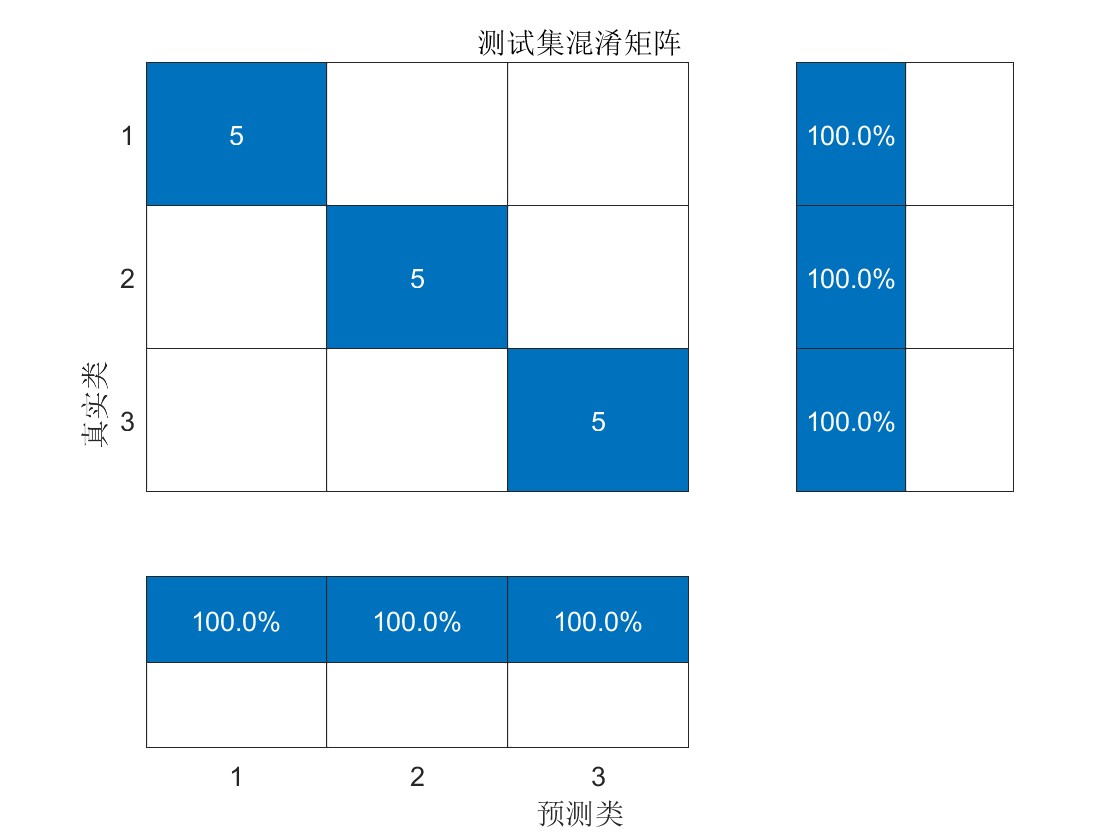
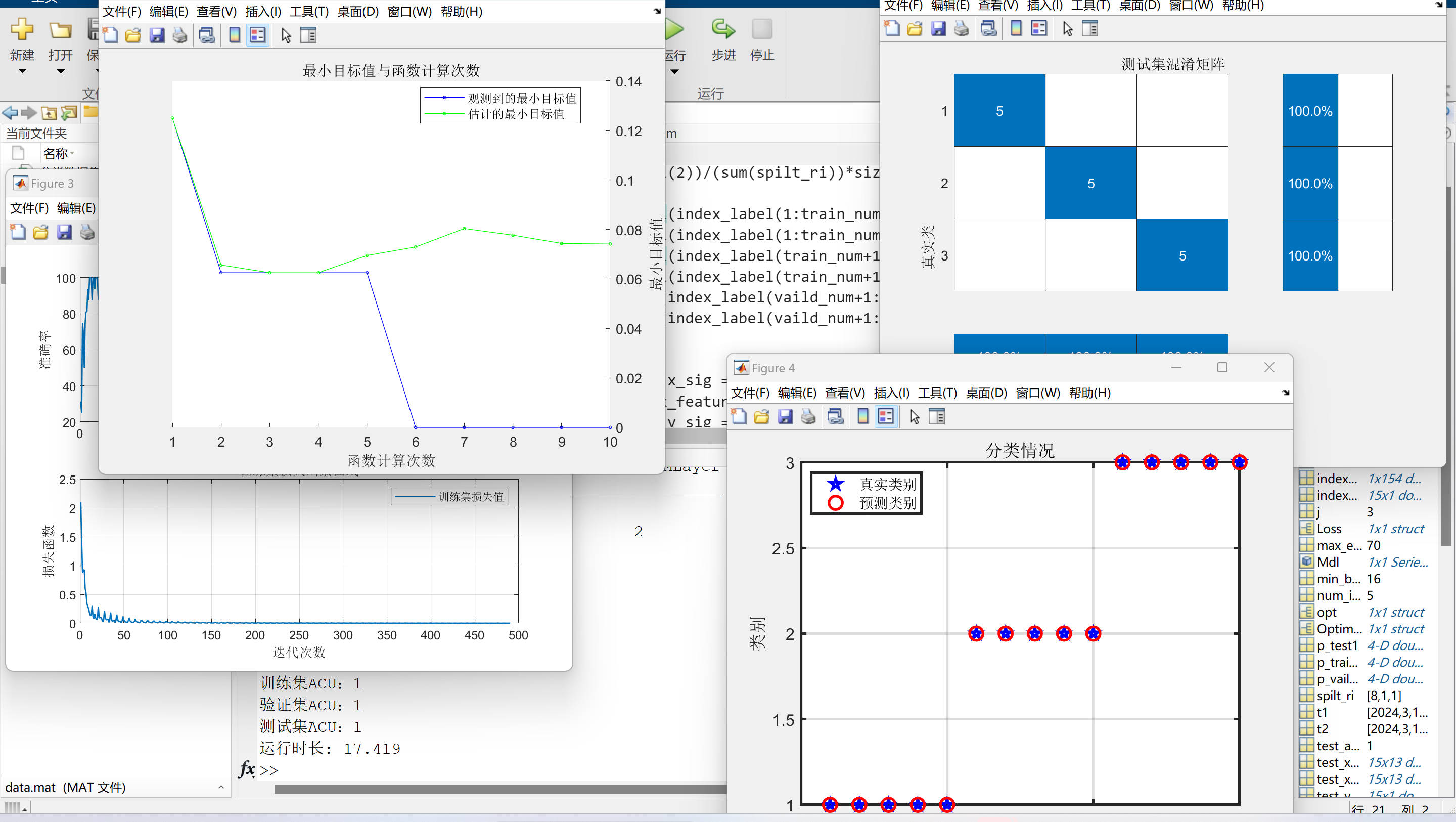
可視化結果: 代碼中包含了對訓練過程和預測結果的可視化,包括損失函數的曲線、真實標簽與預測標簽的對比等,有助于直觀地評估模型的性能和結果的準確性。
輸出的定量結果如下:
訓練集正確率:1
驗證集正確率:1
測試集正確率:1
運行時長:17.419
代碼能正常運行時不負責答疑!
代碼有詳細中文介紹。
代碼運行結果如下:



部分代碼如下:
% 清除命令窗口、工作區數據、圖形窗口、警告
clc;
clear;
close all;
warning off;
load('data') data1=readtable('分類數據集.xlsx'); %讀取數據
data2=data1(:,2:end);
data=table2array(data1(:,2:end));
data_biao=data2.Properties.VariableNames; %數據特征的名稱
A_data1=data; data_select=A_data1;
feature_need_last=1:size(A_data1,2)-1; %% 數據劃分 x_feature_label=data_select(:,1:end-1); %x特征 y_feature_label=data_select(:,end); %y標簽 index_label1=randperm(size(x_feature_label,1)); index_label=G_out_data.spilt_label_data; % 數據索引 if isempty(index_label) index_label=index_label1; end
spilt_ri=G_out_data.spilt_rio; %劃分比例 訓練集:驗證集:測試集
train_num=round(spilt_ri(1)/(sum(spilt_ri))*size(x_feature_label,1)); %訓練集個數
vaild_num=round((spilt_ri(1)+spilt_ri(2))/(sum(spilt_ri))*size(x_feature_label,1)); %驗證集個數
%訓練集,驗證集,測試集
train_x_feature_label=x_feature_label(index_label(1:train_num),:);
train_y_feature_label=y_feature_label(index_label(1:train_num),:);
vaild_x_feature_label=x_feature_label(index_label(train_num+1:vaild_num),:);
vaild_y_feature_label=y_feature_label(index_label(train_num+1:vaild_num),:);
test_x_feature_label=x_feature_label(index_label(vaild_num+1:end),:);
test_y_feature_label=y_feature_label(index_label(vaild_num+1:end),:); )
--樹形DP沒有上司的舞會)


)





)







![多線程 --- [ 線程池、線程安全、其他常見的鎖 ]](http://pic.xiahunao.cn/多線程 --- [ 線程池、線程安全、其他常見的鎖 ])
