談談高并發系統的設計方法論
- 何為高并發系統?
- 什么是并發(Conurrent)?
- 什么是高并發(Hight Concurrnet)?
- 高并發的衡量指標有哪些?
- 實現高并發系統的兩大板塊
- 高并發系統應用程序側的設計方法論
- 1. 分而治之,橫向擴展
- 2. ‘大’ 系統 ‘小’ 做(微服務拆分)
- 3. 分庫分表(分擔數據讀寫壓力)
- 4. 池化技術(資源復用)
- 5. DB 主從架構(數據讀寫分離)
- 6. 使用緩存(系統性能提升立竿見影)
- 7. 動靜分離,靜態資源壓縮 & CDN 加速靜態資源訪問
- 8. 消息異步通信(MQ 流量削鋒)
- 9. ElasticSearch(分擔數據庫查詢)
- 10. 降級熔斷(避免內部服務不可用造成的雪崩效應)
- 11. 限流(預防接口服務請求過載打垮系統)
- 12. 異步(提升系統吞吐量)
- 13. 常規性的優化(提升單個模塊服務性能)
- 14. 系統性壓力測試(查找性能瓶頸)
- 15. 部署模式集群橫向擴容 & 流量切換(應對突發大流量峰值)
- 總結
何為高并發系統?
在理解高并發系統之前,我們先來理解幾個相關概念。
什么是并發(Conurrent)?
在操作系統中,是指一個時間段中有幾個程序都處于已啟動運行到運行完畢之間,且這幾個程序都是在同一個宿主機上運行,但任一個時刻點上只有一個程序在宿主機上運行。
什么是高并發(Hight Concurrnet)?
從字面上來理解就是讓 單位時間同時處理任務的能力盡可能的高。對應到我們研發系統中,也就是說:我們所開發的系統,要在 短時間能能支持大量訪問請求的情況。這種情況比如:雙十一或者 12306 的搶票、以及秒殺等活動。
這要求我們的業務系統,在短時間內,盡可能多的接收來自客戶端的請求,并做出準確的響應。
高并發的衡量指標有哪些?
響應時間:系統對請求做出響應的時間,既然是高并發系統,這個響應時間就不可能太長,需要盡可能的短。吞吐量:系統單位時間內支持的最大請求數,當然越多越好。QPS/TPS是吞吐量最常用的量化指標之一。并發數:系統同時承載的正常使用功能的用戶數量。如通信系統的同時在線人數。反應了系統的負載能力。這個指標當然越大越好。
=》 QPS(TPS) = 并發數/平均響應時間
此外還有些相關的指標也需要了解:
PV(Page View):頁面訪問量,即頁面瀏覽量或點擊量。UV(Unique Visitor):獨立訪客,統計一天內訪問某站點的用戶數。即按人按天去重。DAU(Daily Active User):日活躍用戶數量。通常統計一日(統計日)之內,登錄或使用了某個產品的用戶數,與UV概念相似。MAU(Month Active User):月活躍用戶數量,指網站、app等去重后的月活躍用戶數量。
上述指標內容,主要是反映了高并發系統在 高性能 上的要求。做為 高并發系統,需要實現的目標為:
高性能:這體現了系統的并行處理能力,在有限資源的情況下,提升性能能節省成本。同時也給用戶帶來了更好的用戶體驗。高可用性:系統可以正常服務的時間,盡量避免系統的事故和宕機從而影響正常的業務。高擴展性:表示系統的擴展能力,系統具備更好的彈性,在流量高峰期能否短時間完成擴容,更平穩的承接流量峰值。
所謂設計 高并發 系統,就是設計一個系統,保證它 整體可用的同時,能夠 處理很高的并發用戶請求,能夠 承受很大的負載流量沖擊。
實現高并發系統的兩大板塊
我們要設計高并發的系統,那就需要處理好一些常見的系統瓶頸問題:

硬件資源側:如內存(空間或主頻)不足、磁盤(I/O性能或空間)不足,連接數不夠,網絡寬帶不夠等等。應用程序側:如語言框架性能,代碼規范化,高可用性和高可擴展性的架構設計等等(后面細說,也是本篇文章盡可能闡述的方向)。
此外還有一些考慮因素,硬件資源與 OS 系統的默契配合,選擇一款高性能的 OS 搭配合適(最佳實踐)的硬件資源,為應用程序鋪平部署底座,如魚得水。
因此設計高性能系統需要需要考慮綜上這些因素(“三高”:高性能,高可用性和高可擴展性),以應對突發的流量洪峰。
高并發系統應用程序側的設計方法論
1. 分而治之,橫向擴展
如果你只部署一個應用,只部署一臺服務器,那抗住的流量請求是非常有限的(畢竟硬件資源的能力提供有限)。并且,單體的應用,有單點的風險,如果它掛了,那服務就不可用了。
因此,設計一個高并發系統,我們可以分而治之,橫向擴展。也就是說,把原來 集中式的部署 調整采用 分布式部署 的方式,部署多臺服務器,把流量分流開,讓每個服務器都承擔一部分的并發和流量,提升整體系統的并發能力。
2. ‘大’ 系統 ‘小’ 做(微服務拆分)
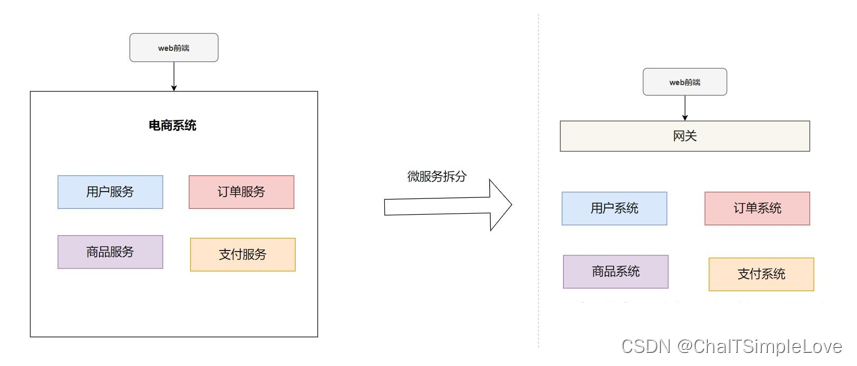
要提高系統的吞吐,提高系統的處理并發請求的能力。除了采用分布式部署的方式外,還可以把大單體項目做模塊化的微服務拆分,這樣就可以達到分攤請求流量的目的,提高了并發能力。
所謂的 微服務拆分,其實就是把一個單體的應用,按功能單一性,拆分為多個服務模塊。比如一個電商系統,拆分為用戶系統、訂單系統、商品系統、支付系統等等。
3. 分庫分表(分擔數據讀寫壓力)
當業務量暴增的話,DB 單機磁盤容量會撐爆。并且數據庫連接數是有限的。在高并發的場景下,大量請求訪問數據庫,DB 單機是扛不住的!高并發場景下,會出現異常報錯。
所以高并發的系統,需要考慮拆分為多個數據庫,來抗住高并發的 “毒打”。假如你的單表數據量非常大,存儲和查詢的性能就會遇到瓶頸了,如果你做了很多優化之后還是無法提升效率的時候,就需要考慮做分表了。一般千萬級別數據量,就需要分表,每個表的數據量少一點,提升 SQL 查詢性能。
4. 池化技術(資源復用)
在高并發的場景下,數據庫連接數可能成為瓶頸,因為連接數是有限的。
我們的請求調用數據庫時,都會先獲取數據庫的連接,然后依靠這個連接來查詢數據,搞完收工,最后關閉連接,釋放資源。如果我們不用數據庫連接池的話,每次執行 SQL,都要創建連接和銷毀連接,這就會導致每個查詢請求都變得更慢了,相應的,系統處理用戶請求的能力就降低了。
比如:PosgtreSQL 就推薦使用連接池,目前很多第三方 SDK 都集成了數據庫連接池。
因此,需要 使用池化技術,即:數據庫連接池、HTTP 連接池、Redis 連接池 等等。使用數據庫連接池,可以避免每次查詢都新建連接,減少不必要的資源開銷,通過復用連接池,提高系統處理高并發請求的能力。
同理,我們 使用線程池,也能讓任務并行處理,更高效地完成任務。
5. DB 主從架構(數據讀寫分離)
通常來說,一臺單機的 DB 服務器支撐的請求訪問(TPS/QPS)是有限的。因此你做了分布式部署,部署了多臺機器,部署了主數據庫、從數據庫。
但是,如果雙十一搞活動,流量肯定會猛增的。如果所有的查詢請求,都走主庫的話,主庫肯定扛不住,因為查詢請求量是非常非常大的。因此一般都要求做主從分離,然后實時性要求不高的讀請求,都去讀從庫,寫的請求或者實時性要求高的請求,才走主庫。這樣就很好保護了主庫,也提高了系統的吞吐。
上面談到的是關于傳統關系型數據庫(RDBMS)的主從架構,除了使用 關系型數據庫,我們還可以使用 分布式數據庫,而國產分布式數據庫(TDSQL,GaussDB,OceanBase,PolarDB 等)在國內外市場都有著巨大的潛力和市場需求。 隨著大數據和云計算技術的普及,國產分布式數據庫將成為未來數據存儲和處理的核心技術。
6. 使用緩存(系統性能提升立竿見影)
無論是操作系統,瀏覽器,還是一些復雜的中間件,你都可以看到緩存的影子。我們使用緩存,主要是提升系統接口的性能,這樣高并發場景,你的系統就可以支持更多的用戶同時訪問。
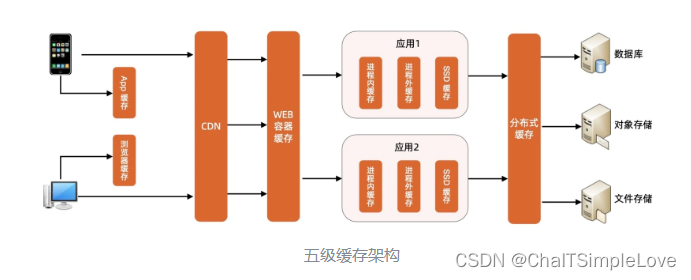
常用的緩存包括:分布式緩存(Redis/Memcached),localhost 本地緩存(App 緩存、HTTP 緩存),應用緩存(前端進程緩存,后端進程緩存),數據庫緩存,反向代理緩存,Web 服務器緩存,瀏覽器緩存,CDN 緩存等等。就拿 Redis 來說,它單機就能輕輕松松應對幾萬的并發,特別是針對讀取數據多(查詢)場景的業務,可以用 緩存 來抗住高并發。通常情況下大多數的業務系統,都遵循 ”二八定律“,讀多(80%)寫入(20%)。
在高并發系統的全鏈路設計環節,都可以依據情況設計 多級緩存 功能,提升系統性能顯著。下面是一個 五級緩存 設計例子:
緩存雖然可以立即提升系統性能,但是也要注意使用緩存的一些潛在問題:
數據一致性
即緩存數據與數據庫的數據是否一致性問題;
緩存雪崩
當某一個時刻出現大規模的緩存失效的情況,那么就會導致大量的請求直接打在數據庫上面,導致數據庫壓力巨大,如果在高并發的情況下,可能瞬間就會導致數據庫宕機。這時候如果運維馬上又重啟數據庫,馬上又會有新的流量把數據庫打死,這種現象就叫做緩存雪崩。
緩存擊穿
其實跟緩存雪崩有點類似,緩存雪崩是大規模的 key 失效,而緩存擊穿是一個熱點的 key ,有大并發集中對其進行訪問,突然間這個 key 失效了,導致大并發全部打在數據庫上,導致數據庫壓力劇增,這種現象就叫做緩存擊穿。
緩存穿透
我們使用 Redis 大部分情況都是通過 key 查詢對應的值,假如發送的請求傳進來的 key 是不存在 Redis 中的,那么就查不到緩存,查不到緩存就會去數據庫查詢。假如有大量這樣的請求,這些請求像 “穿透” 了緩存一樣直接打在數據庫上,這種現象就叫做緩存穿透。
相關文章推薦:
- 《什么是緩存雪崩、緩存擊穿、緩存穿透?》https://zhuanlan.zhihu.com/p/346651831
- 《使用 Redis,你必須知道的 21 個注意要點》https://mp.weixin.qq.com/s?__biz=MzkyMzU5Mzk1NQ==&mid=2247506058&idx=1&sn=b5d0f0eb59c348b86c38f69b8308a512&source=41#wechat_redirect
7. 動靜分離,靜態資源壓縮 & CDN 加速靜態資源訪問
商品圖片(*.jpg,*.jpeg,*.png,*.gif,*.webp,*.svg),icon,wwwroot(部分 html + css + js) 等等靜態資源,可以對 頁面做靜態化處理,減少訪問服務端的請求。如果用戶分布在全國各地,有的在上海,有的在深圳,地域相差很遠,網速也各不相同。為了讓用戶最快訪問到頁面,可以使用 CDN。CDN 可以讓用戶就近獲取所需內容。
- 什么是 CDN?
Content Delivery Network/Content Distribution Network,翻譯過來就是內容分發網絡,它表示將靜態資源分發到位于多個地理位置機房的服務器,可以做到數據就近訪問,加速了靜態資源的訪問速度,因此讓系統更好處理正常別的動態請求。
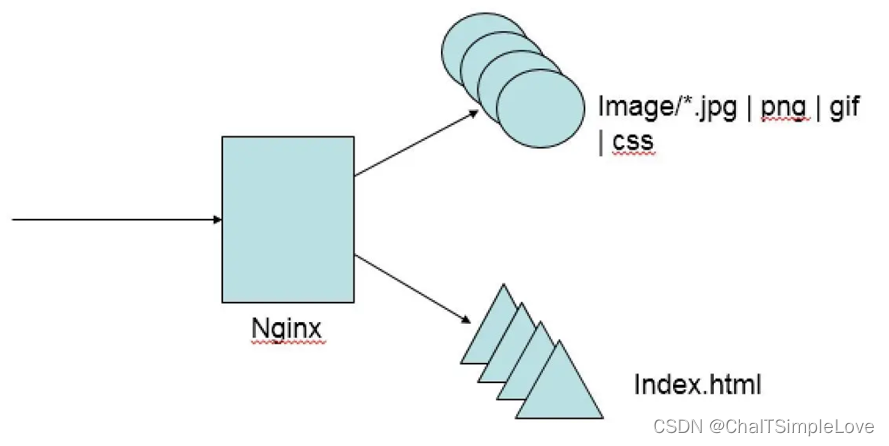
- 什么是 Web “動靜分離” ?
所謂 “動靜分離” 就是通過 nginx(或 apache 等)來處理用戶端請求的靜態頁面,iis/kestrel/apache/tomcat/weblogic 處理動態頁面,從而達到動靜頁面訪問時通過不同的容器來處理。
- 靜態資源壓縮
在宿主資源(CPU)充分的情況下,我們還可以靜態資源壓縮,通常的做法例如:nginx 開啟 gzip 壓縮,將 js、css 等文件,生成對應的 .gz 文件。訪問靜態資源文件越小,耗時越短,速度越快,帶寬損耗越小。
- 減少 http 請求數量
另外在每次 http 請求的繁瑣過程(交換機查找的過程,DNS 解析的過程)是十分耗時的,所以 減少 http 請求數量 也可以減少耗時,從而提升用戶體驗,達到性能優化的目的。
8. 消息異步通信(MQ 流量削鋒)
比如某電商公司搞雙十一、雙十二等運營活動時,需要 避免流量暴漲,打垮應用系統的風險。因此一般會引入 消息隊列,來應對高并發的場景。

假設你的應用系統每秒最多可以處理 2k 個請求,每秒卻有 5k 的請求過來,可以引入消息隊列,應用系統每秒從消息隊列拉 2k 請求處理,在瞬時峰值下保障了服務能夠平滑的延緩處理消息。
常用的 MQ 中間件產品有:ActiveMQ、RocketMQ、RabbitMQ、Kafka、Apache Pulsar,對于 中小型 Web 消息處理個人比較推薦使用 RabbitMQ,大型 Web 海量數據消息處理推薦使用 Apache Pulsar。
9. ElasticSearch(分擔數據庫查詢)
ElasticSearch,簡稱 ES,是一個分布式的搜索和分析引擎,以其強大的擴展能力和高并發處理能力而著稱。由于其分布式特性,ES 可以輕松地通過增加節點來擴展性能和容量,從而自然有效地支撐高并發場景。這使得 ES 成為承載簡單查詢、統計操作以及全文搜索等任務的理想選擇,一般搜索功能都會用到它。當然還可以使用 ES 存儲日志信息等。因為 ES 可以擴容方便,天然支撐高并發。當數據量大的時候,不用動不動就加機器擴容,分庫等等。
10. 降級熔斷(避免內部服務不可用造成的雪崩效應)
熔斷降級 是保護系統的一種手段。俗話說得好 “一粒老鼠屎壞了一鍋湯”,而 熔斷降級 策略就是為了避免高并發系統中偶爾產生的這 “一粒老鼠屎” 設計的手段。
當前互聯網系統一般都是 分布式部署 的。而分布式系統中偶爾會出現某個基礎 服務不可用,最終會演變為導致 整個系統不可用 的情況,這種現象被稱為 服務雪崩效應。
在分布式系統中,某一個服務的調用鏈路 ”A -> B -> C ...“ 如下圖所示:
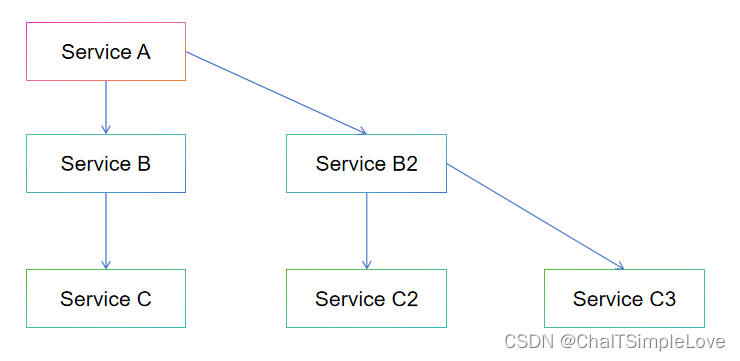
如果 服務 C 出現問題,比如是因為 慢 SQL 導致調用緩慢,那將導致 服務 B 也會延遲,從而 服務 A 也會延遲。堵住的 A 請求會消耗占用系統的線程、I/O、CPU、內存等資源。當請求 A 的服務越來越多,占用計算機的資源也越來越多,最終因為該條服務調用鏈阻塞會導致系統瓶頸出現,造成其他的請求同樣不可用,最后導致整個業務系統崩潰。
為了有效避免 服務雪崩效應,常見的做法是 熔斷和降級。最簡單是加閾值開關控制,當下游系統出問題時,開關自動打開降級,不再調用下游系統。針對 .NET 技術棧小伙伴們可以使用開源組件 Ocelot 網關來實現此功效。
11. 限流(預防接口服務請求過載打垮系統)
針對我們單個宿主機的資源(系統的 CPU、網絡帶寬、內存、線程等)提供的能力是有限的。在高并發大流量過來時,我們的預期都希望系統能對所有請求都正常處理,但是有時候沒辦法,因為宿主機資源的上限,對應環境部署的服務也受到一定的限制。
如果我們設計的系統服務每秒可以抗住 2k 的請求,就算該服務有多個副本存活并且做了負載均衡策略等,在突然的流量高峰負載(比如:10w 甚至更多)請求過來時,分攤到每個副本上面的數據量瞬時內承擔的量也會很大,有可能就剛好超過了單副本處理能力的上限 2k。這個時候如果我們不提前做出針對性的預防措施,放任大量的流量負載請求到服務接口上,同樣會造成 系統性能急劇下降,最終導致整個 系統崩潰。
這個時候,為了 有效的保護系統請求過載,我們可以采取 限流 的方案,負載超過請求閾值,多余的請求直接舍棄。
在高并發系統設計中,限流 & 降級熔斷 策略是保證 系統高可用性 必不可少的手段。
- 什么是限流?
在計算機網絡中,限流就是控制網絡接口發送或接收請求的速率,它可防止 DoS 攻擊 和 限制 Web 爬蟲 。限流,也稱流量控制。是指系統在面臨高并發或者大流量請求的情況下,限制新的請求對系統的訪問,從而保證系統的穩定性。
.net 技術棧中,常見的限流中間件有 Microsoft.AspNetCore.RateLimiting(單機版限流),也可以使用 Ocelot 網關或 Redis 分布式限流等。
- 關于《
ASP.NET Core中的速率限制中間件》請查看,https://learn.microsoft.com/zh-cn/aspnet/core/performance/rate-limit?view=aspnetcore-8.0
12. 異步(提升系統吞吐量)
我們在設計接口服務的時候,針對耗時的操作,盡量異步化處理,比如:http 網絡請求,文件 I/O 操作,數據庫訪問操作等。
- 同步和異步如何區分?
以方法的調用為例,它代表 調用方要阻塞等待被調用方法中的邏輯執行完成。這種方式下,當被調用方法響應時間較長時,會造成調用方長久的阻塞,在 高并發下會造成整體系統性能下降甚至發生雪崩。異步 調用恰恰相反,調用方不需要等待方法邏輯執行完成 就可以返回執行其他的邏輯,在被調用方法執行完畢后再通過回調、事件通知等方式將結果反饋給調用方。
在高并發系統的設計中,在需要的場景中合理恰當的使用異步處理是必不可少的環節。那么我們如何使用異步呢?.NET 后端接口設計可以使用 async/await & Task 實現更徹底的異步操作,或者借用第三方組件 MQ 消息隊列 實現。比如在海量秒殺請求過來時,先放到消息隊列中,快速相應用戶,告訴用戶請求正在處理中,這樣就可以釋放資源來處理更多的請求。秒殺請求處理完后,通知用戶秒殺搶購成功或者失敗。
13. 常規性的優化(提升單個模塊服務性能)
當 "單兵" 作戰能力上去了,"打群架" 還需擔心么?
針對 "單兵" (單服務)作戰能力(接口性能)的優化,通常的手段有:數據接口整合批量操作,慢 sql 優化,數據表建立索引,異步線程阻塞(異步不夠徹底),數據結構/集合類型合理使用,數據多線程并行處理,大表多字段查詢 等等。
14. 系統性壓力測試(查找性能瓶頸)
當我們設計高性能系統時,該處理的手段都處理了,最后是騾子是馬,總得拉出來溜溜,這也是預估系統整體性承受上限的有效手段,在高性能系統設計中也是不可或缺的重要一環,這就是系統性的壓力測試。
就是在系統上線前,需要對系統進行壓力測試,測清楚你的系統支撐的最大并發是多少,確定系統的瓶頸點,讓自己心里有底,做好預防措施。
壓測完要分析整個調用鏈路,性能可能出現問題是網絡層(如帶寬)、Nginx 層、服務層、還是數據路緩存等中間件等等。
通過系統性的壓測,可以獲取到系統一些關鍵性的度量指標,也好對設計的系統性能方面查缺補漏。
15. 部署模式集群橫向擴容 & 流量切換(應對突發大流量峰值)
比如新浪微博,某一天某一時刻突然的熱點話題,遇到突發的大流量高峰,除了上面我們提到的 降級熔斷、限流 保證系統不跨,但并不代表我們設計的系統能吞入更多的請求負載,針對這種情況,我們可以保證系統盡最大量可能的服務用戶,此時對系統設計就要求有集群快速擴容能力和流量分銷切換能力。
- 集群擴容:比如增加從庫、提升配置、添加新節點的方式,提升系統/組件的流量承載能力。比如增加
PostgreSQL、Redis從庫來處理查詢請求。 - 流量分銷和切換:服務多機房部署(同城多活,異地多活),如果高并發流量來了,把流量從一個機房切換到另一個機房。
特別是針對 云原生項目設計原則,可以把服務器托管給云平臺(公有云,私有云,混合云),有能力的公司組織可以自建同城/異地 IDC,應用服務可以容器化部署在 k8s 平臺,讓服務運行底座更加有保障。
總結
需要注意的是,高并發系統的設計和實現遠比上述幾點要復雜得多。在實際業務系統中,需要 根據具體的業務需求和場景來選擇合適的架構和技術。對于復雜的 分布式系統,還需要考慮數據的 一致性、可用性、分布式事務、故障恢復 等問題。
如同老年人的 三高(高血壓,高血脂,高血糖)并發癥問題,需要主治醫師有豐富的知識體系積累和臨床實踐經驗,才能把控患者情況。
同時,對一個有幾十萬行代碼的復雜分布式系統進行高并發架構的設計和實踐是非常具有挑戰性的。這需要對系統有深入的理解和分析,以及對 高并發、分布式、緩存、消息隊列 等相關技術有深厚的積累和實踐經驗。這樣的經驗是非常寶貴的,也是很多公司在招聘高級技術人才時所看重的。
當然設計一個完整的高并發系統,除了上面提到的一些設計方法,比如還有保證系統工程化和可維護性的一些功能,比如:分布式微服務下的 網關中心,配置中心,服務治理(注冊與發現)中心,日志中心(合適的日志系統,為高并發系統提供有力的數據分析),鏈路監控中心,數據備份中心 等等。















占用的錯誤。)
python初中組初賽真題)

)
