提高代碼規范性,基于上一個 baseline 的提高 import pandas as pd
from sklearn. preprocessing import LabelBinarizer
from sklearn. preprocessing import StandardScaler
from sklearn. model_selection import train_test_split
from sklearn. ensemble import RandomForestClassifier
from sklearn. model_selection import GridSearchCV def data_clean ( file_path) : """"數據處理函數parameters:file_path:數據文件路徑""" "data = pd. read_csv( file_path) data. drop( "PassengerId" , axis= 1 , inplace= True ) data. drop( [ "Name" , "Ticket" , "Cabin" ] , axis= 1 , inplace= True ) data[ "Age" ] . fillna( data[ "Age" ] . mean( ) , inplace= True ) data[ "Embarked" ] . fillna( data[ "Embarked" ] . mode[ 0 ] , inplace= True ) data[ "Sex" ] = LabelBinarizer( ) . fit_transform( data[ "Sex" ] ) data = pd. get_dummied( data) data[ "Fare" ] = StandardScaler( ) . fit_transform( data[ "Fare" ] . values. reshape( - 1 , 1 ) ) return ( data)
def data_split ( data) : """"數據劃分函數parameters:data:要劃分的數據""" "x = data. drop( [ "Survived" ] , axis= 1 ) y = data[ "Survived" ] x_train, x_test, y_train, y_test = train_test. split( x, y, test_size= 0.2 ) return ( x_train, x_test, y_train, y_test)
def model_fit ( x, y) : """模型訓練函數parameters:x:特征y:標簽""" Para_grid = [ { "n_estimators" : [ 3 , 10 , 30 ] , "max_features" : [ 2 , 4 , 6 , 8 ] } , { "bootstrap" , [ False ] , "n_estimators" : [ 3 , 10 ] , "max_features" : [ 2 , 4 , 6 ] } ] model = RandomForestClassifier( ) gird_search = GridSearchCV( model, Para_grid, cv= 5 ) grid_search. fit( x, y) return ( grid_search. best_params_, grid_search. best_estimator_) data = data_clean( "data/train.csv" )
x_train, x_test, y_train, y_test = data_split( data)
model_fit( x_train, y_train)
model = RandomForestClassifier( n_estimators= 30 , max_features= 2 , max_depth= 100 )
model. fit( x_train, y_train)
model. score( x_test, y_test)
if __name__ == '__main__' : ABC
模型融合,去 sklearn 看一下就懂 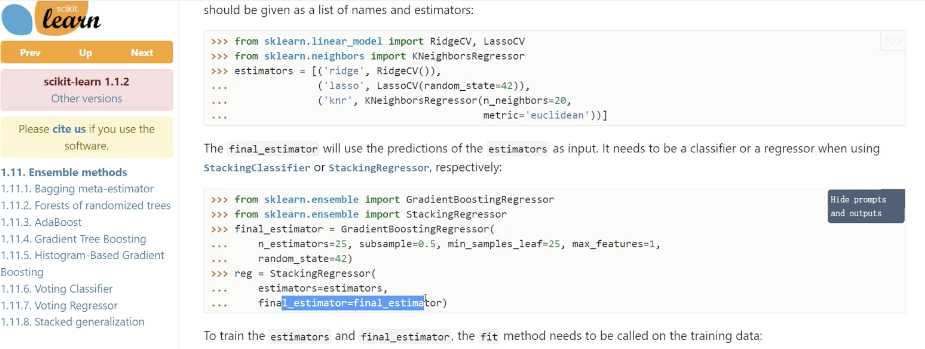





)



)


)


 Practice | 判斷題)


)
