1 目標
目標:
抓取今日頭條美食美圖,如下:
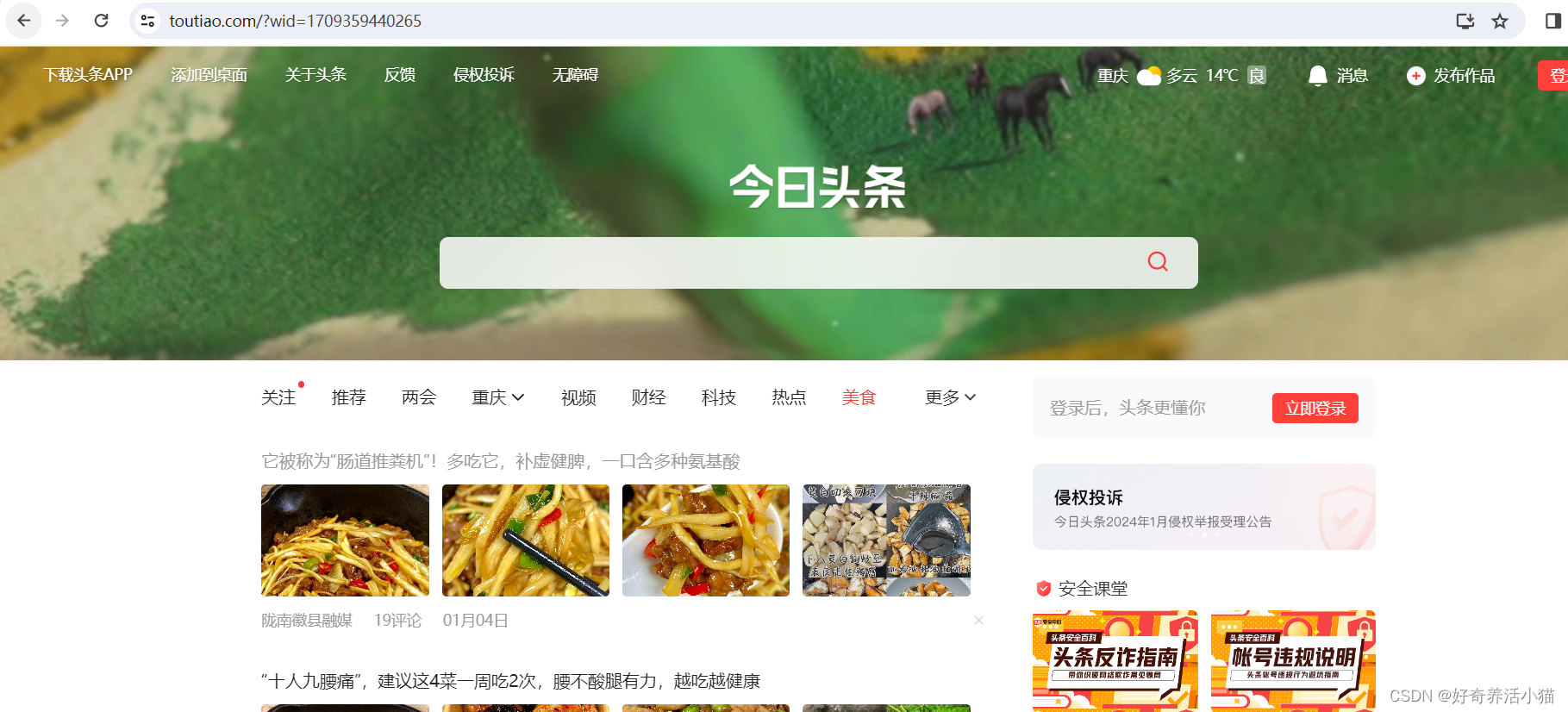
一些網頁直接請求得到的HTML代碼并沒有在網頁中看到的內容,因為一些信息是通過Ajax加載,并通過js渲染生成的,這時就需要通過分析網頁的請求來獲取想要爬取的內容。
直接請求得到的HTML代碼并沒有在網頁中看到的內容:
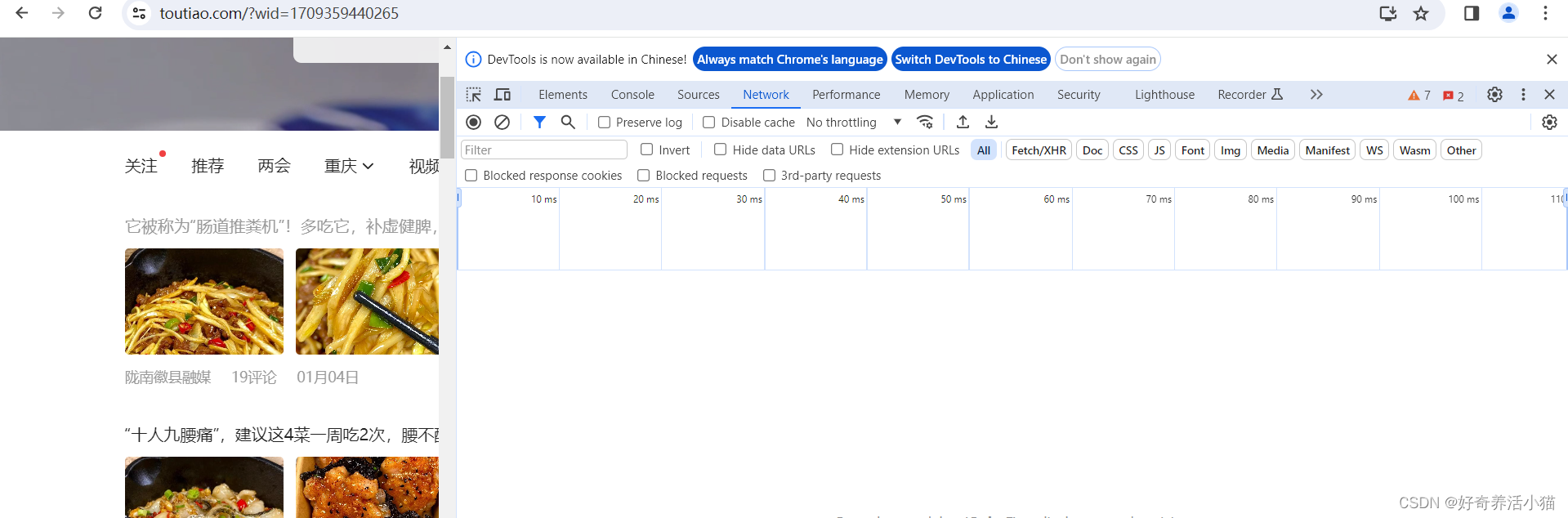
右擊空白處->審查->Network->勾選Preserve log->刷新網頁:
點擊XHR,再選中一個URL,查看請求的方法,發現是用get方法,所以使用requests庫。
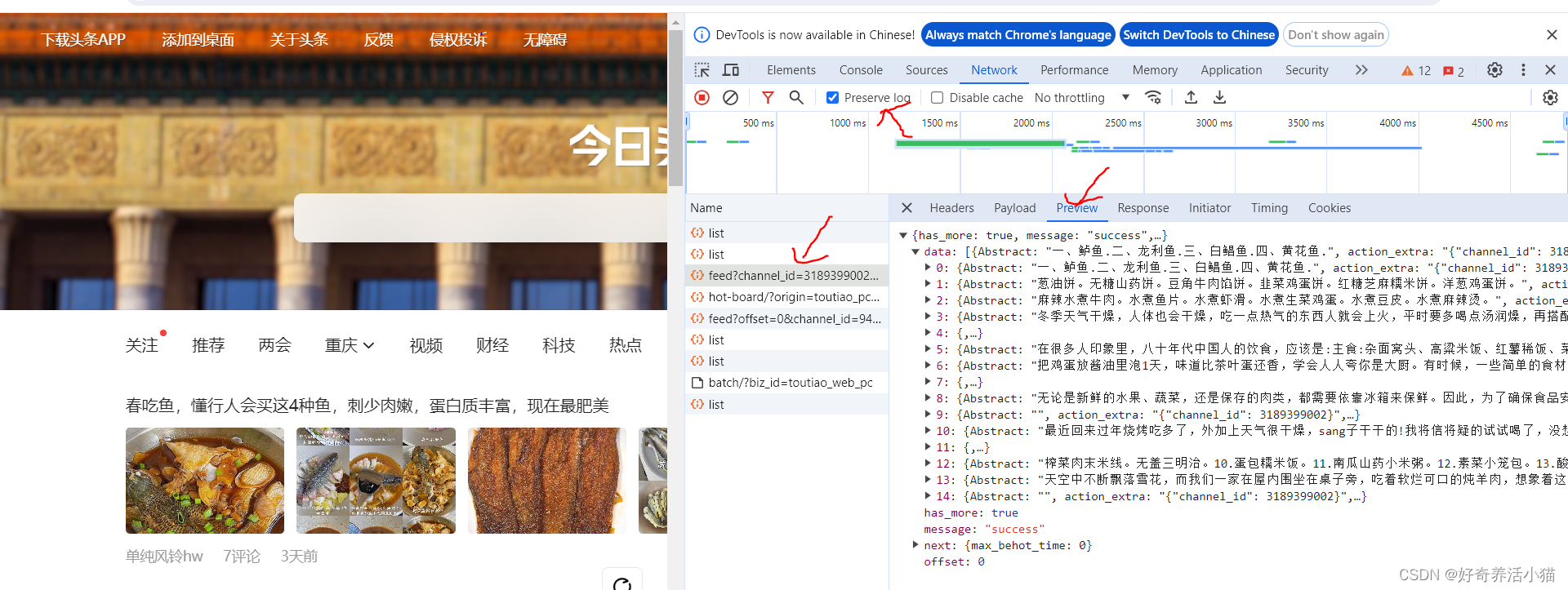
向下更新的過程中,作出url不斷更新:
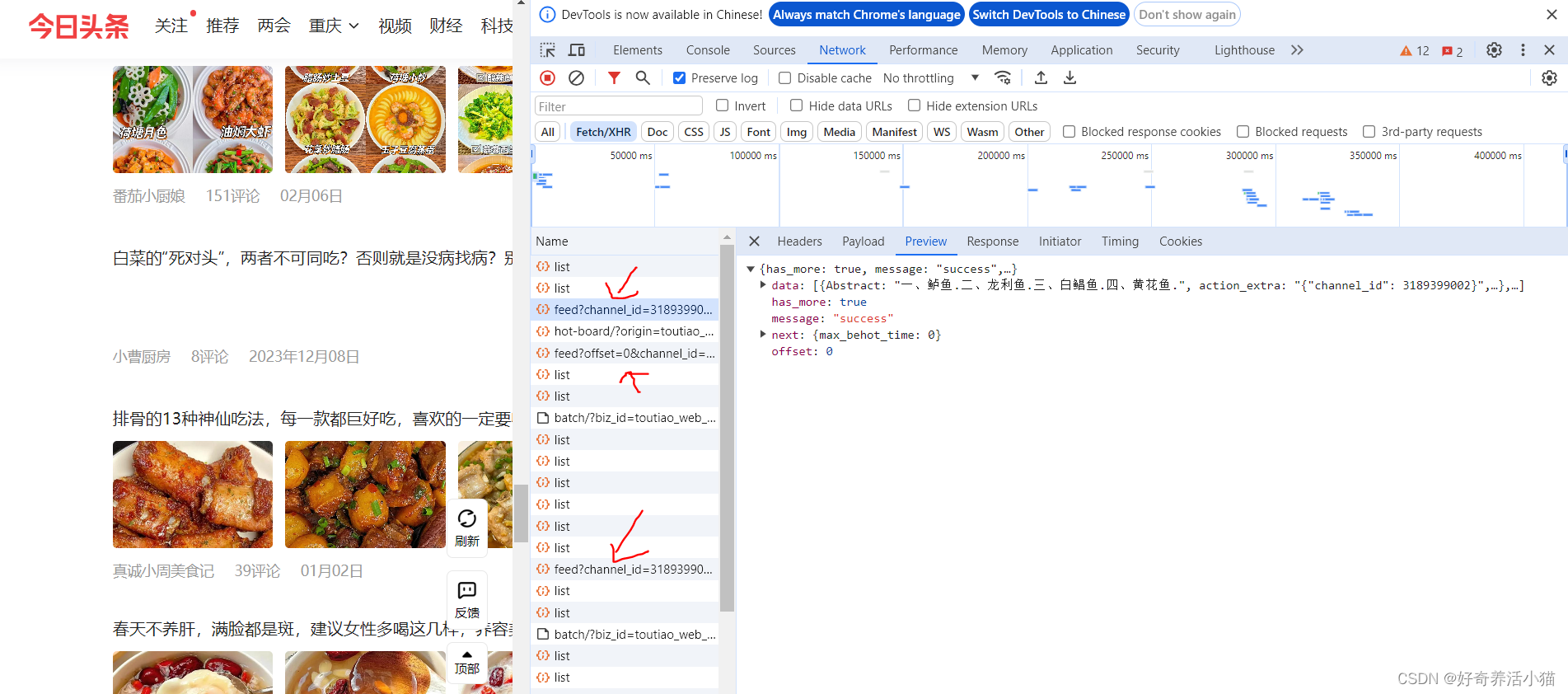
分析查找圖集詳細頁的代碼,來找到圖片的url,這個圖片url隱藏的比較深,都在JS代碼中:
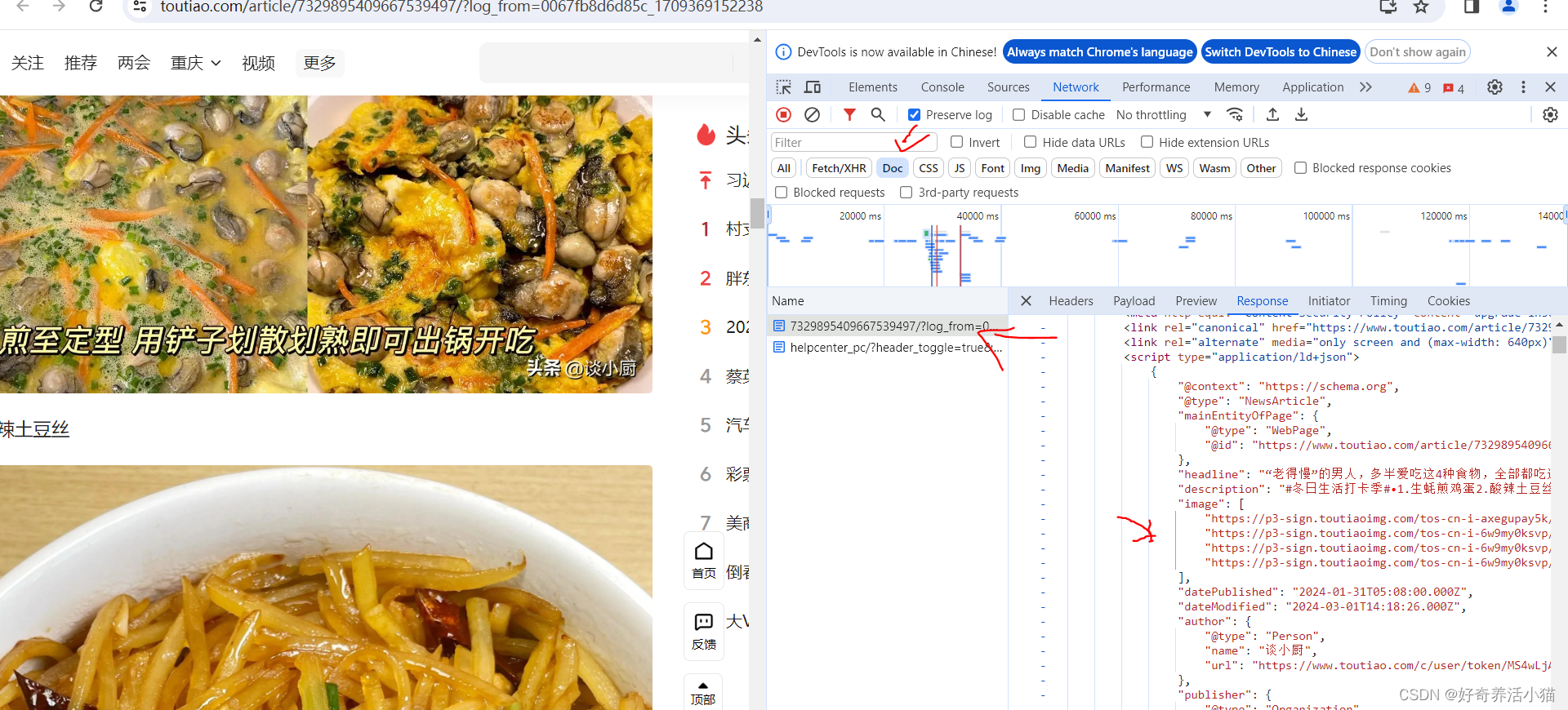
變量并不是在html代碼里的,所以不能使用BeautifulSoup和PyQuery來解析了,只能通過正則表達式來解析。
2 流程框架
- 抓取索引頁內容:利用requests請求目標戰點,得到索引頁面HTML代碼,返回結果。
- 抓取詳情頁內容:解析返回結果,得到詳情頁的鏈接,并進一步抓取詳情頁的信息。
- 下載圖片與保存數據庫:將圖片下載到本地,并把頁面信息及圖片URL保存至MongoDB。
- 開啟循環及多線程:對多頁內容遍歷,開啟多線程提取抓取速度。
3 實戰
1 抓取索引頁內容
看一下索引頁的請求方式:
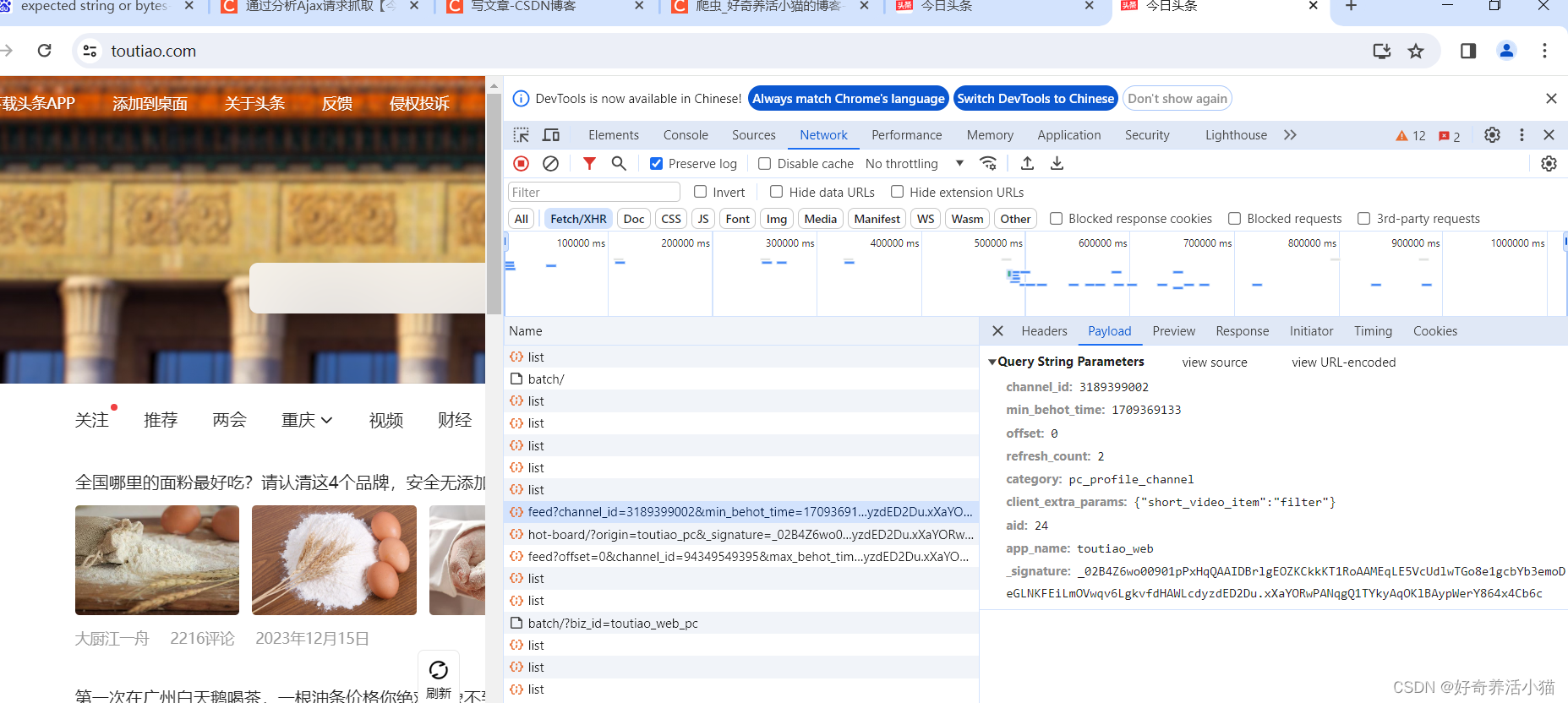
街拍界面更新了方式,了解了Ajax就行,后面寫法同上一章相似,暫時不仔細研究。
舊版形式的詳情。
4 整體代碼
import requests
from urllib.parse import urlencode
from requests.exceptions import RequestException
import json
from bs4 import BeautifulSoup
import re
from config import *
import pymongo
import os
from hashlib import md5
from multiprocessing import Pool
from json.decoder import JSONDecodeError
from pathlib import Pathheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
#聲明mongodb數據庫對象
client = pymongo.MongoClient(MONGO_URL,connect=False)
db = client[MONGO_DB]#請求索引頁(索引頁中包含著許多圖集的url)
def get_page_index(offset,keyword):data = {#定義一個data字典,用于Ajax請求'offset': offset,'format': 'json','keyword': keyword,'autoload': 'true','count': '20','cur_tab': '3','from': 'gallery'}url='http://www.toutiao.com/search_content/?'+urlencode(data)try:response = requests.get(url,headers=headers)if response.status_code == 200:return response.textreturn Noneexcept RequestException:print('請求索引頁出錯')return None#傳入索引頁的html,解析出每個圖集的url
def parse_page_index(html):try:#加入異常處理data = json.loads(html)#對html進行解析,轉換為字典。if data and 'data' in data.keys():#data.keys()返回的是這個json的所有的鍵名,這里判斷'data'在這些鍵名中for item in data.get('data'):#data對應還有許多值,遍歷這些值yield item.get('article_url')#構造一個生成器,取出data中的每一個article_url對應的urlexcept JSONDecodeError:pass#請求每個圖集的詳情頁
def get_page_detail(url):try:response = requests.get(url,headers=headers)if response.status_code == 200:return response.textreturn Noneexcept RequestException:print('請求詳情頁出錯',url)return None#解析詳情頁,獲取圖集中每張圖片的url
def parse_page_detail(html,url):soup = BeautifulSoup(html, 'lxml')# 用BeautifulSoup來提取title信息title = soup.select('title')[0].get_text()print(title)#下面提取json串,串中包含了圖片信息images_pattern = re.compile('JSON.parse\("(.*?)"\),', re.S)#注意對括號進行轉義result=re.search(images_pattern,html)if result:result = result.group(1).replace('\\', '')data = json.loads(result)#轉換成json對象if data and 'sub_images' in data.keys():sub_images = data.get('sub_images')#每個sub_images都是一個字典,需要遍歷它來提取url元素# 用一句話來構造一個list,把item賦值為sub_images的每一個子元素# 再取得sub_images的每一個item對象的url屬性,完成列表的構建,這個列表名為images,里面是sub_images下所有的urlimages = [item.get('url') for item in sub_images]root_dir=create_dir('E:\spider\jiepai')download_dir = create_dir(root_dir/title)for image in images: download_image(download_dir,image)#通過循環把圖片下載下來return {#以一個字典形式返回'title':title,'url':url,#這是當前詳情頁的url'images':images}#把url存儲到數據庫
def save_to_mongo(result):if db[MONGO_TABLE].insert(result):print('存儲到MongoDB成功',result)return Truereturn False#通過url來請求圖片
def download_image(save_dir,url):print('正在下載',url)try:response = requests.get(url,headers=headers)if response.status_code == 200:save_image(save_dir,response.content)#content返回的是二進制內容,一般處理圖片都用二進制流return response.textreturn Noneexcept RequestException:print('請求圖片出錯',url)return Nonedef create_dir(name):#根據傳入的目錄名創建一個目錄,這里用到了 python3.4 引入的 pathlib 。directory = Path(name)if not directory.exists():directory.mkdir()return directorydef save_image(save_dir,content):file_path = '{0}/{1}.{2}'.format(save_dir,md5(content).hexdigest(),'jpg')if not os.path.exists(file_path):#如果文件不存在with open(file_path,'wb') as f :f.write(content)f.close()def main(offset):html=get_page_index(offset, KEYWORD)for url in parse_page_index(html):#獲得每個圖集的urlhtml=get_page_detail(url)#用某個圖集的url來請求詳情頁if html:result=parse_page_detail(html,url)#解析詳情頁的信息if result:save_to_mongo(result)if __name__ == '__main__':groups = [x*20 for x in range(GROUP_START,GROUP_END+1)]#20,40,60...pool=Pool()pool.map(main,groups)
)









![LeetCode 刷題 [C++] 第226題.翻轉二叉樹](http://pic.xiahunao.cn/LeetCode 刷題 [C++] 第226題.翻轉二叉樹)




)

)
