前言
? ?書接上回,雙鏈表便是集齊帶頭、雙向、循環等幾乎所有元素的單鏈表PLUS.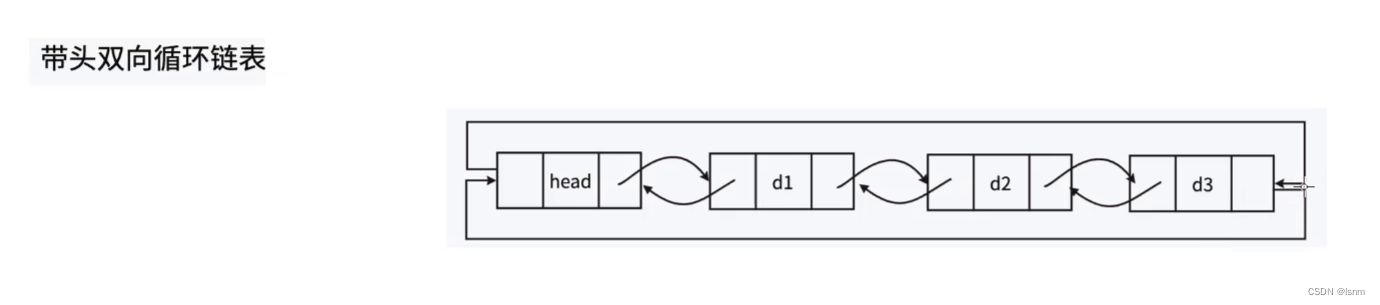
1.初始化、創建雙鏈表
typedef int LTDataType;
typedef struct LTNode {LTDataType data;struct LTNode* next;struct LTNode* prev;
}LTNode;? ?不同于單鏈表,此時每個節點應當包含兩個指針,一個指向前,一個指向后。
任然將創建節點和初始化雙鏈表封裝成兩個函數
LTNode* LTBuyNode(LTDataType x) {LTNode* phead = (LTNode*)malloc(sizeof(LTNode));if (phead == NULL) {perror("malloc fail!");exit(1);}phead->data = x;phead->next = phead->prev = NULL;
}LTNode* LTInit() {LTNode* phead = LTBuyNode(-1);phead->next = phead;phead->prev = phead;return phead;
}? ? ? LTInit步驟中,phead便是我們的哨兵位,可以不予其data賦值,也可以賦予一個不太可能成為數據的值。但是我們需要將他的next指針和prev指針分別指向下一個節點(目前是他自己)和上一個節點(目前也是他自己),這樣就形成了雙鏈表的雛形
2.插入接口
2.1尾插
void LTNodePushBack(LTNode* phead,LTDataType x) {assert(phead);LTNode* newnode = LTBuyNode(x);//開始調整各個指針指向phead->next = newnode;
}請各位稍加思考,開始調整指針的第一句對嗎?
錯了!我們認為此時的雙鏈表只有一個頭結點,所以尾差應該插在哨兵位后面,但我們函數的目的是適用于所有的尾插,這便是慣性思維?帶來的錯誤。寫各種功能函數時,提前構思出各種情況固然是好事,但對于我們新手與初學者而言,先在腦海中的普通且簡答的情況下寫出接口,再根據各個特殊情況調整才更加合適。
那我們還需要遍歷鏈表找尾節點嗎?
答案是否定的,由于循環鏈表的緣故,我們可以從頭結點(哨兵位)找到現在的尾節點,也就是phead->prev
void LTNodePushBack(LTNode* phead,LTDataType x) {assert(phead);LTNode* newnode = LTBuyNode(x);//開始調整各個指針指向newnode->prev = phead->prev;newnode->next = phead;//先修改新節點的元素的指向,此時不會導致任何節點丟失phead->prev->next = newnode;phead->prev = newnode;
}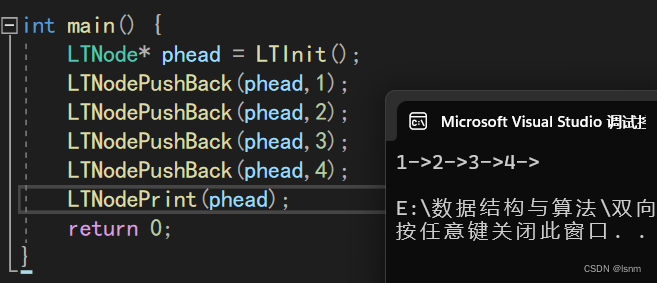
打印函數封裝如下:
void LTNodePrint(LTNode* phead) {assert(phead);LTNode* pcur = phead->next;while (pcur != phead) {printf("%d->", pcur->data);pcur = pcur->next;}printf("\n");
}不同于前面的單鏈表,此處我們沒有再使用二級指針,原因如下:
當鏈表中只有哨兵位節點時,我們稱鏈表為空鏈表,無論如何,我們不應該刪除的哨兵位。
所以,不同于單鏈表,雙鏈表一般情況不需要傳二級指針

? ? ? ?單鏈表很多時候設計修改自己的地址,所以需要使用二級指針,而雙鏈表大多數可以直接通過一級指針修改指針指向的內容,不需要使用二級指針。
但比如說,實現刪除鏈表的接口,此時就可以哨兵位的二級指針,因為涉及到修改、刪除哨兵位。
不過一級指針也可以使用(只是最后需要手動置NULL),但是可以保證接口一致性,接口一致性能降低客戶的使用成本。
再補充一個博主修改雙鏈表指針指向的思路:
1.首先修改要插入節點的本身元素指針的指向。
2.再修改待插入元素的前驅和后驅的指針指向。
2.2頭插
? ? 頭插是在第一個有效節點之前插入數據,而不是在哨兵位之前插入。哨兵位之前插入數據和尾差無異。尾差才是在最后一個有效節點之后插入數據/哨兵位之前插入數據

void LTNodePushInfront(LTNode* phead, LTDataType x) {assert(phead);LTNode* newnode = LTBuyNode(x);newnode->next = phead->next;newnode->prev = phead;phead->next->prev = newnode;phead->next = newnode;
}賦值思路依然如上:先給newnode的next和prev賦值,此時這樣操作不會影響任何人,再依次改變前驅和后驅節點的指針指向
3.刪除接口
3.1尾刪
除了斷言哨兵位是否為空,還要斷言phead->next!=phead(只剩一個哨兵位也叫空鏈表,不能再進行刪除操作),頭刪也是這個道理。
void LTNodePopBack(LTNode* phead) {assert(phead);assert(phead != phead->next);LTNode* ptail = phead->prev;ptail->prev->next = phead;phead->prev = ptail -> prev;free(ptail);
}感覺到指針指向較多怕丟失時,也可以像上面這樣定義一個新變量記錄地址,也更加容易理解。
3.2頭刪
? ? 同理,為了不造成空間浪費,我們仍然定義一個新變量來記錄想刪除的第一個有效節點,方便使用free函數。
void LTNodePopInfront(LTNode* phead) {assert(phead);assert(phead != phead->next);phead->next->next->prev = phead;LTNode* del = phead->next;phead->next = phead->next->next;free(del);del = NULL;
}4.指定位置的操作
4.1查找接口
? ? 為了便于獲得指定位置的操作的實參,我們實現一個查找函數。
LTNode* LTFind(LTNode* phead, LTDataType x) {assert(phead);LTNode* pcur = phead->next;for (; pcur != phead; pcur = pcur->next) {if (pcur->data == x) {return pcur;}}printf("find LTData Failed!");return NULL;
}4.3指定位置之后插入數據
void LTInsert(LTNode* pos, LTDataType x) {assert(pos);LTNode* newnode = LTBuyNode(x);newnode->prev = pos;newnode->next = pos->next;//先完成newnode的賦值pos->next->prev = newnode;pos->next = newnode;
}4.4刪除指定位置的節點?
理不清楚關系就定義新變量,思路一下就簡化了
void LTErase(LTNode* pos) {assert(pos);LTNode* prev = pos->prev;LTNode* next = pos->next;prev->next = next;next->prev = prev;free(pos);
}? ? 最后全部的測試的通過了。
5.鏈表與順序表的比較和數據結構小結
我們已經學習了兩種類型的數據結構,下面進行小結

數據結構是與數據庫/文件等價的一門課程,在高校中這兩種管理方式也多以單獨的課程開放。
那么就我們學習過的順序表和鏈表兩種結構而言,孰優孰劣呢?
順序表:
(所謂隨機訪問并不是真的表示隨機,而是說我想訪問哪都可以直接訪問)

鏈表(一般不說單鏈表,而說功能齊全的雙鏈表)

就紅字內容,我們再稍微簡略的展開說說:
cpu是不會直接從內存中拿取數據的(速度:寄存器>緩存>內存>硬盤),一般情況都是從緩存中拿取數據(數據量小的時候寄存器也可以直接拿數據)。
大部分情況下,如果緩存中有數據,cpu就可以直接“命中”,沒有就不命中,先從內存加載到緩存中再命中。
由局部性原理,cpu會一次性的直接去拿一定體量的連續數據(由硬件性質決定)。
而由于順序表是連續的,比如下圖,第一次沒能命中,由于已經加載了沒有命中的指針所指向的數據及其后面空間的數據,之后都能直接命中,而對于空間不連續的鏈表,大概率情況下是不會繼續命中的,每一次都會經歷從內存加載到緩存的過程,降低效率。甚至有可能造成緩存污染,也cpu一次性能裝的數據有限,很多有用的數據可能被無效的節點之后的空間擠掉,造成污染。
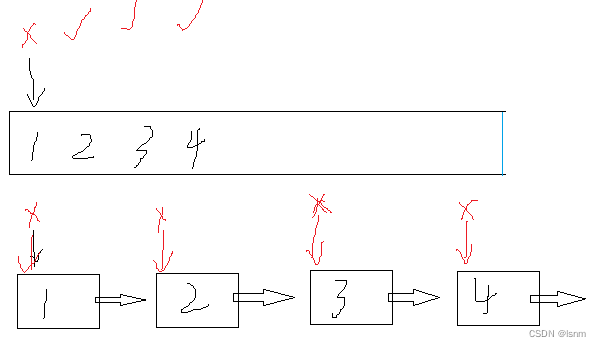
過程如下:
(cache line為緩存)
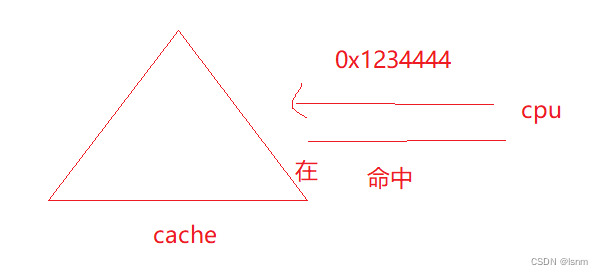
在cache line的話直接命中,較高效

不在的話就不命中,去內存中找(比如順序表是連續的內存,就會很方便找)。
6.小結
存在即合理,在當順序表和鏈表沒有其他接口的影響時,順序表的查找會更快。
充分的理解各種數據結構,手撕各種數據結構才能在以后的學習中更方便選型。可參考:
與程序員相關的CPU緩存知識 | 酷 殼 - CoolShell
??






)


)
)





)


