一、模型評估
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report# 使用測試集進行預測
y_pred = model.predict(X_test)# 計算準確率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy*100:.2f}%")# 打印混淆矩陣
conf_matrix = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(conf_matrix)# 打印分類報告,包括精確率、召回率和F1分數
class_report = classification_report(y_test, y_pred)
print("Classification Report:")
print(class_report)二、模型保存
#使用joblib保存模型
import joblib
joblib.dump(model, "./yorelee_model.pth")
#模型的后綴名是無所謂的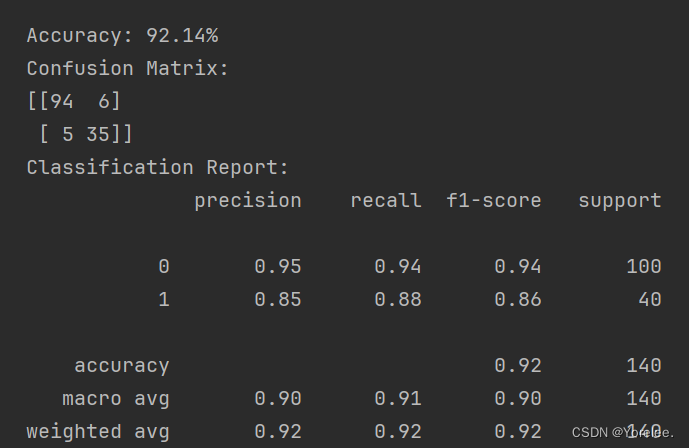
三、后話
模型選擇的時候,也可以使用模型融合,即結果由用不同模型的結果按比例得到。
比如pre=(pre_1*a+pre_2*b)/(a+b)。
那么我們在保存模型的時候,這兩個模型要一起保存,然后之后訓練就導入兩個模型,pre這樣算出來就行。
%%time
# 2種模型融合
def model_mix(pred_1, pred_2):result = pd.DataFrame(columns=['LinearRegression','XGBRegressor','Combine'])for a in range (80):for b in range(1,80):y_pred = (a*pred_1 + b*pred_2 ) / (a+b)mse = mean_squared_error(y_test,y_pred)mse = mean_squared_error(y_test,y_pred)new_row = pd.DataFrame([{'LinearRegression':a, 'XGBRegressor':b, 'Combine':mse}])result = pd.concat([result, new_row], ignore_index=True)return resultlinear_predict=model_linear.predict(x_test)
xgb_predict=XGBClassifier.predict(x_test)
model_combine = model_mix(linear_predict, xgb_predict)model_combine.sort_values(by='Combine', inplace=True)
model_combine.head()
#各種比例來一份,看看mse最高分,查看 a和b的具體值)
 Practice | 朋友數)



)





)

)

)


)
