文章目錄
- 基本配置
- 分庫分表的分片策略
- 一、inline 行表達時分片策略
- algorithm-expression行表達式
- 完整案例和配置如下
- 二、根據實時間日期 - 按照標準規則分庫分表
- 標準分片 - Standard
- 完整案例和配置如下
基本配置
邏輯表
邏輯表是指:水平拆分的數據庫或者數據表的相同路基和數據結構表的總稱。比如用戶數據根據用戶id%2拆分為2個表,分別是:ksd_user0和ksd_user1。他們的邏輯表名是:ksd_user。
在shardingjdbc中的定義方式如下:
spring:shardingsphere:sharding:tables:# ksd_user 邏輯表名ksd_user:
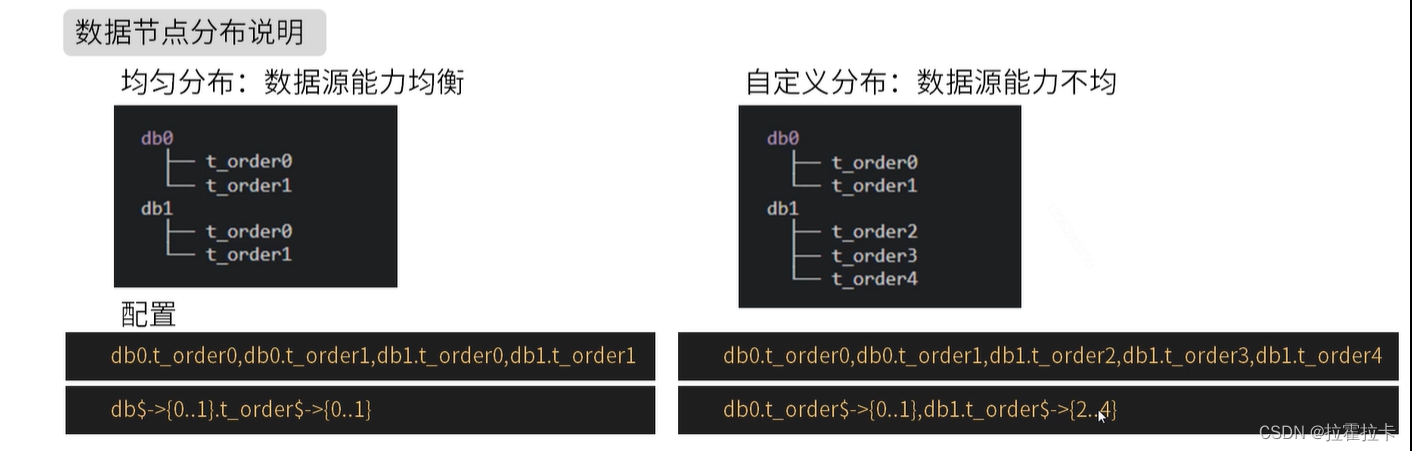
分庫分表數據節點 - actual-data-nodes
tables:# ksd_user 邏輯表名ksd_user:# 數據節點:多數據源$->{0..N}.邏輯表名$->{0..N} 相同表actual-data-nodes: ds$->{0..2}.ksd_user$->{0..2}# 也可以這么寫,不同數據源不同表actual-data-nodes: ds0.ksd_user$->{0..2},ds1.ksd_user$->{2..4}# 指定單數據源的配置方式-同一個數據源,不同表actual-data-nodes: ds0.ksd_user$->{0..4}# 全部手動指定actual-data-nodes: ds0.ksd_user0,ds1.ksd_user0,ds0.ksd_user1,ds1.ksd_user1,
尋找規則如下:
分庫分表的分片策略
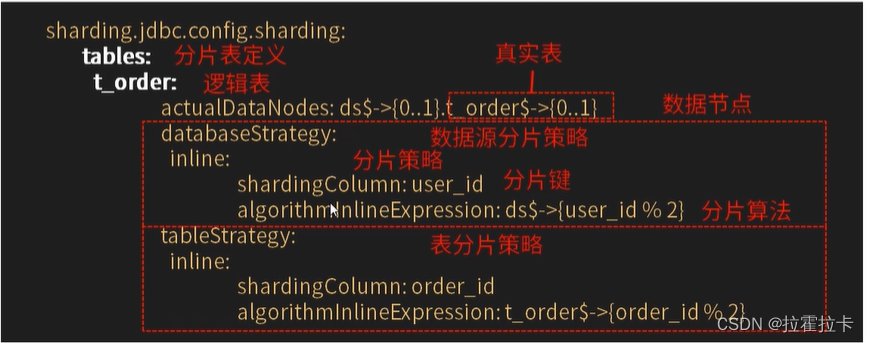
分片策略由分片鍵和分片算法組成
一、inline 行表達時分片策略
對應InlineShardingStragey。使用Groovy的表達時,提供對SQL語句種的=和in的分片操作支持,只支持單分片鍵。對于簡單的分片算法,可以通過簡單的配置使用,從而避免繁瑣的Java代碼開放,如:ksd_user${分片鍵(數據表字段)userid % 5} 表示ksd_user表根據某字段(userid)模 5.從而分為5張表,表名稱為:ksd_user0到ksd_user4 。數據庫也是如此。
# 配置默認數據源ds1sharding:# 默認數據源,主要用于寫,注意一定要配置讀寫分離 ,注意:如果不配置,那么就會把三個節點都當做從slave節點,新增,修改和刪除會出錯。default-data-source-name: ds0# 配置分表的規則tables:# ksd_user 邏輯表名ksd_user:key-generator:# 主鍵的列明,雪花算法,也可以是UUIDcolumn: idtype: SNOWFLAKE# 數據節點:數據源$->{0..N}.邏輯表名$->{0..N}actual-data-nodes: ds$->{0..2}.ksd_user$->{0..2}# 拆分庫策略,也就是什么樣子的數據放入放到哪個數據庫中。database-strategy:inline:sharding-column: sex # 分片字段(分片鍵)algorithm-expression: ds$->{sex % 3} # 分片算法表達式# 拆分表策略,也就是什么樣子的數據放入放到哪個數據表中。table-strategy:inline:sharding-column: age # 分片字段(分片鍵)algorithm-expression: ksd_user$->{age % 3} # 分片算法表達式
grove表達式說明:
- ${begin…end} 表示區間范圍
- ${[unit1,unit2,….,unitn]} 表示枚舉值
- 行表達式種如果出現連續多個 e x p r e s s s i o n 或 {expresssion}或 expresssion或->{expression}表達式,整個表達時最終的結果將會根據每個子表達式的結果進行笛卡爾組合
algorithm-expression行表達式

完整案例和配置如下
- 準備三臺服務器(測試用也可以用docker 安裝三個服務),三個數據庫ksd_sharding-db,名字相同,兩個數據源ds0,ds1,ds2
- 每個數據庫下方新建ksd_user0、ksd_user1、ksd_user1即可
- 數據庫規則,result = (sex%3),result=0的放入ds2庫,result=1的放入ds1庫,result=2的放入ds2庫
- 數據表規則:result = (age%3),根據取模結果分別放入ksd_user0、ksd_user1、ksd_user1表
- 如果數據庫配置了主從復制,需要將主從復制取消掉
mysql> stop slave;
server:port: 8085
spring:main:allow-bean-definition-overriding: trueshardingsphere:# 參數配置,顯示sqlprops:sql:show: true# 配置數據源datasource:# 給每個數據源取別名,下面的ds1,ds2,ds3任意取名字names: ds0,ds1,ds2# 給master-ds1每個數據源配置數據庫連接信息ds0:# 配置druid數據源type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://master:port/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMTusername: rootpassword: 123456maxPoolSize: 100minPoolSize: 5# 配置ds2-slaveds1:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://slave1:port/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMTusername: rootpassword: 123456maxPoolSize: 10minPoolSize: 5# 配置ds3-slaveds2:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://slave2:port/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMTusername: rootpassword: 123456maxPoolSize: 10minPoolSize: 5# 配置默認數據源ds1sharding:# 默認數據源,主要用于寫,注意一定要配置讀寫分離 ,注意:如果不配置,那么就會把三個節點都當做從slave節點,新增,修改和刪除會出錯。default-data-source-name: ds0# 配置分表的規則tables:# ksd_user 邏輯表名ksd_user:key-generator:# 主鍵的列明,雪花算法,也可以是UUIDcolumn: idtype: SNOWFLAKE# 數據節點:數據源$->{0..N}.邏輯表名$->{0..N}actual-data-nodes: ds$->{0..2}.ksd_user$->{0..2}# 拆分庫策略,也就是什么樣子的數據放入放到哪個數據庫中。database-strategy:inline:sharding-column: sex # 分片字段(分片鍵)algorithm-expression: ds$->{sex % 3} # 分片算法表達式# 拆分表策略,也就是什么樣子的數據放入放到哪個數據表中。table-strategy:inline:sharding-column: age # 分片字段(分片鍵)algorithm-expression: ksd_user$->{age % 3} # 分片算法表達式
# 整合mybatis的配置XXXXX
mybatis:mapper-locations: classpath:mapper/*.xmltype-aliases-package: com.example.shardingjdbc.sharding.entity@GetMapping("/save")public String insert() {User user = new User();user.setNickname("test" + new Random().nextInt());user.setBirthday(new Date());// 3%3=0,所以這條數據應該在ds0這臺服務上user.setSex(3);// 25%3=1 所以這個條數據應該在ksd_user1這個表里面user.setAge(25);user.setPassword("123456");userMapper.addUser(user);return "success";}
二、根據實時間日期 - 按照標準規則分庫分表
標準分片 - Standard
- 對應StrandardShardingStrategy.提供對SQL語句中的=,in和惡between and 的分片操作支持
- StrandardShardingStrategy只支持分片鍵。提供PreciseShardingAlgorithm和RangeShardingAlgorithm兩個分片算法
- PreciseShardingAlgorithm是必選的,用于處理=和IN的分片
- RangeShardingAlgorithm是可選的,是用于處理Betwwen and分片,如果不配置和RangeShardingAlgorithm,SQL的Between AND 將按照全庫路由處理
完整案例和配置如下
yml配置
server:port: 8085
spring:main:allow-bean-definition-overriding: trueshardingsphere:# 參數配置,顯示sqlprops:sql:show: true# 配置數據源datasource:# 給每個數據源取別名,下面的ds1,ds2,ds3任意取名字names: ds0,ds1,ds2# 給master-ds1每個數據源配置數據庫連接信息ds0:# 配置druid數據源type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://master:port/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMTusername: rootpassword: 123456maxPoolSize: 100minPoolSize: 5# 配置ds2-slaveds1:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://slave1:port/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMTusername: rootpassword: 123456maxPoolSize: 10minPoolSize: 5# 配置ds3-slaveds2:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://slave2:port/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMTusername: rootpassword: 123456maxPoolSize: 10minPoolSize: 5# 配置默認數據源ds1sharding:# 默認數據源,主要用于寫,注意一定要配置讀寫分離 ,注意:如果不配置,那么就會把三個節點都當做從slave節點,新增,修改和刪除會出錯。default-data-source-name: ds0# 配置分表的規則tables:# ksd_user 邏輯表名ksd_user:key-generator:# 主鍵的列明,雪花算法,也可以是UUIDcolumn: idtype: SNOWFLAKE# 數據節點:數據源$->{0..N}.邏輯表名$->{0..N}actual-data-nodes: ds$->{0..2}.ksd_user$->{0..2}# 拆分庫策略,也就是什么樣子的數據放入放到哪個數據庫中。database-strategy:standard:sharding-column: birthday # 分片字段(分片鍵)preciseAlgorithmClassName: com.example.shardingjdbc.sharding.algorithm.BirthdayAlgorithm# 拆分表策略,也就是什么樣子的數據放入放到哪個數據表中。table-strategy:inline:sharding-column: age # 分片字段(分片鍵)algorithm-expression: ksd_user$->{age % 3} # 分片算法表達式
# 整合mybatis的配置XXXXX
mybatis:mapper-locations: classpath:mapper/*.xmltype-aliases-package: com.example.shardingjdbc.sharding.entity自定義日期規則
/*** @description: BirthdayAlgorithm*/
public class BirthdayAlgorithm implements PreciseShardingAlgorithm<Date> {List<Date> dateList = new ArrayList<>();{Calendar calendar1 = Calendar.getInstance();calendar1.set(2020, 1, 1, 0, 0, 0);Calendar calendar2 = Calendar.getInstance();calendar2.set(2021, 1, 1, 0, 0, 0);Calendar calendar3 = Calendar.getInstance();calendar3.set(2022, 1, 1, 0, 0, 0);dateList.add(calendar1.getTime());dateList.add(calendar2.getTime());dateList.add(calendar3.getTime());}@Overridepublic String doSharding(Collection<String> collection, PreciseShardingValue<Date> preciseShardingValue) {// 獲取屬性 數據庫中的值Date date = preciseShardingValue.getValue();// 獲取數據源名稱列表Iterator<String> iterator = collection.iterator();String target = null;for (Date item: dateList) {target = iterator.next();if (date.before(item)) {break;}}return target;}
}測試結果
- http://localhost:8085/user/save?sex=3&age=3&birthday=2020-03-09 —- ds1

- http://localhost:8085/user/save?sex=3&age=3&birthday=2021-03-09 —- ds2

)

)


)

版本庫 —— 存儲系統,存儲目錄,提交對象及其命名、移動與復制~)


)




)



