目錄
- Throughput/Latency
- Serial Computing
- Parallel Computing
- Types of parallel computers
- Simple 4-width SIMD
- Amdahl's law
- Types of parallelism
- **Data Parallel Model**
- Task parallel
- Partitioning
- Domain Decomposition
- Functional Decomposition
- Communications
- Example that does not need communication
- Example that need communication
- Synchronization
- Barrier
- Granularity
- Fine-grain Parallelism
- Coarse-grain Parallelism
- How expensive is memory I/O
- Solving the problem
- Just add more stuff for the GPU to do
- Latency Hiding
- Coalesced Global memory access
- Host/Device Transfers and Data Movement
- Avoid transfers
- Pinned Host Memory
在本章中,我們將回顧一些有關并行計算的概念。但更加強調 GPU。
Throughput/Latency
在討論性能之前,我們先回顧一下一些概念。
- 吞吐量:單位時間內計算任務的數量。即:一分鐘內 1000 筆信用卡付款。
- 延遲:調用操作和獲得響應之間的延遲。即:處理信用卡交易所需的最長時間為 25 毫秒。
在優化性能時,一個因素(例如吞吐量)的改進可能會導致另一因素(例如延遲)的惡化。
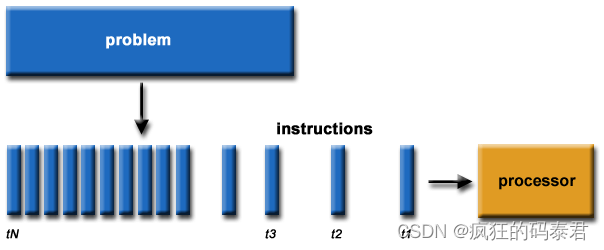
Serial Computing
這是老辦法,我們遇到一個問題,我們把它們分解成一個個小塊,然后一個接一個地解決。
Parallel Computing
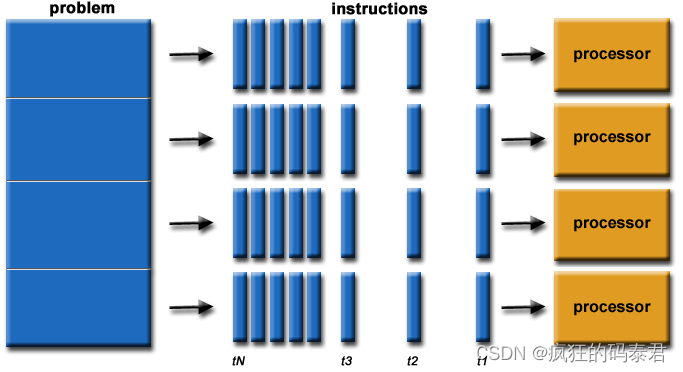
從最簡單的意義上來說,并行計算是同時使用多個計算資源來解決計算問題。
Types of parallel computers
根據弗林分類法,并行計算機有 4 種不同的分類方法。
下面是一些經典的例子
- SISD:非常舊的計算機(PDP1)
- MIMD:超級計算機
- SIMD:Intel 處理器、Nvidia Gpus
- MISD:確實很少見。
對于 GPU,它們通常是 SIMD 類型的處理器。不同的處理單元執行相同的指令,但在共享內存的不同部分。
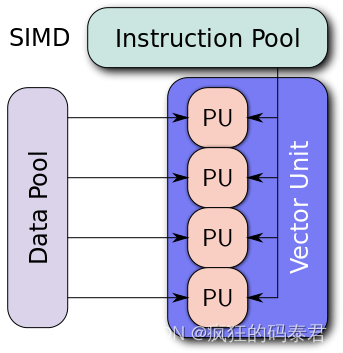
Simple 4-width SIMD
下面我們有一個 4 寬度的 SIMD。這里的所有處理器都在同時執行“add”指令。
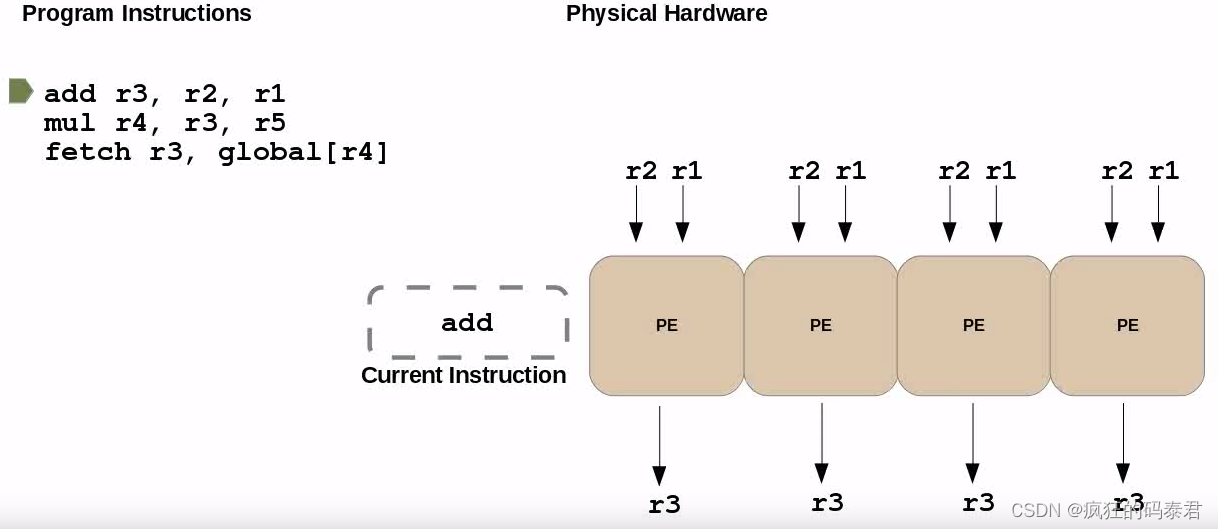 當您聽說 GPU 有 5000 個核心時,請不要被愚弄,它可能只是說它有 5000 個 ALU(算術邏輯單元)。 GPU 可同時執行的最大任務數通常在 Nvidia 上稱為“warp size”,在 AMD 上稱為“wavefront”,通常是按塊/網格組織的 32 寬 SIMD 單元。
當您聽說 GPU 有 5000 個核心時,請不要被愚弄,它可能只是說它有 5000 個 ALU(算術邏輯單元)。 GPU 可同時執行的最大任務數通常在 Nvidia 上稱為“warp size”,在 AMD 上稱為“wavefront”,通常是按塊/網格組織的 32 寬 SIMD 單元。
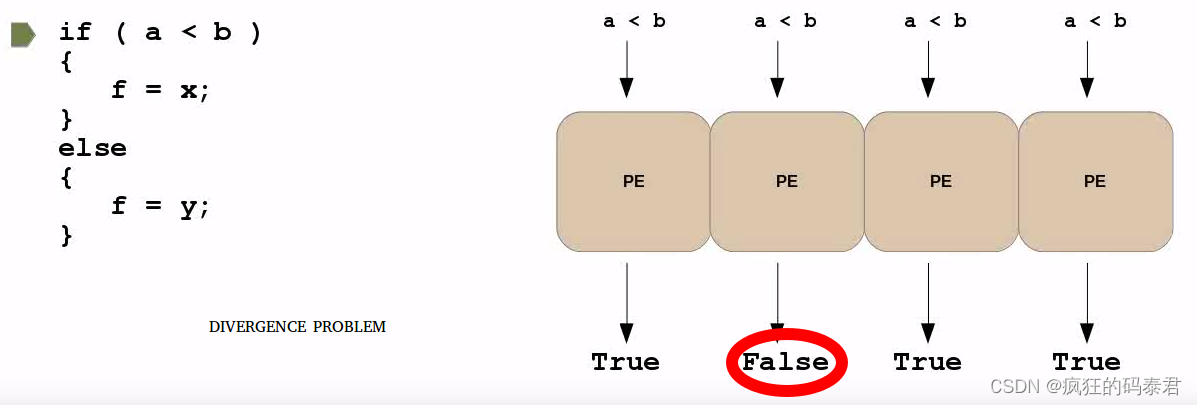
可能發生的一個有趣的問題是,如果您有一條分支(if)指令,并且每個處理元素決定不同的事情。如果發生這種情況,您將受到處理處罰。這種效應稱為發散。為了解決這個問題,您必須嘗試盡量減少波動前(cuda 中的wrap)上分支指令的使用。
如果您需要這種分支分配,您可以使用 opencl 中的“select”來編譯為單個指令(原子),這樣就不會發生發散問題。
Amdahl’s law
Amdahl’s Law指出潛在的程序加速(理論延遲)由可以并行化的代碼 p 的比例定義:
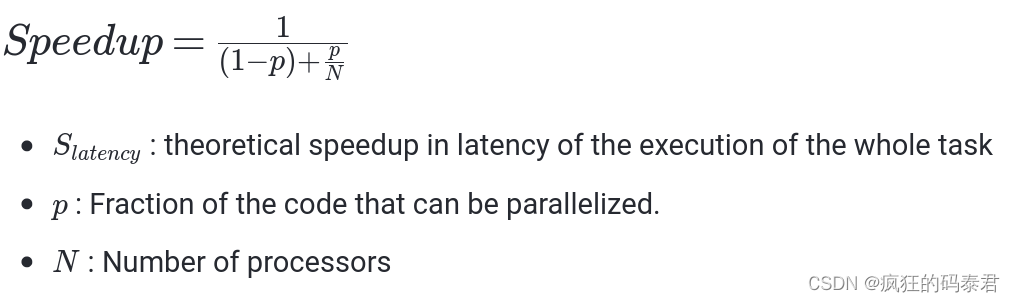
- S : 整個任務執行延遲的理論加速
- p: 可以并行化的代碼的一部分。
- 處理器數量
從該定律可以得到:加速受到不可并行工作部分的限制,即使使用無限數量的處理器,速度也不會提高,因為串行部分會受到限制。
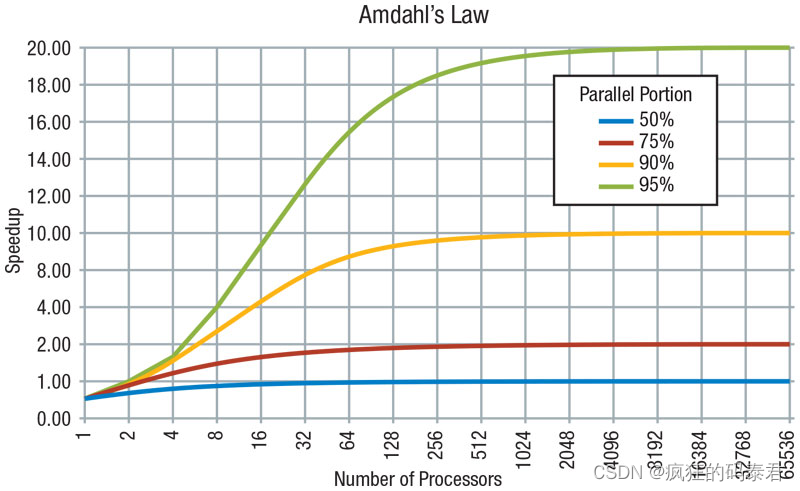
程序的總執行時間T分為兩類: - 執行不可并行串行工作所花費的時間
- 進行可并行工作所花費的時間
這里還缺少一些重要的東西。阿姆達爾定律沒有考慮內存延遲等其他因素。
Types of parallelism
Data Parallel Model
在此模型上,共享內存對所有節點都是可見的,但每個節點都處理該共享內存的部分內容。這就是我們通常使用 GPU 要做的事情
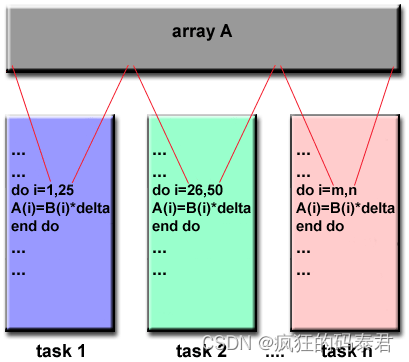
數據并行方法的主要特點是編程相對簡單,因為多個處理器都運行相同的程序,并且所有處理器大約在同一時間完成其任務。當每個處理器正在處理的數據之間的依賴性最小時,此方法是有效的。例如,向量加法可以從這種方法中受益匪淺。
Task parallel
任務并行方法的主要特點是每個處理器執行不同的命令。與數據并行方法相比,這增加了編程難度。由于處理時間可能會根據任務的分割方式而有所不同,因此需要一些同步。如果任務完全不相關,問題就會容易得多。
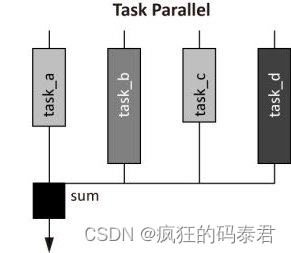
Partitioning
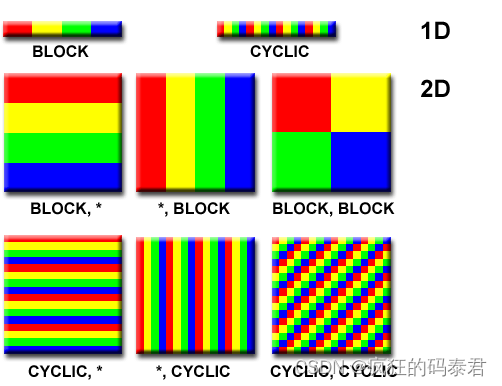
設計并行程序的第一步是將問題分解為可以分配給多個任務的離散工作“塊”。這稱為分解或劃分。有兩種在并行任務之間劃分計算工作的基本方法:
- 域分解:
- 功能分解。
Domain Decomposition
在這種類型的分區中,與問題相關的數據被分解。然后,每個并行任務都處理一部分數據。
Functional Decomposition
在這種方法中,重點是要執行的計算,而不是計算所操縱的數據。問題根據必須完成的工作進行分解。然后,每個任務執行整體工作的一部分。
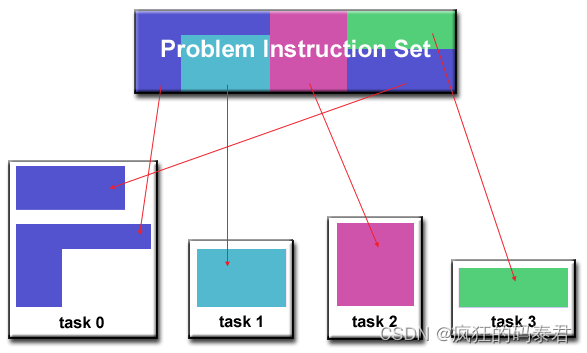
Communications
通常一些并行問題需要節點(任務)之間進行通信。這又是一個與問題相關的問題。需要考慮的一些要點:
- 通信總是意味著開銷
- 通信頻繁需要節點(任務)同步,需要較大的開銷
當您需要將數據發送到 GPU 來執行某些計算,然后將結果傳回 CPU 時,就意味著需要進行通信。
Example that does not need communication
某些類型的問題可以分解并并行執行,幾乎不需要任務共享數據。例如,想象一下圖像處理操作,其中黑白圖像中的每個像素都需要反轉其顏色。圖像數據可以輕松地分配給多個任務,然后這些任務彼此獨立地完成各自的工作。這些類型的問題通常被稱為“尷尬并行”,因為它們非常簡單。需要很少的任務間通信。
Example that need communication
大多數并行應用程序并不是那么簡單,并且確實需要任務彼此共享數據。例如,3-D 熱擴散問題需要任務了解具有相鄰數據的任務計算出的溫度。相鄰數據的更改會直接影響該任務的數據。
Synchronization
管理工作順序和執行工作的任務是大多數并行程序的關鍵設計考慮因素。同步總是會影響性能,但當任務需要通信時總是需要同步。
同步類型
- Barrier(用于 OpenCl)
- Lock/semaphore 鎖/信號量
- Synchronous communication operations 同步通訊操作
Barrier
這是一種同步機制,每個任務都執行其工作,直到到達屏障。然后它會停止或“阻塞”,直到所有任務都到達同一點。當最后一個任務到達屏障時,所有任務都會同步。
Granularity
這是關于計算和通信之間的比率。有 2 種粒度
Fine-grain Parallelism
通信多于計算
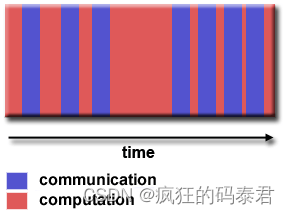
Coarse-grain Parallelism
計算多于溝通
最有效的粒度取決于算法及其運行的硬件環境。但是……通常通信的延遲比計算的延遲更大。例如,將數據復制到 GPU 或從 GPU 復制數據。所以我們更喜歡粗粒度,這意味著大量的計算和很少的 GPU/CPU 通信。
How expensive is memory I/O
正如心理實驗一樣,想象一個處理元素(節點/任務)在 1 秒內做出語句(即 V:=1+2+3/4)。但如果需要讀/寫 GPU 全局內存,則需要更多時間。考慮下表。
順便說一句,我們考慮到數據已經在 GPU 上,將數據發送到 GPU 是另一個問題。
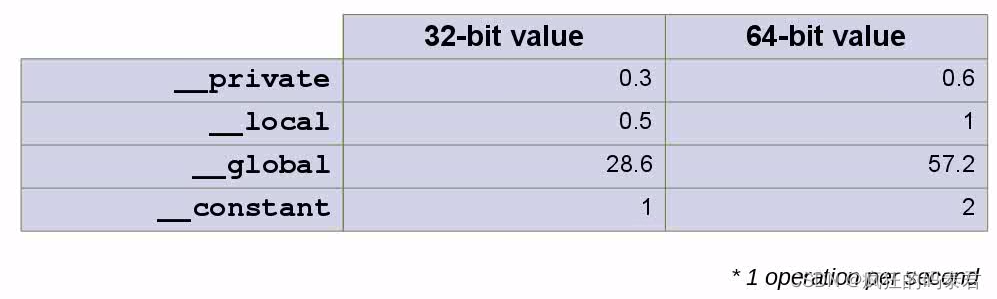 在此表中,我們有不同的內存類型,其中全局內存是 GPU 內存,私有內存和本地內存是位于每個核心內部的內存,常量也是全局內存,但專門用于讀取速度更快。現在檢查以下示例。
在此表中,我們有不同的內存類型,其中全局內存是 GPU 內存,私有內存和本地內存是位于每個核心內部的內存,常量也是全局內存,但專門用于讀取速度更快。現在檢查以下示例。
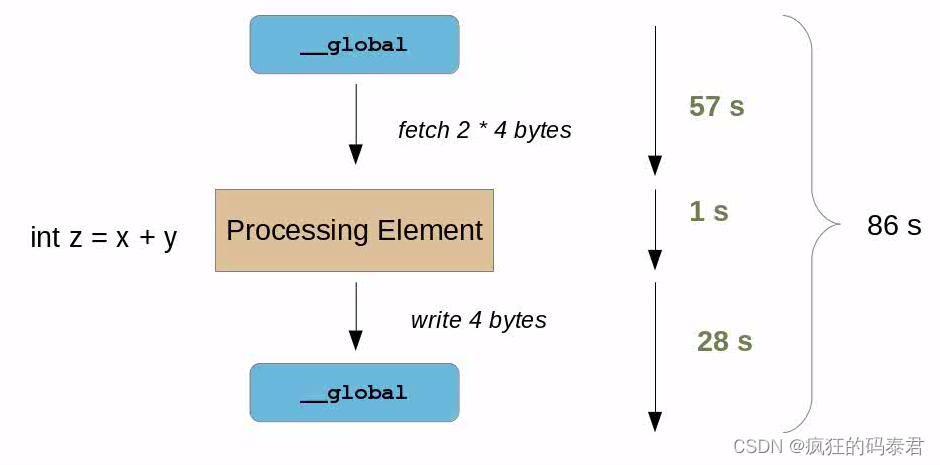
在這種情況下,我們的計算結果是 整個時間的 1 86 \frac{1}{86} 861? 。這很糟糕,這意味著我們的 ALU 工作在 A L U e f i c i e n c y ALU_{eficiency} ALUeficiency?= 1 86 ? 100 \frac{1}{86}*100 861??100 ∴ A L U e f i c i e n c y ALU_{eficiency} ALUeficiency?=1.1%。
現在想象一下,我們需要處理更多的數據,而不是 int(4 字節)x,y 將是 long(8 字節)。
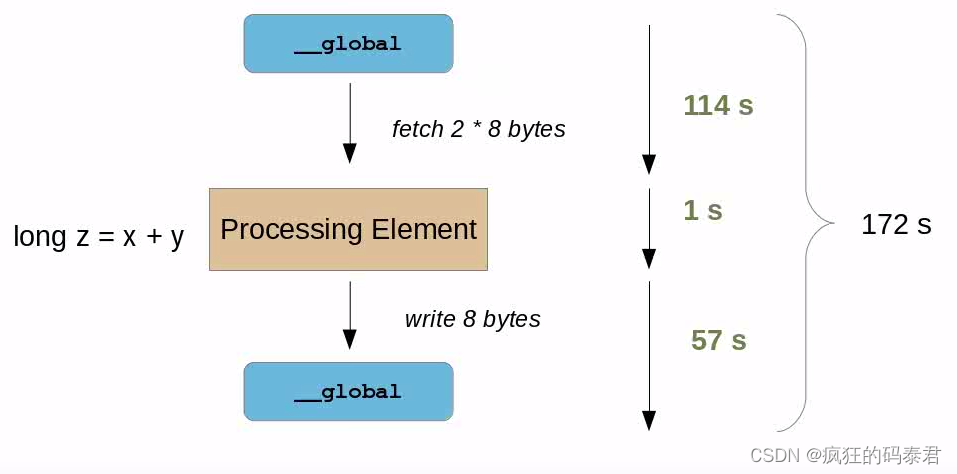
現在情況變得更糟了。我們的計算結果是整個時間的 1 172 \frac{1}{172} 1721? 。這很糟糕,這意味著我們的 ALU 工作在 A L U e f i c i e n c y ALU_{eficiency} ALUeficiency?= 1 172 ? 100 \frac{1}{172}*100 1721??100 ∴ A L U e f i c i e n c y ALU_{eficiency} ALUeficiency?=0.58%。
如果我們想與某些原始順序算法相比提高性能,這可能意味著兩件事:
- 原來的順序算法一定比這個內存I/O延遲慢很多。
- 您需要在 GPU 內執行更多操作才能稀釋該時間。
Solving the problem
Just add more stuff for the GPU to do
我們可能想到的第一件事是添加更多要完成的處理,這實際上會花費比內存延遲更多的時間。同樣,如果處理時間加上內存延遲小于原始順序 CPU 版本,您將獲得加速。
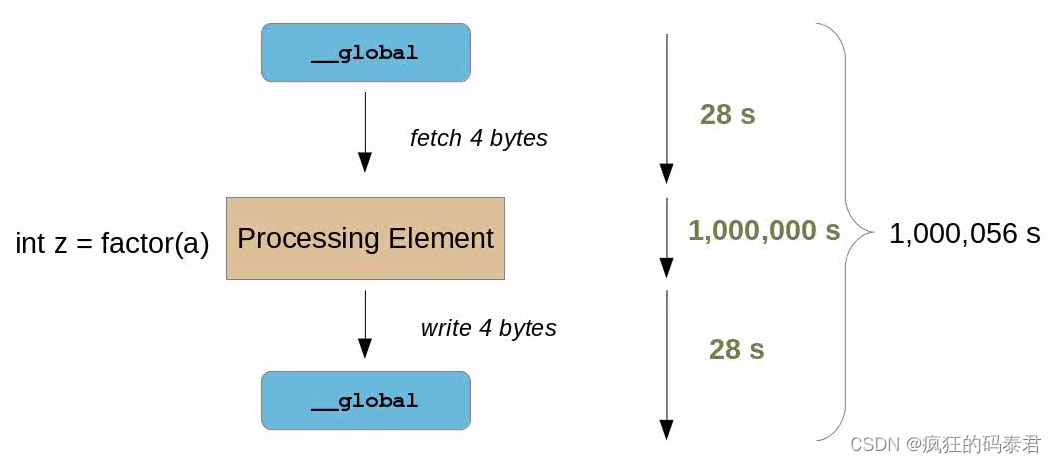 在這種情況下,您現在擁有 100% 的 Alu 效率,但這僅在現實生活中當您處理令人尷尬的并行問題時才會發生。例如大矩陣乘法、密碼分析等…
在這種情況下,您現在擁有 100% 的 Alu 效率,但這僅在現實生活中當您處理令人尷尬的并行問題時才會發生。例如大矩陣乘法、密碼分析等…
Latency Hiding
更好的技術是使用 GPU 上下文切換機制來隱藏此延遲。這是通過向 GPU 發出并行代碼標志來實現的,表明它正在等待可用的內存請求。當這種情況發生時,等待可用內存的處理元素組將進入池。與此同時,GPU 可以啟動另一個工作組來執行,但最終會暫時停止。這個想法是,當這種情況發生時,一些工作項將具有可用的內存,這將具有最小化整個延遲的效果。
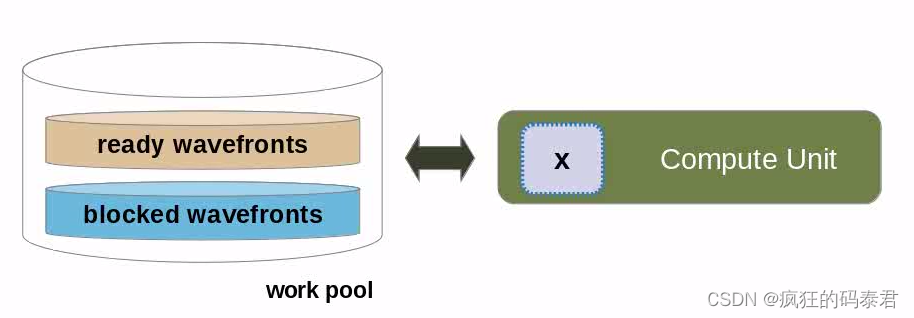
所以我們用工作組(work group)來溢出我們的計算單元
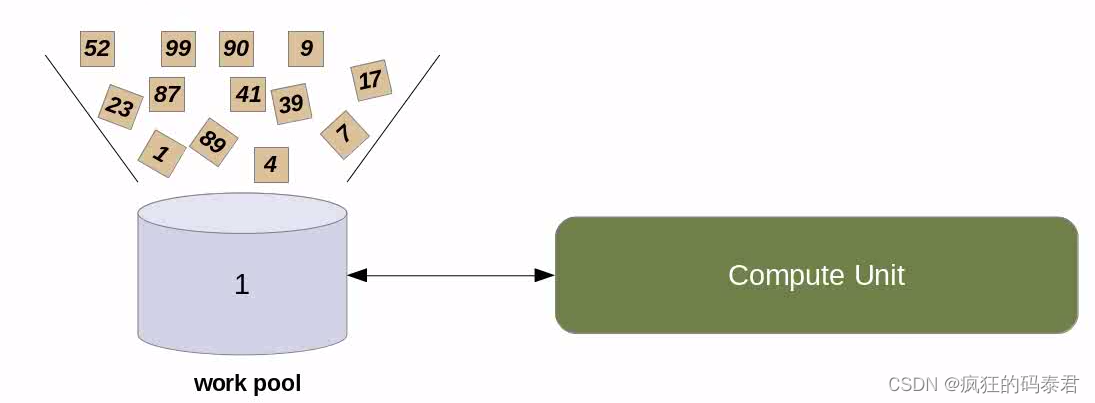
然后,我們隱藏內核訪問全局內存的長內存延遲時間,因為當 GPU 分配要執行的工作組時,有些工作組可能是可用的。順便說一句,當您的工作組位于波前(或warp)內時,這將起作用.
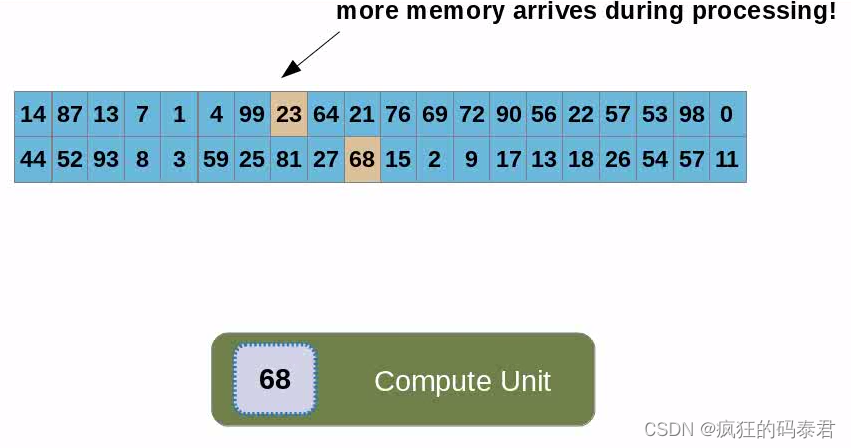
Coalesced Global memory access
主機向GPU發送數據后,內存將位于全局內存上,每個線程(計算單元)都會訪問數據。我們已經討論過這很慢,但有時您需要這樣做。每次內核在全局內存上讀/寫時,它實際上是在訪問一塊內存。合并訪問是指訪問相鄰地址上的數據。
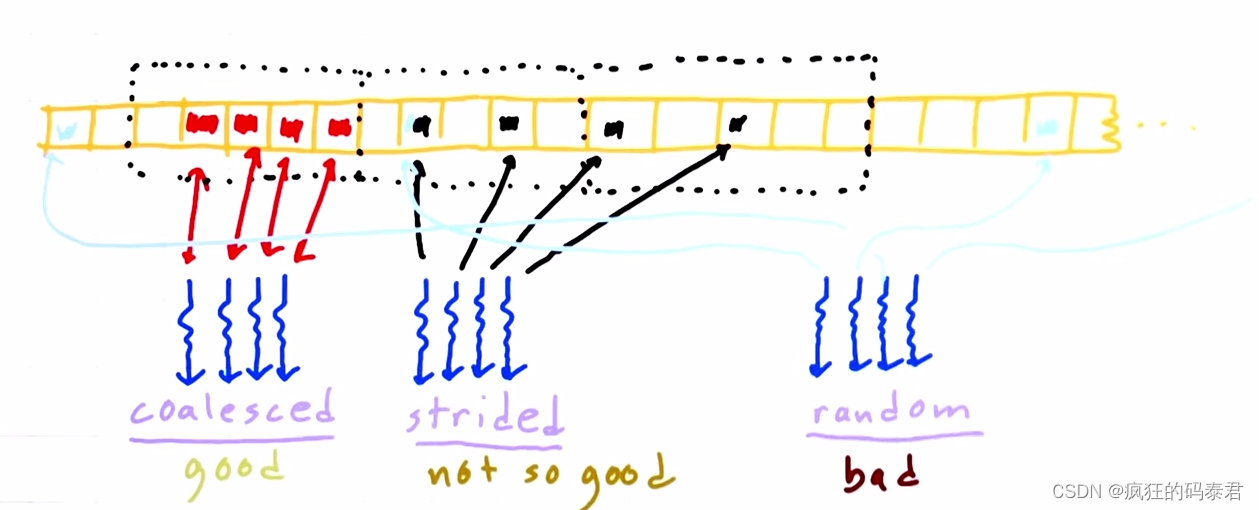
因此,這意味著使用較少的線程消耗相鄰內存塊來訪問內存比使用大量的線程消耗隨機地址更快。
Host/Device Transfers and Data Movement
到目前為止,我們僅考慮數據已位于 GPU(全局內存)上時的性能。這忽略了 GPU 編程中最慢的部分,即從 GPU 獲取數據和從 GPU 取出數據。
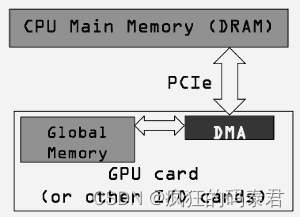
我們不應該僅使用內核的 GPU 執行時間相對于其 CPU 實現的執行時間來決定是運行 GPU 還是 CPU 版本。當我們最初將代碼移植到 GPU 時,我們還需要考慮通過 PCI-e 總線移動數據的成本。
因為 GPU 是插入 PCI-e 總線的,所以這很大程度上取決于 PCI 總線的速度以及有多少其他東西正在使用它。
host/device transfer latency 是嘗試在 GPU 上加速算法時的主要困難。
發生這種情況是因為,如果您的順序算法計算的時間小于此主機/設備傳輸的時間,則無需做太多事情。但有一些…
Avoid transfers
這是最明顯的一個,但您至少需要一個,對嗎?因此,寧愿進行一次大傳輸,也不愿進行多次小傳輸,特別是在程序循環中。
Pinned Host Memory
默認情況下,主機 (CPU) 數據分配是可分頁的。 GPU 無法直接從可分頁主機內存訪問數據,因此當調用從可分頁主機內存到設備內存的數據傳輸時。發生這種情況是因為操作系統為其所有設備提供了虛擬地址,并且您的驅動程序需要使用這些頁面來獲取真實地址。 GPU 驅動程序必須首先分配一個臨時頁面鎖定或“固定”主機數組,將主機數據復制到固定數組,然后將數據從固定數組傳輸到設備內存,如下所示。
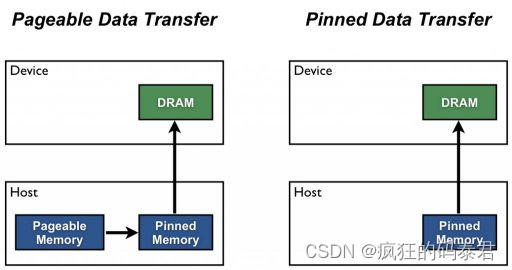
如圖所示,固定內存用作從設備到主機傳輸的暫存區域。我們可以通過直接在固定內存中分配主機陣列來避免可分頁和固定主機陣列之間的傳輸成本。
您不應該過度分配固定內存。這樣做會降低整體系統性能,因為它會減少操作系統和其他程序可用的物理內存量。很難提前判斷多少才算是太多,因此與所有優化一樣,測試您的應用程序及其運行的系統以獲得最佳性能參數。


(線上圖片))

)


)











