目錄
前言
一、StarRocks表設計
1.1?字段類型
1.2 分區分桶
1.2.1 分區規范
1.2.2 分桶規范
1.3 主鍵表
1.3.1?數據有冷熱特征
1.3.2?大寬表
1.4 實際案例
1.4.1?案例一:主鍵表內存優化
1.4.2 案例一:Update內存超了,導致主鍵表導入失敗
1.4.3 案例四:tablet 數量治理
1.5 建表案例
二、StarRocks監控
2.1?監控架構
2.2?監控使用
2.2 監控分類
2.2.1 Overview
2.2.2 Cluster Overview
2.2.3 Query Statistic
2.2.4 Jobs
2.2.5 Transaction
2.2.6 FE JVM
2.2.7 BE
2.2.8 BE tasks
2.2.9 BE Mem
三、總結
前言
? ? ?StarRocks 是一款高性能分析型數據倉庫,使用向量化、MPP 架構、CBO、智能物化視圖、可實時更新的列式存儲引擎等技術實現多維,實時,高并發的數據分析。StarRocks 既支持從各類實時和離線的數據源高效導入數據,也支持直接分析數據湖上各種格式的數據。StarRocks 兼容 MySQL 協議,可使用 MySQL 客戶端和常用 BI 工具對接。同時StarRocks具備水平擴展,高可用、高可靠、易運維等特性,StarRocks 廣泛應用于實時數倉、OLAP 報表、數據湖分析等場景。
一、StarRocks表設計
? ? ?現有的場景中,主要使用比較多的兩種表模型是更新模型和主鍵模型。二者在同維度列相同的 數據處理上是一致的,不同的是相對于更新模型,主鍵模型在查詢時不需要執行聚合操作,并且支持謂詞下推和索引使用,能夠在支持實時和頻繁更新等場景的同時,提供高效查詢。
? ? 下面內容主要是對更新模型與主鍵模型都適用的分區分桶規范,以及主鍵模型需要而外注意一些場景。
1.1?字段類型
? ? ?定義恰當數據字段類型對StarRocks查詢的優化是非常重要的,從查詢效率的角度考慮,我們可以遵循兩條原則:
- 如果數據沒有Null,可以指定Not Null屬性;
- 盡量使用數字列代替字符串列。
1.2 分區分桶
? ?StarRocks采用Range分區,Hash分桶的組合數據分布方式。
? Table (邏輯描述) -- > Partition(分區:管理單元) --> Bucket(分桶:每個分桶就是一個數據分片:Tablet,數據劃分的最小邏輯單元)
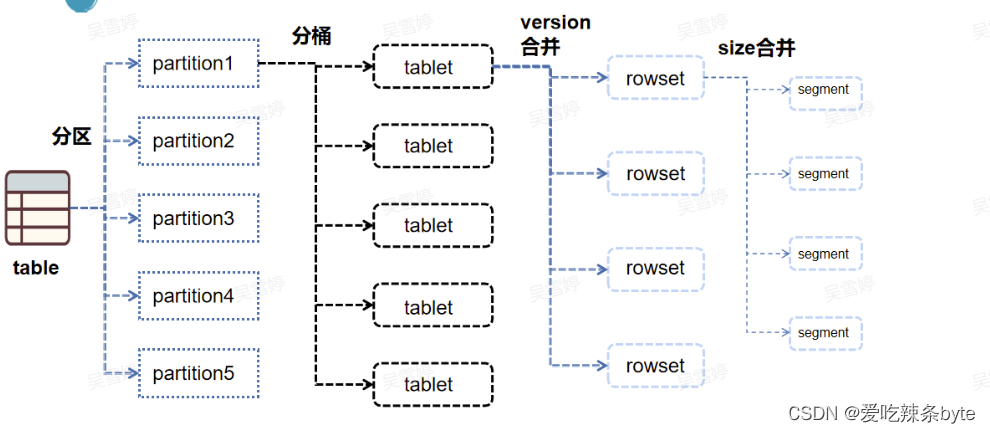
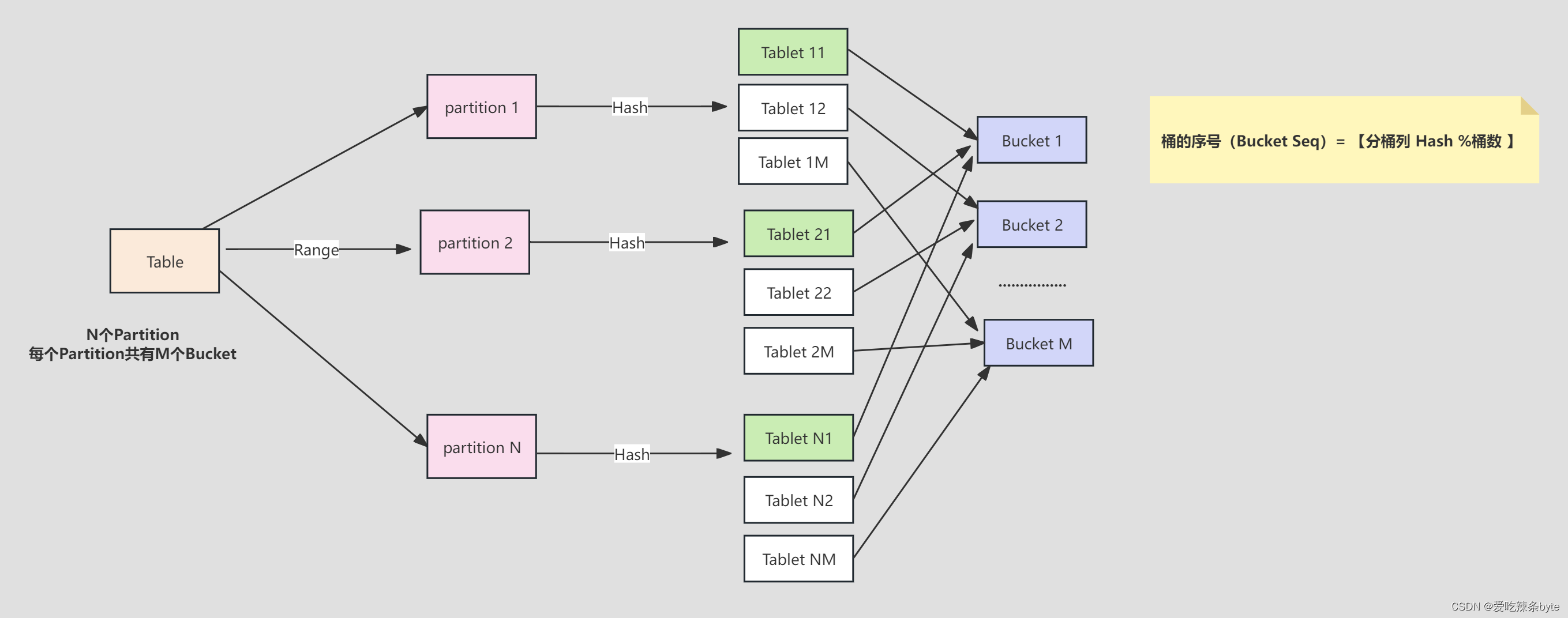
1.2.1 分區規范
- 分區鍵選擇:當前分區鍵僅支持日期類型和整數類型,表中數據可以根據分區列(通常是時間和日期)分成一個個更小的數據管理單元。查詢時,通過分區裁剪,可以減少掃描的數據量,顯著優化查詢性能。
- 分區粒度選擇:StarRocks 的分區粒度需要綜合考慮數據量、查詢特點、數據粒度等因素。單個分區原始數據量建議維持在100G以內。
1.2.2 分桶規范
- 分桶鍵選擇:
- 如果查詢比較復雜,則建議選擇高基數的列為分桶鍵,保證數據在各個分桶中盡量均衡,提高集群資源利用率。
- 如果查詢比較簡單,則建議選擇經常作為查詢條件的列為分桶鍵,提高查詢效率。
- 如果數據傾斜情況嚴重,可以使用多個列作為數據的分桶鍵,但是建議不超過 3 個列
- 分桶數:分桶數的設置需要適中,如果分桶過少,查詢時查詢并行度上不來(CPU多核優勢體現不出來)。而如果分桶過多,會導致元數據壓力比較大,數據導入導出時也會受到一些影響。
? ?ps:? 從經驗來看,每個分桶的原始數據建議不要超過5個G,考慮到壓縮比,即每個分桶的大小建議在100M-1G之間。
1.3 主鍵表
? ? ?該模型適合需要對數據進行實時更新的場景,特別適合 MySQL 或其他數據庫同步到 StarRocks 的場景。雖然原有的Unique更新模型也可以實現對數據的更新,但Merge-on-Read 的策略大大限制了查詢性能。Primary主鍵模型更好地解決了行級別的更新操作,配合 Flink-connector-StarRocks 可以完成 MySQL 數據庫的同步。
? 由于StarRocks 存儲引擎會為主鍵建立索引,而在導入數據時會把主鍵索引加載在內存中,所以主鍵模型對內存的要求比較高,還不適合主鍵特別多的場景。目前比較適合的兩個場景是:
1.3.1?數據有冷熱特征
? ? 數據有冷熱特征,即最近幾天的熱數據才經常被修改,老的冷數據很少被修改。典型的例子如 MySQL 訂單表實時同步到 StarRocks 中提供分析查詢。其中,數據按天分區,對訂單的修改集中在最近幾天新創建的訂單,老的訂單完成后就不再更新,因此導入時其主鍵索引就不會加載,也就不會占用內存,內存中僅會加載最近幾天的索引。

1.3.2?大寬表
? ? 大寬表(數百到數千列),主鍵只占整個數據的很小一部分,其內存開銷比較低。比如用戶狀態和畫像表,雖然列非常多,但總的用戶數不大(千萬至億級別),主鍵索引內存占用相對可控。

1.4 實際案例
1.4.1?案例一:主鍵表內存優化
- 治理前現狀
? ? ? 數據團隊集群總共有主鍵表50張左右,集群8臺BE節點,平均每臺BE大概有7.5G內存被主鍵長期消耗(常駐),當前集群機器分配給 BE 服務也就只有50G,嚴重影響了離線寫入與查詢的性能。
- 治理方式
不需要實時更新的主鍵表都改用更新模型。
檢查所有主鍵表的數據生命周期,刪除多余數據。
寫入有冷熱概念的表,全部增加分區鍵。
- 治理結果
? ? ? 主鍵表優化,BE 內存釋放大概48G(常駐),優化后BE有更多內存用于寫入和查詢。
1.4.2 案例一:Update內存超了,導致主鍵表導入失敗
- 1.背景
? ? ?收到研發反饋,說有多個主鍵表導入報錯,任務返回如下:
Caused by: java.io.IOException: com.starrocks.connector.flink.manager.StarRocksStreamLoadFailedException: Failed to flush data to StarRocks, Error response: {"Status":"Fail","BeginTxnTimeMs":0,"Message":"close index channel failed, load_id=bc4eb485-f99b-1f20-ffd9-e7e7e22925ab","NumberUnselectedRows":0,"CommitAndPublishTimeMs":0,"Label":"2434c3d7-9cef-45b0-b057-482b9a0032cd","LoadBytes":1056,"StreamLoadPutTimeMs":1,"NumberTotalRows":0,"WriteDataTimeMs":14,"TxnId":1355616,"LoadTimeMs":15,"ReadDataTimeMs":0,"NumberLoadedRows":0,"NumberFilteredRows":0}- 2.報錯
? ? ?通過 Label ID去BE日志里面過濾,找到相關的報錯:
? ? ps:每一個事務可以設置一個label,StarRocks FE會檢查本次begin transaction 請求的label是否已經存在,如果label在系統中不存在,則會為當前label開啟一個新的事務。

- 3.相關監控

- 4.原因
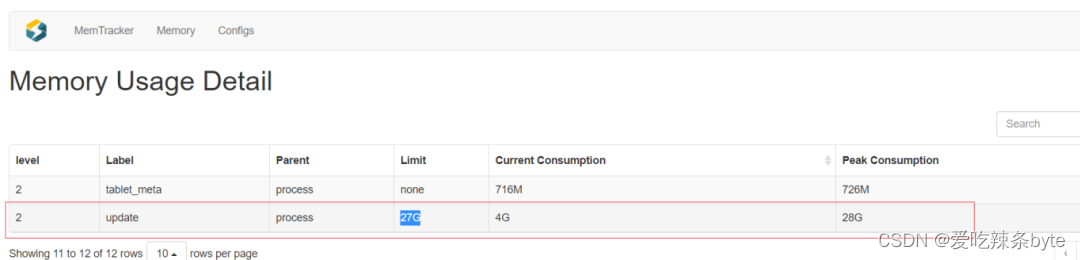
? ?默認BE的Update內存設置是27G,實際使用中發現這部分內存使用超了,導致任務報錯。
該值已經很大了,排查后發現有幾張表設計的不合理。
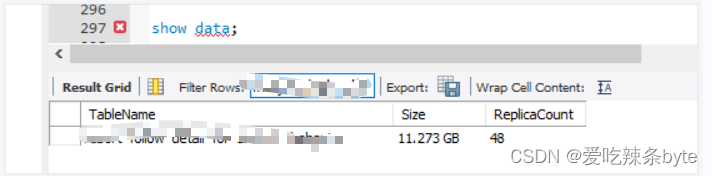
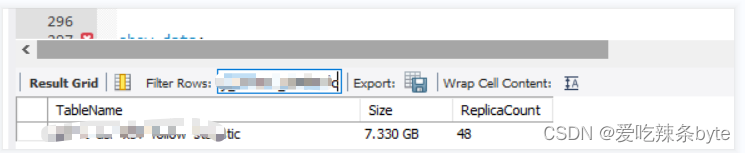
? ?該主鍵表沒有分區,在寫入的時候會把整張表都加載到內存中,導致BE內存暴漲,超出Update 限制。
- 5.處理
? ? ?表優化:發現該業務其實并不需要用主鍵模型只需要更新模型就能滿足需求。于是把主鍵模型改為了更新模型。
- 6.補充與總結
1.相較更新模型,主鍵模型(Primary Key)可以更好地支持實時/頻繁更新的功能。如果表寫入的是離線任務,或者更新頻率很低則不需要使用主鍵模型,因為主鍵模型相對于更新模型有更大的內存消耗。
2.主鍵表把主鍵加載到內存中的最小維度是分區,所以主鍵表如果有冷熱數據的概念,可以根據時間增加分區鍵,減小寫入時主鍵部分消耗的內存。(默認主鍵表在寫入的時候,會將主鍵加載到內存中,如10分鐘沒有寫入需求才會把這部分內存釋放)
1.4.3 案例四:tablet 數量治理
- 治理前現狀
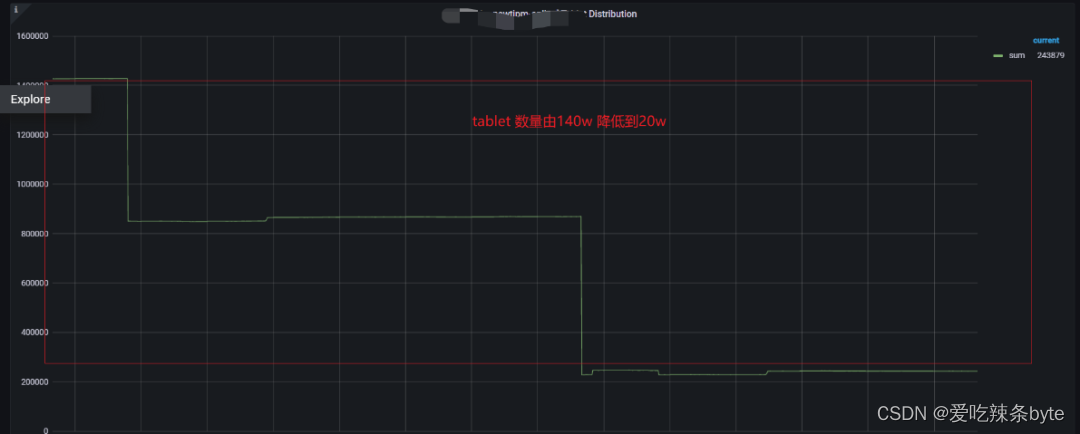
? ? ? 數據團隊集群的數據分片Tablet數120w,整個集群的數據量才3T,平均每個Tablet大小才2.6M,遠低于官方推薦的100M-1G,有大量的tablet大小只有幾KB,而Tablet 過多導致元數據過大,FE內存緊張。(show data)
- 治理方式
? ?以單個分區大小在100G以內,單個Tablet 數據分配在100M-1G為標準,對表的分區分桶做重新設計,具體方式是:
a. 把天級別分區改為月級別分區
b. 對于分桶過多,數據量不大的表,減少分桶數量
- 治理結果
? ? 治理后,Tablet 數量由140W 降低到13W,FE?內存峰值由 18.6G 下降為 4.5G,減少了FE內存的浪費。
1.5 建表案例
(1)業務背景:需要新建一張訂單表,表信息如下:
#=====1.字段
bos_id bigint(20) NOT NULL COMMENT "組織架構樹id",
vid bigint(20) NOT NULL COMMENT "節點id",
path varchar(65533) NULL COMMENT "父節點路徑",
prod_id bigint(20) NOT NULL COMMENT "產品id",
prod_inst_id bigint(20) NOT NULL COMMENT "產品實例id",
st tinyint(4) NOT NULL COMMENT "數據統計類型0:全部, 1:自身, 2:全部子節點",
consign_type tinyint(4) NOT NULL COMMENT "交付單狀態0:待發單;1:發單;2確認收貨",
order_no bigint(20) NOT NULL COMMENT "訂單號",
dd date NOT NULL COMMENT "日期",
merchant_id bigint(20) NOT NULL COMMENT "商戶id",
vid_type bigint(20) NOT NULL COMMENT "節點類型",
consign_vid bigint(20) NULL COMMENT "處理vid",
create_time datetime NOT NULL COMMENT "創建時間"#=====2.數據量:年數據量預估在20億左右。
#=====3.SIZE:年數據量是10G左右,23年之前有存量數據1G。
#=====4.常用過濾條件:dd,bos_id,path,prod_id。
#=====5.QPS:10
(2)建表分析
1、 2023年之前存量數據較少,使用頻率低,可以建為一個分區。
2、 增量數據穩定10G每年,并有時間維度做分區,采用月分區,平均分區大小在0.83G。(每分區=10G/12)
3、 在保證每個Tablet數據量在100M-1G之間的同時,增加讀寫的并發,將分桶設置為6,平均Tablet大小是138M(每桶=0.83G / 6)。#======建表,更新模型
CREATE TABLE table1 (
dd date NOT NULL COMMENT "日期",
bos_id bigint(20) NOT NULL COMMENT "組織架構樹id",
vid bigint(20) NOT NULL COMMENT "節點id",
path varchar(65533) NULL COMMENT "父節點路徑",
prod_id bigint(20) NOT NULL COMMENT "產品id",
prod_inst_id bigint(20) NOT NULL COMMENT "產品實例id",
st tinyint(4) NOT NULL COMMENT "數據統計類型0:全部, 1:自身, 2:全部子節點",
consign_type tinyint(4) NOT NULL COMMENT "交付單狀態0:待發單;1:發單;2確認收貨",
order_no bigint(20) NOT NULL COMMENT "訂單號",
merchant_id bigint(20) NOT NULL COMMENT "商戶id",
vid_type bigint(20) NOT NULL COMMENT "節點類型",
consign_vid bigint(20) NULL COMMENT "處理vid",
create_time datetime NOT NULL COMMENT "創建時間"
) ENGINE=OLAP
UNIQUE KEY(dd, bos_id, vid, path, prod_id, prod_inst_id, st, consign_type, order_no)
COMMENT "履約分析_待發貨待發單待備貨"
PARTITION BY RANGE(dd)
(PARTITION p2022 VALUES [('1970-01-01'), ('2023-01-01')),
PARTITION p2023 VALUES [('2023-01-01'), ('2024-02-01')),
PARTITION p202401 VALUES [('2023-02-01'), ('2024-03-01')))
DISTRIBUTED BY HASH(bos_id, order_no) BUCKETS 6
PROPERTIES (
"replication_num" = "3",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "MONTH",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-2147483648",
"dynamic_partition.end" = "1",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "6",
"dynamic_partition.start_day_of_month" = "1",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);二、StarRocks監控
? ? 本模塊包含監控架構、監控頁面使用、監控項的解釋以及對應值的合理范圍(其中部分性能指標有原理及排查思路的擴展)。
2.1?監控架構
? ? StarRocks 支持基于Prometheus 和 Grafana實現可視化監控,便于監控和故障排除。StarRocks 提供了兼容Prometheus的信息采集接口,Prometheus通過 Pull 方式訪問 FE 或 BE 的 Metric 接口,然后將監控數據存入時序數據庫。Grafana 則可以將 Prometheus 作為數據源將指標信息可視化。搭配 StarRocks 提供的Dashboard模板,可以便捷的實現StarRocks集群監控指標的統計展示和閾值報警。
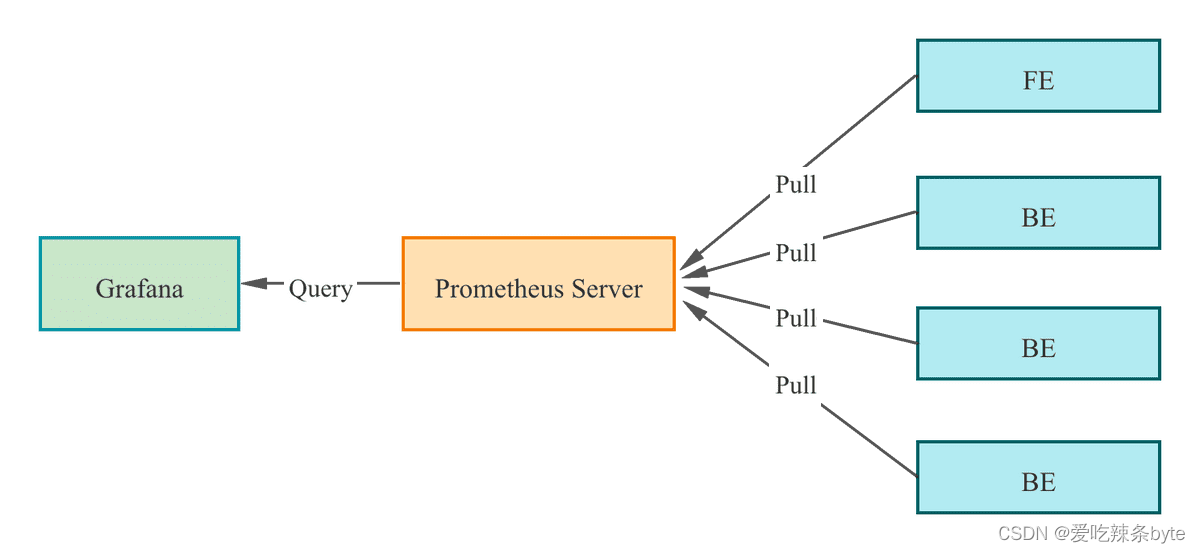
? 監控告警選擇上,基于官方推薦的 Prometheus+Grafana 的方案,?公司內部接入 AlertManager+ 自定義的 API 做告警。
? ?Prometheus 通過 Pull 方式訪問 FE 或 BE 的 Metric 接口,然后將監控數據存入時序數據庫。監控展示選取的是通過 Grafana 配置 Prometheus 為數據源。

-
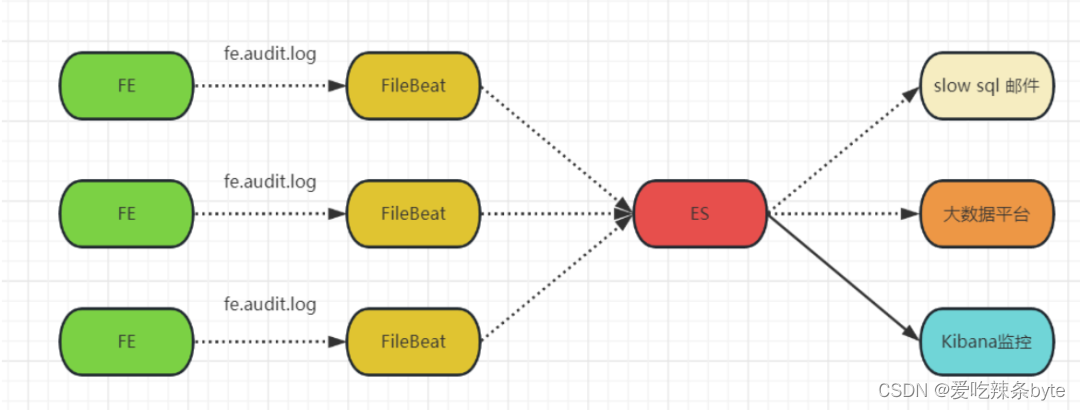
StarRocks 慢查詢
? ? ?針對集群的審計SQL進行采集分析,通過ELK將各個FE節點的審計日志采集后寫入到ES中,通過配置規則,篩選出其中的慢sql,推送到告警系統中,以提醒相應的同事關注及優化。
2.2?監控頁面使用
? 根據需求,選擇需要查看的集群,FE,BE節點。

2.2 監控分類
? ?對于關鍵指標會標記。
2.2.1 Overview
? ?主要是用來同時展示所有StarRocks 集群的運行狀態,一般作為StarRocks日常巡檢的一部分。
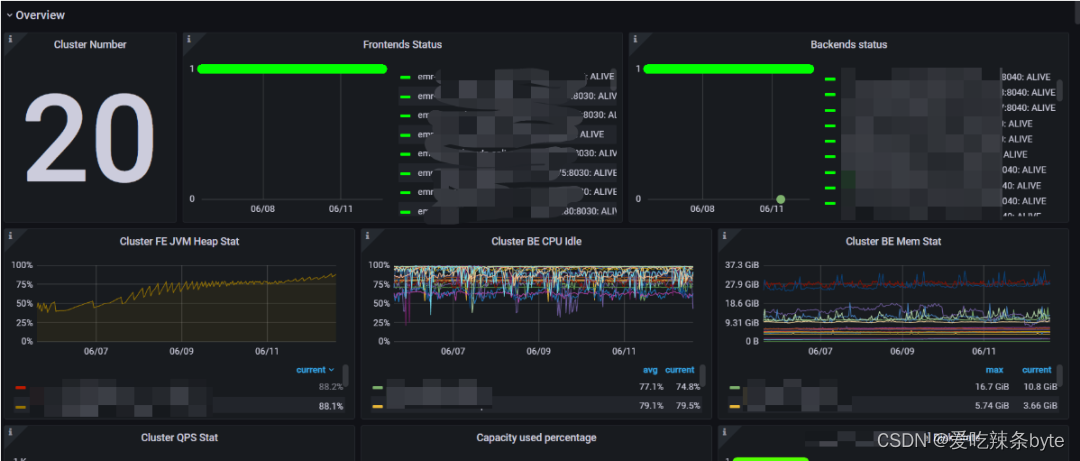
監控項解釋:
1、Cluster Number:starrocks 集群總數
2、Frontends Status:fe節點狀態(1為alive,0為dead)
3、Backends status:be節點狀態(1為alive,0為dead)
4、Cluster FE JVM Heap Stat:fe內存使用情況(所有fe節點的平均值)
5、Cluster BE CPU Idle:be節點cpu使用情況(所有be節點的平均值)
6、Cluster BE Mem Stat:be節點內存使用情況(所有be節點的平均值)
7、Cluster QPS Stat:集群qps
8、Capacity used percentage:集群存儲使用百分百
9、Disk State:be節點磁盤的狀態(1為正常,0為異常)
2.2.2 Cluster Overview
? ? 主要是所選擇集群的基礎指標,觀察所選集群的基礎狀態。

1、FE Node:FE節點的總數
2、FE Alive:alive狀態 FE節點數
3、BE Node:BE節點的總數
4、BE Alive:alive狀態 BE節點數
5、Total Capacity:集群整體的存儲
6、Used Capacity:已使用的存儲
7、Max Replayed journal id:當前最新的journal id
8、Scheduling Tablets:集群中正在調度(被復制)的tablet數量(tablet缺失,不一致,unhealthy,balance 都會觸發tablet 的復制),一般情況下,該值超過50需要檢查一下集群的負載。
2.2.3 Query Statistic
? ?集群查詢相關的指標:
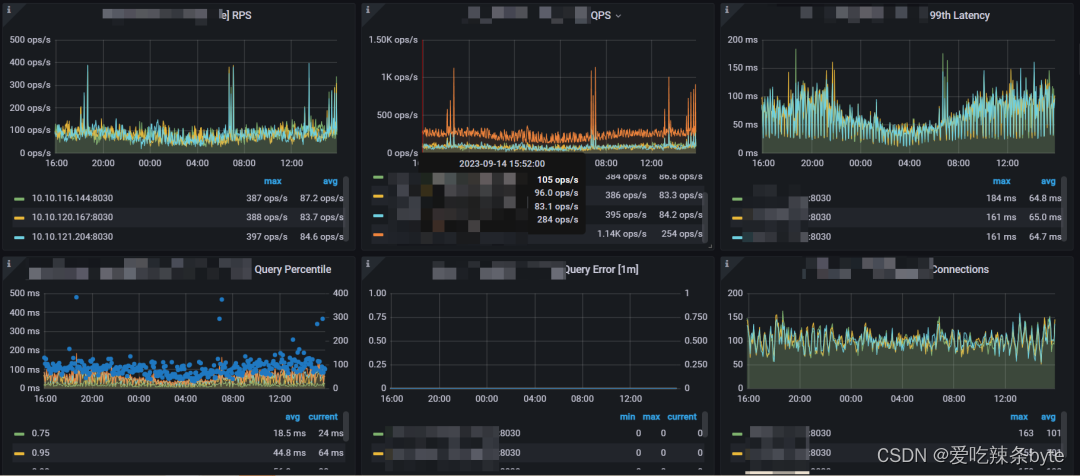
1、 RPS:每個FE的每秒請求數。請求包括發送到FE的所有請求。
2、 QPS:每個FE的每秒查詢數。查詢僅包括 Select 請求。
3、?99th Latency:每個FE 的 99th個查詢延遲情況。
4、 Query Percentile:左 Y 軸表示每個FE的 95th 到 99th 查詢延遲的情況。右側 Y 軸表示每 1 分鐘的查詢率。
5、 Query Error:左 Y 軸表示累計錯誤查詢次數。右側 Y 軸表示每 1 分鐘的錯誤查詢率。通常,錯誤查詢率應為 0。
6、?Connections:每個FE的連接數量
7、Slow Query:慢查詢的數量(累計值)
2.2.4 Jobs
??寫入任務的相關指標:
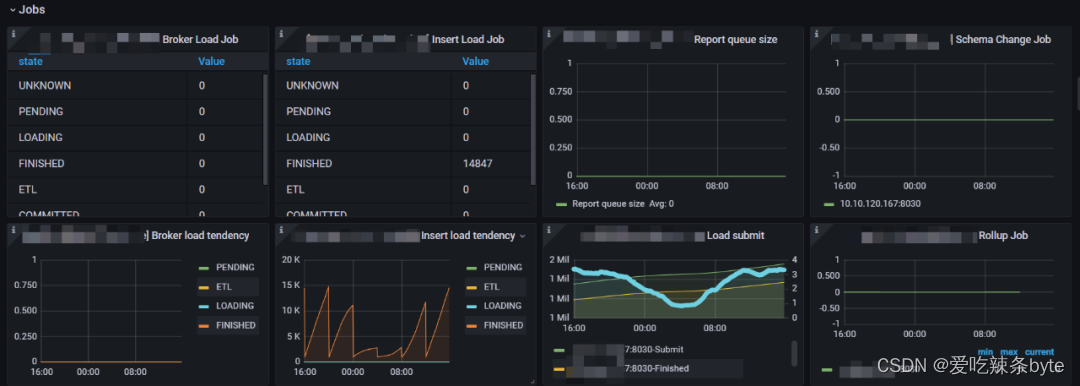
1、Broker Load Job:每個負載狀態下的Broker Load 作業數量的統計。
2、Insert Load Job:由 Insert Stmt 生成的每個 Load State 中的負載作業數量的統計。
3、Report queue size:Master FE 中報告的隊列大小
4、Schema Change Job:正在運行的Schema 更改作業的數量。
5、Broker load tendency:Broker Load 作業趨勢報告
6、Insert Load tendency:Insert Stmt 生成的 Load 作業趨勢報告
7、Load submit:顯示已提交的 Load 作業和 Load 作業完成的計數器。
8、Rollup Job:正在運行Rollup 構建作業數量
2.2.5 Transaction
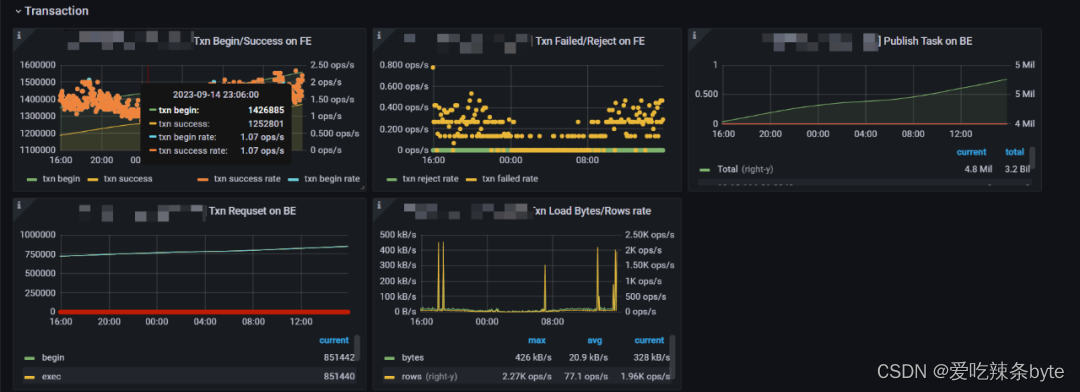
1、Txn Begin/Success on FE:事務開始/完成的數量,及速率,可以側面衡量集群的寫入頻率
2、Txn Failed/Reject on FE:事務失敗/拒絕的速率,可以側面衡量集群寫入失敗的情況
3、Publish Task on BE:發布任務請求總數和錯誤率。(注意每個節點取得是錯誤的概率,集群正常情況下這個應該為0)
4、Txn Requset on BE:在 BE 上顯示 txn 請求這里包括:begin,exec,commit,rollback四種請求的統計信息
5、Txn Load Bytes/Rows rate:事務寫入速度,左 Y 軸表示 txn 的總接收字節數。右側 Y 軸表示 txn 的Row 加載率。
2.2.6 FE JVM
? ?FE服務的內存,線程相關指標:
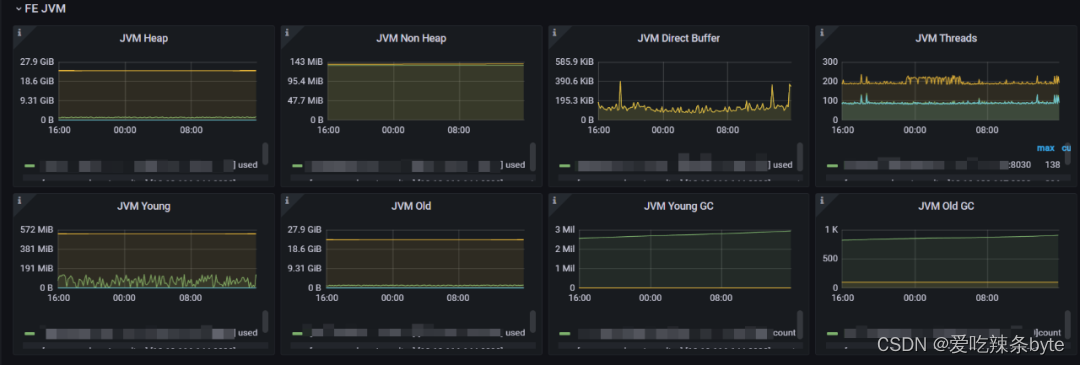
1、JVM Heap:FE 服務堆內存使用(2.0.2 版本?FE?內部有內存架構有問題,有統計不全的情況,該值不是極為準確,可以作為?FE?負載變化的參考)
2、JVM Non Heap:非堆內存的使用
3、JVM Direct Buffer:指定 FE 的 JVM 直接緩沖區使用情況。左 Y 軸顯示已用/容量直接緩沖區大小。
4、JVM Threads:集群FE JVM線程數。用來參考FE的負載情況
5、JVM Young:指定 FE 的 JVM 年輕代使用情況。
6、JVM Old:指定 FE 的 JVM 老年代使用情況。
7、JVM Young GC:指定 FE 的 JVM 年輕 GC 統計信息(總數和平均時間)。
8、JVM Old GC:指定 FE 的 JVM 完整 GC 統計信息(總數和平均時間)。
2.2.7 BE
? ?BE服務的基礎,集群層面的指標:
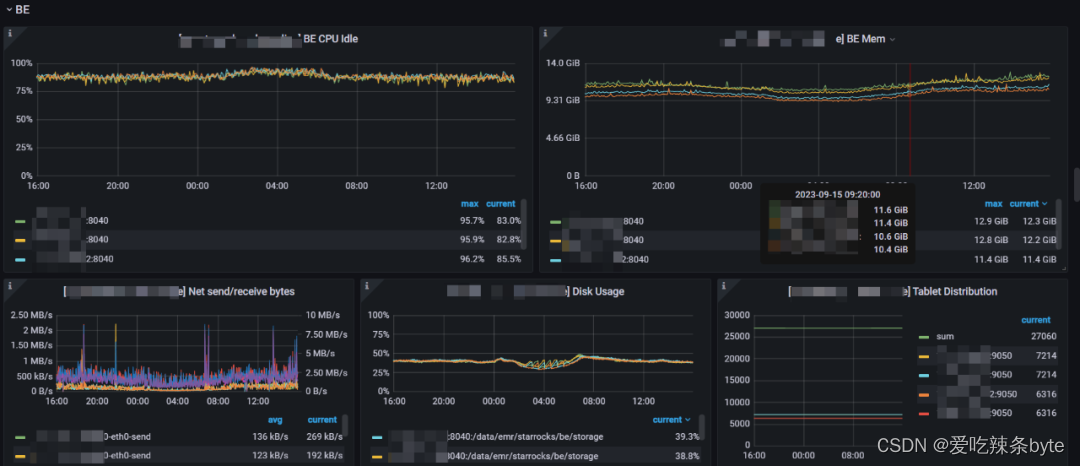
1、BE CPU Idle:BE 的 CPU 空閑狀態。低表示 CPU 忙。說明CPU的利用率越高
2、BE Mem:這里是監控集群中每個BE的內存使用情況
3、Net send/receive bytes:每個BE節點的網絡發送(左 Y)/接收(右 Y)字節速率,除了“IO”
4、Disk Usage:BE節點的storage的大小(注意這個只是/data/starrocks/storage目錄的大小,實際機器上面可能會比這個大,有log或者系統使用的磁盤)
5、Tablet Distribution:每個 BE 節點上的 Tablet 分布情況,原則上分布式均衡的,如果差別特別大,就需要去分析原因。(該值不宜過大,太大會消耗FE,以及BE的內存,我們做過相關壓測一個 Tablet 大概消耗FE 5KB的內存,并且改值隨著整體 Tablet 總量增加而增加。默認一張表的全部Tablet 數= 分區數*分桶數 *?3副本)
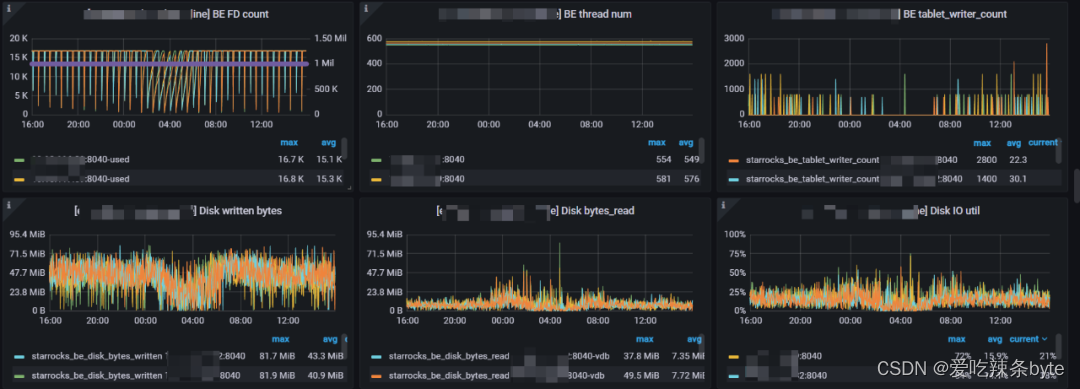
1、BE FD count:BE的文件描述符( File Descriptor)使用情況。左 Y 軸顯示使用的 FD 數量。右側 Y 軸顯示軟限制打開文件數。(可以理解為文件句柄)
2、BE thread num:BE的線程數(用來衡量be的并發情況,當前16core機器在400左右為正常值)
3、BE tablet_writer_count:be節點上面正在做寫入的tablet 數量(用來衡量be寫入負載)
4、Disk written bytes:be節點上磁盤的寫速度。
5、Disk bytes_read:be節點上磁盤的讀速度。
6、Disk IO util:每個 BE 節點上磁盤的 IO util 指標,數值越高表示IO越繁忙。

1、BE Compaction Base:BE的Base Compaction(基線合并)壓縮速率。左Y軸顯示be節點壓縮速率,右Y軸顯示的整個集群累計做base compaction的大小。
2、BE Compaction Cumulate:BE的Base Cumulate壓縮速率。左Y軸顯示be節點壓縮速率,右Y軸顯示的整個集群累計做Cumulate compaction的大小。
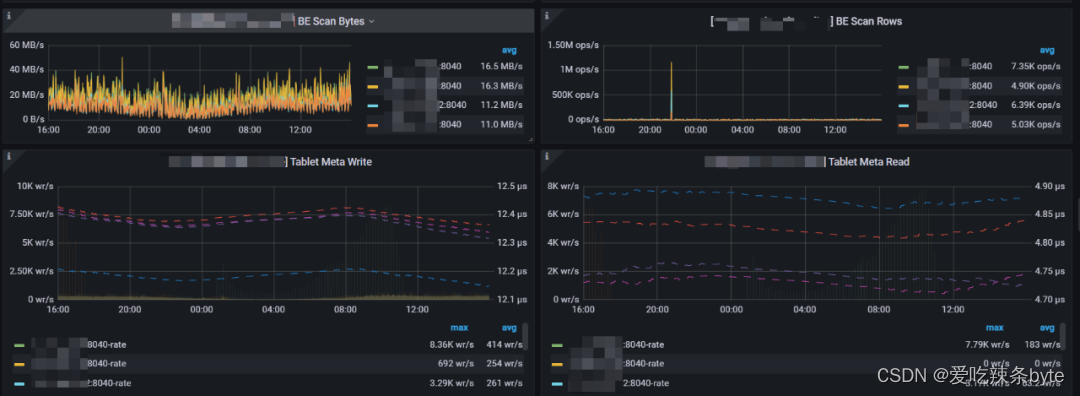
1、BE Scan Bytes:BE掃描效率,這表示處理查詢時的讀取率。(該值可以結合qps一起參考集群的查詢壓力)
2、BE Scan Rows:BE掃描行的效率,這表示處理查詢時的讀取率。
3、Tablet Meta Write:左Y 軸顯示了tablet header 的寫入速率。右側 Y 軸顯示每次寫入操作的持續時間。
4、Tablet Meta Read:左Y 軸顯示了tablet header 的讀取速率。右側 Y 軸顯示每次讀操作的持續時間。
2.2.8 BE tasks
? BE服務任務級別的監控指標:
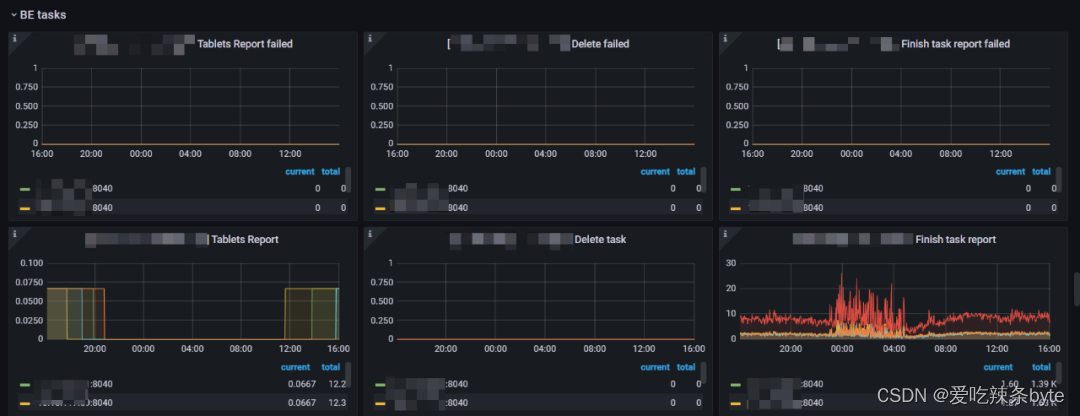
1、Tablets Report failed:BE Tablet 匯報給FE的失敗率。(正常值是0,如果該值異常,考慮排查FE BE通信,或者FE?BE負載是否有問題)
2、Delete failed:BE 做刪除操作的失敗率。(一般不會出現失敗,如果刪除失敗檢查一下磁盤是否正常)
3、Finish task report failed:BE向FE匯報的失敗率。(正常值是0,如果該值異常,考慮排查FE?BE通信,或者FE?BE負載是否有問題)
4、Tablets Report:BE向FE做全量Tablet匯報的頻率(正常的值是在0.67左右,如果該值減少,需要排查一下BE節點的負載情況)
5、Delete task:BE做刪除操作的頻率。(用來監控集群刪除數據的頻率,一般情況是0,如果該值比較大,需要排查集群是否在做 刪表,刪庫操作)
6、Finish task report:BE節點運行Task的頻率(可以用來衡量BE的繁忙程度和并發)
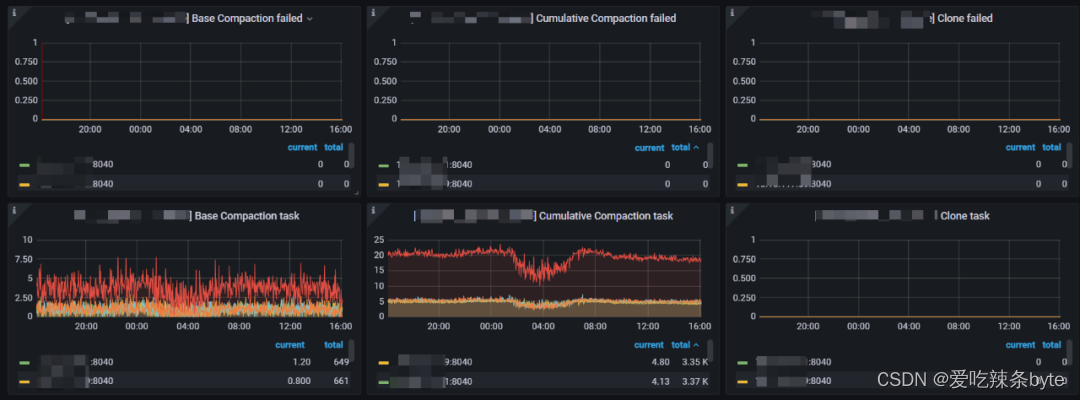
1、Base Compaction failed:Base compaction失敗率(BE做大合并的失敗率,正常是0,如果該值異常,需要檢查Be compaction內存,以及BE的IO是否正常。)
2、Cumulative Compaction failed:Cumulative Compaction(BE做小合并的失敗率,正常是0,如果該值異常,需要檢查Be compaction內存,以及BE的IO是否正常。)
3、Clone failed:tablet clone的失敗率(Tabelt 做副本修復或者均衡的時候會clone,該值異常檢查一下BE的IO)
4、Base Compaction task:Be做base compaction的頻率。(用來反應當前集群的compaction大壓力,如果Tablet 不及時做compaction,會影響讀寫性能,可以調整base compaction的并發來調整)
5、Cumulative Compaction task:BE做cumulative compaction的頻率。(用來反應當前集群的小compaction壓力,如果Tablet 不及時做compaction,會影響讀寫性能,可以調整cumulative compaction的并發來調整)
6、Clone task:BE節點Tablet 做復制的頻率(這個可以結合 scheduler tablet監控一起來判斷集群的Tablet復制的情況)

1、Create tablet:新建Tablet 頻率(一般新建表,新建分區,寫數據會伴隨著tablet數的增加,改值可以用來衡量集群的寫入頻率)
2、Single Tablet Report:tablet的匯報頻率(左側 Y 軸表示指定任務的失敗率。通常,它應該是 0。右側 Y 軸表示所有 Backends 中指定任務的總數。)
3、Create tablet failed:新建Tablet 失敗率(一般新建表,新建分區,寫數據會伴隨著tablet數的增加,該值正常是0,如果該值異常要檢查一下集群是否有建表,建分區失敗的情況)
2.2.9 BE Mem
? BE服務內存分配使用情況:
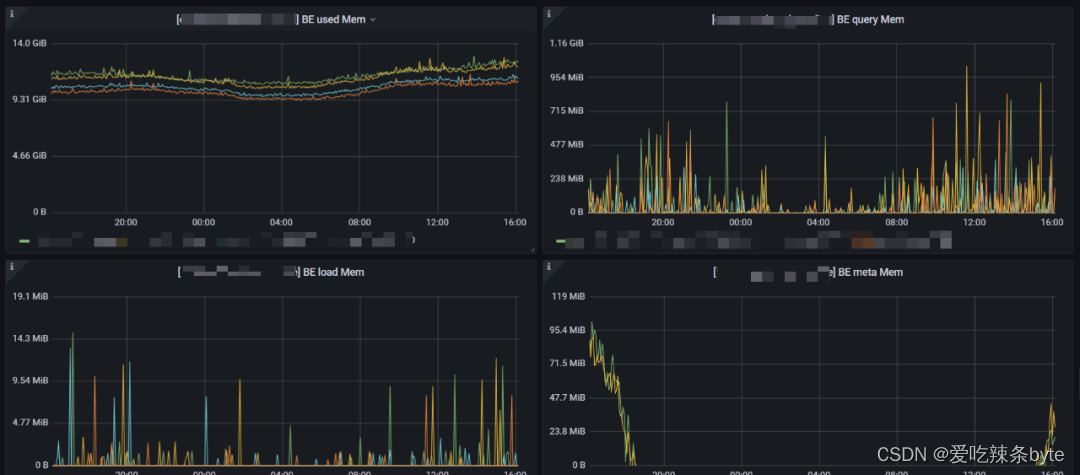
1、BE used Mem:BE服務使用的總內存(當前BE節點配置的內存基本都為機器內存的80%,如果使用內存超了需要,排查內存具體消耗在哪里,具體優化或者分析是否需要擴容)
2、BE query Mem:查詢部分消耗的內存。(對于64G內存的機器,當前該值的限制是40G,該內存需要結合QPS,慢查詢一起治理優化)
3、BE load Mem:導入任務消耗的內存。(對于64G內存的機器,當前該值的限制是13G,如果該值大,需要連接集群Show Load;查看當前的導入任務,建議超過10G大小的數據,不要再業務高峰期操作)
4、BE meta Mem:BE消耗元數據總內存。(在查詢和導入的時候,BE會把相關的Tablet元數據加載到內存中,這部分內存目前沒有命令可以主動釋放,需要重啟節點才能釋放)
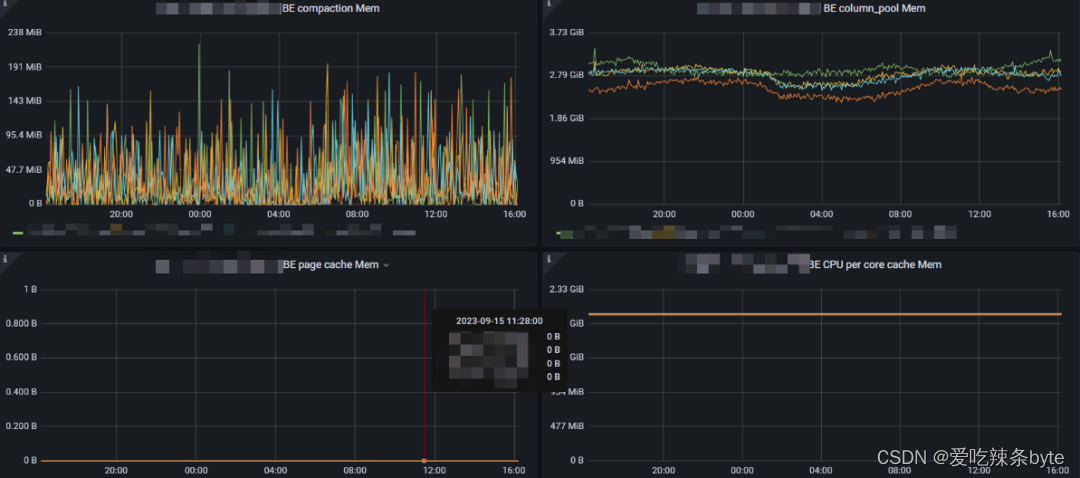
1、BE compaction Mem:BE服務做compaction合并使用的內存。(對于64G的機器,當前該值的限制是14G,建議超過10G大小的數據,不要再業務高峰期操作,否則做compaction會很消耗內存,影響集群的查詢)
2、BE column_pool Mem:column pool 內存池,用于加速存儲層數據讀取的 Column Cache。(在做查詢的時候,會把部分緩存保留在內存中,該內存沒有命令主動釋放,只能重啟節點才能釋放)
3、BE page cache Mem:BE 存儲層 Page 緩存。(當前集群都沒有開啟Page cache)
4、BE CPU per core cache Mem:CPU per core 緩存,用于加速小塊內存申請的 Cache。
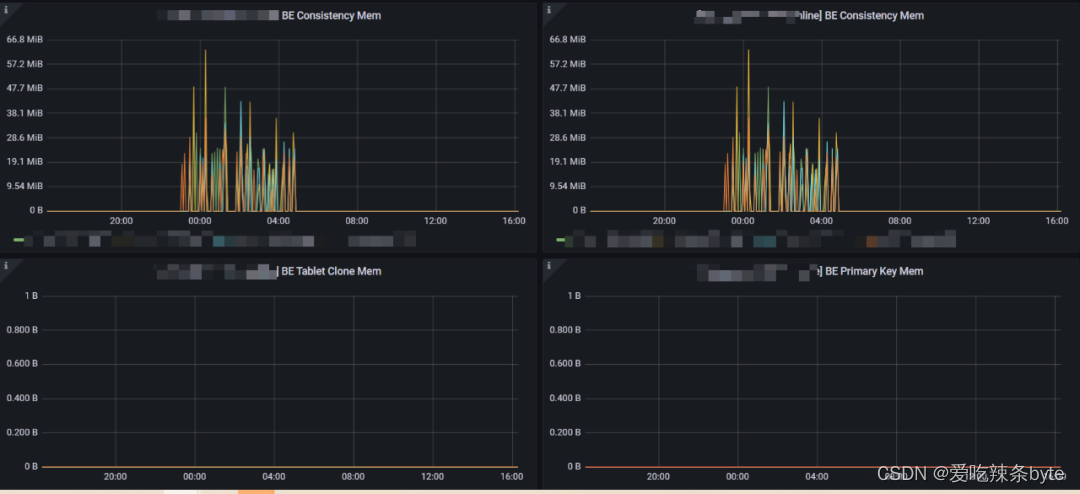
1、BE Consistency Mem:集群做Tablet 一致性校驗的時候消耗的內存(集群會周期性的自動觸發做一致性校驗,有不一致的之后會伴隨著Tablet 的復制,改情況為正常情況)
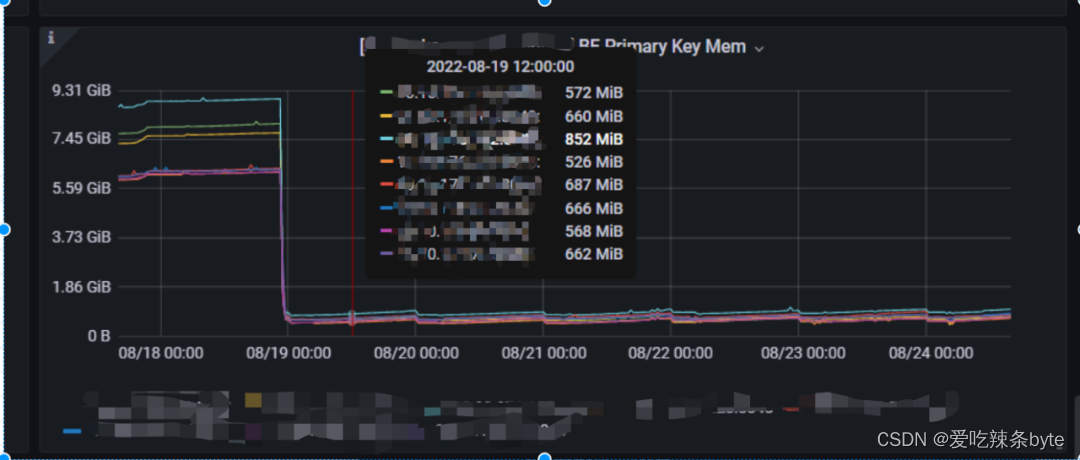
2、BE Primary Key Mem:主鍵索引消耗的內存。(對于64G的機器,該值的限制是26G,默認主鍵表在寫入的時候,會把目標分區的主鍵索引都加載到內存中,如果該值過大,可以聯系運維,訪問BE 8040端口查看主鍵內存消耗的集群情況,找到對應的表做對應治理)
3、 BE Tablet Clone Mem:Tablet 復制時消耗的內存(如果該值過大,需要排查集群tablet的健康情況,一般會伴隨大量的Tablet Scheduler)
三、總結
? ? 在 StarRocks 中,合理建表和集群監控是數據分析和查詢引擎的關鍵環節。建表是構建數據基礎的第一步,需要精心規劃和管理,以確保數據的高效存儲和查詢。同時,監控則是保障系統穩定性和性能的守護者,通過實時的性能分析和故障檢測,及時發現并解決潛在問題,確保系統持續運行。
參考文章:
Apache DolphinScheduler 在奇富科技的首個調度異地部署實踐
【最全指南】StarRocks Prometheus+Grafana 監控報警配置 - 🙌 StarRocks 技術分享 - StarRocks中文社區論壇
StarRocks 2.4 Grafana監控模板及指標項整理 - 🙌 StarRocks 技術分享 - StarRocks中文社區論壇
StarRocks 的表設計規范與監控體系
使用 Prometheus 和 Grafana 監控報警 | StarRocks


:算法及其在醫療問題中的應用)
















)