為促進駕駛場景中語音處理和識別研究,在ISCSLP 2022上成功舉辦智能駕駛座艙語音識別挑戰 (ICSRC)的基礎上,西工大音頻語音與語言處理研究組 (ASLP@NPU)聯合理想汽車、希爾貝殼、WeNet社區、字節、微軟、天津大學、南洋理工大學以及中國信息通信研究院等多家單位在ICASSP2024上推出了車載多通道語音識別挑戰賽(ICMC-ASR)。作為大會的旗艦賽事之一,ICMC-ASR發布了在新能源汽車內錄制的100多小時多通道語音數據(單通道計算)以及用于數據增廣的40小時噪聲數據。挑戰賽設有語音識別 (ASR)和語音分離和識別 (ASDR)兩個賽道,分別使用字符錯誤率 (CER)和連接最小排列字符錯誤率 (cpCER)作為評價指標。
本次挑戰賽吸引了國內外共計98支隊伍參賽,并在兩個賽道上收到了53個有效提交結果。競賽總結論文“ICMC-ASR: The ICASSP 2024 In-Car Multi-Channel Automatic Speech Recognition Challenge”已被語音研究頂級會議ICASSP2024接收。現對該論文進行分享,包括競賽舉辦的背景、所采用的數據集、賽道設置、比賽結果和各參賽隊伍所采用的關鍵技術等。
賽事網址:https://icmcasr.org/

論文題目:ICMC-ASR: The ICASSP 2024 In-Car Multi-Channel Automatic Speech Recognition Challenge
合作單位:理想、希爾貝殼、WeNet社區、字節、微軟、天津大學、南洋理工大學、中國信息通信研究院
作者列表:王賀、郭鵬程、李越、張奧、孫佳耀、謝磊、陳偉、周盼、卜輝、徐昕、張彬彬、陳卓、巫健、王龍標、Eng Siong Chng、李蓀
論文原文:https://arxiv.org/abs/2401.03473
相關鏈接:NPU-ASLP實驗室10篇論文被ICASSP2024錄用

發表論文截圖
背景動機
隨著深度學習的不斷發展,語音識別(ASR)技術取得了長足的進步,其性能也獲得了大幅提升。然而ASR系統在實際復雜遠距離拾音場景中的表現遠未達到滿意的效果,干擾來自背景噪聲、混響、說話人重疊和需要適配各種麥克風陣列幾何結構拓撲等。為了應對這些挑戰,CHiME系列競賽應運而生,競賽的宗旨是通過鼓勵多通道信號處理算法的研究和創新來促進魯棒 ASR系統的發展。
語音交互已經變成車機系統不可或缺的組成部分。不同于智能家居或者會議等常見語音識別 (ASR)系統部署的場景,密閉且不規則的駕駛艙的聲學環境是相對更加復雜的。此外,在駕駛過程中存在著各種噪聲,如風聲、引擎聲、輪胎聲、車載廣播和音樂、多人交談等。因此,如何利用語音處理和識別領域的最新技術來提高汽車ASR系統的魯棒性是一個值得研究的重要問題。
在2022年,我們舉辦了智能駕駛艙語音識別挑戰 (ICSRC)[1],并發布了一個在新能源汽車中收集的20小時單通道評估集,為車載ASR提供了一個公開評測的平臺。然而,在車載ASR系統的基準測試中仍然缺乏較大規模的實錄數據。為了填補這一空白,我們在ICSRC成功舉辦的基礎上推出了ICASSP 2024車載多通道自動語音識別 (ICMC-ASR)挑戰賽,專注于復雜駕駛條件下的語音處理和識別。此外,ICMC-ASR數據集包括了一個超過100小時的車內實錄多通道、多說話人的普通話對話數據和40小時的汽車內錄制的多通道噪聲音頻(時長均以單通道計算)。ICMC-ASR挑戰賽包括語音識別和語音分離與識別 (ASDR)兩個賽道,針對車內多說話人聊天場景,分別使用字錯誤率 (CER)和連接最小排列字符錯誤率 (cpCER)作為評估指標。最終,ICMC-ASR挑戰吸引了國內外98支團隊參賽,并在兩個賽道中收到了53個有效結果。其中,USTC-iflytek團隊在ASR賽道上13.16%的CER和ASDR賽道上21.48%的cpCER獲得雙賽道冠軍,相較于基線系統有顯著提升。
ISCSLP 2022丨ICSRC 賽事結果公布
ICASSP2024丨車載多通道語音識別挑戰賽排名結果公布
競賽描述
數據集
ICMC-ASR挑戰賽數據集為圖1所示的新能源車內實錄多通道中文語音數據,車內說話人坐在不同的位置,包括駕駛位、副駕駛位和兩個后排座位。具體而言,4個分布式麥克風分別放置在四個座位對應車門上方,錄制每個座位上的說話人的“遠講”數據。為了方便語音轉錄,每位說話人都佩戴了高保真耳機,錄制得到“近講”數據。由于駕駛場景的真實聲學環境復雜,同時涉及各種噪聲干擾,我們精心設計了不同錄制條件來盡可能覆蓋所有的駕駛場景。我們通過排列組合與駕駛相關的各種因素,包括駕駛道路 (市區街道和高速公路)、車輛速度 (停車、緩慢、中等和快速)、空調 (關閉、中檔和高檔)、車載音響 (關閉和開啟)、駕駛位車窗和天窗 (關閉、開啟三分之一和開啟一半)、駕駛時間 (白天和夜晚),來達到這一目的。最終,構成了60種不同的駕駛場景,囊括了大部分的車內聲學環境。

圖1 數據錄制的新能源車和內嵌麥克風示意

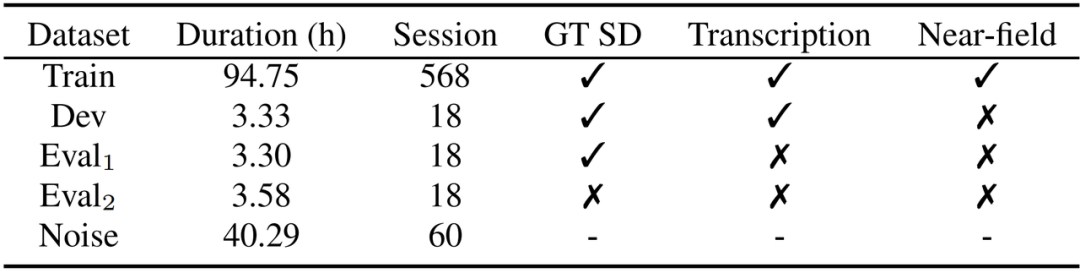
表1 ICMC-ASR數據集的統計信息,包括近場音頻的時長 (Duration)、會話數 (Session)、是否提供真實說話人日志 (GT SD)、轉錄文本 (Transcription) 以及近場音頻 (Near-field)。
賽道設置
Track1 — 語音識別 (Automatic Speech Recognition, ASR):在此賽道中,參賽者會得到測試集上的真實時間戳信息。該賽道的主要目標是構建基于多通道多說話人語音數據的魯棒ASR系統。參賽者需要設計并構建能夠有效融合不同通道信息、抑制噪聲、處理多說話人重疊的系統。對于此賽道,ASR系統的準確性將通過字錯誤率(CER)來衡量。
Track2?—?語音日志與識別 (Automatic Speech Diarization and Recognition, ASDR):與Track1不同,Track2在評估過程中不提供任何關于說話人和時間戳的先驗信息,包括每個語句的分割和說話人標簽以及每個會話中的總說話人數等。此賽道的參賽者需要設計一個既可以獲取說話人日志又可以進行語音轉錄的系統。對于此賽道,我們采用連接最小排列字錯誤率 (cpCER) 作為ASDR系統的度量標準。
競賽結果及討論
表2展示了在本次ICMC-ASR挑戰賽中取得優異成績的團隊以及基于WeNet工具包[11]的基線系統的主要技術點和結果。如查看完整的排行榜和詳細的系統報告,請參閱我們的競賽官方網站。我們分別計算了35支參與Track1的團隊和18支參與Track2團隊的所提交結果的CER和cpCER指標。據此,ICASSP2024 ICMC-ASR挑戰賽的兩個賽道的冠軍均是USTC-iflytek團隊,在Track1和Track2上分別取得了13.16%的CER和21.48%的cpCER。下面就各團隊所使用的技術展開討論,包括語音前端、ASR以及說話人日志三個方面。
基線系統:https://github.com/MrSupW/ICMC-ASR_Baseline
競賽官方網站:https://icmcasr.org/
表2 兩個賽道的Top系統和競基線系統所使用的主要技術和結果。語音前端和ASR在兩個賽道中都被應用,而說話人日志技術僅用于Track2。加粗的團隊受邀提交ICASSP 2024的技術報告論文。

語音前端?大多數團隊都在語音前端方面沿用了基線系統中使用的聲學回聲消除 (AEC)和獨立矢量分析 (IVA)技術。基于此,一些團隊整合了用于去混響的加權預測誤差 (WPE)和分離說話人語音的引導源分離 (GSS)技術,例如RoyalFlush團隊、FawAISpeech團隊和HLT2023-NUS團隊。此外,許多參賽團隊也使用了基于神經網絡 (NN)的語音前端降噪模型,包括MP-SENet [3]、DCCRN-VAE [8]和DEEP-FSMN [5]。特別地,USTCiflytek團隊在GSS中使用能量和相位差異代替傳統的最大信號噪聲比 (SNR)標準進行通道選擇,同時在波束形成器中使用遞歸平滑技術評估功率譜密度矩陣,為下游ASR提供了更高質量的單通道音頻。
ASR Backbone?根據ICMC-ASR挑戰賽不允許使用額外文本數據的規則,許多團隊選擇使用開源音頻數據訓練自監督學習 (SSL)模型來生成音頻特征,然后將其輸入主流ASR模型進行訓練。HuBERT?[4] SSL模型是最受歡迎的模型之一,在分析討論的7支團隊中,有4支均使用了HuBERT模型。其余的三支隊伍,Nanjing Longyuan團隊使用了Data2vec2 [6]作為SSL模型,并在訓練過程中引入了噪聲增廣技術;USTC-iflytek團隊對未標記數據迭代生成偽標簽,并提出了針對口音優化的Accent-ASR模型;FawAISpeech團隊提出了基于E-Branchformer和交叉注意力[12]的多通道ASR模型,沒有使用SSL模型。
說話人日志?除Fosafer Research和Nanjing Longyuan團隊,大多數團隊使用基于神經網絡的VAD模型,在說話人日志技術上選擇了TS-VAD [13]并基于此進行改進。具體地,USTC-iflytek團隊將TS-VAD模型擴展到多通道音頻,提出并使用了Multi-Channel TS-VAD [2];RoyalFlush團隊、喜馬拉雅語音團隊和HLT2023-NUS團隊采用了類似的方法,使用不同的基于神經網絡的模型提取說話人表征,取代了傳統TS-VAD中所使用的i-vector特征。
本賽事相關數據后續會開源,敬請關注。
參考文獻
[1] Ao Zhang, Fan Yu, Kaixun Huang, Lei Xie, et al., “The ISCSLP 2022 Intelligent Cockpit Speech Recognition Challenge (ICSRC): Dataset, Tracks, Baseline and Results,” in Proc. ISCSLP. IEEE, 2022, pp. 507–511.
[2] Ruoyu Wang, Maokui He, Jun Du, Hengshun Zhou, et al., “The USTC-Nercslip Systems for the CHiME-7 DASR Challenge,” 2023.
[3] Ye-Xin Lu, Yang Ai, and Zhen-Hua Ling, “MP-SENet: A Speech Enhancement Model with Parallel Denoising of Magnitude and Phase Spectra,” 2023.
[4] Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, et al., “Hubert: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units,” IEEE/ACM TASLP, vol. 29, pp. 3451–3460, 2021.
[5] Shiliang Zhang, Ming Lei, Zhijie Yan, et al., “Deep-FSMN for Large Vocabulary Continuous Speech Recognition,” in Proc. ICASSP, 2018, pp. 5869–5873.
[6] Alexei Baevski, Arun Babu, Wei-Ning Hsu, and Michael Auli, “Efficient Self-Supervised Learning with Contextualized Target Representations for Vision, Speech and Language,” in Proc. ICML. PMLR, 2023, pp. 1416–1429.
[7] Brecht Desplanques, Jenthe Thienpondt, and Kris Demuynck, “ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN based Speaker Verification,” in Proc. Interspeech. 2020, pp. 3830–3834, ISCA.
[8] Yang Xiang, Jingguang Tian, Xinhui Hu, et al., “A Deep Representation Learning-based Speech Enhancement Method using Complex Convolution Recurrent Variational Autoencoder,” arXiv preprint arXiv:2312.09620, 2023.
[9] Jingguang Tian, Xinhui Hu, and Xinkang Xu, “Royalflush Speaker Diarization System for ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Challenge,” arXiv preprint arXiv:2202.04814, 2022.
[10] Hui Wang, Siqi Zheng, Yafeng Chen, Luyao Cheng, and Qian Chen, “CAM++: A Fast and Efficient Network for Speaker Verification using Contextaware Masking,” arXiv preprint arXiv:2303.00332, 2023.
[11] Zhuoyuan Yao, Di Wu, Xiong Wang, et al., “WeNet: Production Oriented Streaming and Non-streaming End-to-End Speech Recognition Toolkit,” 2021.
[12] Pengcheng Guo, He Wang, Bingshen Mu, Ao Zhang, and Peikun Chen, “The NPU-ASLP System for Audio-Visual Speech Recognition in MISP 2022 Challenge,” in Proc. ICASSP. IEEE, 2023, pp. 1–2.
[13] Ivan Medennikov, Maxim Korenevsky, Tatiana Prisyach, Yuri Khokhlov, et al., “Target-Speaker Voice Activity Detection: A Novel Approach for Multispeaker Diarization in A Dinner Party Scenario,” pp. 274–278, 2020.
文章來源于音頻語音與語言處理研究組?,作者王賀





)



)
)








物聯網NodeMCUESP8266(ESP-12F)連接新版onenet mqtt協議實現上傳數據(溫濕度)和下發指令(控制LED燈))