1.謬論
很多非一手的資料特別是中文資料其實并不可靠 因為很多作者都是直接通過轉載他人的作品 也不管他人作品真與假 而且有一部分的作品中的言論和官方描述相去甚遠 有的則是翻譯的過程中出現了問題
比如sizeof很多人認為是一個函數 其實他并不是一個函數 而是一個運算符 是一個一元運算符
而且就算官方也有出錯的時候 這就要求我們具有辨別的能力了
2.建議
首選官方資料(手冊、官網……)
英文資料 > 中文資料
具備驗證知識點正確性的能力(有關編程語言知識點的正確性 掌握匯編語言是最靠譜的檢驗手段)
3.匯編的好處
1.可以檢驗知識點的正確性
2.可以進行破解
3.可以制作外掛
4.代碼本質挖掘
1.sizeof本質
sizeof本質上不是一個函數 而是一個運算符
在匯編語言中 函數利用了call完成調用操作 而在sizeof的底層匯編中 壓根沒有call的影子 說明根本就不是所謂的函數
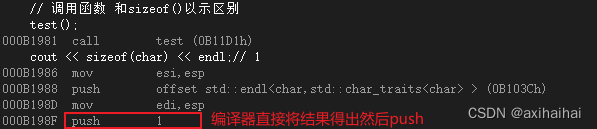
從另外一個方面也可以看出sizeof不是一個函數
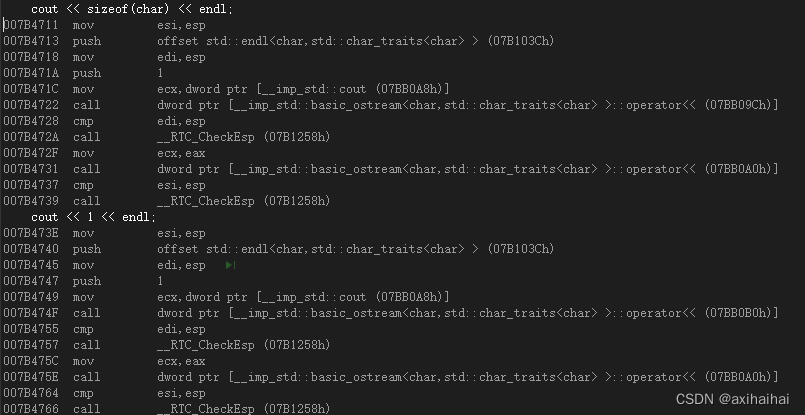
我們可以看到直接打印sizeof(char)的結果和打印sizeof(char)的底層匯編所執行的操作是一模一樣的 說明編譯器在編譯階段是直接可以識別出sizeof()的結果并且替換成相應的結果(因此sizeof也被稱為編譯時特性) 既然如此 更能說明sizeof不是一個函數
2.a++和++a的區別
3.if-else和switch的效率比較
4.程序的內存布局
5.多態的實現原理
5.程序的本質
程序是以機器碼(或稱作CPU指令 即由0和1組成的)的形式儲存在硬盤中的(在儲存之前 是由編譯器將其編譯成機器碼的) 當運行軟件的時候 程序會被裝載到內存之中 然后CPU會根據機器碼的要求調用計算機的其他設備完成相關的需求(CPU只能識別機器碼)
CPU由寄存器、運算器、控制器組成 其中寄存器也有和內存一樣的儲存功能 那么CPU在訪問寄存器方面肯定是比內存要來的快的 原因在于寄存器更加接近CPU
6.寄存器和內存
通常情況下 CPU會先將內存中的數據儲存到寄存器中 然后在對寄存器中的數據進行訪問或者運算
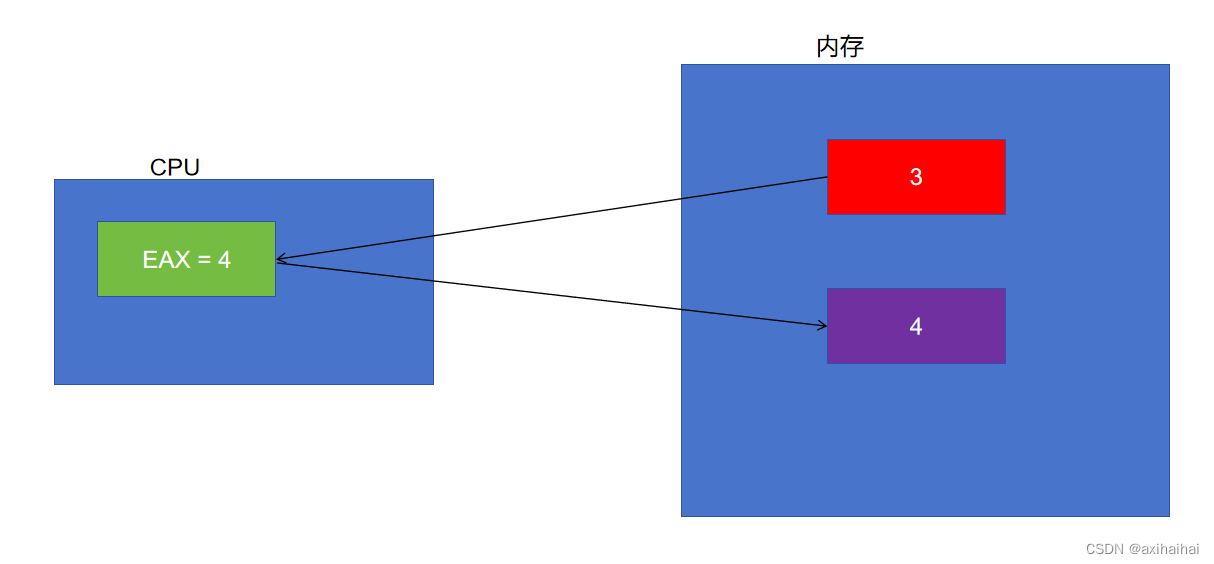
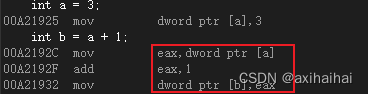
我的要求是對紅色內存中的數據進行加一操作
其中 首先會將紅色內存中的數據儲存到eax寄存器中 即mov eax, 紅色內存空間
接著讓EAX的數據和1相加 即add eax, 1
最后會將結果儲存到藍色的內存空間中 即mov 藍色內存空間, eax
從反匯編的角度也可以說明驗證我的說法
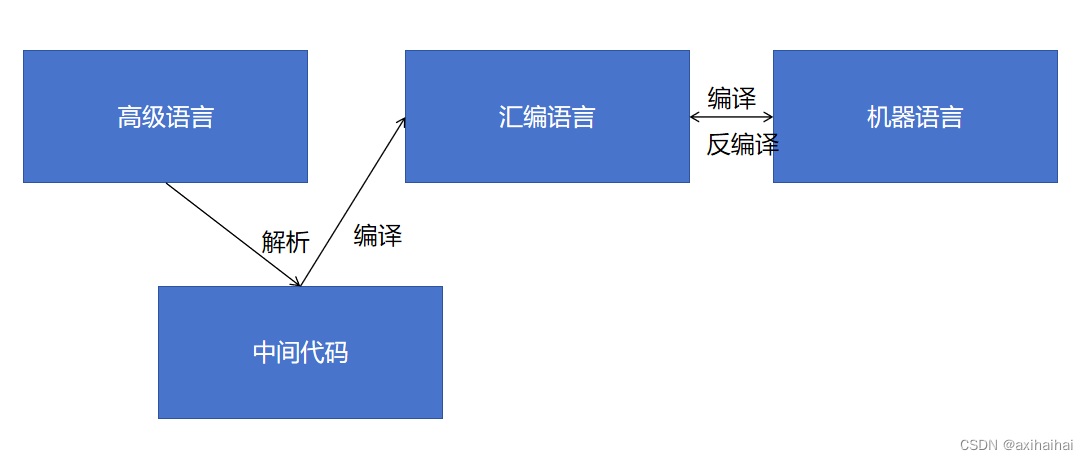
7.編程語言的發展
機器語言(由0和1組成) -> 匯編語言(用符號替代了0和1 可讀性更強了) -> 高級語言(c/c++/java…… 接近人類自然語言 更具有可讀性)
對于同一個操作 將寄存器ebx的內容傳入到eax中(以下代碼是偽代碼)
機器語言:010100000001111011010
匯編語言:mov eax, ebx
高級語言:eax = ebx;
很多語言都有高級語言編譯成匯編語言、匯編語言編譯成機器語言最終運行到計算機上的過程
其中匯編語言和機器語言是可以相互轉換的 也就是說匯編可以編譯成機器語言 機器語言也可以反編譯成匯編語言 所以匯編語言和機器語言是一一對應的 每一條匯編語言都有與之對應的機器語言
然而高級語言雖然可以通過編譯得到匯編/機器 但是匯編/機器幾乎不能夠反編譯成高級語言

對比兩張圖片可以看到兩個不同的高級語言底層的匯編/機器是一模一樣的 更能說明匯編/機器幾乎不能夠還原成高級語言(因為一旦還原的話 會產生歧義)
不同的CPU架構(x86和arm)的機器指令是不一樣的(CPU架構不一樣 CPU就不一樣 那么所處理的機器指令也就不一樣)
8.一些編程語言的本質
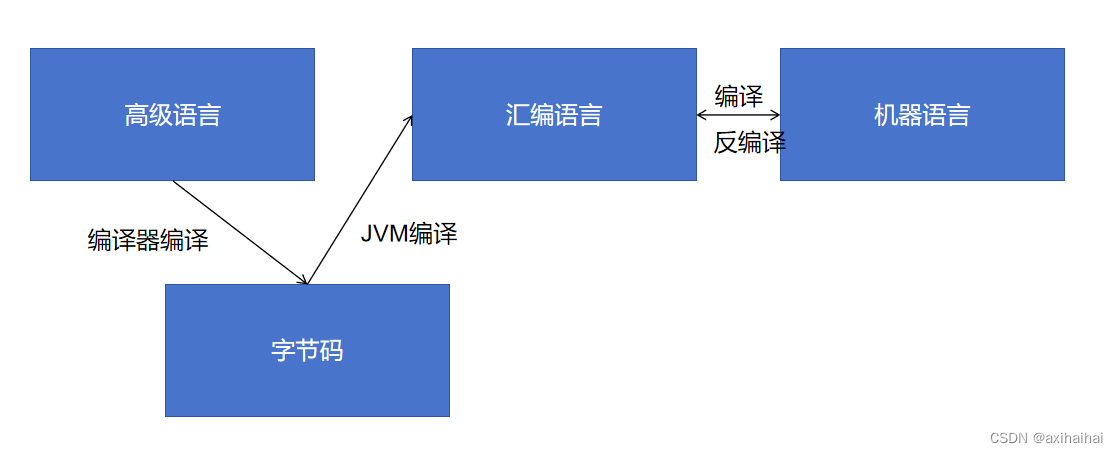
1.編譯型語言(不依賴虛擬機)
諸如C/C++/OC/Swift 輕易反匯編

2.腳本語言
諸如Python/PHP/JS 由腳本引擎(比如瀏覽器等)解析
3.編譯型語言(依賴虛擬機)
Java/Ruby 由JVM進行字節碼的裝載
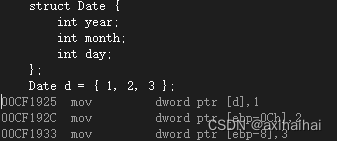
9.visual studio中的反匯編

從上圖可見 反匯編中的每一行大致都是由三部分組成 第一部分是內存中用于標識機器碼的位置的地址值 第二部分則是這段代碼的機器碼 第三部分則是這段代碼的匯編代碼

而且高級語言中的一行代碼不一定對應著匯編/機器碼中的一行 可能是多行




)










:用c++通過自然語言處理技術分析語音信號音高)

)

